
考虑天气影响的高速公路交织区交通运行状态识别
2023-12-28 02:53李岩陈姜会曾明哲徐金华汪帆
交通运输系统工程与信息 2023年6期
李岩,陈姜会,曾明哲,徐金华,汪帆*,3
(1.长安大学,运输工程学院,西安 710064;2.湖南省国土资源规划院,长沙 410007;3.中交第一公路勘察设计研究院有限公司,西安 710075)
0 引言
交通运行状态的确定是评价道路通行效率、发现交通拥堵瓶颈、制定交通管控决策方案的关键前提。传统交通状态以流量、密度、平均车速等交通流基本参数为评价指标,但在降雨、大雾、强风等不利天气情景下,相同的参数值运行状态同正常天气相比存在较大差异。不利天气会影响道路上驾驶员的自由流速度等特性[1],进而导致道路通行能力发生变化。高速公路交织区路段车流交织行为集中[2],导致各车道受不利天气影响存在较大差异。因此,建立考虑天气、车道等因素影响下高速公路交织区的运行状态识别方法,有助于高速公路管理者在面对不利天气下做出更合理的管控决策。
对交通运行状态的研究考量因素主要包括车流密度、交通量、匝道饱和度[3]等,多集中于分析道路交通流因素。然而雨、雾、雪等不利天气下驾驶员的行车会受到影响[4],尤其在高速公路交通速度较高的情况下对不利天气更敏感[5],导致高速公路运行速度、道路最大通行流量等受到影响[6]。因此对高速公路交通运行状态识别应充分考虑不利天气的影响。
高速公路交通状态划分主要包括交通基本图建模方法、交通流视频图像识别和基于数值聚类划分等方法。交通基本图建模方法通过基本图形态或三相交通流理论划分交通状态[7]。交通流视频图像识别方法是通过监控视频提取交通图像特征参数,建立算法模型实现交通状态识别[8]。此方法复杂度较高,且对海量的交通视频不便处理。基于数值聚类划分方法是从数据角度出发建立聚类算法,利用检测器获得的连续交通流数据,将交通流划分为多种状态。其中,K-means 聚类方法能获取与《道路通行能力手册》(Highway Capacity Manual,HCM)服务水平标准最接近的状态划分结果[9]。当数据中同时包含数值型和分类型数据时,K-means等运用于数值型数据的聚类方法不再适用。为克服此缺陷,k-prototypes聚类算法集成了K-means和K-modes 算法[10],综合了对数值属性和分类属性的考量。该算法在考虑两种属性上简单高效,但衡量类别型数据只考虑频率最高的类,忽略了其他类别属性,在识别状态时仍存在偏差。
综上,本文以高速公路交织区为研究对象,结合天气因素与交通流参数的考量,探究在不同等级天气影响下交织区各车道交通特性的变化情况,并采用改进的k-prototypes算法构建高速公路交织区各车道交通运行状态识别的方法。
1 研究方法
1.1 影响因素集构建
交通运行状态影响因素分析是开展交通状态识别工作的基础及前提。考虑到高速公路交织区情况复杂,每条车道的流量、车型比例、车辆换道等情况均存在差异,同一指标体系不能表征所有车道的交通运行状态,因此对交织区进行分车道研究。如图1 所示,在天气的考量上,通过分析不利天气对交通流运行的影响状况确定天气等级,并筛选对交通运行状态影响较高的指标作为天气指标。

图1 交通运行状态影响因素集构建流程Fig.1 Procedures on constructing impact factor set of traffic operation state
考虑到传统交通流模型中,Van Aerde 模型对实测交通数据拟合效果好,同时适用于交通密度大和交通密度小的情况,并能刻画不同交通设施下的交通特性[11],因此本文选取该模型探究不利天气对交通流特性的影响。
为衡量指标对交通运行状态的影响程度,将实测点到Van Aerde拟合曲线上的最小距离定义为交通偏离度,用以描述交通流运行状态的稳定性,其绝对值越小,表明交通流越稳定。考虑到数据集中各等级天气样本数据量的不平衡性,以及指标间的相互影响,而随机森林模型能够在不平衡数据集中检测到特征指标间的关系,因此利用该模型以交通偏离度为因变量,其他指标为自变量,对指标进行重要度排序并结合各车道状态分类误判率与变量数的变化关系确定指标的数量。
1.2 交通运行状态识别方法
1.2.1 改进的k-prototypes交通状态聚类算法
交通运行状态表征体系中交通流、天气指标分别为数值型和类别型数据。传统算法对类别属性的表示是直接选择频率最高的属性值,在多个类簇出现频率最高的值相同时,数据对象到每个类簇的距离相同,导致不能准确将其划分到最近的类簇中。为克服此缺陷,引进熵值法对k-prototypes 聚类模型进行改进。熵值反映数据的离散程度,越离散熵值越大。分别用r 、c 表数值型和类别型指标,则第 j 个变量的数值属性Xj(1 ≤j ≤mr) ,表示在属性Xj下对象xi的取值所占的比重,其中,1 到mr为数值型变量,i为数据集中的第i 组数据,1 ≤i ≤n;对于类别属性表示在属性Xj下第t 个属性所占的比重,其中,mr到m 为类别型变量,ntj表示属性值为的对象个数,则各属性的信息熵表示为
在聚类过程中属性的重要程度与其值构成的差异度成正比,熵值越大属性的权重越高。属性Xi权重值为其中,1 ≤j ≤m ,
聚类中心的映射函数为
式中:zl为类簇Cl的聚类中心;nj为属性Xj下的数值型对象个数。基于权重和聚类中心的优化,相异性度量公式为
其中,数值属性相异度度量采用欧式距离,即
结合中心点表示方法,类别属性相异度度量为
1.2.2 聚类效果评价标准与算法流程
为有效评估混合型数据的聚类结果,提出聚类的有效性评价指标CUM。将混合型数据集U中的属性集A,分为数值型属性集Ar,类别型属性集Ac,假设类别数据被划分为k类Ck={C1,C2,…,Ck},该类别数据聚类的效用函数为
类别效用函数根据聚类结果和每个特征值的二元分布定义,不同于传统遵循实例之间的相似性和差异性的聚类标准。
在计算数值型数据的聚类时,假设数值型数据被划分为k类,Ck={C1,C2,…,Ck},其效用函数为
基于式(6)和式(7),混合型数据聚类结果的有效性指标为
式中:|A|、|Ar|、|Ac|分别为属性集中A、Ar、Ac的对象数量。当CUM越大,聚类结果越好。可通过以CUM最大为目标,来确定最优的聚类结果。
算法步骤如下。
输入:数据集,聚类数k。
Step 1 随机选取k个初始中心点。
Step 2 针对数据集中的每个样本点,计算样本点与k个中心点的距离。
Step 3 将样本点划分到离它最近的中心点所对应的类别中。
Step 4 重复Step 3,直到没有样本数据需更换簇。
Step 5 计算聚类有效性指标CUMi。
输出:各类别聚类中心,聚类有效性指标CUM。
最后结合聚类中心和改进k-prototypes算法计算各类别聚类中心的相异性距离值,用以衡量各类别与理想天气的贴近度,从而对交通运行状态进行等级确定。
2 数据来源与质量检验
2.1 数据来源
数据来源于国内京昆高速(G5,太原到晋中介休段)、二广高速(G55,朔州怀仁到山阴段及太原阳曲段)。A型交织区为最典型的交织区形式[12],以图2所示的A型交织区为例,将高速公路车道编号从中间带到右路肩依次从1 开始增序编号。数据包含:流量(Flow),车辆平均速度(Speed),交织区合流比(RMerge)与分流比(RDiverge),密度(Density),目标车道与邻近车道平均速度差值(DSpeed)及流量差值(DFlow),目标车道平均速度与交织区整体平均速度的比值(RSpeed)及流量占比(RFlow),大车流量占比(RTruck),交织区内检测器与上游检测器平均速度差值(UDSpeed)、流量差值(UDFlow)及密度差值(UDensity),交织区内检测器与下游检测器平均速度差值(DDSpeed)、流量差值(DDFlow)及密度差值(DDensity)等16 个指标。天气数据来源天气网、降雨量监测站等平台,包含降雨、能见度、风速、风向等数据信息。

图2 A型交织区形式Fig.2 Type A weaving segments
2.2 数据质量检验
为保证数据真实可靠,需对所采用的数据进行质量检验,根据交通流量、速度、占有率三参数阈值和相互关系剔除错误数据,并匹配交通流与天气数据,剔除缺失天气数据时段的指标。再验证所选检测器数据间的可比性,统一20 个A 型交织区各车道平均速度数据的量纲后,分服务水平等密度间隔进行Kolmogorov-Smirnov(K-S)分布检验。结果如表1所示,各车道平均速度在不同服务水平下均通过检验,即同类型交织区数据不存在显著差异。

表1 交织区速度分布K-S检验结果Table 1 K-S test results of velocity distribution in weaving segments
3 实例分析
3.1 天气对交通流特性的影响分析
根据汽车道路试验方法通则及气象等级标准确定理想天气[13]应符合以下指标:无降水,地面干燥,风速不大于3 m·s-1,能见度良好(大于4 km)。当其中一条不满足时即为不利天气。因此本文主要考虑降雨、雾、强风因素。降雨量依据国家气象局《降雨的等级划分》划分为6个等级。风速考虑到其对车辆行驶的影响程度以及高等级风速样本量过少原因,将12 级风中的0 级无风划为等级0,1级软风和2级轻风合并为等级1,3级微风和4级和风合并为等级2,5级清风和6级强风合并为等级3,7 级疾风和8 级大风合并为等级4,9 级烈风及以上合并为等级5。能见度参考标准《雾的等级及预报》并结合实际情况将其划分为7个等级,具体划分如表2所示。

表2 天气影响因素等级划分Table 2 Classification of weather impact factors
基于实测数据构建Van Aerde交通流模型得到不同等级降雨、能见度、风速下的流-密-速关系图。如图3所示,交通流三参数随降雨和能见度等级的上升而上升;0~2 级风速间交通流状态无明显变化,3 级及以上风速对交通流的影响显著。相比正常天气,各不利天气下交织区自由流速度、通行能力、临界速度下降幅度分别在3.60%~7.82%、11.23%~30.00%、8.41%~26.64%之间,堵塞密度受天气等级影响变化不明显。
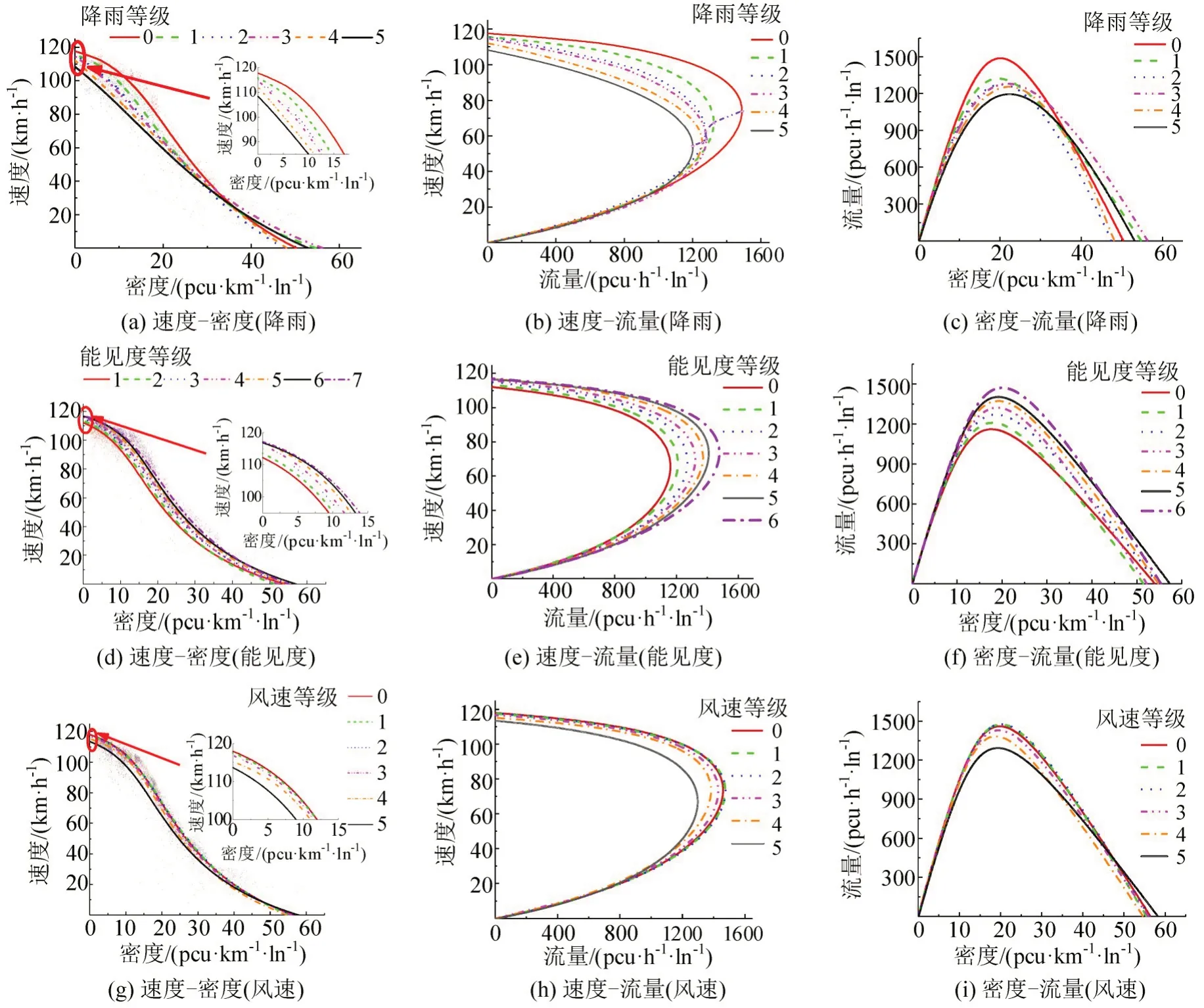
图3 不同天气影响因素等级下Van Aerde交通基本图Fig.3 Van Aerde traffic fundamental diagram under various weather influence factor levels
考虑到实际环境中,常同时受多种天气因素交互影响,故对各天气因素进行聚集划分。如图4所示,定义优先等级为恶劣天气>中度天气>轻微天气>正常天气,以满足的最高优先级对天气等级进行判定。

图4 天气等级划分Fig.4 Classification of weather level
3.2 交通偏离度与特征变量
图5 为交通偏离度划分结果,Van-Aerde 拟合曲线将实测数据点分割为两部分,拟合曲线u方向数据点的交通偏离度值为负,v向为正。LA为拟合曲线在拟合点A处的切线,B点的交通偏离度为线段AB的长。分车道计算交通偏离度,结果分布图符合标准正态分布,依据分布形式将其划分为3个等级。
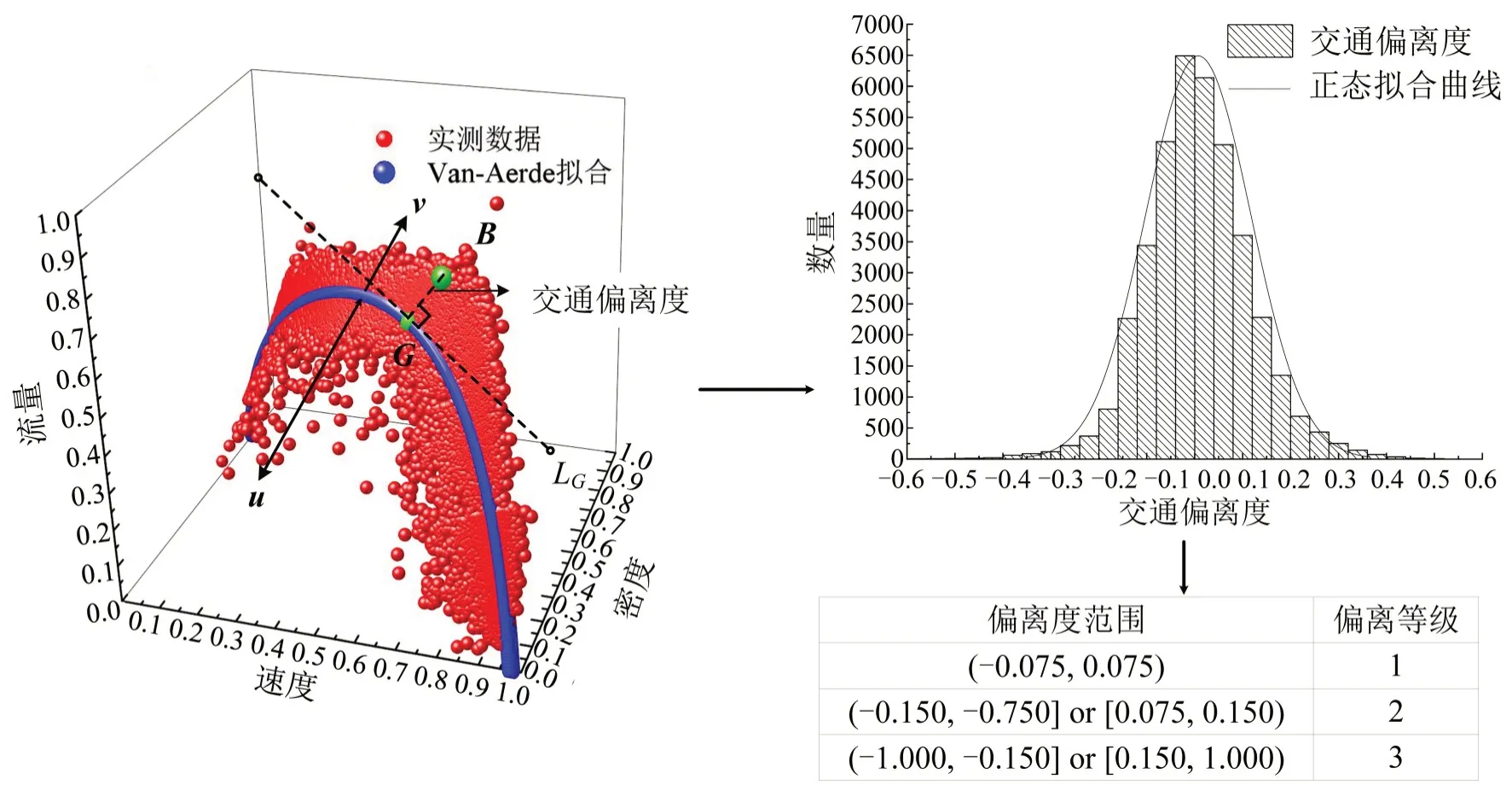
图5 交通偏离度划分结果Fig.5 Classification of traffic deviation
指标筛选如图6所示,特征变量中天气因素对各车道交通流运行的影响均很大。车道2和车道1的交织区合流比(RMerge)相差最大为0.079,其次是车道3 和车道1 大车流量占比(RTruck)相差0.077。确定指标数量如图6(b)所示,在特征数从1增加至6 时,分类误判率从7.8%~8.8%下降到了1.5%~2.5%,说明考虑多指标能增强对交通状态划分的准确性,但在数量大于6 之后,误判率出现转折。因此各车道对应变量均选择重要度排序前6的变量。
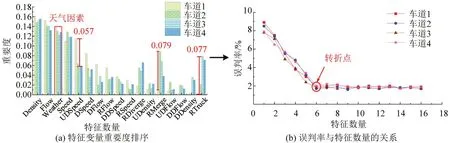
图6 特征变量筛选Fig.6 Results of indicator screening
3.3 交织区各车道交通状态特性分析
利用改进k-prototypes 算法对4 个车道的交通状态进行聚类并计算CUM值。如图7 所示,当聚类数为7时,各车道CUM达到最大值,即各车道交通运行状态划分为7类最佳。

图7 聚类有效性变化Fig.7 Analysis on effectiveness of clustering
各车道运行状态类别聚类中心如表3和表4所示。各车道类别3 的天气状态均为0 等级,车流量最高为60 pcu·(5 min·ln)-1,速度在100.1~119.2 km·h-1,密度最高为6.53 pcu·km-1·ln-1,将其定为最佳运行状态。

表3 交织区各车道交通运行状态三参数结果Table 3 Three traffic parameters for each lane in weaving segments under different status

表4 交织区各车道交通运行状态指标结果Table 4 Indicators on traffic status for each lane in weaving segments
计算其他状态类别与最优类别3的贴近度,结果如表5所示,车道1~车道4的交通运行状态从优至劣排序分别为:3-6-7-2-5-1-4,3-2-6-7-5-1-4,3-7-2-6-5-4-1,3-7-2-5-6-1-4。

表5 相异性距离计算结果及交通运行状态等级排序Table 5 Results of dissimilarity distance and ranking of traffic operational states levels
HCM 中将高速公路服务水平(Level of Service,LOS)根据密度临界值划分为A~F 共6 级,对比所提出方法得到交通运行状态的最大密度、最小速度范围,结果如表6所示。

表6 交通运行状态等级比较Table 6 Comparison of traffic operational states levels
从表6可以看出,在恶劣天气的影响下,车道1和车道3最大密度在A级LOS范围内,最小速度分别下降了11.2 km·h-1和17.4 km·h-1,按最小速度在HCM中均降为D级服务水平;车道2和车道4最大密度在C 级LOS 范围内,最小速度分别下降了21.2 km·h-1和27.4 km·h-1,按最小速度LOS均降为E。可见,在服务水平较低时,车道行驶速度受恶劣天气的影响下降更明显,且不同的车道受影响的程度亦不同。
在中度天气的影响下,车道1 和车道2 的LOS分别从D、E 级下降到F 级,最小速度分别下降了15.6 km·h-1和29.6 km·h-1;车道3 和车道4 的LOS分别从C、B 级降为E 级,最小速度分别下降了24.2 km·h-1和22.3 km·h-1;各车道在服务水平较低时受天气影响程度更大。
在轻微天气的影响下,车道1 和车道2 的LOS均从A下降到C,最小速度分别下降了8.6 km·h-1和9.0 km·h-1;车道3的LOS从C下降到F,车道4从B下降到E。此外,车道4 的各状态密度最大为28.98 pcu·km-1·ln-1,而车道1 的最大密度达到54.37 pcu·km-1·ln-1。车道4在低密度状态下车辆行驶也会受到换道的干扰。在不利天气影响下,各车道同一状态等级的交通流特性存在明显差异。
3.4 不同交织区类型交通特征探讨
如图8所示,选择具有相类似车道设计的典型B、C型交织区探讨所提出方法的可行性。

图8 交织区类型Fig.8 Weaving segment types
应用所提出方法识别B、C型交织区状态,并与A 型交织区的结果对比,如图9 所示。各交织区的车道在受到天气的影响下,状态等级均受到影响且车道4的车道最大密度均小于其他车道,本文提出的交通状态识别方法对A、B、C型交织区均适用。

图9 不同交织区不同等级状态特征分布Fig.9 Distribution of level state characteristics in three types weaving segments
4 结论
本文得到的主要结论如下:
(1)分析了雨、雾、风速因素对高速公路交织区交通运行状态的影响。结果表明,相比正常天气,在不利天气因素影响下交织区自由流速度、通行能力、临界速度下降幅度分别为3.60%~7.82%、 11.23 %~30.00%、8.41%~26.64%。
(2)提出了考量天气因素的高速公路交织区车道级交通运行状态划分方法。利用随机森林算法筛选特征变量,通过构建结合信息熵的改进k-prototypes 算法,划分高速公路交织区各车道运行状态。应用京昆高速及二广高速的交织区运行数据验证表明,该方法能够很好地识别不利天气影响下的道路运行状态。
(3)受恶劣天气影响下的交织区服务水平下降明显且服务水平等级越低受天气影响越大,A级服务水平受不利天气影响,下降范围在C~D 级服务水平;B、C 级会下降到E 级服务水平;D、E 级会下降到F 级服务水平;在考虑天气因素下,各车道同一状态等级的交通流特性存在明显差异,分车道选取指标更能反映交织区的交通特性。
(4)研究所使用的交通数据仅为高速公路线圈检测器数据,未来可利用视频数据进一步获取交织区内车辆换道及跟驰轨迹等信息,融合多源数据对高速公路交织区进行更精细化的交通运行状态识别。
猜你喜欢
美食(2022年2期)2022-04-19
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
女报(2019年3期)2019-09-10
成都信息工程大学学报(2018年6期)2018-03-21
西南交通大学学报(2016年3期)2016-06-15
华人时刊(2016年17期)2016-04-05
中国工程咨询(2016年1期)2016-02-14
中国交通信息化(2015年10期)2015-06-06
