
基于众包校正的多源融合室内定位算法
2023-12-08 08:39赵逢达孙己正李贤善章蓬伟刘付勇潘芳芳
燕山大学学报 2023年6期
赵逢达,孙己正,李贤善,3,章蓬伟,刘付勇,潘芳芳
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.新疆科技学院 信息科学与工程学院,新疆 库尔勒 841000;3.河北省软件工程重点实验室,河北 秦皇岛 066004)
0 引言
近年来,疫情筛查、消防救援、商场营销等诸多面向室内的位置服务需求呈大幅增长态势,使得室内定位成为当下的研究热点之一[1]。室内环境下,受到建筑墙体的阻隔,北斗和全球定位系统的定位效果较差[2]。为了解决这一问题,大量的研究人员将Wi-Fi 和蓝牙作为代替卫星的定位信号源。
在定位方法中,部分研究是基于Wi-Fi 接收信号强度指示(Received Signal Strength Indicator,RSSI)定位技术展开的[3]。通过构造指纹数据库的方式进行定位是一类常见的定位方法,例如将K 近邻(K-Nearest Neighbors,KNN)[4]、随机森林[5]等算法应用在定位中。在室内静态环境下,这些算法成本低、易实现、精度较高,但复杂多变的室内环境导致RSSI 浮动较大,并且维护动态变化的指纹库会产生较高的成本。Bai 等[6]将定位过程分为了位置匹配和位置过滤两个部分,此方法在UJIIndoorLoc 数据集上得到了较好的表现。尽管文献[6]中的方法在个体用户定位上获得了不错的效果,但由于部分用户在数据收集时会受到环境的影响,因此这些用户的定位精度会出现较大的下降。为了解决这一问题,本文利用众包思想,在完成粗定位后,使用聚类的方法筛选出了精度较高的用户,并利用精度较高的用户对精度较低的用户进行校正。
文献[7-8]将Wi-Fi 的RSSI 和蓝牙的RSSI 进行融合处理。Gan 等[7]将Wi-Fi 的RSSI、蓝牙的RSSI 以及传感器数据这三种信息归一化处理,并将处理后的数据作为深度网络的输入,相比于单独使用三种信源,此方法可以有效提高定位精度。但该方法没有发挥出蓝牙RSSI 在短距离下浮动较小、定位精度高的优势。类似的解决方案都需要大量的人力物力在环境中部署蓝牙信标,而且受到其部署位置的限制,无法达到灵活使用蓝牙数据的效果。Ta 等[8]没有设定固定的蓝牙信标,而是利用用户组内的蓝牙通信来计算用户之间的距离,通过结合时域方法和非时域方法提高了定位精度,此方法可以同时计算出一个用户组中所有用户的位置,用户组之间没有交集,这样容易忽视处于不同用户组但距离相近的用户信息。为了解决这一问题,本文所提出的算法设定为:每个用户均对应一个用户组。各用户组之间的信息不完全相同,这样保证不同的用户可以使用对自己最有效的定位信息。
综上,结合Wi-Fi 覆盖面积大和蓝牙短距离精度高的特点,本文提出基于众包校正的多源融合室内定位算法(Multi-sensor fusion indoor positioning algorithm based on crowdsourcing correction,MFCC)来提高定位精度。该算法在获得粗略位置和用户间距离后,利用众包思想,计算出距离每个目标用户最近的用户组,对于每个特定的用户组使用K 均值(K-means)算法将离群用户筛选出,并将离群用户的粗定位位置校正为用户组质心位置与粗定位位置的加权和,由此得到校正后的用户组位置。利用校正的目标用户与其用户组之间的蓝牙距离和位置信息构建虚拟空间指纹,并使用KNN 算法进行虚拟空间校正,最后得到用户的位置坐标。本文贡献如下:
1)提出了一种适用于多种定位算法的校正方法,并通过实验证明了校正方法的可行性,此方法可以将多种定位算法的定位精度提升23.0%~31.3%。
2)提出了基于众包校正的多源融合室内定位算法,该算法在UJIIndoorLoc 数据集上可以将误差降至4.96 m。
1 相关工作
基于Wi-Fi RSSI 的室内定位算法分为基于损耗模型的算法[9-11]、基于指纹库的算法[4-5,12]和基于决策的算法[13]三类。基于损耗模型的算法大多是根据室内电波传播损耗模型和路径损耗模型实现的。此类算法在离线阶段对RSSI 首先进行滤波处理,再对数据进行拟合求得适合当前情况的损耗模型。在线阶段将强度值代入模型中得到对应的距离,根据三边/多边测量原理,将问题转化为高斯-牛顿迭代法、正规方程等方式求解非线性最小二乘法的问题。但由于RSSI 的噪声对回归算法影响很大,所以基于损耗模型的算法在实际使用时会产生较大误差。基于指纹库的算法也是使用较多的一类算法,这类算法通常在离线阶段将定位空间按照某种精度划分成网格,同一网格中的所有点都划归为一类,由此建立一个庞大的指纹数据库。在线阶段使用KNN[4]、随机森林[5]、支持向量机[12]等方法进行位置的预测。一般情况下此种方式的定位精度受采集精度和指纹库大小的影响,并且在环境发生变化后,需要消耗大量的人力重新采集创建指纹库。基于决策的算法不同于前述两种算法,它将定位过程看成是一系列的动作行为,通过一个动作序列将位置推算出来。例如Dou 等[13]使用了深度强化学习的方法,利用二分的思想,在可控的精度范围内进行定位,此种方法在实际定位时可以达到较好的定位精度。
除了Wi-Fi,蓝牙也常被用于定位中[14-16]。蓝牙既可以工作在一对一配对模式下,也可以工作在一对多广播模式中。文献[16]提出了结合蓝牙RSSI 和飞行时间两种数据的方法,该方法中两种不同的数据可以优势互补,以此来提高定位精度。但市场上大部分设备还不具备高精度测量飞行时间的传感器模块,因此这种方法难以付诸实践。同时由于蓝牙通信距离的限制,单独使用蓝牙进行定位需要在环境中部署大量的信标,这无疑增加了定位实施的复杂度和困难。
Wi-Fi 和蓝牙融合定位算法中,薛伟等[17]使用了堆叠自动编码机对数据进行训练并从中提取特征,构建位置指纹数据库。该方法减少了RSSI 中噪声对定位结果的影响,提高了定位精度。曹鸿基等[18]通过计算Wi-Fi 与蓝牙两个定位结果的坐标间距,判断是否存在异常定位结果,最后对两个定位结果进行加权处理得到最终位置,该方法较单信号源方法提高了定位精度。Tian 等[19]通过启发式差分进化算法来优化无线访问节点(Access Point,AP)和蓝牙低功耗(Bluetooth Low Energy,BLE)信标放置问题,随后使用KNN 算法实现定位功能,该方法有效地提高了定位精度。与上述算法不同的是,本文并未通过设定静态蓝牙信标来计算蓝牙单源下的定位结果,而是通过环境中用户之间的蓝牙通信对已有的Wi-Fi 定位结果进行校正。
对于多用户定位而言,何荣毅等[20]提出了基于距离的多用户协同定位方法,但该算法无法区分定位结果的精度,由此带来了校正后精度降低的风险。本文提出的MFCC 算法考虑了蓝牙通信的距离限制,通过设定阈值的方法提高了加入用户组中用户信息的准确性。另外,本文利用众包思想,通过聚类校正和虚拟空间校正的方法提高了用户组整体的定位精度。
2 M FCC 算法
2.1 算法概述
本文提出的基于众包校正的多源融合室内定位算法分为离线阶段和在线阶段,如图1 所示。
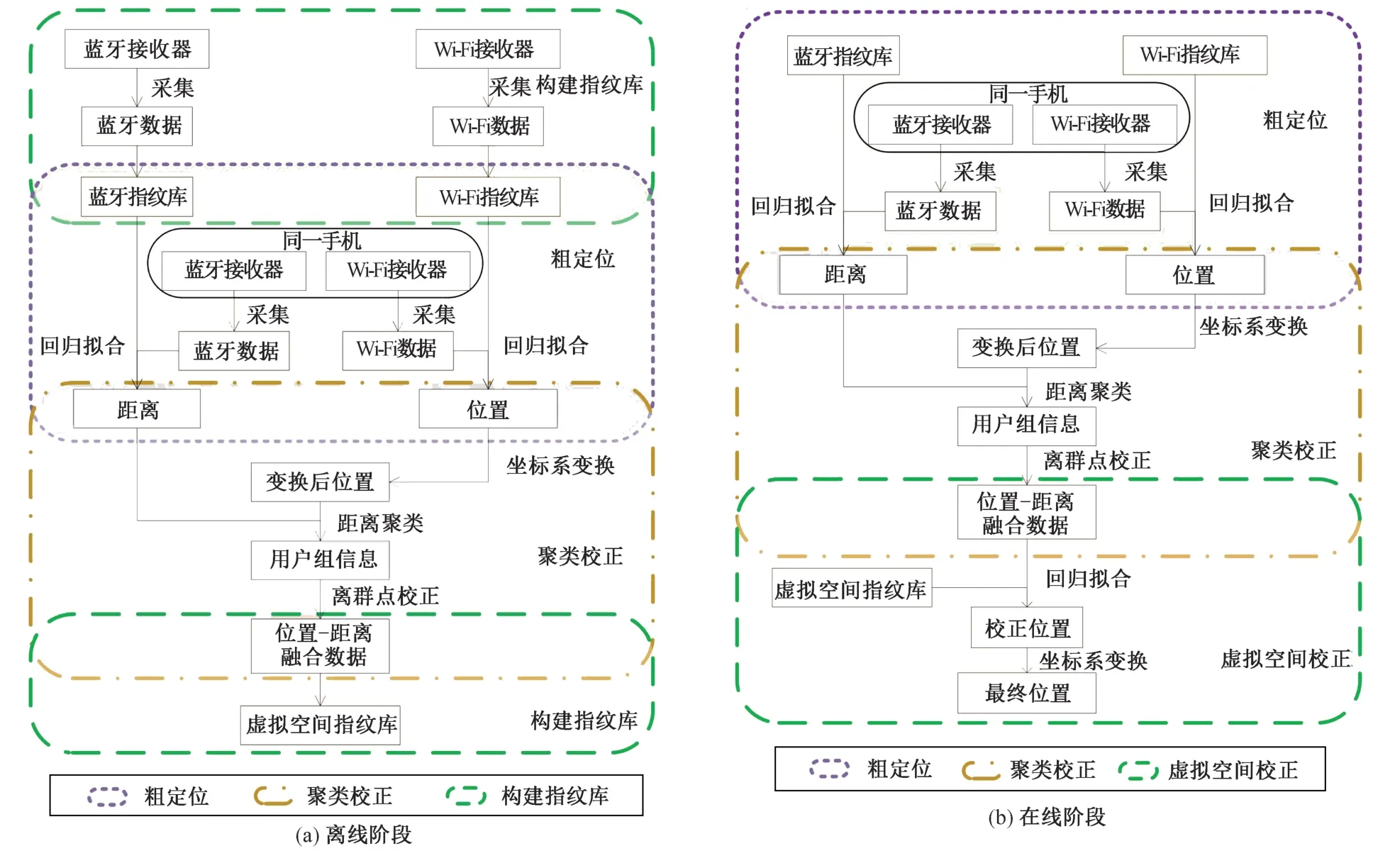
图1 MFCC 算法框架Fig.1 Framework of the MFCC
离线阶段的任务是构建Wi-Fi 指纹库、构建蓝牙指纹库、粗定位、聚类校正和构建虚拟空间指纹库,如图1(a)所示。虚拟空间是根据不同用户组进行坐标系转换后的空间,这是为了将用户组内常见的位置分布信息用于校正。
在线阶段的任务是粗定位和众包校正,如图1(b)所示。它首先通过带权值的 K 近邻算法(Weighted K-Nearest Neighbors,WKNN)和K 近邻算法得到用户的粗略位置和用户间距离。根据用户间的距离可以得到距离当前用户最近的用户组。本文中根据蓝牙RSSI 计算出的距离被称为蓝牙距离,一个用户组中蓝牙距离超出某个阈值的所有用户称为离群用户,其他用户称为聚群用户。在用户组中,用聚群用户的位置来校正离群用户的位置。在聚类校正后,将组内成员坐标进行坐标系转换,得到虚拟空间的位置信息,然后将所得到的位置信息利用虚拟空间校正进行求解,得到虚拟空间校正定位。最后将虚拟空间中的坐标映射回原空间,由此得到最终的定位结果。
2.2 构建W i-Fi 指纹库与蓝牙指纹库
粗定位的客户端以智能手机为例,拟定环境中有n位持有智能手机的用户,m个AP,则在每一个扫描周期T,每一台智能手机需要向服务器发送自己的MAC 地址和获取到的m个AP 的RSSI以及各个AP 对应的MAC 地址,以第i位用户为例,其向服务器发送数据的格式为〈MACphonei,(MACAPj,RSSIi,APj)〉,其中j∈[1,m]。
同时,通过扫描周围智能手机的蓝牙RSSI,将结果发送至服务器,格式为〈MACphonei,(MACphonek,RSSIi,BLEk)〉,其中k≠i,MACphonei表示第i位用户的智能手机的MAC 地址,MACAPj表示第j个AP 的MAC 地址,RSSIi,APj表示第i位用户接收到的第j个AP 的RSSI。RSSIi,BLEk表示第i位用户接收到第k位用户的智能手机发出的蓝牙RSSI。为方便表示,将用户和用户的智能手机统称为用户。数据传输框架如图2 所示。
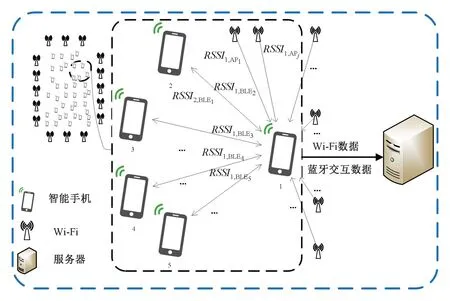
图2 数据传输框架Fig.2 Data transmission framework
在服务器端,首先创建Wi-Fi 指纹库,将参考点的位置坐标和各AP 的MAC 地址及其RSSI 值作为一条指纹存入指纹库。在第i个参考点上的一条指纹FPi为
式中,pi=(xi,yi)为第i个参考点的坐标。将所有参考点的指纹存入指纹库,创建Wi-Fi 指纹库。
在完成Wi-Fi 指纹库的创建后,下一步创建蓝牙指纹库。由于蓝牙的有效通信距离较短,并且当距离超过3 m 后,RSSI 会出现较大浮动,本文借助这一特性,通过RSSI 计算用户组中的各个用户之间的蓝牙距离,并将其作为用户组的划分标准。
由于蓝牙的RSSI 在实际传播中存在多种因素带来的噪声干扰,噪声干扰对蓝牙的损耗模型影响较大,故此处仍选用指纹法。蓝牙指纹库中第i条指纹表示为
其含义为当发射设备与接收设备距离为DBLEi时,接收设备所接收到的RSSI 为RSSIBLEi。
2.3 粗定位
粗定位阶段,假设用户S在任意待测点检测到的AP 信息fS为
其中,RSSIS,APj表示用户S接收到的第j个AP 的RSSI。用户S与第i条Wi-Fi 指纹FPi的欧氏距离dSi为
该距离越小代表S与第i个指纹点的距离越近,反之越远。取k个与S最近的指纹点,对这些指纹点设置权重为距离的倒数比,则用户S的粗定位位置为
将用户S的粗定位结果记录为〈MACphoneS,〉,其中MACphoneS表示用户S的MAC 地址。其余n-1位用户的粗定位结果记录为{〈MACphonej,〉 |j∈[1,n],j≠S}。下面计算用户S与其他用户之间的距离。
假设用户S接收到用户U的一条蓝牙RSSI为RSSIS,BLEU,则其与蓝牙指纹库中第i条指纹的距离为|RSSIS,BLEU-RSSIBLEi|。取最近的k条指纹,此处k与Wi-Fi RSSI 处的k没有关系,则由RSSIS,BLEU计算得到的蓝牙距离dS,U为
用户S与n-1 位用户之间的蓝牙距离数组DS为
其中,dS,j为根据用户S根据接收到第j位用户发射的蓝牙RSSI 计算得到的蓝牙距离,在实际测量中,等式dS,j=dj,S不恒成立。至此粗定位部分全部完成,下面进行校正部分。
2.4 聚类校正
MFCC 算法中校正分为聚类校正和虚拟空间校正。在聚类校正中,首先要根据粗定位得到的位置信息和距离信息计算出用户组G,然后将用户组G拆分为离群用户GO和聚群用户GI,最后用GI的定位结果来校正GO的定位结果。
具体地,根据蓝牙距离数组DS,找出距离最小的n′位用户,将这些用户和用户S定义为一个用户组G。在用户组G中,离群用户和聚群用户的计算标准为:令用户i到当前用户组中其他用户的总距离为,离群用户GO为
聚群用户为GI=G-GO。假定环境中有5 个用户,其中用户4 为定位中的离群用户,聚类校正的过程如图3 所示。

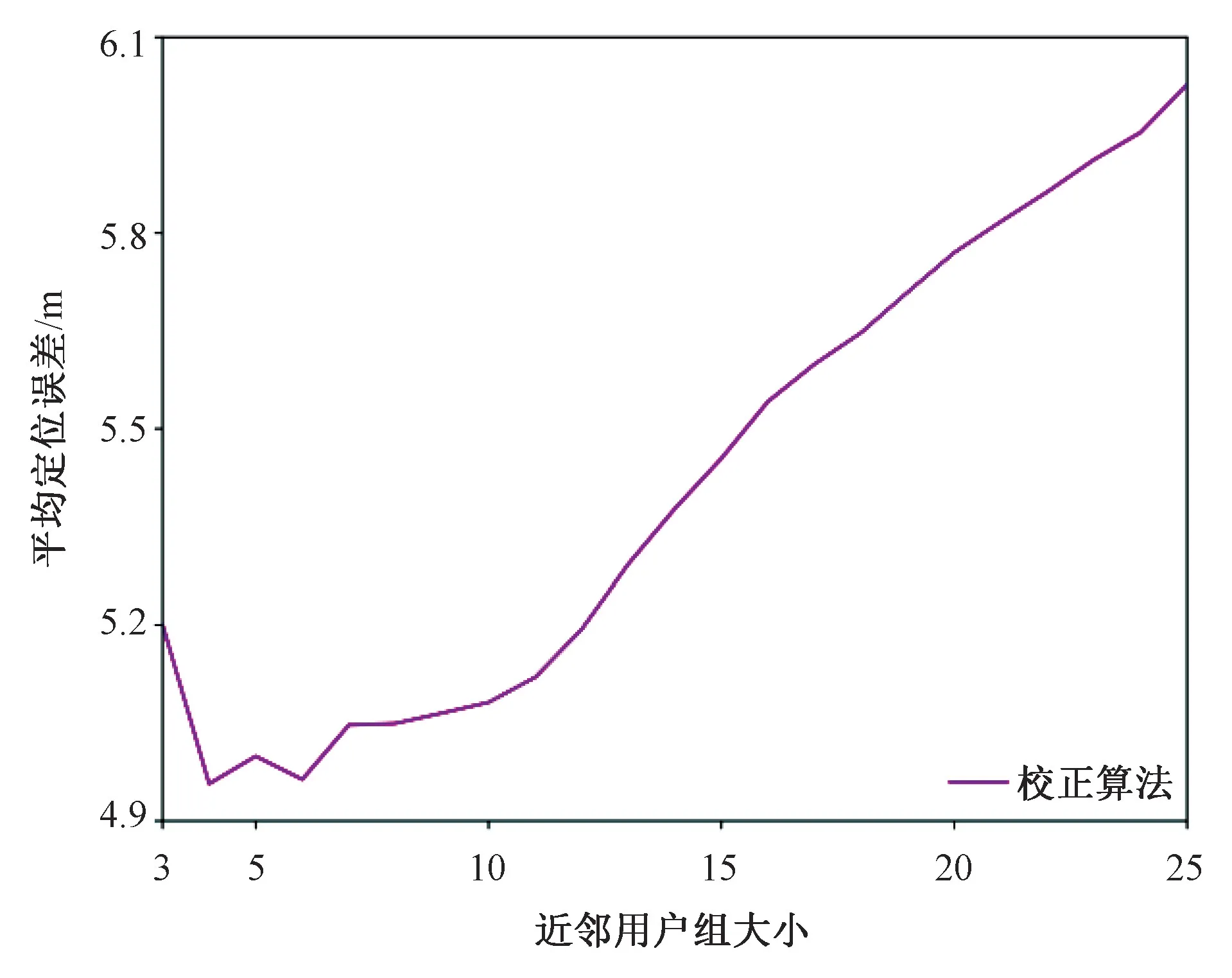
图3 用户组大小设置为4 的聚类校正Fig.3 Cluster correction with the population size 4
其中,δ为粗定位误差的标准差。为方便计算,将坐标系进行变换,令(xS,yS)=(0,0),则粗定位位置坐标,有
可令用户S的粗定位位置与真实位置的误差距离为
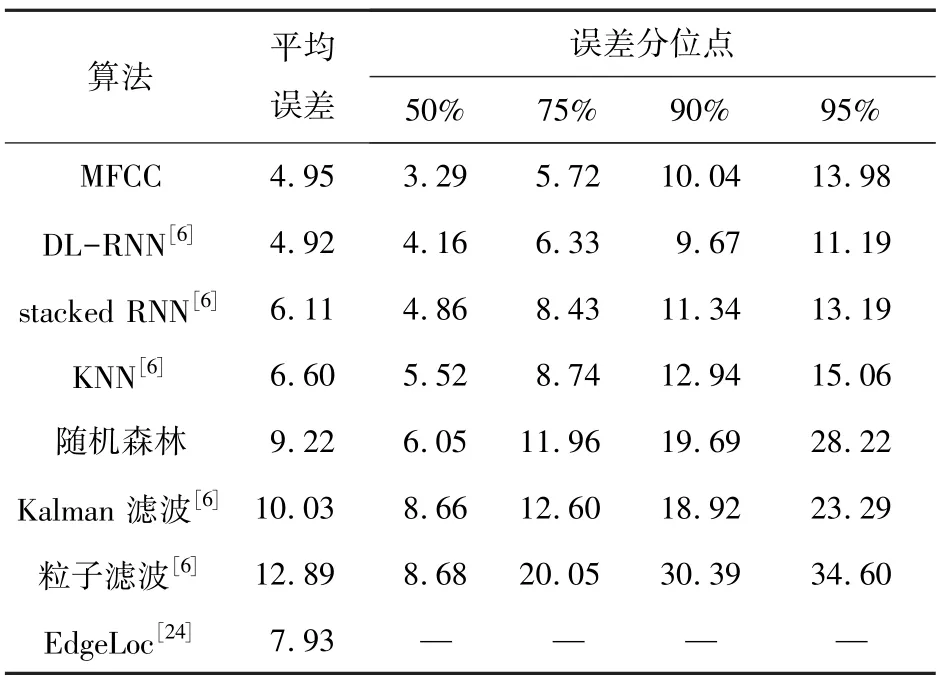
即在一个用户组中,高于半数的定位误差低于平均误差。本文选择使用用户组中低误差结果来校正高误差结果,即使用聚群用户的定位结果来校正离群用户的定位结果,聚群用户占用户组的比例为P(χ2 令n′个用户的真实位置为{pS,1,…,pS,n′}⊂{p1,…,pn},pS,j=(xS,j,yS,j)表示距离用户S第j近的用户位置,有关系如下: 式中,dmax是为区分用户组与组外用户而设置的距离阈值。 根据式(8)可得此时聚群用户组为GI,离群用户组为GO,GI大小为lI,由式(14) 可知lI∈n′·[0.5,P(χ2 由式(17)可知,{pS,0,pS,1,…,pS,n′}与pS的距离均小于dmax,则GI的真实位置与OS的距离小于dmax。由式(18)的结论可知,GI的粗定位位置与的距离应小于dmax,此时距离大于等于dmax的用户可视为离群用户。 若距离S第j近的用户属于离群用户,则其校正后的坐标为代表以为起始位置,为终点方向,距离为α的位置作为校正位置,α的值可根据实验场景进行设置。 聚类校正算法描述如算法1 所示。 算法1聚类校正 在上述算法描述中,步骤(5)为核心步骤,用于区分GI和GO,具体地,需要计算用户组内两两之间的距离,因此聚类校正算法的时间复杂度为O(n′2)。 经聚类校正后,用户S可以得到一组形如的数组。第一个数组为离线阶段所得,第二个数组为在线阶段所得,其中是用户S校正后,距离S第j近的用户坐标。智能手机之间的最大有效通信距离为rmax,因此dmax≤rmax,因此在实际中,{pS,0,pS,1,…,pS,n′}分布在圆心为OS最大半径为rmax的圆形范围内。利用上文中的中心坐标^OS,以离线阶段为例,将用户组的聚类校正位置平移至圆形范围中,即将(,…,)线性变换为坐标系原点为的圆形范围被定义为虚拟空间。虚拟空间内的校正工作不受真实空间坐标的影响,真实空间的坐标与虚拟空间的坐标一一对应,对应关系为 假设对于某点S的用户组的定位信息为 则S到第i条虚拟空间指纹的距离为 虚拟空间校正算法描述如如算法2 所示。 算法2虚拟空间校正 在上述算法描述中,步骤(3)用于在指纹库中进行位置匹配,当虚拟空间指纹库大小为nv时,虚拟空间校正算法的时间复杂度为O(nv)。 本文设计实验对MFCC 算法进行了性能评估。实验中的 Wi-Fi 数据来自公共数据集UJIIndoorLoc[21]和IPIN2017[22-23]数据集中CAR 建筑物(IPIN2017-CAR)。UJIIndoorLoc 数据集中包含3 栋多层建筑物,总面积约108 703 m2,总共有520 个AP,其训练集和验证集分别有19 938 条和1 111 条数据。在使用UJIIndoorLoc 数据集进行定位前,对数据进行了如下处理:首先数据集中的空值100 替换为-94,即认定-94 以下的RSSI 是无效的。其次,删除了一些低方差特征,降低了数据的冗余性。然后,删除了训练集中一些重复的数据行,并填充了部分新数据,填充方法为:若两个点的位置小于阈值,则将两点的中点添加至训练集中,其特征为两个点特征的平均值。最后,由于训练集中部分位置特征与邻近位置相差较大,故将训练集中此类数据予以删除。 IPIN2017-CAR 数据集包含一栋单层建筑物,训练集中共有58 个AP,其训练集和测试集分别1 800 条和128 条数据。 用于测量周围设备距离的蓝牙RSSI 是来自真实环境中的数据。本文选取燕山大学信息馆二号楼411 房间为实验场地,该实验场地为空房间,场地面积为176 m2。在定位区域中设计以手机位置为中心,半径以0.3 m 向外递增的12 个圆环,考虑到真实环境中手机之间的蓝牙通信存在信号干扰,故同时将12 个Beacon 发射器分别随机放置于12 个圆环上,每个圆环上有且仅有一个Beacon发射器,采集设备选用Lenovo G50-80 笔记本和HUAWEI Mate 30 智能手机。分别将两部设备在采集点进行1 分钟的数据收集,在两部设备采集的数据集中,对每个不同距离的RSSI 随机抽取50条,共计600 条数据作为距离和RSSI 转换的原始数据。蓝牙RSSI 采集实验布局如图4 所示。 图4 蓝牙信号强度采集图Fig.4 Bluetooth RSSI acquisition diagram 3.2.1 用户组大小的测试 为了对校正算法的最佳用户组大小进行测试,大小范围为3 至25 的用户组被选择用来测试,目标用户没有被包括在用户组数量中。由于用户距离的阈值大小应考虑蓝牙的低误差通信距离,参照经验值,本实验将其设置为2.5 m。聚群用户比例设置为0.6,得到的结果如图5 所示。 图5 邻近用户组大小的影响Fig.5 Influence of adjacent user group size 由图5 可以发现,当近邻用户组大小为4 时,可以获得最佳的定位误差结果4.96 m。在用户组大小最少为3 时,可得到5.20 m 的定位误差,其与未校正的结果6.48 m 相比,也有19.8%的下降。在图5 中,除了第4 个和第6 个位置,其余位置均呈现了上升的趋势。在用户组大小为5 时出现向上波动,分析其原因为:相较于前一个点,此时个别用户组添加的一个新位置处于低误差和高误差边缘,干扰了聚群用户和离群用户的区分,影响了低误差点的校正。同理,相较于用户组大小为5 时,用户组大小为6 的定位误差出现了下降,考虑为个别用户组添加的一个新位置使低误差位置的比例升高,由此产生了较好的效果。由理论部分可知,随着用户组的增大,用户组的平均误差应呈现下降趋势,而用户组大小从7 开始,误差呈现了与理论不相符的变化,其原因为在设定的阈值下,校正范围内的用户数量无法达到校正用户组大小,导致该用户无法利用周围信息进行校正,即减少了校正点的比例。除此之外,用户组的增大,也意味着聚群用户中出现高误差点比例的概率增大,因此校正后的定位误差趋向于校正前的定位误差。 3.2.2 对比实验 为了证明MFCC 算法的有效性,本文选择了多种定位算法在UJIIndorLoc 数据集上进行了比较,具体结果如表1 所示。本实验中设置α=0。 表1 UJIIndoorLoc 数据集上的定位误差Tab.1 Positioning error on UJIIndoorLoc m 从表1 中可以发现,MFCC 算法较DL-RNN 的结果相比,在50%和75%分位点的误差低于DLRNN,在90%和95%分位点的误差高于DL-RNN算法,并且在95%分位点的误差高于stacked RNN算法。这是由于本文算法的校正部分仅对蓝牙通信有效距离以内的位置有效,通过对测试数据集分析可以发现,有半数的位置无法构建校正用户组,这些位置仅仅使用了粗定位算法。相比于粗定位算法,DL-RNN 和stacked RNN 两种深度学习方法可以获取更高级的数据特征,并且DL-RNN利用了更多时间序列上的信息,模型更为复杂,因此使用此两种深度学习算法会出现误差低于仅使用粗定位算法的情况。理论上若这些位置周围出现一个以上的用户组,即可将这些位置进行有效的校正,误差会再次降低。尽管如此,MFCC 算法较KNN、随机森林、Kalmam 滤波和粒子滤波的结果而言,在90%和95%分位点的定位误差仍有较大降低,并且在50%和75%分位点的定位误差有20.9%~62.1%的降低,在平均误差部分对其他算法有19.0%~61.6%的降低,所以MFCC 算法可以有效地降低定位误差。 为了验证MFCC 算法也适用于其它数据集,本文选用IPIN2017-CAR 作为对比,选用WKNN拟合、DNN 拟合和LSTM 拟合三种定位算法作为对比算法。对于LSTM 算法的所使用的序列数据,本小节按照数据集中的时间顺序进行处理。四组实验得到累积误差图和定位误差表如图6 和表2所示。 表2 IPIN2017-CAR 数据集下定位误差Tab.2 Positioning error on IPIN2017-CAR m 图6 IPIN2017-CAR 数据集下定位累积误差图Fig.6 Cumulative positioning error diagram on IPIN2017-CAR 通过图6 和表2 中四组实验的对比可以发现,本文所提出的算法在平均误差、50%分位点、75%分位点和90%分位点均低于对比算法所产生的误差,但在95%分位点产生的误差要高于对比算法,与在UJIIndoorLoc 上实验的结果相似,这是因为部分用户无法构建用户组所导致的定位结果未校正。由实验结果可知,MFCC 算法在IPIN2017-CAR 数据集上也具有良好的定位效果。 3.2.3 校正部分与现有算法的结合 为了进一步验证MGCC 算法中的校正部分可降低多种定位算法的定位误差,本节选用KNN 拟合、随机森林拟合、DNN 拟合和LSTM 拟合四种定位算法。由于LSTM 的输入需要序列数据,而UJIIndoorLoc 数据集并非严格意义上的序列数据,故本文利用其中的时间信息进行处理,数据的具体处理方式为:首先将数据集中的所有数据按照建筑物相同、楼层相同、用户相同和手机相同进行划分,随后将数据按照时间排序,若两条相邻数据之间的时间相差不超过60 s 则将该数据视作处于一条完整路径中,当完整路径中数据个数小于设定阈值时,则将路径中最后一个位置点进行多次复制达到最小路径长度阈值,并将该数据视作静止状态的路径用作训练或测试。由于训练集中每个位置均采集了多次,故按照上述生成数据的方法,将会产生大量的静止状态数据。实验得到累积误差图和定位误差表如图7 和表3 所示。 表3 使用校正前后的平均定位误差Tab.3 Average positioning error before and after using the correction algorithm 图7 使用校正前后的定位累积误差图Fig.7 Cumulative positioning error diagram before and after using the correction algorithm 由图7 和表3 可以看出,随机森林的校正效果最为明显,校正后的误差相比于未校正时下降了31.3%,为2.89 m;KNN 的效果较差,但误差也下降了1.49 m,下降比例为23.0%。通过4 组消融实验的对比可知,对于不同的定位算法,本文提出的校正方法均可以降低23%以上的误差,由此说明MFCC 算法中校正部分可以有效地降低多种定位算法的定位误差。 通过4 组实验的对比可以发现,针对不同的定位算法,本文提出的校正部分可以产生不同程度的误差降低。实验结果表明,定位误差较低的定位方法使用本校正方法后,会产生更好的定位效果。 本文提出一种基于众包校正的多源融合室内定位算法,该算法能够针对多用户的室内环境提高定位精度。算法的粗定位部分可以较快地得到用户的粗略位置和用户间的距离;聚类校正利用用户间的距离进行校正,提升了高误差用户的定位精度;虚拟空间校正利用用户组位置分布进行校正,提升了用户的定位精度。与DL-RNN 等十种定位算法在UJIIndoorLoc 和IPIN2017-CAR 两个数据集上的对比实验结果表明,MFCC 可将平均定位误差分别降至4.96 m 和4.35 m,尤其是50%的定位精度可以达到3.29 m 和3.62 m。用户组大小的测试实验结果表明,当周围存在3 个以上的用户时即可对定位结果进行校正,定位精度最高提高23.5%。校正部分与现有算法的结合实验结果表明,提出的校正方法嵌入随机森林、LSTM 等现有定位算法时,可将定位精度最高提高31.3%。 由于定位算法计算的仍是上一时刻的位置,与当前时刻相比会产生一定误差。在下一步工作中,将考虑通过预测用户下一时刻的位置来提高定位精度。
2.5 构建虚拟空间指纹库与虚拟空间校正

3 实验结果与分析
3.1 实验数据描述

3.2 实验内容及实验结果

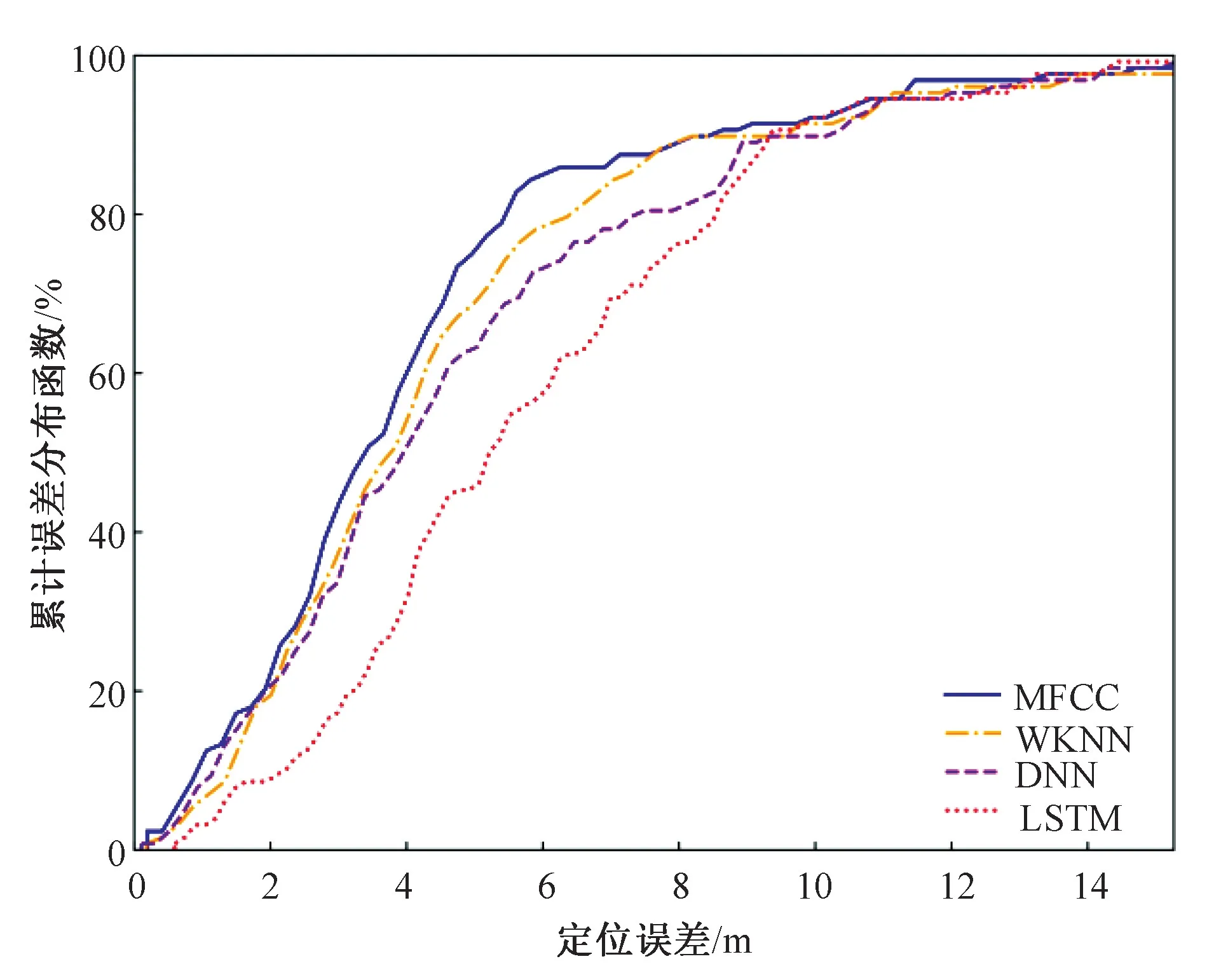
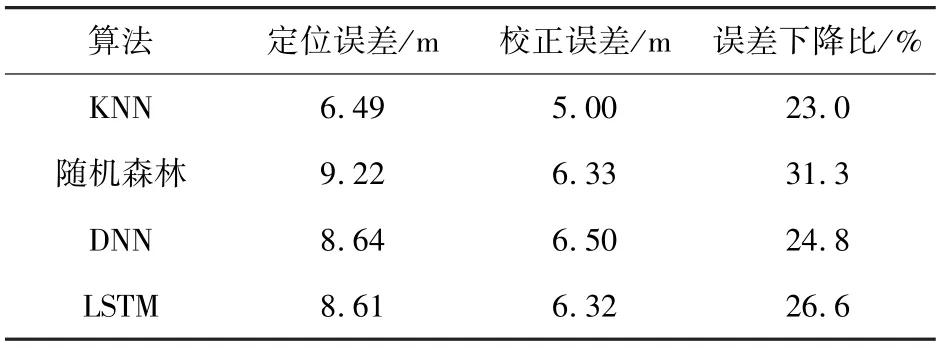
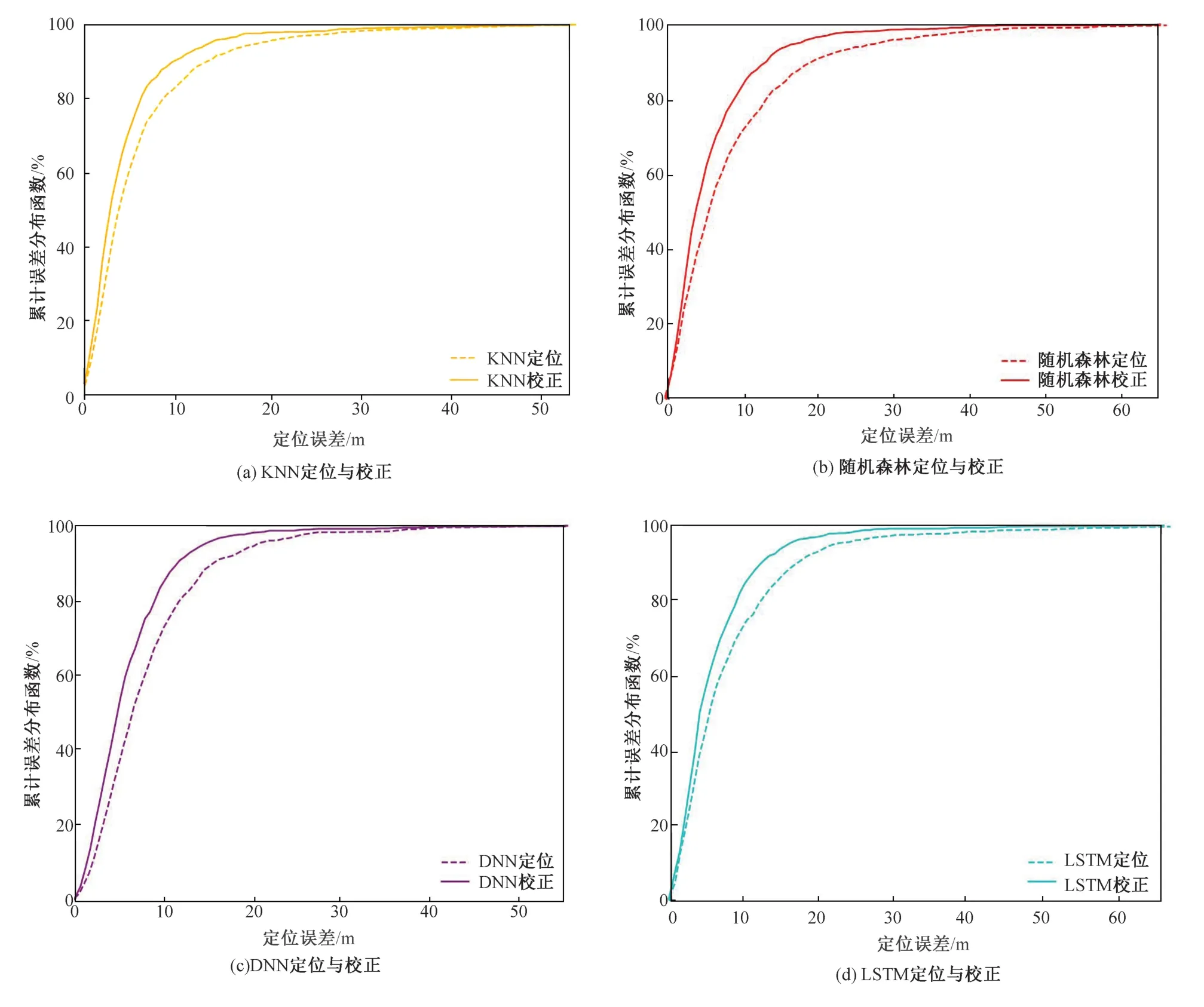
4 结论
猜你喜欢
工业设计(2022年7期)2022-08-12科学与信息化(2022年3期)2022-02-18小哥白尼(趣味科学)(2021年11期)2021-02-28小天使·一年级语数英综合(2020年10期)2020-12-16家庭影院技术(2018年10期)2018-11-02家庭影院技术(2018年3期)2018-05-09玩具世界(2017年8期)2017-02-06电脑与电信(2016年3期)2017-01-18自动化学报(2016年8期)2016-04-16黄山学院学报(2015年5期)2015-10-22
