
多种缺失模式下交通数据组合近似填补方法
2023-12-28 02:53郭凤香黄金涛陈昱光郭延永刘攀
交通运输系统工程与信息 2023年6期
郭凤香,黄金涛,陈昱光,郭延永,刘攀*
(1.昆明理工大学,交通工程学院,昆明 650504;2.东南大学,交通学院,南京 210096)
0 引言
交通数据采集和处理是城市智能交通系统构建的关键,而完备的道路交通信息则是把握路网动态所必需的。但是,在实际环境中交通数据的采集设备常会因设备故障或传输故障等问题导致所采集的数据是缺失的。对于缺失数据传统的做法是直接删除,但这样做往往会严重影响样本分布,导致下游任务无法顺利展开,进而影响最终结果。为了解决上述问题,对这些缺失数据进行相应的补全成为研究的关键。近年来,随着计算能力和统计学方法的不断发展,针对缺失数据的研究得到了显著进展。各种复杂而灵活的缺失数据处理方法应运而生,目前,主流的数据填补方法分为3种,即插值填补法、预测填补法和统计学习填补法[1]。
对于连续且具有时间特性的交通数据来说,相邻的数据之间存在关联性,因此使用相邻非缺失数据的均值进行插值填补十分有效。简单的插值方法如线性插值和样条插值法,但这类方法只考虑前后数据特征,无法处理高缺失率及高维度的缺失情况。K-最近邻算法(KNN)对于处理时间关联性数据具有特别优势,因此被广泛用于数据填补。Zhang 等[2]改进KNN 模型通过计算缺失数据和所有训练数据之间的灰度距离,为缺失数据选择K最近邻为缺失数据进行补全,但该方法填补效果依赖于参数选取,填补效率不高。Cheng 等[3]建立了一种自适应时空K最近邻模型,综合考虑城市交通的空间异质性,模型的泛化能力较强,但该方法适用于短时随机缺失,对于长序列连续缺失,适用性不高。
预测填补法主要是解决完全缺失数据填补问题,可根据历史数据和其他相关特征属性利用相关预测方法估计缺失值。典型的方法如自回归综合移动平均(ARIMA)[4]、支持向量机(SVM)[5]、人工神经网络(ANN)[6]等。随着数据量的激增,机器学习和深度学习被广泛应用于缺失数据预测。Zhang等[7]提出一种基于图卷积网络模型的交通数据完成模型,结合时空特征推导缺失值,但模型仅对时空依赖关系明显的交通参数具有良好效果,对时空关系不显著数据的填补效果则差强人意。考虑到不同交通场景信息对数据填补的影响,Yang等[8]提出了一种时空可学的双向注意生成对抗网络来进行数据补全,模型可自主学习优化参数,在低维数据补全任务中性能得到改善。对于高维复杂交通数据,Wu等[9]设计了一个多注意张量完成网络来进行数据补全,增强了对复杂数据缺失补全。这种基于网络模型的预测方法总体效果较好,但对于小样本数据,模型就会失效,即数据量不足,模型无法训练。此外,对于多变量随机缺失,由于填补位置分散,缺失数据所处位置前后不一,使得填补工作复杂化。
统计学习方法通常会对数据集分布进行先验假设,缺失值也适应相关的分布。例如,Lei等[10]引入时空高斯过程(GP)先验来模拟低秩矩阵分解框架中的潜在因素进行数据填补,模型改进了GP 超参数学习方法,强调对交通数据的时空一致性描述。Wu等[11]利用交通数据的全局和非局部低阶先验,提出一种用于时空交通数据插补的张量完成模型,但该方法仅考虑了随机缺失,相对于连续缺失,该方法并不适用。Huang等[12]提出一个基于概率一般线性模型的主成分分析来解决数据随机丢失问题和交通速度数据的估算问题,该方法对城市多样交通数据补全效果欠佳。
综上,现有研究仍有以下几点不足:(1)基于深度学习的数据填补方法需要一定的数据量才能完成模型训练,且模型的超参数较多,对超参数的优化开销太大,因此对小样本数据的填补任务适应度不高。(2)当数据缺失模式为随机时,缺失数据的插补方法多依赖于相邻数据进行插值处理。而由于采集设备故障或在某一时段该地无检测设备响应导致的数据连续丢失,一般的插值方法就会失效,故而针对不同的数据缺失类型需要更换不同方法,影响填补效率。(3)对于数据连续缺失问题,常使用预测填补法和统计学习方法来解决,但预测填补法无法使用后续数据对靠前数据进行预测补全,同时在实际中交通数据分布随机且复杂,故而仅凭统计学习方法假设数据满足相同分布亦会使得插补误差增大。
针对上述数据缺失场景各填补方法存在的问题,本文提出一种多种缺失模式下交通数据组合近似填补方法。利用最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)进行填补增强模型在小样本数据的适应性;为了提高模型效率,使用鲸鱼优化算法(Whale Optimization Algorithm,WOA)优化LSSVM的超参数,解决模型部分参数人工选取问题。根据缺失数据自身的单变量特征以及与其相关的多变量特征,引入多重插补的思想,分别对缺失数据进行单变量填补和多变量填补,提取缺失数据的自身变化规律及长期波动特征,解决模型在多种缺失模式下的一法多用问题。最后依据单变量填补和多变量填补的差异度,提出使用自适应阈值分割法赋予不同时段的阈值,根据动态阈值对单变量填补结果和多变量填补结果进行加权求和后输出,以满足不同时段多种交通数据缺失场景,为研究交通数据补全提供新思路。
1 研究方法
1.1 整体框架
对于缺失填补主要有两种思路,即单变量填补和多变量填补。单变量填补主要利用单变量信息,填补缺失数据;而多变量填补则是利用与缺失变量相关的其他变量信息对缺失数据进行填补。将两者相结合提出基于WOA-LSSVM模型的组合近似填补方法,方法流程如图1所示。首先根据单变量填补和多变量填补特征构建训练数据集,对于单变量数据,利用滑动窗口分别对q个特征列H构建单变量数据样本;对于多变量数据则是以缺失数据所属变量为标签,以该变量相关的其他变量为特征输入构建多变量数据样本。再根据单变量样本数据,使用WOA-LSSVM 模型进行单变量填补,将填补结果输入到多变量数据样本的特征输入中作为训练数据集,利用WOA-LSSVM模型来预测缺失值,同时引用链式多重填补思想,将预测结果与原值进行比较分析后,输出多变量填补结果。最后考虑到交通的周期性特征使用自适应阈值分割法划分不同时段下的动态阈值,依据阈值将单变量填补结果和多变量填补结果结合完成缺失值填补。
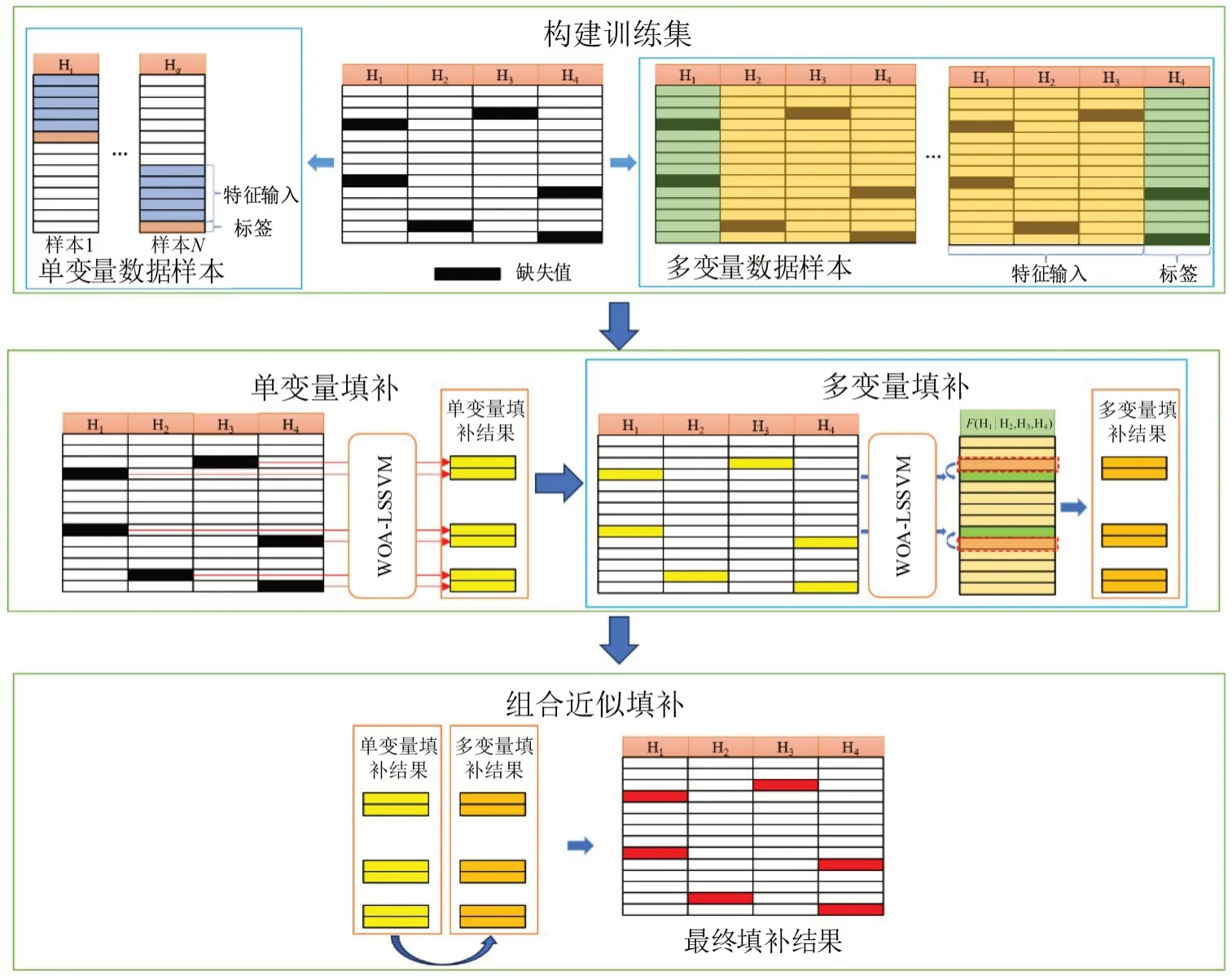
图1 组合近似填补方法流程Fig.1 Combined approximate fill method flow
1.2 基于鲸鱼优化算法的LSSVM改进模型
LSSVM 是在SVM 基础上建立的一种改进算法,LSSVM以等式约束条件代替标准SVM中的不等式约束条件,采用最小二乘线性系统误差和作为损失函数,降低模型复杂度,减少训练时间,克服数据量较少的问题。
将采集的路网浮动车实时运行数据进行预处理,处理后构建训练集D={(xi,yi)|i=1,2,…,n},其中,xi为第i个输入样本,yi为第i个输出样本,n为样本数。模型的优化目标与约束条件为
式中:J(·)为损失函数;w为权重向量;b为偏差参数;φ为核函数;γ为惩罚因子;ei为第i个样本的随机误差。
LSSVM 的核函数K(xi,xj)对模型的鲁棒性及泛化能力有着较高的影响,大量研究表明,高斯径向基(RBF)函数在预测任务中表现良好,因此本文选取RBF作为核函数,即
式中:xj为第j个输入样本;σ为核函数宽度。
LSSVM的预测精度取决于核函数宽度σ及惩罚因子γ,不合理的参数设置容易使LSSVM 陷入局部最优,导致模型预测精度不佳。故本文引入鲸鱼优化算法(WOA),进行全局寻优,以提高模型建模精度。其优化流程如图2所示,具体步骤如下。
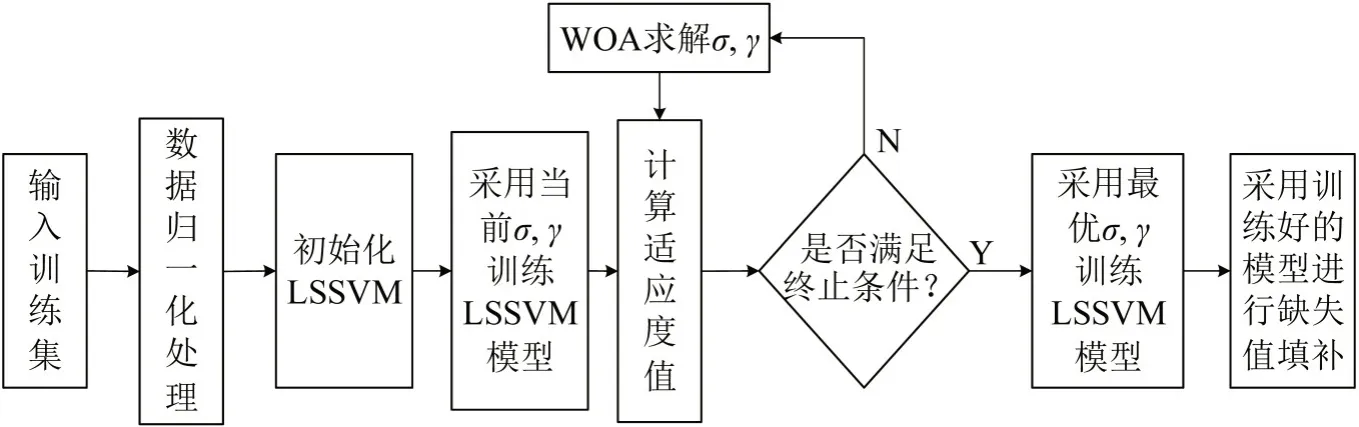
图2 WOA-LSSVM模型Fig.2 WOA-LSSVM model
Step 1 为统一量纲,减少样本数据存在数量级的差距,将样本数据做归一化处理。
Step 2 WOA初始参数设置。主要设置变量数Vdim、最大迭代次数tMaxiItem,鲸鱼种群规模为S,变量下限bl及变量上限bu。
Step 3生成初始位置坐标X0(γ,σ),基于初始位置构建LSSVM模型,并进行模型训练。
Step 4 根据预测结果计算LSSVM模型的均方根误差(RMSE)作为适应度值,保留最小适应度值对应最优鲸鱼位置坐标X*(γ,σ),作为当前最优个体位置。
Step 5 若迭代次数t <tMaxiItem,则根据选择收缩包围机制概率P和系数向量A,更新位置坐标。
当 |A|<1且p <0.5 时,更新位置为
当 |A|<1且p >0.5 时,更新位置为
当 |A|≥1时,更新位置为
式中:t为迭代次数;X(t)为当前鲸鱼位置坐标;X*(t)为鲸鱼最优位置坐标;D为鲸鱼与猎物之间的距离;C为系数常量;g为常数用于定义螺旋形状;l为[-1,1]中的随机数;Xrand(t)为随机坐标,即当|A|≥1 为随机搜寻方式,当 |A|<1 时,选择螺旋包围方式。利用更新后的位置坐标训练LSSVM模型。
Step 6 重新计算模型预测的均方根误差,保留最小适应度的鲸鱼位置坐标,并输出结果。
1.3 组合近似填补方法
数据填补主要考虑两种情况,即单变量填补和多变量填补。单变量填补顾名思义就是利用缺失数据自身的变量信息进行模型训练,强调捕捉单个变量内在的变化特征,完成数据填补。而多变量填补则是利用与缺失变量相关的其他变量信息构建模型进行填补,达到获取连续缺失信息的目的。以往对于多变量填补多使用链式多重填补,未考虑缺失变量自身的内在规律,因此本文提出组合近似填补方法(CAF),其填补流程如下。
Step 1 构建数据集
标记数据集中各属性变量缺失值。依据单变量和多变量的特征,分别构建训练数据集。对于单变量样本,需要先剔除缺失值,将数据集中的数据分组,每组前k个值作为特征输入,第k+1 作为标签,滑动步长默认为1 构建训练集,如图3(a)所示;对于多变量填补是以缺失数据所属变量为标签,以该变量相关的其他变量为特征输入构建多变量数据样本,如图3(b)所示。

图3 训练集构建过程Fig.3 Training set construction process
Step 2 单变量填补
利用单变量样本数据集训练WOA-LSSVM。然后针对单个变量特征的缺失值使用训练后的模型进行填补,输出单个变量缺失值的填补结果yui。
Step 3 多变量填补
将Step 2 中的输出结果补全多变量样本数据集中的特征输入,完善训练集后进行WOALSSVM 模型训练,最后使用训练后的模型对整个缺失数据特征列进行预测。此时得到的数据并非数据的填补值,还需要将预测结果与缺失数据列进行对比分析,依据预测结果,选取与缺失值预测结果相近的值作为参照,设置邻近匹配数(Number of Proximity Matches,NPM)来限制匹配邻近值的参考数量,假设NPM 为3,则计算3 个邻近预测值均值与原数据值的比值,根据比值对缺失数据预测值等比例缩放后得到多变量填补结果。对所有缺失属性均执行上述操作,直到所有特征属性无缺失值,得到多变量填补结果ymi。
Step 4 组合近似填补
以Step 2 和Step 3 填补结果为基础设定阈值,当两者填补结果差异度超过阈值,选取最大结果作为参考对模型填补结果进行修正;当两者填补结果差异度低于阈值,选取最小结果作为参考对模型填补结果进行修正,修正后得到最终结果。计算公式为
考虑到交通数据的周期性特征,不同时段数据分布特征不同,本文引入图像识别中的自适应阈值分割法,其思想不是计算全局阈值,而是针对不同局部区域自适应计算不同阈值。因此对不同时段内的数据依据填补结果差异度划分不同阈值,避免不同交通流状态下填补界限模糊。该阈值设置为在时段T下所有缺失位置的差异度平均值,以实现不同时段阈值的自动确定,从而对不同时段下的不同阈值进行自适应,其计算公式为
式中:M为在t时段下缺失值数量。
2 实验分析
2.1 数据介绍
利用车载诊断系统(On-Board Diagnostics,OBD)采集获得云南省玉溪市实车轨迹数据,数据采集频率为6 s·次-1。数据字段包括车辆代码、GPS时间、车辆定位信息、速度集合等信息,其中,每次上传速度数据为6个,即可认为速度数据采集频率为1 s·次-1。采 用2022 年2 月21 日 和22 日9:00-19:00的浮动车轨迹数据,处理后得到6291450个轨迹点。本文共选取8 条路段,如图4 所示。提取各路段轨迹数据,按5 min 时间间隔计算路段平均速度和路段平均行程时间,同时根据轨迹数据计算对比度(CON)和逆方差(IDM),以分别描述车辆的加减速工况和怠速工况[13]。最终得到道路完整参数数据集如表1所示。
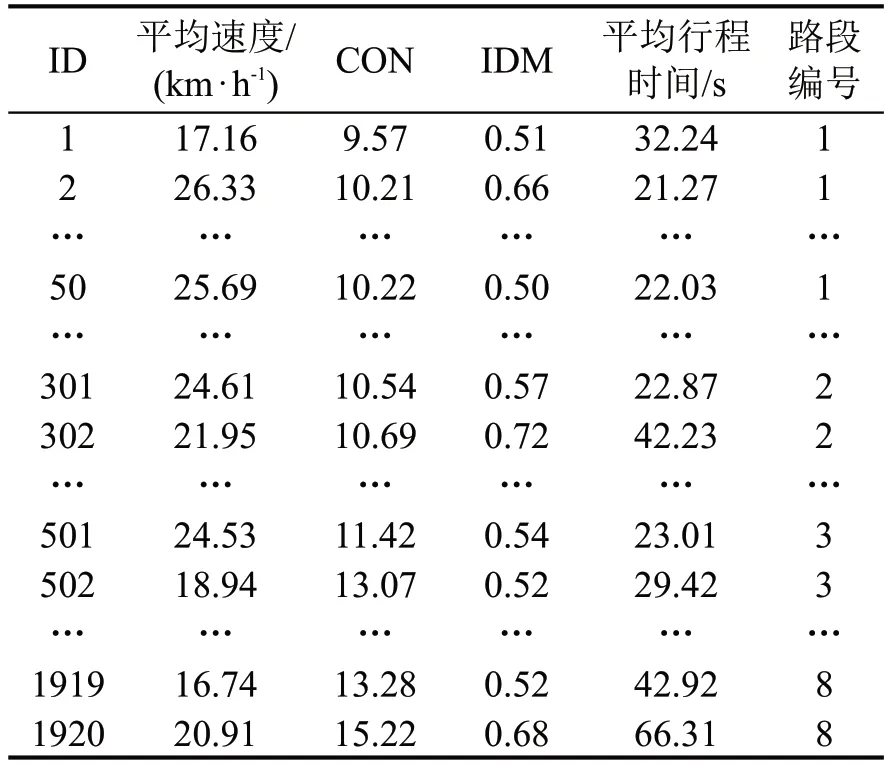
表1 道路参数数据集Table 1 Dataset of road parameters
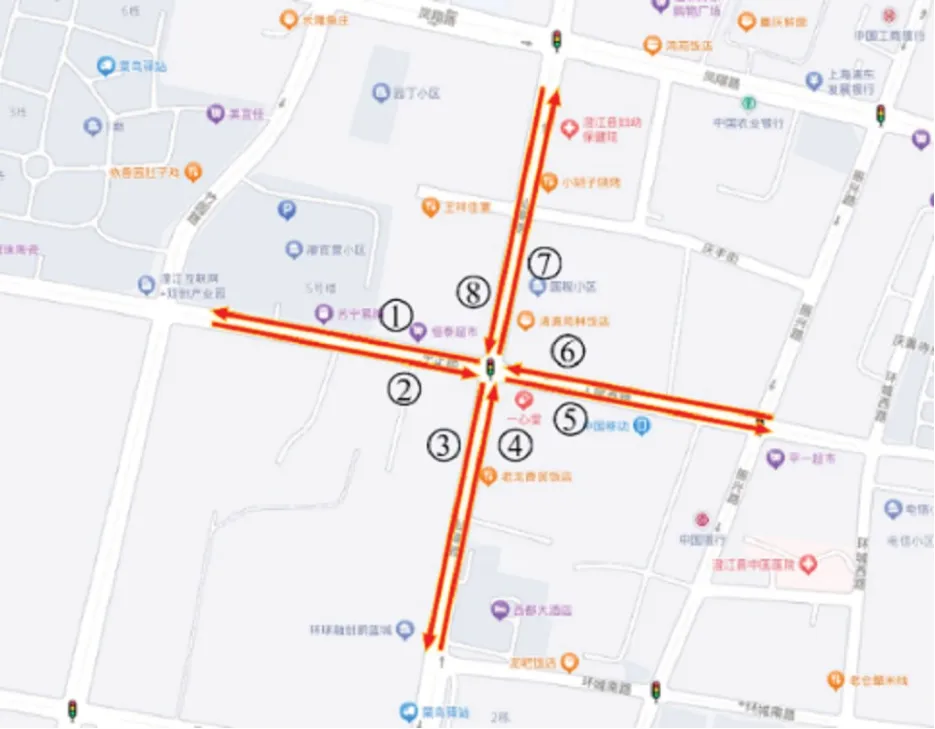
图4 实验路段Fig.4 Experimental section
2.2 实验设计与评价指标
为验证本文填补方法的有效性,同时针对交通数据缺失特点设计两种缺失模式:一种是由于浮动车分布不均导致路段短时间内没有车辆经过产生随机缺失,如图5(a)所示;另一种是由于设备问题导致路段上数据的连续缺失,如图5(b)所示。为还原数据缺失随机性,在完整数据集中利用随机函数还原两种缺失模式。同时,利用链式多重填补(MICE)[14]和K-最近邻(KNN)填补[15]与组合近似填补(CAF)方法进行对比,以比较模型填补效果。阈值更新时间为2 h,其他模型的初始参数设置如表2所示。

表2 实验初始参数设置Table 2 Initial parameter settings for experiment

图5 缺失模式Fig.5 Missing patterns
本文使用两个评价指标来评价模型的补全效果,分别为平均绝对误差(MAE)和均方根误差(RMSE),其表达式为
式中:N为缺失数据个数;Yi为第i个实际值;为第i个填补值。
2.3 补全效果分析
为探究不同缺失模式下多变量填补模型和单变量填补模型填补效果的差异度,本文在上述两种数据缺失模式下,以5%的缺失率设计对比实验。以平均速度为列,利用WOA 算法进行迭代优化模型参数,迭代过程如图6所示。利用训练好的模型进行多变量和单变量填补其差异度结果如图7 所示。从图中可以看出,无论是随机缺失(图7(a))还是连续缺失(图7(b)),模型差异度较大的地方多集中于真实值中的低值,当缺失值低于10时,两种填补方法差距急剧扩大,最大差异度达到80%。这是由于在低数值阶段差异度的分母较小,放大了差异度,而在高数值阶段分母较大缩小了差异度。从两种缺失模式下的填补效果来看,随机数据缺失的填补结果更加稳定。这也表明,在不同数据量纲中简单地使用其中一种填补方式的填补结果过于片面,需要更多的数据参考,以增强填补效果。
图6 模型迭代图Fig.6 Model iteration diagram

图7 多变量与单变量填补差异度Fig.7 Multivariate versus univariate imputation dissimilarity
为对比CAF 的填补效果,选取MICE 和KNN作为基线模型进行对比,以平均行驶速度和平均路段行程时间为例,当缺失率为5%时,3 个模型的填补结果如图8 所示。从图中可以看出:3 个模型的填补值与真实值分散程度相近,模型在随机缺失模式下补全效果最好;在连续缺失情况下由于长序列缺失,使得模型填补误差较大,但模型CAF的填补表现较KNN和MICE优异。此外,对比平均行驶速度和平均路段行程时间的填补效果可以看出,当缺失数据离散程度较高时,模型的填补难度增大,相较于KNN 捕捉缺失数据的变化趋势和MICE 提取缺失数据的波动情况,CAF利用单变量和多变量进行组合填补达到同时提取缺失数据变化趋势和波动情况的目的,继而提高缺失数据补全准确性。

图8 模型填补结果Fig.8 Model filling results
为进一步比较3种方法的填补效果,以路段平均速度为填补对象,改变缺失率,研究在两种缺失情况下,不同缺失率模型的填补效果,结果如图9所示。从图中可以看出:随着缺失比例的升高,模型的误差增高;在平均速度随机缺失的情况下模型的RMSE 和MAE 比数据连续缺失更低,当缺失率达到30%时最为明显;数据随机缺失情况下,CAF模型的RMSE仅为0.37,而连续缺失情况下CAF模型的缺失值为1.81,这说明模型对随机缺失适用性更好。本文提出的CAF 缺失值补全方法在各种缺失概率下均优于另外两种缺失补全算法,尤其是在连续缺失填补中,CAF 的RMSE 和MAE 均远低于对比算法,当缺失率为25%时,CAF相较于KNN和MICE的平均绝对误差(MAE)下降了70%。原因在于本文算法考虑了其他变量特征对缺失变量的影响,继而掌握了缺失变量值的长期波动,同时也考虑了自身数值的变化规律,能够更好地捕捉缺失数据本身的浮动规律,提高了缺失值的填补精度。

图9 不同缺失率下模型填补结果Fig.9 Model imputation results under different missing rates
3 结论
本文针对交通数据缺失问题提出基于WAOLSSVM 的组合近似填补方法,根据单变量和多变量的组合填补结果捕捉缺失数据的短期变化趋势和长序列的波动特征以提高缺失值补全精度。利用云南省玉溪市轨迹处理数据进行实验,根据实验结果可以得到以下结论。
(1)数据随机缺失情况下的填补效果优于连续缺失,数据连续缺失序列越长,填补误差越大。通过实验表明,模型在缺失率较大的情况下依然保持良好的填补精度,证明在利用数据本身时序规律的同时,提取其他相关变量间的关联信息,对提高缺失值填补精度有着重要作用。
(2)数据的离散程度对数据填补精度有着重要影响,尤其是针对连续缺失状态下,数据离散程度越高,填补效果越差。
(3)本文提出的组合近似方法可以轻松处理小样本混合数据,超参数少且可自主优化,降低填补的复杂性,提高了填补精度。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
童话世界(2020年32期)2020-12-25
河北理科教学研究(2020年2期)2020-09-11
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
小学生导刊(2018年16期)2018-07-02
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
数学年刊A辑(中文版)(2015年2期)2015-10-30
新高考·高二数学(2014年7期)2014-09-18
