
融合空间注意力的自适应安检违禁品检测方法
2023-11-20 10:58任东升杨鹏熙杜茂生
计算机工程与应用 2023年21期
游 玺,侯 进,任东升,杨鹏熙,杜茂生
1.西南交通大学 信息科学与技术学院 智能感知智慧运维实验室,成都 611756
2.西南交通大学 综合交通大数据应用技术国家工程实验室,成都 611756
3.西南交通大学 唐山研究院,河北 唐山 063000
随着城市交通的快速发展,安检在保障出行安全中发挥着重要的作用。但是目前识别安检机扫描出的违禁物品主要还是依靠人工完成,这种方式会耗费大量的人力和财力,尤其是在人流高峰期,安检人员可能因为工作疲劳而出现漏检、误检的情况。因此,研究出一种高精度的智能安检识别算法对保障公共出行安全有着十分重要的意义。
目标检测在交通、监控和医学等领域都有大量应用[1]。钱伍等[2]在YOLOv5[3]基础上对主干网络和融合网络进行改进,提高模型在各种复杂交通场景中对交通灯的检测能力。宋艳艳等[4]在YOLOv3[5]的基础上结合残差结构进行多尺度融合提高检测性能,并引入斥力损失函数解决目标遮挡问题。在X 光安检图像的违禁物品检测领域中也积累了大量研究成果[6]。主要从YOLO系列为代表的单阶段算法和以Faster R-CNN[7]为代表的两阶段算法两个方向进行研究。单阶段算法与两阶段算法相比,结构简单且检测速度更快,但检测精度稍有欠缺。
面对X光安检图像违禁品研究领域物品复杂、遮挡和密集等诸多挑战,吴海滨等[8]在YOLOv4[9]算法的基础上加入改进的空洞卷积,使用多尺度聚合上下文信息,最后通过K-means聚类算法优化初始候选框,但是检测精度仍然不是很理想;针对此问题,董乙杉等[10]提出了一种改进YOLOv5 的X 光违禁品检测模型,该模型在YOLOv5 算法的基础上,结合注意力机制、加权边框融合和数据增强策略以提高网络检测的精准度。康佳楠等[11]提出了一种多通道区域建议的多尺度X 光安检图像检测算法,在Faster R-CNN算法的基础上,采用多尺度特征提取与多通道区域建议网络融合更多的特征图信息,以提高违禁品检测精度。由于违禁物品相对于行李箱较小,普通的网络模型对小目标检测能力很弱,为了解决X 光图像中小目标违禁物品漏检问题,吉祥凌等[12]在SSD[13]网络的基础上采用多尺度特征融合方法来提高小目标检测性能。张友康等[14]在SSD网络模型上,引入小卷积非对称模块和多尺度特征图融合模块来提升网络对小目标检测的性能。但是网络检测的速度仍然无法达到实时性要求,于是郭守向等[15]基于YOLOv3网络模型改进,将其主干网络改为由两个DarkNet组合的新主干网络,并且引入特征增强模块来提高小目标的检测效果,并提高了检测速度。
目前针对X 光安检图像违禁品检测的研究取得了有效进展,但是仍然存在以下问题:没有对不同摆放姿态和不同形状的违禁品进行感受野适配,导致模型有漏检现象;没有抑制复杂背景噪音带来的干扰,导致模型存在误检现象;锚框的设定依赖于人工进行聚类设定,导致锚框初始值泛化性不强,从而影响模型检测准确度;小样本数据集无法训练出高准确率的结果。
综上,本文从特征提取网络、注意力机制、候选区生成网络和检测器四个方面,在精度更高的两阶段检测网络Cascade RCNN[16]基础上进行改进,主要贡献如下:
(1)提出一种空间自适应注意力模块(spatial adaptive attention module,SAAM),提高网络对目标区域的关注度,更好地抑制复杂背景带来的噪音干扰;同时引入可形变卷积(deformable convolutional networks,DCN)[17]改进特征提取网络,提高网络对不同尺度违禁品的自适应性。
(2)提出一种多尺度自适应候选区域生成网络(multiscale guided anchoring region proposal network,MGA-RPN),结合Guided Anchoring[18]方法并融合多尺度特征图,自适应生成候选框和高质量特征图。
(3)改进级联检测头,嵌入在线难例挖掘模块(online hard example mining,OHEM)[19]解决正负样本不均衡问题,提高对小样本目标的检测精度。
1 本文方法
Cascade R-CNN是一种基于Faster R-CNN进行改进的高精确度检测模型,引入了级联检测器(cascade detector)。采用多阶段训练策略,将多个不同IoU 阈值的检测器进行级联。每个检测器含有一个ROI Align、一个全连接层FC、一个分类回归C 和一个边框回归B。级联检测器将前一个阶段网络输出的边框回归对候选区进行重采样,作为下一个ROI Align 网络的输入,对检测结果进行不断优化[20]。
本文算法模型选用ResNet50[21]作为特征提取网络,FPN[22]+PAN[23]作为特征融合网络,整体以Cascade R-CNN网络结构为框架,并以此为Baseline进行改进得到本文的X 光违禁品检测方法(X-ray prohibited item cascade R-CNN,XPIC R-CNN),网络结构图如图1所示。
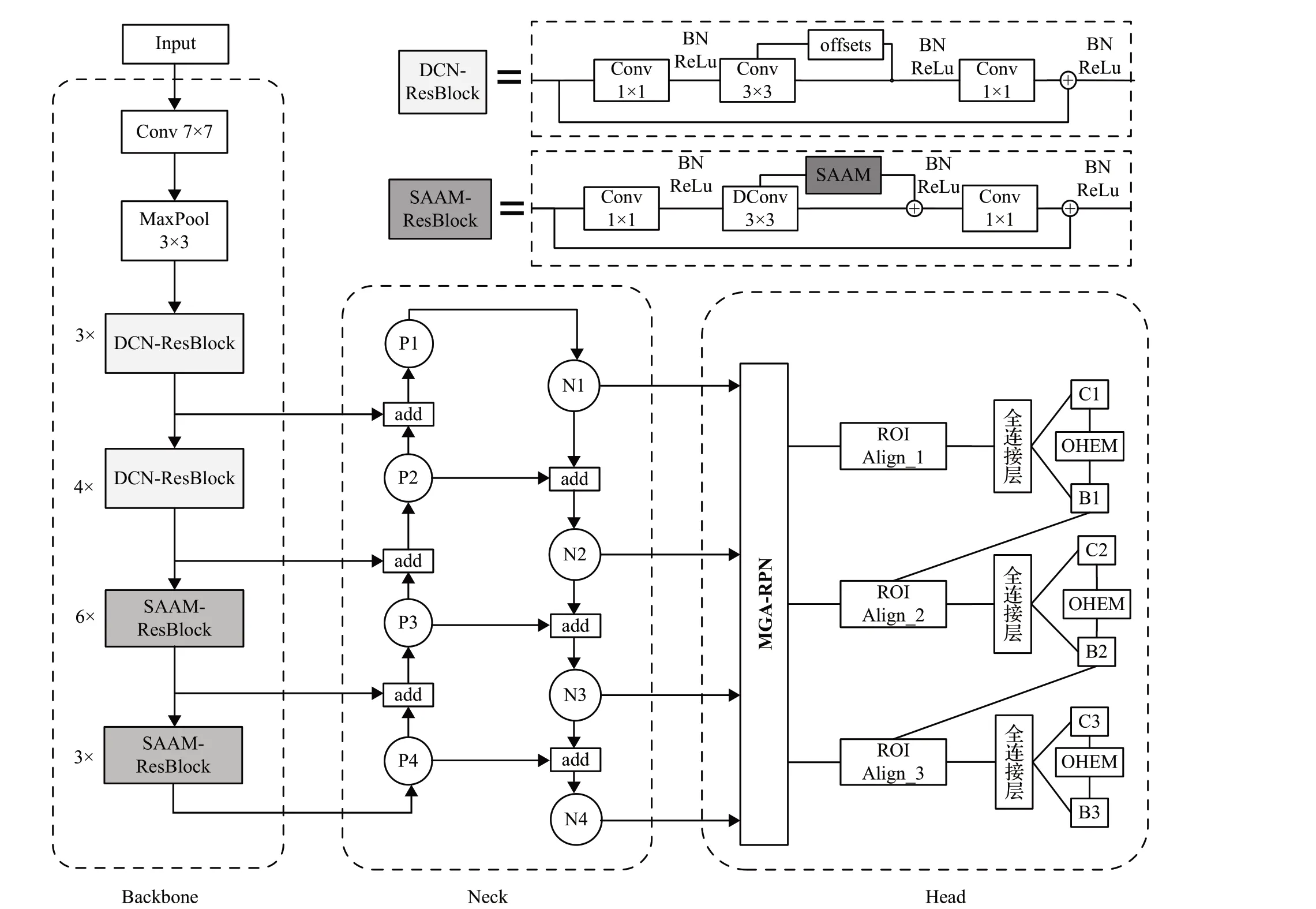
图1 XPIC R-CNN网络结构图Fig.1 XPIC R-CNN network structure diagram
1.1 自适应特征提取网络
X光拍摄的安检图像中物品形状各异,普通卷积在同一层网络中感受野是固定的,对不同尺寸物体适应能力差,如图2(a)所示;而可形变卷积通过偏移域学习符合物体形状的偏移量,使网络的感受野能够覆盖不同尺寸的目标,自适应提取目标的特征信息,如图2(b)。因此本文使用可形变卷积替换ResNet50 网络后4 个阶段的普通卷积,增加网络对不同形状违禁品的适应性。
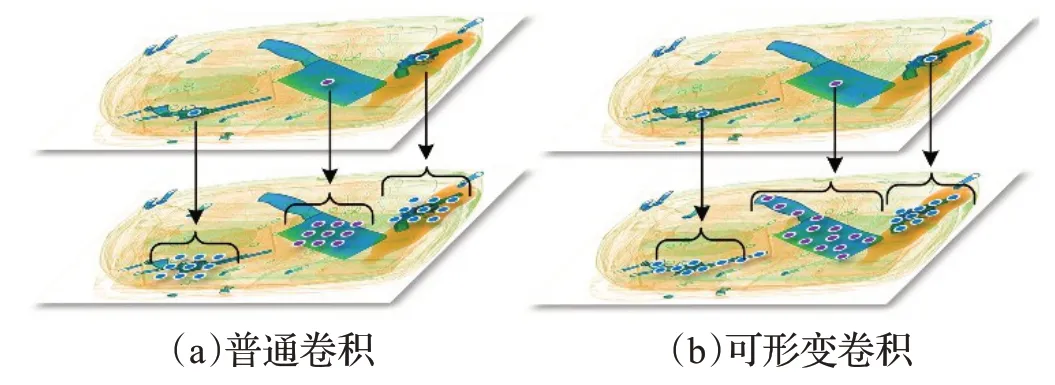
图2 普通卷积与可形变卷积感受野对比图Fig.2 Comparison of normal and deformable convolutional fields of perception
普通卷积操作主要是在输入的特征图x上采用特定的大小的网格R进行采样,然后再进行w加权运算。对输出对特征图y上的每个位置p0通过公式(1)计算:
公式中R={( - 1,-1),(-1,0),…,(0,1),(1,1)} 。可形变卷积的网络结构图如图3 所示,它是对每个p0位置都添加一个偏移量Δpn进行计算,进而得到自适应的定位,公式如下:

图3 可形变卷积原理图Fig.3 Schematic diagram of deformable convolution
1.2 空间自适应注意力模块
空间注意力机制是一种强化重要信息和抑制非重要信息的方法,可以更好地关注目标物体的本身减少对背景噪音信息的干扰。卷积注意力只能针对局部进行计算,导致感受野太小无法覆盖到所有目标范围;自注意力能进行全局运算,但也带来了巨大的计算量。因此,结合了可形变卷积的空间稀疏采样优势和自注意力强大的元素间关系建模能力,提出一种空间自适应注意力模块(spatial adaptive attention module,SAAM),嵌入到ResNet50 网络的后两个阶段中,使网络更高效地提取X 光违禁品的特征。如图4,SAAM 模块使用偏移量生成网络对目标区域自适应提取,将偏移量所覆盖到的区域作为注意力的计算范围,避免了全局注意力运算,从而减少计算量,加快网络训练收敛速度。
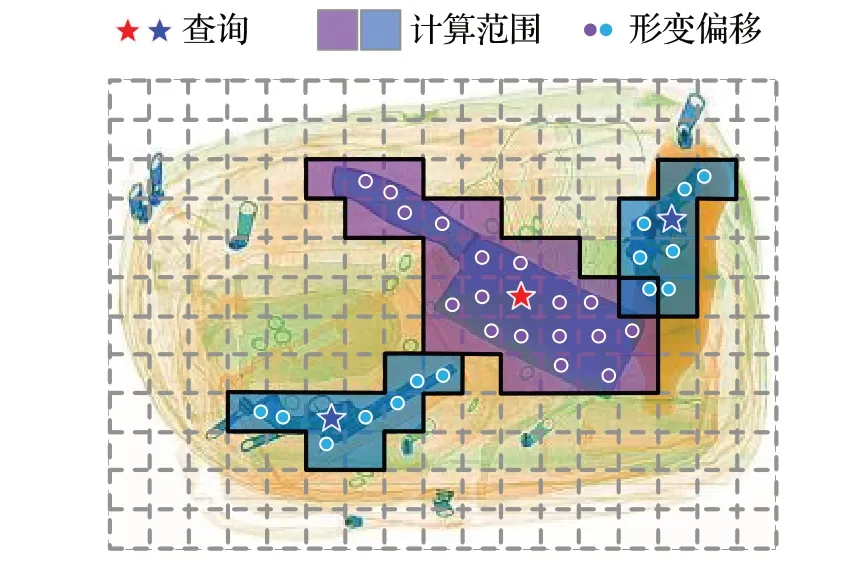
图4 空间注意力的自适应原理图Fig.4 Schematic diagram of spatial adaptive attention
SAAM模块原理如图5所示,对输入的特征图x生成目标区域的k个感兴趣点,用于后面的偏移量叠加。特征图x与转换矩阵Wq相乘得到查询向量zq,如公式(3)所示:

图5 空间自适应注意力模块原理图Fig.5 Schematic diagram of spatial adaptive attention
然后将zq输入偏移量生成网络得到第k个感兴趣点的偏移量Δpqk,具体做法如下:
之后,把生成的偏移量与感兴趣点进行叠加,并在形变点的位置对特征图x进行特征采样得到Value向量,WV为特征采样矩阵,公式如下:
因为感兴趣点和偏移采样点均来自特征向量zq,所以这里的注意力权重不再由qkT内积运算获得,而是可以直接从zq进行线性映射得到,进一步减少了计算量,如公式(6)所示:
公式(6)中,Aqk是第k个感兴趣点的注意力权重得分,zqk是第k个感兴趣点在查询向量zq中的位置,Linear代表全连接函数。
最后将注意力权重得分Aqk与V进行内积运算,并累加k个感兴趣得到这个采样区域的注意力结果,公式如下:
以上是一个计算头部的计算原理,这里使用M个头进行计算k个感兴趣点,得到最终的多头注意力结果公式为:
1.3 多尺度自适应候选区域生成网络模块
对本文研究的数据集进行分析,可以得如图6所示的锚框高宽比率分布情况,若进行人工预设锚框初始值将很难覆盖所有的情况,并且人工初始化锚框的质量会严重影响到检测网络的准确度。
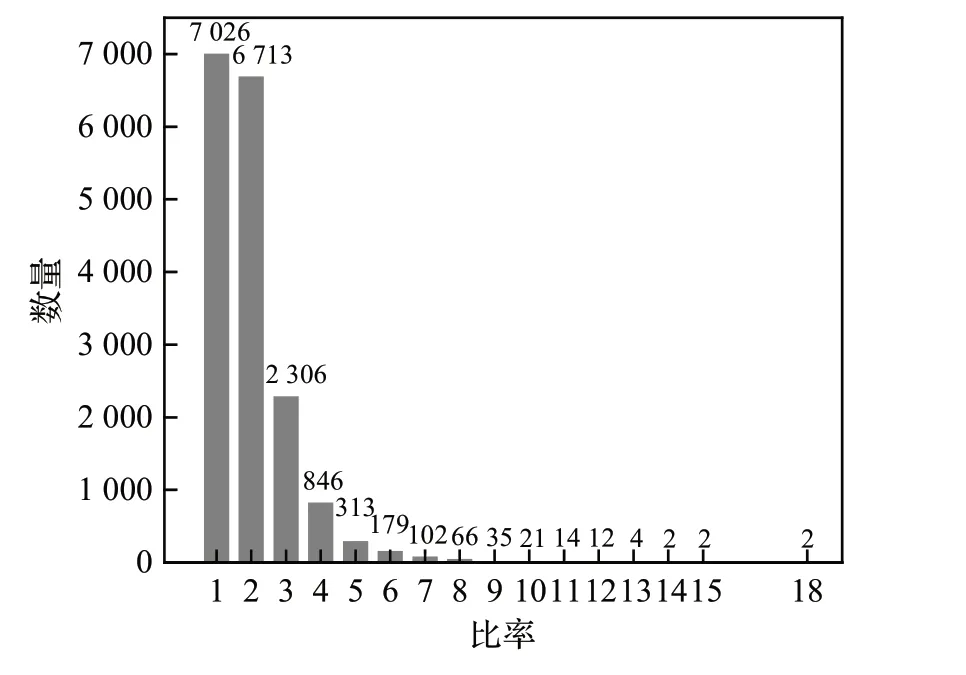
图6 数据集Anchor高宽比率的数量分布图Fig.6 Distribution of number of dataset anchor aspect ratio
因此本文设计了一个多尺度自适应候选区生成网络模块(multiscale guided anchoring region proposal network,MGA-RPN),采用多尺度特征图输入的方式结合Guided Anchoring方法。MGA-RPN可以通过多尺度特征图中丰富的语义信息指导锚框的生成,从而自适应生成候选框,并同步生成适配对应大小感受野的特征图,为后续检测工作带来更精准的效果。主要由两个子模块组成,结构如图7所示。
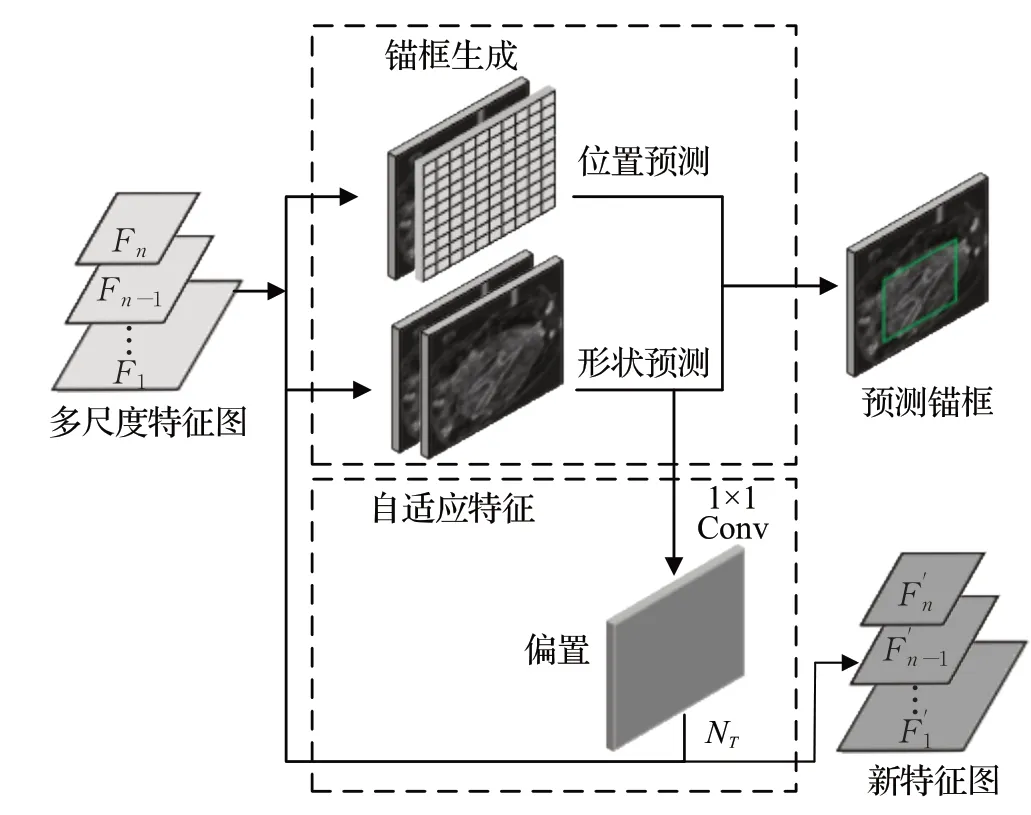
图7 MGA-RPN模块结构Fig.7 MGA-RPN module structure
(1)锚框生成模块的作用是得到高质量的锚框。从输入特征图Fi中提取相关语义信息,通过位置预测网络区分目标与背景,生成目标中心位置的概率p(i,j|Fi);形状预测网络会输出每个预测中心的最佳锚框尺寸比例(dw,dh)∈[-1,1];最后通过公式(9)转换得到最终的锚框尺寸。
公式中σ为锚框的预设尺度系数,初始化值为8,s为步长,dw和dh为形状预测网络的输出值,w和h为转换后准确的锚框尺寸宽高值。
(2)自适应特征模块的作用是生成适配锚框大小感受野的特征图。由于常规进行预设锚框的操作导致网络对每层特征提取的步骤是一致的,所以感受野是固定的,而本文的锚框是语义指导生成的,其感受野大小是不固定的,因此需要对原来的特征图进行感受野适配。主要过程是利用上一个模块中形状预测网络生成的锚框宽和高,经过一个1×1 的卷积得到一个偏移量,并将其送入一个3×3 的可形变卷积即可获得适配所需大小感受野后的特征图。其公式如下:
式中,fi是第i个特征图,(wi,hi)是对应目标的锚框形状,NT是为一个3×3 的可形变卷积,f′i是适配锚框大小感受野后的特征图。
1.4 嵌入OHEM的级联检测头
X光安检违禁品检测中,违禁品的数量相对于其他正常物品的仅占很少的一部分,并且一些类别的训练样本也属于小样本,存在违禁目标与背景的正负样本不均衡问题。为了让一部分小样本的违禁品类别得到高效地利用,在检测头中嵌入OHEM模块,训练过程中挖掘困难样本进行反向传播更新网络参数,使模型检测准确度得到进一步提升。
OHEM 是一种能够解决网络模型正负样本不平衡问题的训练策略,在训练过程中自动筛选出难以识别的样本重新送入网络中进行反复训练,其基本原理结构如图8 所示。网络先获取检测头中N个RoI 计算的分类损失值和回归损失值,之后分别对这些损失值进行求和排序,再通过非极大值抑制算法(non-maximum suppression,NMS)[24]去除IoU大于一定阈值的RoI,最后筛选出前B个损失值最大的RoI 作为难例样本进行反向传播更新参数。
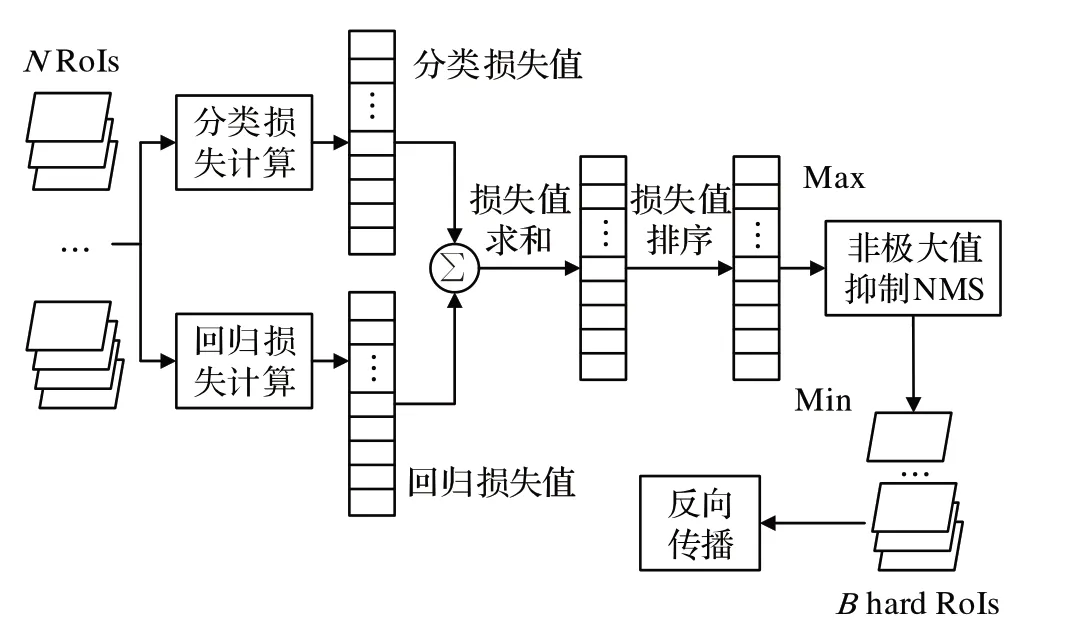
图8 OHEM原理图Fig.8 OHEM schematic diagram
2 实验与结果分析
2.1 数据集的处理与分析
该领域的研究人员大多使用的是自制作数据集,由于安检图像涉及隐私安全等问题,所以公开的X光安检图像数量较少。目前已知的该领域的相关公开数据集有GDXray[25]、OPIXray[26]和SIXray[27]。SIXray 数据集由1 059 231张X光行李图像组成,SIXray数据集的主要用于图像分类任务,包含了大量没有违禁物品的图像,所以不能直接用于目标检测任务,需要对该数据集进行处理。
本文在SIXray 数据集的基础上制作了用于违禁物品检测的数据集SIXray_PI。从SIXray数据集中筛选出包含违禁物品的图像有8 909 张,违禁物品由Gun、Knife、Wrench、Pliers、Scissors 五类组成,各类的图片分布情况如图9所示。
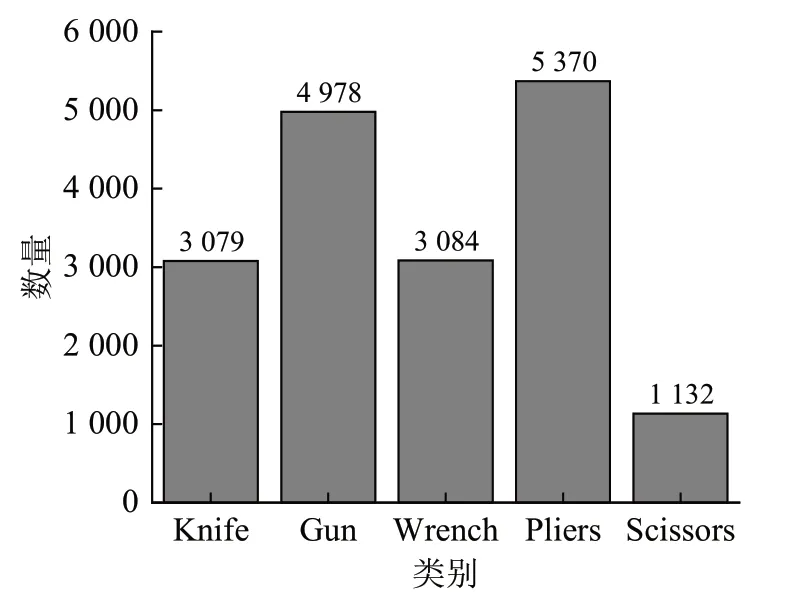
图9 SIXray_PI数据集分布情况Fig.9 SIXray_PI dataset distribution
最终将所有图像按照8∶1∶1随机划分训练集、验证集和测试集。
2.2 实验环境与训练策略
本文实验环境:操作系统为Ubuntu20.04,CPU 为i7-9700K,内存16 GB,显卡为NVIDIA RTX 2080Super。Python 3.8 和Pytorch 1.9,训练框架为MMDetention 2.26[28]。训练策略与参数如表1所示。

表1 实验相关参数设定Table 1 Experiment related parameter setting
2.3 评估指标
准确率(Precision)是衡量查准率的指标,统计的是在所有正样本中正确目标所占比例;召回率(Recall)是衡量查全率的指标,统计的是所有真实目标中被网络模型检测中的目标所占比例。其公式[29]为:
式中,TP表示类别判断正确的预测框数量,FP表示错将其他类预测为本类的预测框数量,FN表示错将本类预测为其他类的预测框数量。
而现实中准确率和召回率往往是难以兼得的,因此在目标检测中的主要评价指标为平均精度值(average precision,AP),它是由准确率和召回率绘制的P-R曲线下的面积得到的,其公式为:
在N个类别目标检测中则使用多类平均精度均值(mean average precision,mAP)作为评价指标,其公式为:
2.4 消融实验
2.4.1 引入DCN有效性验证实验
为了验证本文引入DCN 的有效性,进行该模块的对比实验,比较参数量、mAP50和AR100三个评价指标。结果如表2所示。

表2 DCN对算法性能影响对比Table 2 Comparison of DCN impact on algorithm performance
通过表2 分析可知,引入DCN 后,参数量增加了0.58 MB,mAP50提升了0.1个百分点,AR100提升了0.9个百分点。本文针对浅层特征图提取过程采用了DCN网络,使得网络整体对目标的定位信息提取更加准确,因此获得了AR100的较大提升。
为了进一步验证引入DCN 的有效性,将ResNet50骨干网络提取的浅层特征图进行可视化,可视化效果图如图10 所示。通过该可视化图分析可知,可形变卷积使网络更适配目标形状,强化了Knife 目标的边缘定位信息,为后续深层次网络的特征提取剔除了更多的噪声干扰,证明了本文使用可形变卷积替代普通卷积的有效性。

图10 浅层特征图可视化对比Fig.10 Comparison of shallow feature map visualization
2.4.2 SAAM模块
为了验证本文提出的SAAM 模块的有效性与优越性,将其与CBAM[30]和Self-Attention[31]两种主流的空间注意力模块进行对比实验,比较mAP50、AR100、参数量和GFLOPs四个评价指标,结果如表3所示。
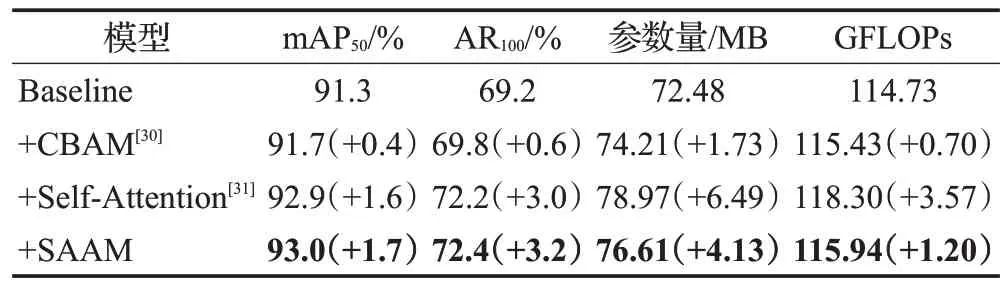
表3 SAAM模块对算法性能影响对比Table 3 Comparison of SAAM module impact on algorithm performance
通过表3分析可知,SAAM模块在各个指标上都取得了最优值。相比Self-Attention 参数减少了2.36 MB,计算量减少了2.36 GFLOPs,mAP50和AR100却都有提升。相比CBAM参数量和计算量有所增加,但是mAP50提升了1.3 个百分点。相比未采用此模块的网络,参数量增加了4.13 MB,计算量增加了1.2 GFLOPs,mAP50提升了1.7个百分点,AR100提升了3.2个百分点。
进一步分析该模块对复杂背景噪音抑制能力与自适应性能力,使用Grad-CAM(gradient-weighted class activation MAP)[32]进行网络关注度可视化,可视化对比结果如图11 所示。图11 中右侧含有一个Pilers 类违禁物品,被大量其他物品所覆盖,可以作为一个复杂背景实验样本。从图11 可以看出,由于CBAM 只能获取局部感受野,其对背景噪音的抑制能力最差,从而导致网络对目标的关注度不高。Self-Attention进行全局计算,能够抑制复杂背景中大部分的噪音干扰。与其他两种注意力相比,SAAM模块抑制复杂背景噪音干扰的能力最强。并且该注意力模块使用偏移网络自动学习卷积偏移量,使感受野覆盖范围更符合违禁目标大小,模型的自适应性能力更强,证明了本文提出的SAAM模块的有效性。

图11 可视化热力对比图Fig.11 Visualized thermal comparison chart
2.4.3 MGA-RPN模块
(1)候选框定性分析
将RPN与MGA-RPN网络中的锚框可视化,从图12可以看出,RPN 的锚框初始值来自于人工设定,对目标的匹配度较低。MGA-RPN的锚框更集中于违禁品目标,为后续的RCNN网络提供了高质量的正样本候选框。
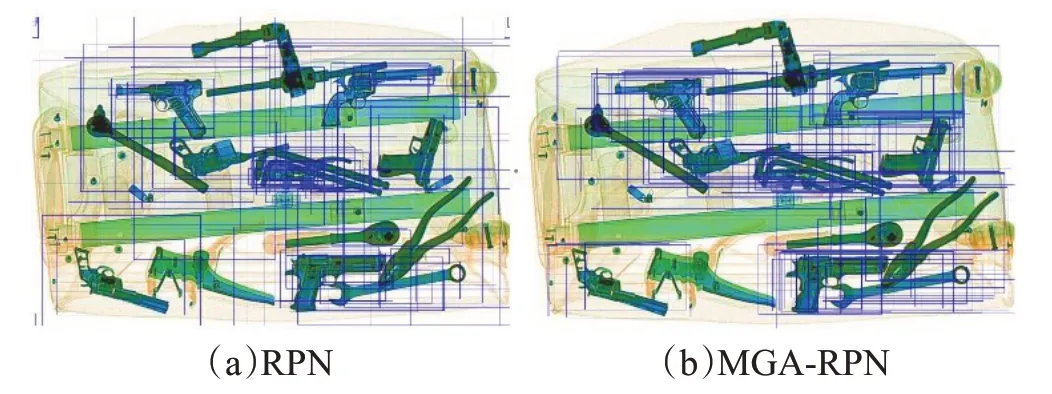
图12 候选框可视化对比图Fig.12 Candidate frame visualization comparison chart
(2)特征图定性分析
对MGA-RPN适配的4层特征图可视化,从图13可以看出,MGA-RPN 根据生成的锚框适配特征图后,每层的感受野更加符合不同违禁目标的尺寸,为后续分类检测网络提供了高质量的特征图。
(3)定量分析
从参数量、mAP50和AR100三个评价指标进行定量分析实验。实验结果如表4 所示。分析表4 可知,引入MGA-RPN 模块后,参数量增加了0.36 MB,mAP50提升了1.1 个百分点,而AR100提升了1.9 个百分点。经分析认为,MGA-RPN模块根据输入特征图含有的语义信息自适应生成了更准确的锚框,以及针对生成的锚框进行适配特征图,从而给网络模型带来了较大的召回率提升,进而提高了网络的准确率。

表4 MGA-RPN模块对算法性能影响对比Table 4 Comparison of MGA-RPN module impact on algorithm performance
2.4.4 嵌入OHEM模块的有效性实验
如表5,在级联检测器中嵌入OHEM模块能够解决目标与背景的不均衡问题,不同阈值下的平均检测精度都有提高,最高达到1.2个百分点的提升效果。

表5 OHEM模块对算法性能影响Table 5 Impact of OHEM modules on algorithm performance
为了更具体分析OHEM模块对小样本scissors类别的提升效果,在IoU=0.5和IoU=[0.5:0.95]两个不同阈值下的对比平均准确度,结果如图14所示。
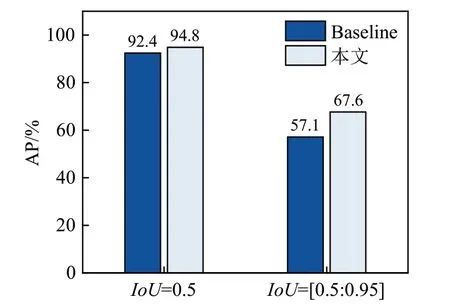
图14 小样本scissors检测准确率对比图Fig.14 Comparison of accuracy of scissors test for small samples
小样本目标由于数量较少导致网络无法进行大规模训练为其更新参数,容易被模型判定为难以训练的困难样本。OHEM 可以在训练过程中自动筛选出困难样本重新送入网络中进行反复训练,使得小样本目标在训练过程中被反复利用,从而达到对小样本精度有效提升效果。如图14,在IoU=0.5 的阈值下,在训练过程中会有较多的样本被判定为正样本,所以OHEM 提升效果不是特别明显。而在IoU=[0.5∶0.95]的时候,小样本目标的不充分训练导致被判定为困难样本的数量增加,OHEM 能够挖掘这些困难样本进行反向传播更新网络参数,使得检测精度有较大的提升。
2.5 对比实验
2.5.1 XPIC R-CNN与基准算法的对比实验
(1)定量分析
使用不同阈值下的mAP 和AR 评价指标进行定量分析,结果如表6所示。分析表6中数据可知,本文方法在mAP50、mAP75、mAP50∶95和AR100分别提升了3.2、7.7、6.4和8.2个百分点,证明本文改进算法的有效性。

表6 XPIC R-CNN与基准算法的对比结果Table 6 Results of XPIC R-CNN compared to baseline
(2)复杂度与性能分析
为了探究不同模块对本文方法性能的影响,使用参数量(parameters)和浮点运算量(floating point of operations,FLOPs)两个指标与衡量网络模型的复杂度。参数量是网络模型训练过程中需要更新的权重与偏置数量,属于空间复杂度的范畴。FLOPs是模型的计算量,属于时间复杂度的范畴。以输入图像尺寸为640×640 进行实验,不同模块对模型的性能影响结果如表7所示。

表7 XPIC R-CNN与基准算法的对比结果Table 7 Results of XPIC R-CNN compared to baseline
通过表7 分析可知,影响模型参数量最大的是SAAM模块,由于此模块需要对所有目标进行注意力计算,所以给模型带来了4.13 MB 的参数量增加,但是只增加了1.21 GFLOPs的计算量,符合设计时减少计算量的预期。影响模型计算量最大的是MGA-RPN模块,因为此模块会使用4个不同尺度的特征图进行计算生成锚框,所以给模型带来了1.94 GFLOPs计算量的增加。而OHEM 模块只会在训练过程中进行挖掘困难样本反向传播更新模型参数,并不会额外增加参数量与计算量。
(3)P-R图分析
在召回率R取值为{0,0.01,0.02,…,1}时,采用插值方法算出对应的准确度P,绘出P-R对比图15。P-R曲线所围成的面积代表对应目标的平均检测精度,从图15对比可知,本文算法的在各类曲线在相同的召回率R下,准确度P均高于基准网络,进一步证明了本文算法改进的有效性。
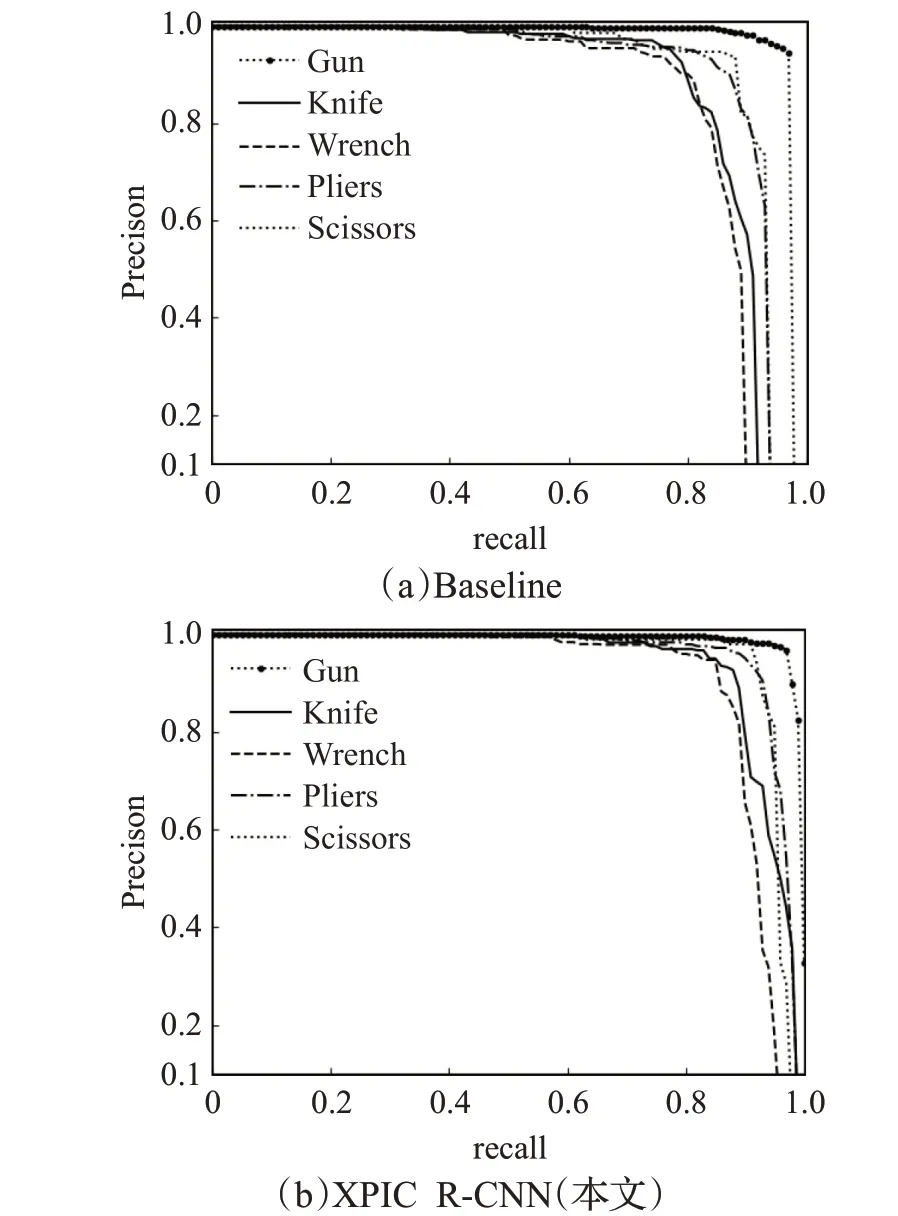
图15 各类别P-R曲线对比图Fig.15 P-R curve comparison chart of various classes
(4)混淆矩阵
为了探究本文算法的误检和漏检情况,绘制的混淆矩阵结果如图16 所示。通过分析可知,Gun 拥有0误检率和1%的漏检率;Knife 最高只有3%的概率被误检为Wrench,Pliers 只有2%的概率被误检为Wrench;Scissors 只有2%的概率被误检为Knife;误检最高的Wrench 也只有5%的概率被识别为Pliers;漏检率最高的Wrench 仅有10%,本文算法满足高准确率和低误检率的目标。

图16 混淆矩阵Fig.16 Confusion matrix
(5)不同形态的违禁品检测能力分析
将本文方法与Baseline 在不同尺度上的检测能力进行定量对比分析,实验结果如表8所示。小目标和中大目标的检测能力分别提升了3.2、5.5和6.1个百分点,分析认为不同形态目标精度提升的原因有以下三点:一是可形变卷积提供了更加适配的感受野,二是空间自适应注意力对背景噪音的强抑制能力,三是MGA-RPN提供了更高质量的候选框。

表8 不同形态违禁品检测结果Table 8 Results for different forms of contraband
再选取不同场景下具有不同形态目标的图片进行定性对比分析。从图17对比照片看出本文XPIC R-CNN网络模型能够更加准确地检测X光图像中的违禁物品。在密集场景和遮挡场景对比图中存在形态各异的违禁物品,本文模型能够检测出更多的违禁物品;在小目标对比图可以看出本文模型能够准确地识别出小目标违禁品,直观地验证了本文算法对不同形态目标检测性能提升的有效性。

图17 检测效果对比图Fig.17 Comparison chart of detection effect
2.5.2 主流算法对比实验
本文选取RetinaNet50[33]、SSD、YOLOv3、YOLOv5、Faster RCNN、Cascade RCNN 两篇最新的相关文献方法进行对比实验。RetinaNet50 通过引入Focal Loss 缓解了正负样本不均衡问题,极大提高了网络模型的性能;SSD 是截至目前主流的目标检测框架之一,精度接近Faster RCNN,速度接近YOLO 的高性能检测器;YOLOv3是目前工业界常用的检测算法,是一款性能与速度十分均衡的检测器;YOLOv5则是如今最流行的单阶段检测算法之一;Faster RCNN 是两阶段检测网络的代表之一,引入了RPN 网络极大提高了网络检测性能,Cascade RCNN 为本文的基准算法。文献[34]是在YOLOv5 的基础上加入空间坐标注意力增强特征提取能力,并将特征编码展平为一维向量利用自监督二阶融合得到全局上下文信息。文献[35]是在YOLOv7 的基础上融合高效注意力机制提高深层网络的特征提取能力,采用跳跃连接等方法丰富特征融合后的信息,最后采用密集编码对旋转角度进行离散化处理提高定位准确度。
将上述模型进行同一个实验环境进行对比实验,实验结果如表9 所示。可以发现,本文提出的网络模型mAP 值均超过其他网络模型,计算量和参数量些许偏高。证明了本文检测模型在安检违禁品检测中的优越性。
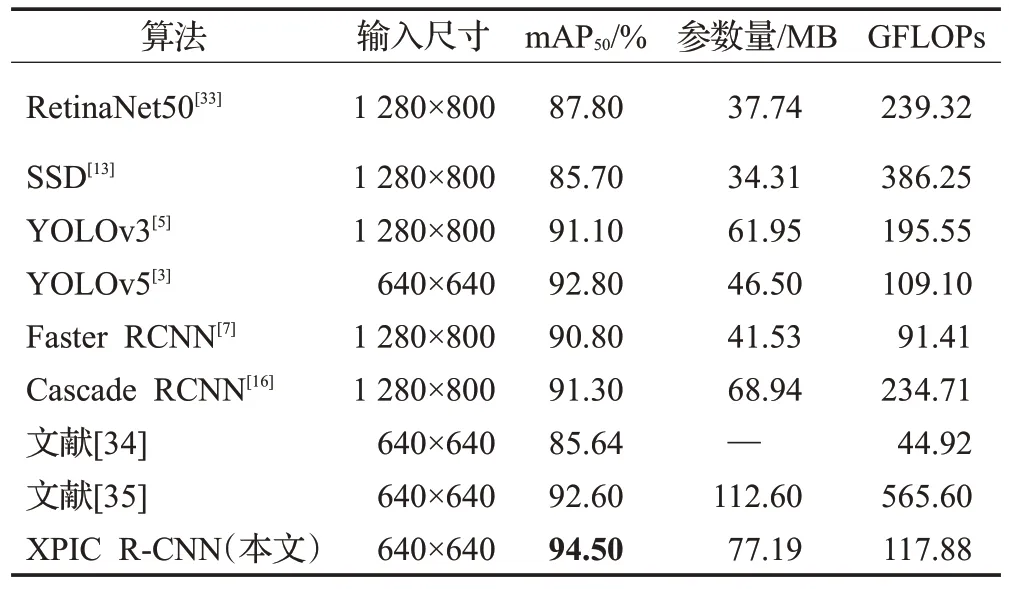
表9 本文模型与主流模型实验对比结果Table 9 Experimental comparison results between our model and mainstream model
3 结束语
本文针对现阶段的X 光违禁物品检测研究准确率低和存在漏检问题,基于Cascade R-CNN网络架构,提出一个融合空间注意力的自适应安检违禁品检测方法XPIC R-CNN。在主干网络ResNet50 中使用可形变卷积替换普通卷积增加不同尺度的感受野,空间自适应注意力模块抑制复杂背景噪声的干扰;MGA-RPN模块生成高质量锚框和特征图;最后在级联检测器中嵌入OHEM 提升困难样本与小样本目标的检测精度。实验结果表明,本文所提出的检测模型平均精度能达到94.5%,最高漏检率仅有10%,满足高精度和低漏检的要求。由于采用了两阶段模型架构,导致算法运算量较大实时性不高。因此,后续工作将重点针对实时性问题进行深入探究。
猜你喜欢
法制博览(2023年9期)2023-10-05
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
北京航空航天大学学报(2021年9期)2021-11-02
哈尔滨学院学报(2020年7期)2020-01-19
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
职工法律天地(2016年20期)2016-01-31
