
基于双路径特征提取网络的三维点云分割算法
2023-12-08 08:41李鹏江温淑焕
燕山大学学报 2023年6期
李鹏江,温淑焕,∗
(1.燕山大学 智能控制系统与智能装备教育部工程研究中心,河北 秦皇岛 066004;2.燕山大学 工业计算机控制工程河北省重点实验室,河北 秦皇岛 066004)
0 引言
伴随3D 采集技术的迅猛发展,3D 传感器获取点云数据变得越来越容易[1]。三维点云数据拥有充足的形状、几何及比例信息。点云数据结合2D 图像,能够帮助机器更好地理解周围的环境。点云语义分割是点云处理中的一个典型而又关键的任务,如今已被极为广泛地应用于机器人、自动驾驶和遥感等领域。相应的分割方法可以分为传统方法和基于深度学习的方法[2]。本文旨在使用深度学习进一步提高分割算法的精度,因此将展开介绍基于深度学习的方法。
大多数现有的使用深度学习处理点云[2]的方法,根据点云表示形式大致分为以下四类:
①基于点的方法:PointNet[3],通过几个独立多层感知机(Multi-Layer Perceptron,MLP)获取逐点特征而后使用最大池化层获取全局的特征。PointNet++[4]为克服点云的不均匀性和变密度等带来的问题,按层次对点进行分组,并不断学习逐渐扩大的局部区域。类似的逐点MLP 的方法还有PointWeb[5]等。此外,本文将重点借鉴对点进行卷积的方法,如经过χ-conv 变换,PointCNN[6]使用MLP 可将输入点转变成标准数据形式,从而可以使用一些常规的卷积算子进行处理。还有使用现有方法执行卷积的某些算法,如三维点云卷积网络PCNN[7]使用了径向基函数。
②基于投影的方法:此类方法往往把三维数据投影到二维,之后用类似处理二维图像的神经网络方法进行处理,如Wu 等人[8]提出了一种端到端的基于条件随机场和SqueezeNet 的网络以快速准确地分割3D 点云。随后SqueezeSegV2[9]为解决域移位问题,使用无监督的域适配管道,可以取得更加精确的分割精度。
③基于体素的方法:为了应用常规3D 卷积,点云需体素化预处理变为密集网格,如Tchapmi L等人[10]提出的SEGCloud,使用三线性插值将粗体素映射回点云,随后加强逐点标签的空间一致性。
④基于图的方法:如SPG[11]使用一些彼此联系的超点和简略形状来表示点云,同时利用超点图或属性有向图捕获上下文和结构信息。
综上所述,基于投影方法的性能非常受视点选择及遮挡情况的影响,且因为投影过程中通常会导致信息损失,从而不能很好地利用潜在的结构和几何信息;尽管体素形式可以保留三维点云的邻域构造,且标准的3D 卷积也可以直接应用在这种数据格式上,但体素化过程天然地会导致信息缺失同时引入了离散伪影,并且通常在实际中很难找到适合的分辨率体素网格;基于图的方法目前研究相对较少。
因此,为了设计一种可以更加精准、高效地获取场景中的语义信息的点云分割算法,本文使用基于点的方法,直接对点进行卷积处理,没有任何中间表示,可以保留更多信息。具体来说,本文分别借鉴核点卷积算子[12](Kernel Point Convolution,KPConv)和点云展平卷积算子[13](Flattening Point Convolution,FPC)构造了双路径特征提取网络,将它们的优势互补,可获得更加丰富的点云融合特征,从而实现点云分类和分割两种任务。同时加入预处理、相互增强、特征融合及空间、通道注意力等几个模块可以更加有效地提取全局上下文信息,在多个点云数据集上展现了优秀的处理性能。
1 点云分割算法结构和原理
如图1 所示,本文设计了一种可用于点云分类和点云分割两种任务的双路径增强网络(Dual Path Augmentation Network,DPA-Net)。采用类似U-Net[16]网络的模式,使用编码器-解码器形式的架构。以下将对整体网络中的特征预处理模块、双路径相互学习模块、残差式特征融合模块、注意力模块及解码器进行介绍。

图1 点云分类分割网络整体架构图Fig.1 Overall architecture of point cloudclassification and segmentation network
1.1 特征预处理模块
如图1 所示,输入点云由两个元素组成:点坐标P∈RN×3,特征F∈RN×D。通常的网络都会输入点云的三维坐标,但有些数据集还包含很丰富的颜色RGB 信息、法线信息、光强度信息等多种特征,这些特征可以在一定程度上反映语义信息。原KPConv[12]、FPC[13]两种点云卷积算子的输入除了三维坐标的几何信息外,其他的特征结合很少。本文提出一种特征预处理模块,可以充分利用数据集中的特征信息,使得一开始输入到卷积层中的数据具有较为丰富的点云特征信息,从而在之后的网络中可以学习到更加充分、丰富的上下文信息,进而提升网络性能。具体,本文使用MLP,类似1×1 的卷积,可以灵活地对输入数据进行维度操作;随后引入批量归一化和激活函数,可使得获取的特征信息更加紧凑;最后将三维坐标信息和高维度的点云特征输入到双路径的卷积模块。
1.2 双路径相互学习模块
在此模块中,以前边预处理模块获取的特征作为输入,分别通过据KPConv、FPC 两种点云卷积算子原理设计的双路径卷积通道进行特征提取。具体,本文将借鉴ResNet[17]网络根据两种算子各自的特点架构每个独立的卷积块,这些卷积块相互连接构成多层的卷积层。同时,本文设计了一种双路径增强机制,使得两条路径的卷积网络在各自学习、训练的时候,可以借鉴另一条路径上的特征,从而获得相互增强的点云特征,优化网络的训练。
1.2.1 两种算子的ResNet 架构
KPConv 可以使用任意数量的核点对点云进行卷积操作,并且据具体情况可以对卷积进行变形以适应当前的结构、几何状态,该算子可以很好地克服点云密度变化带来的挑战,同时参数量小,计算成本低。
然而KPConv 这种对整体的点云进行操作的方法无法捕捉点云分布更为均匀的区域,基于此,本文借鉴FPC 点云卷积算子来克服这方面的困扰,以提升网络精度和性能。FPC 的思想为将局部邻域点展平为二维网格平面,然后利用二维卷积进行特征提取。它对各种输入数据非常稳健,且作为一种局部特征学习模块,它参数量较小,非常适合跟其他点云处理框架进行结合。
两种算子网络分别提取点云特征最后进行融合,优势互补,可以得到更加丰富的上下文信息。两种算子都属于轻量级网络结构,参数量很小,因此不会增加太多的计算成本。
首先,考虑到KPConv 的两种形态,Rigid KPConv 和Deformable KPConv,本文设计了两种架构,如图2、3 所示。图中的1×1 即常规卷积操作,BN、ReLu 分别为神经网络中的常见的用在卷积操作后的批量归一化和激活函数操作。

图2 应用Rigid KPConv 的ResNet 架构Fig.2 ResNet architecture using Rigid KPConv
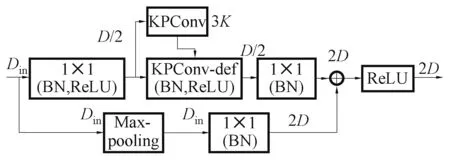
图3 应用Deformable KPConv 的ResNet 架构Fig.3 ResNet architecture using Deformable KPConv
对于FPC,由于其对点云的采样方式不同于KPConv,且其算子模块中会用到PointNet 网络进行特征提取,在图4 中,本文使用共享参数的Shared MLP 以实现维度参数变换的作用。此外,图2~4 中的当前维度参数D不是一个固定的数值,其值对应图1 中网络下采样过程,在64,128,256,512,1 024 之间依次变化。
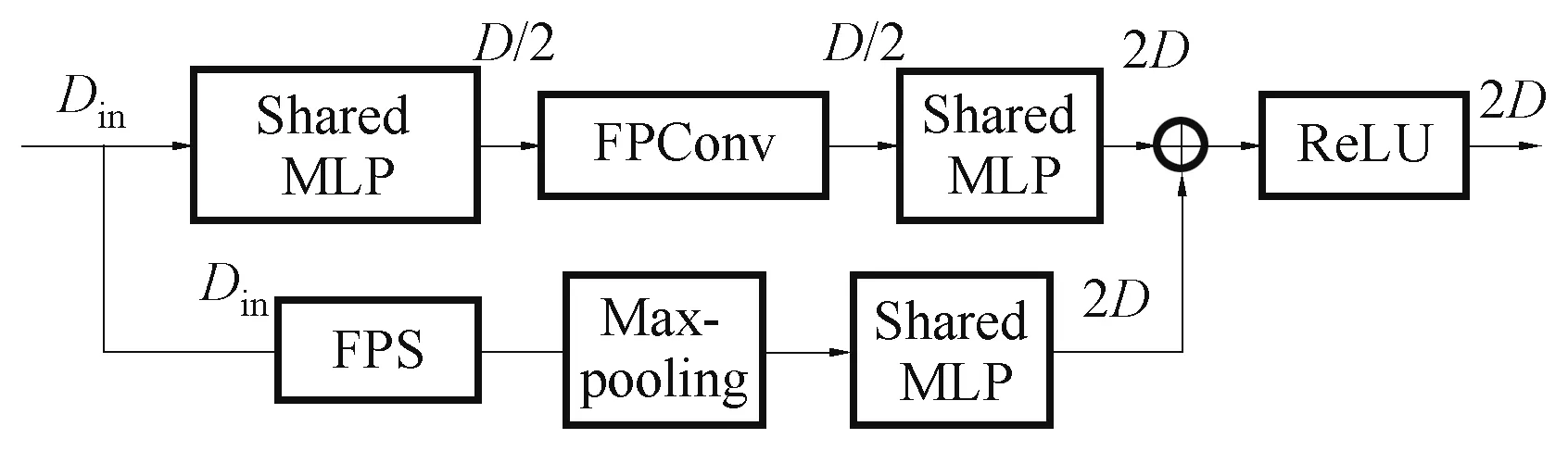
图4 应用FPC 的ResNet 架构Fig.4 ResNet architecture using FPC
1.2.2 双路径增强机制
架构好两种卷积算子的ResNet 卷积块之后,便可分别堆叠多个卷积块形成双路径的多层卷积网络。常规做法是将前一层卷积层的输出作为下一层的输入,最后将两条路径输出的点云特征进行融合。
本文提出一种双路径增强机制(Dual Path Augmentation,DPA),如图5。该机制使得双路径卷积层中的中间层的输入不只来自于本路径前一层的输出,同时还包含了由另一路径学习到的加权特征,这样可以使网络学习到更加丰富的局部信息,及早关注到更充分的上下文信息,从而提升网络效率并且提升最终的网络精度。具体原理如下:
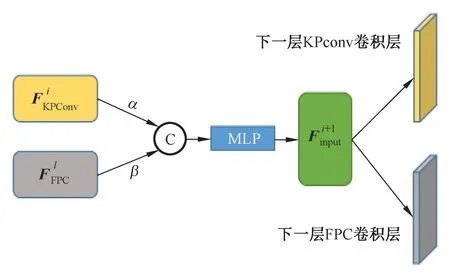
图5 DPA 机制Fig.5 DPA mechanism
其中:i=1,2,3,4,5,表示两条路径中当前卷积层属于第几层,本文模型中两条路径卷积层数都设置为了5 层;和分别表示KPConv 卷积路径和FPC 卷积路径第i层的输出特征;由于这两组特征对于两条路径卷积层的贡献是不一样的,因此将这两组特征分别习得两个权值α和β,进而在维度层面进行拼接C操作,以获得当前层的融合输出特征;随后通过MLP 进行维度参数变换以满足之后卷积层的维度输入要求,即公式中的M,由此便得到了下一卷积层的融合输入特征;需要注意两条路径中,下一卷积层的融合输入特征是不同的,特别的,经训练发现,保持本路径更多特征有利于最终精度的提升,因此对于KPConv 卷积路径,α的值设置为1,β的值则由训练习得,相反地,FPC 卷积路径中将β的值设为1,α的值由训练习得。
1.3 残差式特征融合模块
得到两条卷积路径上最终的输出特征之后,本文提出了一种残差式的特征融合模块,可以更好地结合两条路径上的输出特征,提升网络效率及精度。
如图6 所示,据KPConv 和FPC 两种算子的结构原理,并且通过实验验证发现,保留KPConv路径最后输出的所有特征FKPConv;然后将两路的特征先在维度上进行拼接,得到初步融合特征Ffuse:

图6 特征融合模块Fig.6 Feature fusion module
然后将这个融合特征经由一个残差式的网络结构后再与KPConv 路径特征FKPConv相加,由此得到最终的融合特征:
其中函数f1(·)表示残差网络主路上的卷积Conv1 及ReLu 激活函数操作;函数f2(f1(·))表示残差网络中经过主路操作后又经过由Conv2、ReLu、Conv3 操作组成的shortcut 路;σ表示Sigmoid 激活函数;☉表示残差结构中主路输出和shortcut 路输出进行的逐点矩阵乘法。
1.4 Transformer 的自注意力机制
受Transformer[14]中自注意力机制的启发,本文算法在双路径卷积最终输出的融合特征之后上附加了两个平行的注意力模块[15],空间注意力模块和通道注意力模块。以下将具体介绍两个注意力模块的原理。
1.4.1 空间注意力模块
如图7,从主干网获取N×C的输出特征A后,类似Transformer 中的查询向量、键向量和值向量的获取方式[15],分三路同时经过一个1×1 卷积,将其维度从C降为C1,得到Q,K,V三个向量,之后将K转置后与Q进行矩阵乘法,得到N×N的矩阵,将该矩阵执行softmax 函数,即可得到空间注意力矩阵S,相应注意力值的描述如下:
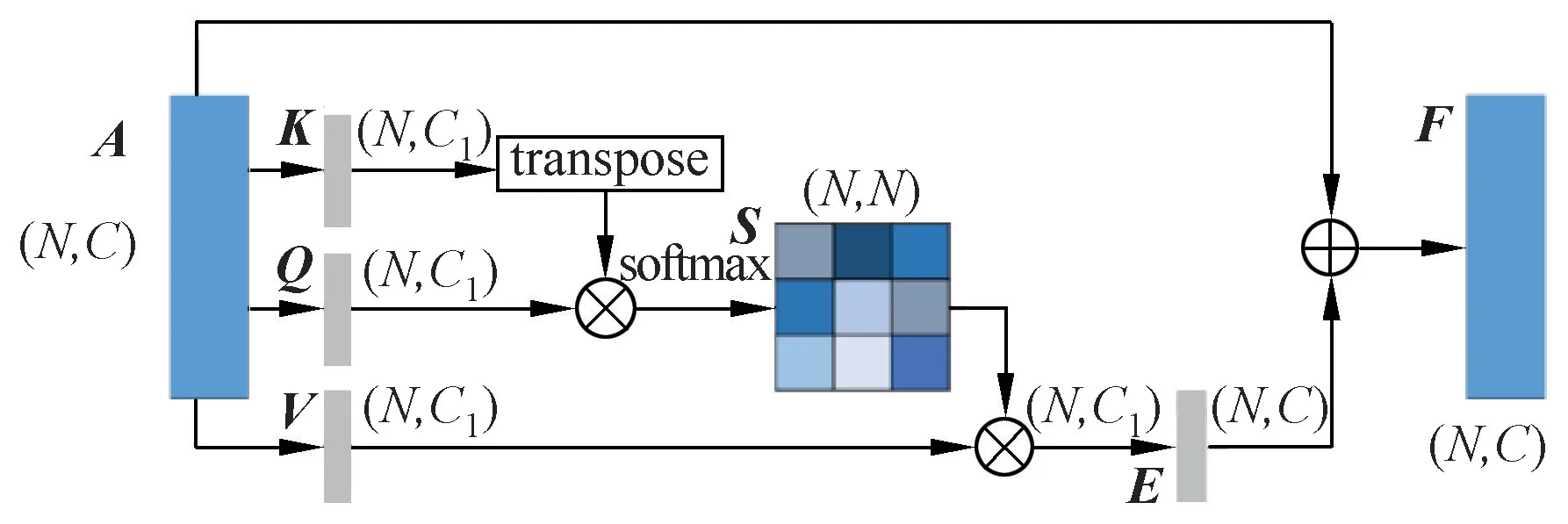
图7 空间注意力模块Fig.7 Spatial attention module
其中,snsms表示第ms个点对第ns个点的影响,然后将N×N的注意力矩阵与N×C1的V进行矩阵乘法,从而得到一个N×C1的聚集的特征映射矩阵E,再通过一个1×1 卷积,将其升维恢复为同A一样的尺寸大小,再之后,使用比例参数λ来加权求和期间的聚合特征。由此,对于第ns个点来说,经过空间注意力模块后的输出可以表示为
其中,λ会逐步学会分配更多权重,其初始值设为0[15]。从上式可以推断,所有位置特征和原始特征进行加权求和后才得到每个位置的结果特征。从而通过空间注意力矩阵选择性地聚合上下文信息后,它可以获得全局的上下文感受野。同时通过类似的语义特征信息之间的彼此增益,可以使得语义更具一致性,且类内更加紧凑。
1.4.2 通道注意力模块
在本模块中[15],将探讨通道之间的互相依赖关系,因为每个通道都可以表示为专注于类的响应。利用通道信息进行分类,可以挖掘更多有用的特征来生成目标区域建议。如图8,通道注意模块的整体结构与空间注意模块相似。然而,在这个模块中开始不用通过1×1 卷积对A进行降维,Q,K,V直接使用A的值,K转置后与Q进行矩阵乘法,得到C×C的空间注意力矩阵S,空间注意力矩阵S,在将该矩阵执行softmax 函数后即可得到,可以表示为
其中,sncmc表示第mc通道对第nc通道的影响,然后将原始特征A跟注意力矩阵S进行矩阵乘法,即可选择性地传播通道信息。同样,可以使用另一个初始化为0 的可学习比例参数μ来加权聚合特征和原始特征:
上式表明,为得到特征映射之间的长期语义依赖关系,将所有通道的特征和原始特征进行加权求以获得每个通道的输出特征,从而得到更加容易辨别的特征。
1.5 解码器及损失函数
对于点云分割任务,解码器部分使用最近邻点上采样方法,如图1,通过4 层的上采样后,获得最终的点级特征;期间,编、解码器的特征图使用跳跃连接,将相同分辨率的编码器部分的特征图串接到解码器每层上采样的输出特征中,需要注意的是,本文编码器双路径网络中都是5 层卷积层,并且对应层的特征维度参数相同,因此可以将两条路径中的特征图都跳跃连接到解码器,以便获得更加丰富的上采样信息;然后使用类似图像中的卷积或MLP 的一元卷积处理,即可得到逐点分类结果,即实现了点云分割。
点云分类任务相对于点云分割框架稍微简单一些,在编码器部分最后经过注意力层之后,最终得到的融合特征通过全局平均池化层聚合特征,然后通过全连接层和softmax 层处理,输出最后的类别信息。
对于分类和分割任务,本算法都采用的是交叉熵损失LCE,可以很方便地进行反向传播计算,同时针对本文提出的双路径相互学习模块,据两条路径中的5 层卷积层设置一组损失函数,因此网络的总体损失函数为
2 实验与结果分析
本文的算法采用Python 3.7 编写,使用Pytorch 1.7.1 神经网络框架,在Ubuntu 16.04 的系统环境下运行。计算机配置为Intel Core i9-10940X 型号的CPU,NVIDIA RTX A6000,48GB内存的显卡。在3 个公共数据集上测试、评估所提出的网络,证明本文所提出模型性能的优越性。使用ModelNet40[18]数据集进行分类任务测试,S3DIS[19]和SemanticKITTI[26]数据集进行点云分割任务测试,并分别与当前分类、分割领域最新的主流算法的精度进行对比。最后设置一组对比消融实验,设计几种不同的模型变体来突出引入Transformer 自注意力机制后,给模型性能带来的提升。另外还给出了本文算法的效率分析,证明所提算法的合理性和有效性。
2.1 M odelNet40 数据集上的分类实验
ModelNet40[18]数据集总共包含12 311 个CAD模型,涵盖40 个对象类别,它被广泛应用于点云形状分类测试。为了进行公平比较,使用官方设置方式,9 843 个对象用于训练,2 468 个对象用于测试评估。具体在网络的训练过程中,进行了数据缩放、翻转和增加扰动来扩充输入数据,使用结合动量的梯度下降法来最小化交叉熵损失,批处理大小设置为16,动量设置为0.98,初始学习率为10-3,并按照每100 个训练批次除以10 的方式对学习率进行指数衰减策略,在最后的全连接层使用概率为0.5 的dropout 层,设置300 个训练批次进行训练,网络最终收敛在250 个训练批次左右。
如表1 所示,使用总体精度作为评价指标,将本文的模型算法与当前最新的算法PointNet[3]、PointNet + +[4]、SO-Net[21]、ConvPoint[22]、PointCNN[6]、PCNN[7]、PointWeb[5]、PointConv[23]、A-CNN[24]、PointASNL[25]、KPConv[12]就ModelNet40的分类精度结果进行对比。值得注意的是,本文特别加入了使用核点卷积的两种原模型Rigid KPConv、Deform KPConv 和FPC 原模型来进行比较,可以看出本文的算法达到了93.2%的最佳精度,体现了本文的模型在实现分类任务上的优越性。
2.2 S3DIS 数据集上的分割实验
S3DIS[19]是用于点云语义分割的大型室内场景数据集,共有2.73 亿个点,标注有13 个类别,覆盖了3 个不同建筑的6 个大型室内区域。图9为该数据集在区域1 的示例图,图中右边部分是对局部场景加了语义标签后的放大图。
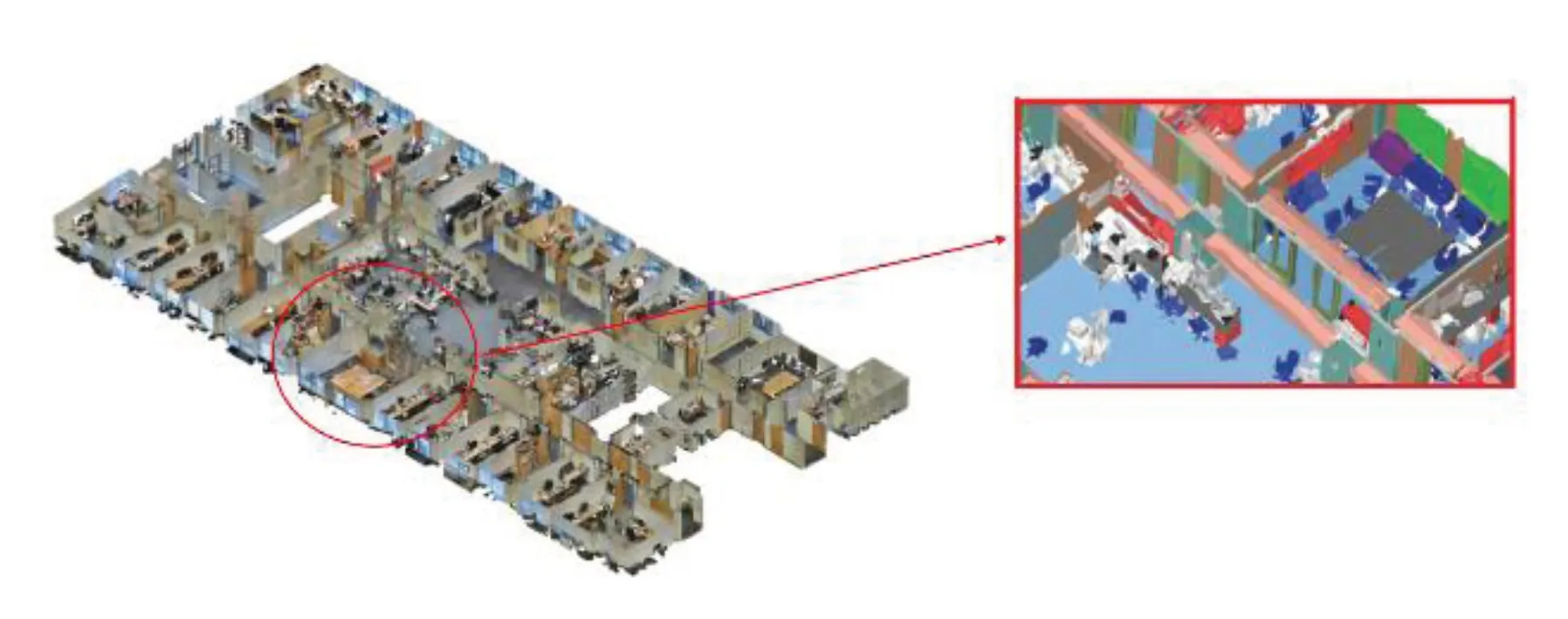
图9 S3DIS 数据集部分示例Fig.9 Part example of S3DIS dataset
在训练过程中,同样使用结合动量的梯度下降法来对逐点的交叉熵损失进行优化,批处理大小大小设置为8,动量设置为0.98,初始学习率为10-2,同样按照每100 个训练批次除以10 的方式对学习率进行指数衰减策略,但最后不再使用dropout 层,设置500 个训练批次进行训练,网络最终收敛在450 个训练批次左右。与大多数方法一样,使用区域5 作为测试场景,以更好的衡量模型的泛化能力,表2 中,与当前最新的主流算法PointNet[3]、SEGCloud[10]、PointCNN[6]、SPG[11]、PCNN[7]、PointWeb[5]、PCT[20]、RandLA-Net[28]、PAConv[32]、KPConv[12]在区域5 进行测试精度对比,如表2 所示。使用语义分割领域最常用的交并比(Intersection over Union,IoU)作为评价指标:
AIoUi表示当前第i个类别的交并比精度,Pi和Gi分别表示当前类别下的预测值(Prediction)和真值(Ground Truth),AmIoU为13 个类别的平均交并比。表2 给出了当前各个算法在包括天花板、地板、桌子等13 个类别上的分类别AIoU结果对比。AmIoU可以更直观地展现当前算法的精度情况,见表2的第二列。
可以看出本文的模型相对其他算法优越性,在AmIoU指标下取得了69.3%的高性能,跟核点卷积的两种原模型Rigid KPConv、Deform KPConv 以及FPC 原算法比较也可以看出本文模型的性能有很大提升。同时具体在13 类具体类别AIoU精度上,本文的模型在7 种类别上取得了最高分割精度。
为了更加直观地展示本文所提算法的效果,将S3DIS 数据集场景中的分割结果进行了可视化。如图10 所示,图(a)为该场景下地面真实语义标签图,图(b)为使用本文算法模型在同样场景的语义预测结果,图(c)为所提算法的预测结果相对于地面真实标签的误差对比。对应表2 可以看出,跟当前大部分先进算法一样,除了在一些像梁、柱这样结构特征信息较少的物体以及像多个桌子、椅子密集分布情况下的误差较大外,本文算法在场景中大部分类别上都能实现较准确的分割效果。
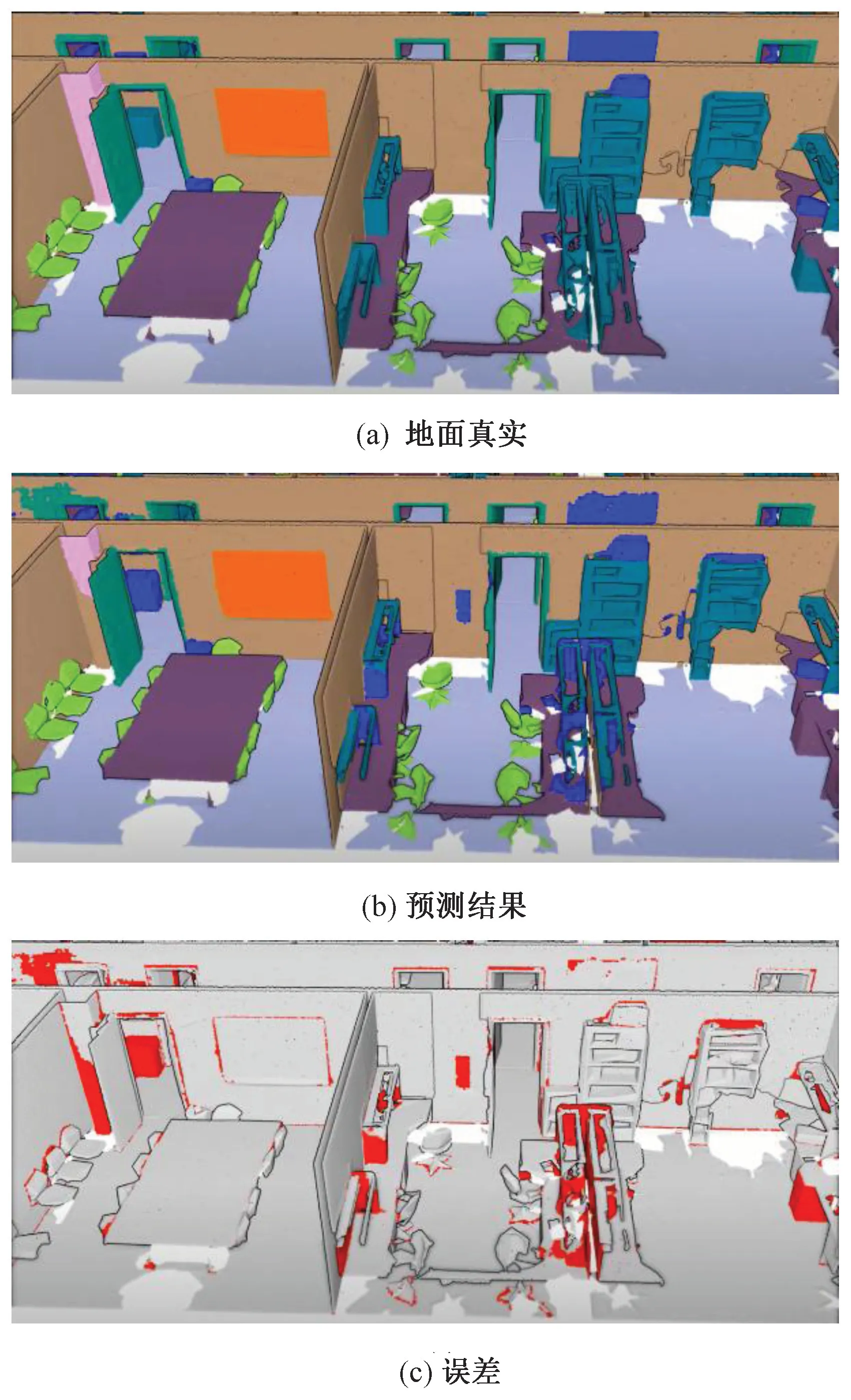
图10 S3DIS 数据集场景分割可视化结果Fig.10 Visualization results of S3DIS dataset scene segmentation
2.3 SemanticKITTI 数据集上的分割实验
SemanticKITTI[26]数据集是一种大型室外自动驾驶场景数据集,它是点云语义分割算法最常使用的一种激光雷达数据集,非常具有代表性。总共由43 000 多个密集注释的激光雷达扫描组成,包含汽车、行人、道路等19 个语义标签。按照数据集官方文件定义的序列划分,分为22 个序列,其中00-10 序列包含真实标签,使用08 序列作为验证集,00-07 以及09-10 序列作为训练集,剩余的11-21 序列没有真实标签,因此作为测试集。
训练时令批处理大小为4,设置动量为0.98,初始学习率为10-2,同样按照每100 个训练批次除以10 的方式对学习率进行指数衰减策略,最后不使用dropout 层,设置150 个训练批次进行训练,网络最终收敛在120 个训练批次左右。
同样使用AIoU作为评价指标,将本文算法与应用SemanticKITTI 数据集的代表性先进算法进行比。如表3 所示,给出了本文算法与其他算法PointNet[3]、PointNet + +[4]、LatticeNet[27]、RandLANet[28]、SqueezeSegV3[29]、CNN-LSTM[30]、KPConv[12]、FusionNet[31]针对所有类别的平均交并比AmIoU以及每个类别各自的AIoU的精度对比。

表3 SemanticKITTI 数据集上各算法的平均分割精度(AmIoU)及逐类别精度(AmIoU)对比Tab.3 Comparison of average segmentation accuracy (AmIoU)and each category accuracy(AmIoU) of algorithms on SemanticKITTI dataset
可以看出本文算法取得了当前先进精度。相对于其他算法,第二行AmIoU指标取得了63.2%的最高性能。由于原 FPC 算法没有在SemanticKITTI 上进行实验,因此只能跟原KPConv算法比较,可以看出本算法的AmIoU有将近5%的提升,有效证明了本算法对于性能提升的作用;同时在19 种语义类别的逐类别AmIoU指标上,本算法在10 个类别上取得了最高精度的效果。
同样,为直观展现本算法的有效性,将SemanticKITTI 数据集08 序列(验证集)上的分割结果进行可视化展示,如图11。图分为两行,每一行表示一次雷达扫描帧,在此选取了两帧来进行结果展示,图(a)为原始雷达输入,图(b)为本文算法的预测结果,图(c)为真实标签图,可以较为明显地看出本算法在道路、植被、建筑、汽车等相对占地面积较大的语义类别中取得了出色的的分割精度,只有在较远处或相对细微处的预测标签出现一些错误,如移动着的行人、较小的交通标识。

图11 SemanticKITTI 数据集场景分割可视化结果Fig.11 Visualization results of SemanticKITTIdataset scene segmentation
2.4 消融实验
为了能够更加直观准确地体现本文加入注意力模块的原因,专门设计了一组对比消融实验。将图1 中的空间注意力模块以及通道注意力模块去掉,保留其他结构作为基线(Baseline,BL)模型;在BL 的基础上分别加入空间注意力模块(Spatial Attention,SA) 和通道注意力模块(Channel Attention,CA);以及如图1 一样,同时使用SA 和CA,由此得到4 组模型变体在S3DIS 分割数据集上进行对比实验。如表4 第2 列,在只有BL 时的AmIoU精度为67.9%,精度已经高于KPConv 和FPC 原算法;在加入了SA 后精度提升了将近1%;加入CA 后相对逊色一些,精度提升了0.5%;同时加入两个模块精度提升了1.4%,充分验证了双注意力模块引入的有效性和可实施性。

表4 不同的模型变体在S3DIS 数据集上的分割精度对比Tab.4 Comparison of segmentation accuracy of different model variants on S3DIS dataset
同时,本文最终采用的模型在13 类分类别精度中的大部分类别中都取得了最高精度,见表4。这有效证明了本文所提出DPA-Net 网络在加入双注意力模块后能提取更多的上下文信息,提升最终的精度。
2.5 算法效率分析
如表5 所示,系统地评估本文算法网络在真实大规模场景下进行3D 点云语义分割的效率。使用相同的评价标准,在SemanticKITTI 数据集上将本文训练的模型与其他代表性算法网络进行比较。使用08 序列验证集,共有4071 个点云扫描帧。将每种网络的总参数量、网络单次运行可以处理的最大3D 点云数量以及跑完一次08 序列消耗的时间进行对比。可以看出,综合内存、时间等方面的消耗,RandLA-Net[28]单次推断的效率最高,但其后续需要多重评估来最小化随机采样带来的影响,势必会增加消耗。本文算法融合KPConv、FPC 两种卷积算子,但搭建的卷积层数远小于两种原算法网络;注意力层的引入只会增加有限的参数量;网络中的其他结构更多的是1×1 卷积或者共享参数的MLP,其参数量很小。因此结合AmIoU精度来看,本文算法在没有过多地增加消耗的情况下,精度有了巨大提升。

表5 SemanticKITTI 数据集上分割的效率对比Tab.5 Comparison of efficiency of segmentation on SemanticKITTI dataset
3 结论
本文提出了一种双路径卷积的三维点云分割算法DPA-Net,用以进行点云分类和分割两种任务。在点云分类数据集ModelNet40 上的总体精度相对于主要参考算法有了较大的提升,达到了93.2%;在点云分割数据集S3DIS 上的分割交并比精度达到了69.3%,相对于KPConv、FPC 分别提升了3.9%、6.5%,改进效果明显,此外,在本数据集上进行的消融实验充分证明了引入注意力模块的有效性;在SemanticKITTI 分割数据集上的交并比精度达到了63.2%,相对于KPConv 提升了4.4%,相对于其他先进算法,同样具有明显优势,同时,就网络总参数量、运行消耗时间进行的算法效率评估表明,本算法在没有过多增加消耗的情况下,精度有了巨大的提升。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2021年2期)2021-06-09
应用数学(2020年2期)2020-06-24
电子制作(2019年11期)2019-07-04
数学年刊A辑(中文版)(2018年2期)2019-01-08
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
数学物理学报(2016年3期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
