
面向隐私保护的稀疏对抗攻击样本生成方法
2023-12-08 08:39陈淑平尤殿龙
燕山大学学报 2023年6期
王 涛,马 川,陈淑平,尤殿龙
(1.河北科技师范学院 工商管理学院,河北 秦皇岛 066004;2.燕山大学 工程训练中心,河北 秦皇岛 066004;3.燕山大学 图书馆,河北 秦皇岛 066004;4.燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
0 引言
人工智能技术日益在计算机视觉领域中变得不可替代。基于深度神经网络(Deep Neural Network,DNN),智能设备通过对图像的智能分析和处理,可支持目标检测、目标识别、流量统计、事件监测、监控安防、AI 零售等应用场景[1-2],甚至可以进行视觉推理和场景理解[3-5]。人工智能在计算机视觉领域的应用正在重塑人们的生活、工作和思维的方式。但另一方面,图像之中包含丰富的语义知识,可以透露很多本身内容之外的隐含信息,一旦被恶意使用将会对个人隐私构成巨大威胁。例如,利用深度学习模型可以从个人图像中挖掘出职业[6]、健康状况[7]、性取向[8]等敏感信息。结合大数据分析,甚至能够得到用户关系网[9]。在无死角监控和社交媒体共享的时代,如何保护个人隐私成为亟待解决的问题。
目前,对抗DNN 模型检测的研究中,基于模糊处理的方法、数据中毒攻击和对抗样本攻击被广泛研究。Wilber 等人[10]使用模糊、像素化、变暗和遮挡等模糊技术对抗人脸测试。但基于模糊处理的方法要么对原图像破坏过多,要么对DNN 识别系统无效。Cherepanova 等人[11]开发了LowKey系统,可以使用户在社交媒体上公开图像之前进行预处理(对图像投毒),以便第三方DNN 模型无法将其用于人脸识别目的。Shan 等人[12]提出了Fawkes,帮助人们在公开图像之前对其图像进行投毒以抵御DNN 识别模型。当这些图像用于训练识别模型时,会导致用户的正常图像被错误识别。这种方案的前提是能够向数据集中注入投毒图像,如果目标模型已经训练完毕或在干净的数据集上进行训练,则上述方法将失效。对抗样本攻击的方法是通过对图像施以轻微扰动来欺骗DNN 模型,致其错误分类[13]。Yang 等人[14]提出了一种利用图像加密技术生成对抗性身份掩码的方法,并通过在人脸图像上覆盖掩码来隐藏原始身份。该类方法的优势是无论DNN 模型的结构如何,只需修改自己的图像数据即可达到目的,因此更适合在真实场景中保护用户隐私。
DNN 模型检测的技术核心是基于深度学习的图像分类。为了在监控和社交平台这些真实场景中保护个人隐私,可以在图像中添加少量扰动来对抗目标模型,致其错误分类,从而无法完成后续一系列未经授权的任务。如暴露在视频监控下的人和物品可以贴扰动贴、发布到社交平台的图像可以在上传时修改少量像素值,以此方式来对抗DNN 模型。
为了提高攻击方法在真实场景中的实用性,降低对图像的破坏性,本文使用稀疏对抗攻击方法,即通过扰动少量像素(扰动像素即修改像素)进行对抗攻击,以达到保护个人隐私的目的。
1 相关研究
Szegedy 等人[13]首次提出了对抗攻击方法,发现微小扰动即可使DNN 错误分类。Goodfellow 等人[15]提出FGSM 算法,利用梯度来生成扰动,提供了一种简单而快速地生成对抗样本的方法。随后,Kurakin 等人[16]对FGSM 算法进行拓展,提出了BIM 算法,用于物理世界中的对抗攻击。Moosavi-Dezfooli 等人[17]提出了Deepfool 方法,基于超平面分类求解最小扰动,同等攻击效果下得到了比FGSM 方法更少的扰动,并对分类器的鲁棒性进行了量化。Rozsa 等人[18]提出了FGVM 算法,加强了对抗攻击的泛化能力,可以对抗多种深度神经网络。以上方法采用的是白盒攻击,对目标模型的梯度、结构和参数等信息依赖程度高。此外,由于利用了L2或者L∞范数限制扰动幅度来生成最小扰动,微小的扰动虽然肉眼不可见,但通常需扰动整张图像中的每一个像素,这就使得该类方法难以应用于真实场景。
Papernot 等人[19]在L0范数约束下进行定长扰动,提出了JSMA 算法,引入显著图概念,达到了只需修改少量的输入特征即可使目标模型误分类的目的。Narodytska 等人[20]利用一种基于局部搜索的算法来构造梯度的数值近似用以扰动图像,只需修改很少的像素即可生成对抗样本,且是一种黑盒攻击方法。Su 等人[21]提出了一种One-pixel攻击方法,利用差分进化算法,仅需获取目标模型的输出标签的概率信息,不需要计算梯度即可生成对抗样本(只是效率较低),是一种黑盒的攻击方法。Carlini 和Wagner[22]分别在L0、L2和L∞范数约束下引入三种攻击算法,在防御蒸馏和非蒸馏的网络上都获得了良好的效果,证明了算法的通用性。Modas 等人[23]提出了一种稀疏对抗攻击方法SparseFool,可以快速地计算稀疏扰动,并能有效地扩展到高维数据。但较大的稀疏度会导致这些少量的像素被修改的过于显著而容易被察觉(可感知)。为了提高稀疏对抗攻击方法的不可感知性,Croce 等人[24]提出了CornerSearch 算法,通过添加额外的约束,使像素仅在特定区域扰动,并避免沿轴对齐边缘扰动,从而达到稀疏扰动但肉眼仍然不易感知的目的。近期,Croce 等人[25]又提出了一种基于随机搜索的多功能稀疏对抗攻击框架Sparse-RS。
这些研究为本文带来了启发和灵感。其中,稀疏对抗攻击的研究中,有的限制扰动像素的数量但不限制扰动的幅度,有的限制了像素扰动的幅度但不限制扰动的位置,有的限制在特定区域内扰动像素但又没有兼顾扰动的幅度和数量。扰动过多的像素很难在真实场景中实施,不限制像素扰动的位置和幅度则对图像破坏过大且易被感知。为了能够同时满足这些目标,最有效的方法就是把对抗样本生成问题转化为多目标优化问题,同时限制扰动像素的数量、幅度和位置。扰动像素的数量越少、幅度越小、位置越偏,则效果越好。下面阐述本文提出的稀疏对抗攻击样本的生成算法。
2 稀疏对抗攻击样本生成算法
本文在保证扰动尽可能小的前提下,遍历正确类别之外的其他类别,并使其他类别的置信度尽可能大,据此生成对抗样本。下面给出形式化的优化目标。
2.1 优化目标
一张图像可用一个n维向量X=(x1,x2,…,xn)形式化地表示,其中分量xi表示图像中的一个像素。若图像是彩色的,xi是一个五元组,即xi=(mi,ni,Ri,Gi,Bi),其中mi,ni为像素xi的坐标,Ri,Gi,Bi表示像素xi的三个颜色分量。若图像是灰度图,则xi为一个三元组,即xi=(mi,ni,Gai),其中Gai为灰度。后文只针对五元组的彩色图像进行阐述,三元组的灰度图的扰动方法与之同理,故不再赘述。
令f是DNN 模型的分类器,f接收输入向量X并计算图像X属于各类别的分类置信度(即概率)并取结果中最大的作为分类结果,比如计算后类别t的分类置信度最大,则f将X分类为类别t。令ft(X)表示图像X属于类别t的分类置信度。修改图像X中的某些像素,对X进行扰动,得到扰动向量e(X)=(e1,e2,…,en)。其中ei的结构与xi完全相同,即ei=(mi,ni,Ri,Gi,Bi),其中mi,ni为像素ei的坐标,Ri,Gi,Bi表示像素ei的三个颜色分量的扰动量,若Ri,Gi,Bi的值都是0 则说明该像素没有被扰动。令符号adv表示图像未被扰动时由f分类得到的类别。添加扰动后,希望分类器f产生分类错误,这就需要f将图像X分类为其原类别adv的置信度尽可能的小,而分类为其他类别的置信度应尽可能的大。同时,为了达到肉眼不易感知的目的,需要保证扰动e(X)尽可能的小。于是,优化目标可以形式化地表述为求下面问题的最优解e(X)∗:
其中,C为类别总数,adv为图像X未被扰动时由f分类得到的类别。本文算法属于稀疏对抗攻击算法,只修改少量像素进行扰动,由L0范数约束。即‖e(X)‖0≤k,其中k为扰动像素的个数,e(X)为稀疏向量,只有被扰动的像素才有RGB 扰动值,其他像素的RGB 扰动值都为0。为了便于表述,将e(X)称为扰动向量,而将X+e(X)称为扰动图像向量,表示原图像X被扰动之后的图像。其值为X和e(X)中对应位置上的颜色分量相加之后得到的n维向量,简记为E。
2.2 扰动向量构建
添加稀疏扰动后,为了尽可能地降低被肉眼识别出来的概率,需要限制扰动像素的幅度和扰动像素的位置。
2.2.1 限制扰动像素的幅度
限制扰动像素的幅度即限制扰动后的像素与原像素周围的像素之间的色差。色差过大会增加被肉眼识别的概率,但色差过小又会降低对抗成功率。因此,将像素xi及与xi呈直线相邻的2 个像素作为一组来计算标准差(即分别将水平、竖直以及两条斜对角线这四条线上的三个像素作为一组计算颜色标准差,得到四组结果),记为σ1i、σ2i、、,如图1(a)所示。选取其中最小的值,记为σi=min(σ1i,σ2i,σ3i,σ4i) 。颜色标准差反映色差的离散程度,在像素xi上加减这个σi,就得到像素xi的两个扰动颜色值,即xi±σi,如图1(b)和(c)所示。对于这两个扰动颜色值,后续会分别计算其扰动效果,并将扰动效果更好的保留,作为该像素的扰动颜色。像素xi处在图像的边缘时,对于其缺失的紧邻像素,以边缘像素填充。为了便于表述,将一张图像中所有像素与其周围像素的颜色标准差向量记为σ,即σ=(σ1,σ2,…,σn)。

图1 扰动颜色的生成Fig.1 Generation of perturbation color
先讨论单像素攻击,即k=1 的情况。此时扰动向量e(X)中只有一个像素非空,即e(X)=(0,0,…,σi,…,0)。对于单个像素xi,因为有两种扰动方式,即xi±σi,所以可得到两个单像素扰动图像向量
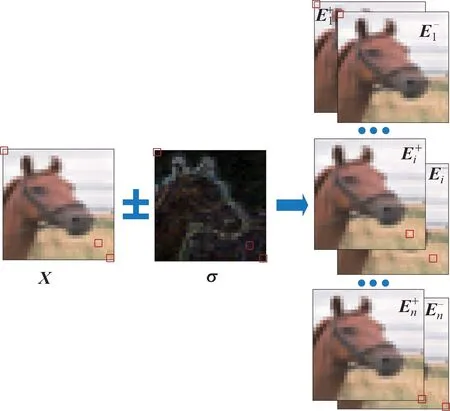
图2 单像素扰动图像向量空间的生成Fig.2 Generation of one-pixel perturbation image vector spaces
利用分类器f对中的扰动图像分类,计算各类别的置信度和分类结果。若发现分类结果不是其原来类别adv,则表示单像素攻击成功。一般来说,单像素攻击很难成功,但可以利用单像素扰动的分类置信度,进行多像素攻击。
对于每一个类别t(t∈{1,2,…,C},t≠adv),计算Ei+和Ei-的分类置信度ft(Ei+) 和ft(Ei-),并取其中分类置信度更大的扰动图像用于后续的多像素攻击,为了便于表述,将筛选后的结果(Ei+或Ei-)简记为Ei±,即
从式(3)中可知,Ei±指代的是导致分类器f分类为t的置信度最高的那个扰动xi像素的扰动图像(Ei+或Ei-)。分别针对每一分类,按置信度降序排列。记图像Ei±分类为t的置信度的排序序号为fsti,若fsti
对于分类t(t=1,2,…,C,t≠adv),取Fs中第t列前N个排序序号所对应的扰动图像,即可得到最可能将分类结果扰动成t的N个单像素扰动图像。
2.2.2 限制扰动像素的位置
将扰动像素到图像中心点的欧式距离作为扰动像素偏远程度的度量,即dt()=‖(mi,ni)-(m′i,n′i)‖2,其中(mi,ni)为图像Ei±中像素xi的坐标,(m′i,n′i)为图像中心点的坐标。
本文的目标是在保证攻击有效的前提下,搜索离中心区域尽可能远的扰动像素,即扰动像素的位置越偏远则效果越好。因此,针对每一类别t(t≠adv),选取Fs的第t列中排序序号前N个所对应的扰动图像,再依据其dt(Ei±) 降序排序,排序后的序号记为dsti,若dsti
2.2.3 利用抽样方案生成对抗攻击样本
随机抽取k个像素进行扰动,来生成一个针对类别t(t≠adv)的目标攻击样本,即‖e(X)‖0=k,k≥2。
为了同时保证扰动成功率和扰动效果(不易被肉眼识别),排序向量Dts中更靠前的扰动像素,被抽到的概率应该更大。在扰动成功率不明显下降的基础上进行微调,尽量调高排序靠前的样本的抽样率,得到抽样公式
根据式(4),从{1,2,…,N}中随机抽样(s1,s2,…,sk),构造图像X的k个扰动像素。当i=1 时,概率为3/N,当i=N时,概率为3/N3。这个分布保证能更大概率地抽取位置更远、颜色修改对决策边界影响更大的扰动像素。将针对类别t(t≠adv)进行目标攻击的,具有k个扰动像素的扰动图像简记为。这样,k个单像素的扰动效果通过叠加在一起,如图3 所示。

图3 k 像素扰动图像的生成Fig.3 Generationng of k-pixel perturbation image
随机进行Niter次抽样,可以得到针对类别t(t≠adv)进行目标攻击的Niter个k像素扰动图像向量组成的向量空间,其中{s1i,s2i,…,sik}t表示第i次抽样得到的k个像素的序号信息。利用分类器f对中的k像素扰动图像分类,计算各类别的置信度和分类结果。若存在分类结果为t(不再分类为其原分类adv)的扰动图像,则表示攻击成功。遍历除adv之外的所有种类,调整k的值,搜索扰动图像,生成多像素对抗样本。
与迭代方案[26]相比,抽样方案的最大优势在于,所有这些图像都可以并行地输入到分类器f中进行分类,这比迭代方案中的顺序处理方式要快得多。而且,抽样方案不像迭代方案一样需依赖先前的步骤,因此不会陷入某些次优解。另外,相比进化算法等复杂算法,抽样方案采用的算法更简单,具有更好的性能。本文方法不依赖目标DNN 模型的结构、梯度和参数等信息,是一种黑盒对抗攻击方法。
2.3 扰动算法
下面给出生成对抗样本的具体步骤和算法。
1) 生成像素颜色标准差向量σ。
为图像X中的每个像素计算其与周围像素之间的标准差,得到颜色标准差向量σ。利用σ可以限制扰动像素的色差,达到扰动图像后不易被觉察的目的。
对图像X中一个像素xi进行扰动(xi±σi),会得到2 个单像素扰动图像和,因此,向量空间中共有2n个单像素扰动图像。用分类器f对中的扰动图像进行分类,若分类结果不是其原分类adv,则找到对抗样本,算法结束。否则,记录n个扰动图像的分类置信度(对于每一个类别t(t≠adv),图像和中只留下分类置信度高的一个)。
3) 依据优化目标排序。
依据式(1)中的优化目标,分类器f将扰动图像分类为其他类别t(t≠adv)的置信度应尽可能的大。对于每一个类别,根据步骤(2)中得到的分类置信度降序排序,得到排序矩阵Fs。遍历类别1 到C(t≠adv),按像素离中心点的距离降序,为每一个类别t(t≠adv)计算出排序向量Dts。
希望生成的对抗样本中扰动像素个数应尽可能地少,因此扰动像素个数k从2 开始,遍历类别1 到C(t≠adv),根据式(4)的概率分布对Dts进行Niter次抽样,得到k像素扰动图像向量组成的向量空间,并在其中搜索对抗样本。若无法生成对抗样本,则逐渐增加k的值直到成功生成对抗样本或k到达限定的最大扰动像素个数kmax为止。
根据以上步骤,即可为图像生成对抗样本,对抗DNN,其具体算法如算法1 所示。

在算法1 中,函数GenSigma(X)会生成颜色标准差向量σ,函数GenOnePixelPerturb(X,σ)会根据σ修改图像X生成单像素扰动图像向量空间,函数GenNPixelsPerturb(X,t,k,Niter)会针对每一个分类类别t(t≠adv)生成k像素扰动图像向量空间。
综上所述,首先进行单像素攻击,找出哪些像素更容易攻击成功,并依据优化目标对这些像素排序;然后通过抽样将k(2≤k≤kmax)个单像素组合在一起进行多像素攻击,生成对抗样本。
3 实验与评价
实验基于经典的ResNet 网络,使用手写数字数据集MNIST 和普适物体数据集CIFAR-10。将最大扰动像素个数kmax设置为30,随机抽样次数Niter设置为1 000,N设置为100。
实验选取了与本文方法最相关的5 种稀疏对抗攻击方法进行对比分析。这5 种方法分别是One-Pixel[21]、CW[22]、SparseFool[23]、JSMA[19]及CornerSearch[24]。对比了对抗成功率、扰动幅度(色差)的均值和中位数、扰动位置的均值和中位数、对抗样本效果等指标,并根据实验结果分析了目标DNN 模型的分类空间特征。
3.1 对抗成功率和扰动数对比
每种方法进行100 次实验,统计结果如表1所示。其中CornerSearch 选取的是与本文最相关的σ-map 模式的结果。

表1 对抗成功率及扰动像素数量对比Tab.1 Comparison of success rate and number of perturbation pixels
由表1 可知,在对抗成功率上,本文方法在MNIST 数据集上略低于SparseFool 和JSMA 方法,在CIFAR-10 数据集上则与其他方法相当或略高。这是由于MNIST 数据集中的图像分辨率为28×28,像素较少导致了算法的优化能力无法有效发挥。从扰动均值和扰动中位数上可以看出,本文的方法扰动像素的数量少于CW 和JSMA,与SparseFool 相当,比 One-Pixel 和 CornerSearch略多。
3.2 对抗样本效果对比
不失一般性,随机选取了1 张图片(ID:70),利用各方法对其扰动,每种方法重复实验100 次,得到100 张扰动图像,然后随机抽取6 张展示在图4 中。

图4 对抗样本效果对比Fig.4 The effect comparison of adversarial examples
由图4 可以看出,JSMA 和CW 方法扰动的像素数量较多,其中JSMA 扰动像素的数量达到50之多。而为了保证对抗成功,使DNN 模型错误分类,One-Pixel、CW、SparseFool 和JSMA 四种方法未对像素的扰动幅度进行限制,致使其扰动像素与周围像素间产生了非常大的色差,肉眼可见,对图像的破坏性较大。CornerSearch 方法的σ-map 模式与本文方法都对像素的修改数量和修改幅度同时进行了限制,扰动像素与周围像素间的色差较小,视觉效果良好,其变化不易感知。本文方法平均需要扰动12 个像素(图像共有1 024 个像素,即扰动率1%),比CornerSearch 方法略多,但由于本文方法同时对图像的扰动位置进行了限制,所以产生的扰动像素更靠图像边缘,对图像的视觉影响更小,更不易感知。相比 One-Pixel、CornerSearch 和SparseFool 方法,本文对扰动像素的位置和幅度优化效果显著,使得扰动像素更加不易感知,能更好地实现保护图像信息而扰动不易察觉的目的。
3.3 DNN 模型分类空间特征分析
下面给出实验中各种方法的扰动像素的位置和RGB 颜色分量的分布,并分析目标DNN 模型的分类空间特征。
扰动像素的位置分布如图5 所示,位置由设置了透明度的圆圈标记。颜色较深的圆圈是由于多次叠加造成的,表明在100 次实验中该位置多次被扰动,这意味着在这些位置扰动更容易成功,说明这些位置邻近目标DNN 模型分类空间的边界。扰动像素到图像中心点的欧氏距离统计结果如表2 所示。对比来看,One-Pixel 和CornerSearch方法的扰动位置集中在图像的中心位置附近,这表明当扰动像素的数量很少时,扰动图像中心位置附近的像素更容易攻击成功。而 CW、SparseFool 和JSMA 方法,扰动像素比较均匀地散布在图像各处,这在JSMA 尤为明显。表明当扰动像素的数量越来越多时,攻击能否成功对位置因素的依赖性越来越小,即使在边缘区域依然可以攻击成功。这也证明了,只要合理选择扰动像素,是可以找到扰动像素位置和扰动像素数量之间的平衡的,即可以扰动数量不多且较偏远的像素达到对抗攻击的目的。本文方法旨在寻找这种平衡,兼顾了扰动像素的位置、数量和扰动幅度,在保证扰动像素的数量不多、幅度不大的情况下,尽量寻找图像边缘位置进行扰动。从图表中可以看出,本文方法的位置优化效果显著。CornerSearch方法的σ-map 模式和本文方法都对扰动幅度进行了优化,导致扰动位置比较集中(图中有更多的位置叠加在一起)。但本文方法距离中心点的位置均值达到了10.4,表明扰动发生在图像中更偏远的位置上。

表2 扰动像素位置与颜色对比Tab.2 Comparison of the position and color of perturbation pixels

图5 位置分布及对比Fig.5 The location distribution and comparison
RGB 颜色分布情况如图6 所示。由设置了透明度的星号标记的是扰动像素原来的RGB 颜色值,由设置了透明度的圆圈标记的是对应像素扰动后的颜色值。同样,颜色较深的标记是因为多次叠加,表明在100 次实验中扰动像素多次被扰动成该颜色,这意味着扰动成这些颜色更容易成功,说明这些颜色值邻近目标DNN 模型的分类空间的边界。
从图6 中可以看出,星号标记的区域比较集中,表明被扰动的像素在原图中的颜色比较接近。结合图4 可知,在颜色接近的区域扰动更容易成功,甚至只对图像的背景区域扰动依然可以攻击成功。用同一像素扰动前后的RGB 颜色值的欧氏距离来度量该像素的扰动幅度,得到各方法的颜色统计数据,如表2 所示。相比其他几种方法,本文方法的颜色扰动均值和中位数更小,表明像素在扰动前后的颜色变化不大,更为接近。说明本文方法生成的对抗样本对原图破坏性更小,肉眼更加不易感知。
3.4 样本的泛化性评估
为了评估本文方法生成的对抗样本的泛化性,选取图像分类领域的经典神经网络ResNet18、ResNet50、IncV3 和VGG16 对样本进行迁移测试。数据集为CIFAR-10,最大扰动像素个数kmax设置为30,随机抽样次数Niter设置为1 000,N设置为100。
选定一个网络模型作为原目标系统,并利用该系统为CIFAR-10 的测试集中的10 000 张图片生成对抗样本。将生成的10 000 个对抗样本输入其他网络(迁移目标系统)进行迁移测试,并统计对抗成功率,结果如表3 所示。
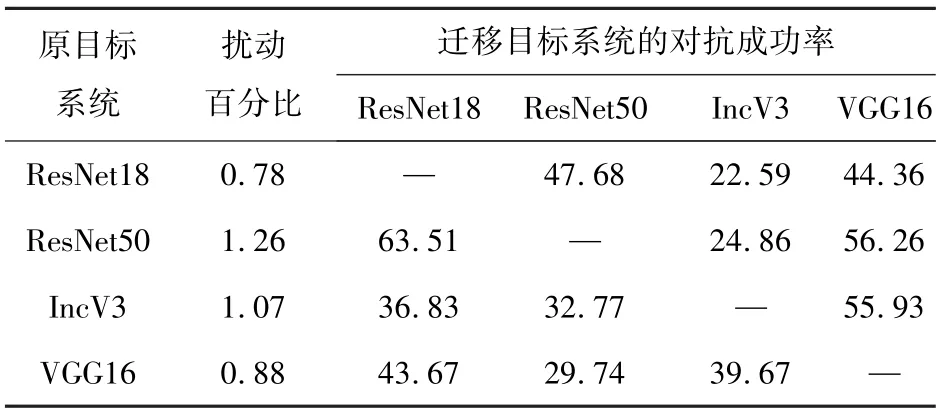
表3 对抗样本的迁移对抗成功率对比Tab.3 Comparison of migration adversarial success rate of adversarial examples %
从表3 中可以看出,同系列网络(Resnet18 和Resnet50)的可迁移性较好,Resnet50 生成的样本迁移到Resnet18,依然可以达到63.51%的对抗成功率。其他网络间迁移,也可以达到20%到60%左右的对抗成功率。这也表明,对抗样本主要分布在分类边界,不同网络模型的图像分类边界多有重叠,因此一种网络生成的样本也能保持不错的泛化性,可用于攻击其他网络。这也意味着,生成样本时,在目标系统中集成多个网络模型,找到各类模型的分类边界的重叠区域进行扰动,将会大大提高样本的泛化能力。
3.5 实用性验证
真实场景中涉及个人隐私和行人检测的网络模型更多的是目标检测模型,但其技术基础依然是图像分类。与图像分类模型的区别在于,目标检测模型需要预测目标实例的位置(即检测框),并在各个检测框中根据分类置信度执行分类任务。为了验证本文方法的实用性,将本文算法应用于工业界广泛使用的目标检测系统YOLOv5上,其攻击效果如图7 所示。行人检测数据集采用MS COCO train2017 的子集COCO128[27]。

图7 原图与对抗样本的检测结果对比Fig.7 Comparison of detection results between original images and adversarial examples
遍历YOLOv5 预测的每个检测框,利用其分类置信度对像素进行扰动,生成对抗样本,并将样本输入YOLOv5 进行测试。从图7 中可以看出,本文算法对大目标和重叠较少的目标实例攻击效果较好,但对重叠较多的目标实例,因为存在各检测框重叠区域内的扰动像素覆盖问题,导致攻击效果一般。原图和对抗样本的检测平均精度均值(Mean Average Precision,mAP)和对抗样本的平均生成时间如表4 所示。图像扰动前后的检测平均精度均值由0.87 下降为0.45,对抗样本的平均生成时间为2.7 s,表明本文算法具有良好的实用性,可用于目标检测任务。

表4 原图与对抗样本的平均精度均值对比Tab.4 Comparison of mean average precision between the original images and the adversarial examples
4 结论
针对真实场景中的个人隐私保护问题,本文提出了一种稀疏对抗攻击样本的生成方法,对抗DNN 模型,致其错误分类从而无法完成后续未授权任务。本文在限制扰动像素数量的同时,对扰动幅度和扰动位置等多个目标进行优化,并采用抽样方案简捷高效地生成对抗样本。实验结果表明,在扰动率限制在1%以内的情况下,显著优化了扰动像素的幅度以及位置,对原图像破坏性更小,扰动更加不易感知。通过迁移测试和算法在目标检测任务的应用,验证了本文算法的泛化能力和实用性。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
核科学与工程(2021年4期)2022-01-12
数学物理学报(2019年4期)2019-10-10
计算机应用(2018年5期)2018-07-25
贵州师范学院学报(2016年3期)2016-12-01
新校长(2016年8期)2016-01-10
电源技术(2015年11期)2015-08-22
轴承(2015年2期)2015-07-25
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
