
基于智能刷卡数据的乘客上车站点估计研究
2023-12-28 02:54高万晨路世昌李丹
交通运输系统工程与信息 2023年6期
高万晨,路世昌,李丹
(辽宁工程技术大学,工商管理学院,辽宁葫芦岛 125000)
0 引言
科技的进步与发展使自动数据收费系统成为可能,并在城市公交系统中得到广泛运用,尤其是自动收费系统(Automatic Fare Collection,AFC)和自动车辆位置系统(Automatic Vehicle Location,AVL)。AFC 系统不仅可以实现收费的目的,还可以实时地收集到巨量的乘客刷卡交易数据。AVL系统可以实时记录公交车辆的到离站时间、经纬度坐标、瞬时速度及方向角等内容。因此,公交企业试图将收集到的海量数据应用于城市公共交通的线网规划、运营、控制与管理等方面,以使公交系统达到最优状态[1]。
但是,如何将海量数据转化成公交企业想要获得的直接可以应用的数据便成为研究者主要关注的内容。在过去的几十年内,学者基于公交企业提供的数据将OD 估计和调度优化等内容开展了一系列研究。就OD估计而言,BARRY等[2]基于纽约市的智能刷卡数据,提出两个假设算法,估计一票制公交系统的OD。马晓磊等[3]将车辆分为已安装GPS和未安装GPS设备两类,针对前者采用数据融合算法估计乘客上车站点,针对后者采用贝叶斯决策树算法估计上车站点,并利用马尔科夫链降低算法复杂度。陈君等[4]将自动收费系统数据与智能调度系统数据进行关联,估计乘客的上车站点,并进行了准确度分析和算法实现。就车辆调度优化而言,TANG 等[5]基于自动收费系统和车辆位置系统数据,获取与时间相关的变量,构建公交时刻表的多目标优化模型,优化现有公交时刻表。ZHANG等[6]基于智能刷卡数据,构建单条线路时刻表优化的非线性模型,采用无导数约束罗盘搜索算法求解模型。
但是,在上述研究中,公交OD 估计是最基础且最重要的研究内容之一,因为,公交OD 估计是后续研究的主要数据输入,所以,公交OD 估计的准确率直接关乎后续研究,因此,本文选取公交OD矩阵估计中的O估计(即上车站点估计)作为主要研究内容,D估计作为将来的研究工作。
AFC系统主要包含一票制与分段计费两类,前者,乘客在上车时需要进行刷卡付费,下车无需再次付费。后者,乘客在上车和下车均需要完成刷卡付费。针对上车站点估计,国内外学者根据公交企业提供的原始数据类型和属性字段内容的差异开展了一系列研究工作,主要分为上车时间和上车站点均已知,上车时间已知而上车位置未知及上车时间和上车位置均未知[1]。
就第一类而言,乘客的上车时间和站点均为已知,因此,不需要进行上车站点估计研究,但是,ALSGER 等[7]提出上车站点估计方法,运用真实的上车站点数据,验证了估算方法的有效性。针对第二类,由于AFC 系统缺乏上车站点属性字段的记录,仅有上车时间字段,因此,柳伍生等[8]使用时间窗方法进行上车站点估计研究,并未对估计准确性进行度量。TANG等[9]采用多阶段深度学习方法估计乘客的上车站点,确定总的上车需求,采用真实的总需求进行验证。在此类别中,由于AFC 系统中缺少个体乘客真实的上车站点数据,因此,无法采用个体真实上车站点验证不同算法估计每个乘客上车站点的准确性。最后一类也是最难估计的一类,因为,AFC 等系统既没有提供上车时间也没有提供上车站点数据,因此,CHENG等[10]根据城市公交系统的相关数据,采用概率模型估计乘客的上车站点。
针对不同算法估计乘客上车站点准确性而言,已有研究中,部分学者采用实际调查法进行验证,但是该方法由于仅调查少部分样本用于验证,当总体数量达到一定量级时,无法真实反映总体的准确性。另一部分研究仅做了上车站点估计研究,并未对估计结果进行准确性度量。已有研究中,仅有少数学者采用乘客真实的上车站点进行验证。由于大多数乘客出行具有一定的规律性,因此,可以把乘客多日出行的所有上车站点数据按照时间顺序进行排序,形成一个上车站点序列。如果能够采用合理的方法度量此上车站点序列的出行规律性,便可进一步确定某种算法估计乘客上车站点的准确性。在信息论中,熵率可以度量事件发生的平均不确定性,熵率越大,则不确定性越高。崔洪军等[11]采用熵率度量人们出行时间序列的重复性,研究表明,出行事件序列的熵率越小,出行规律性越强,反之亦然。因此,本文采用熵率方法度量不同算法确定乘客上车站点的准确性,为确定乘客上车站点和后续研究提供参考。
本文的研究工作属于第二类,即上车时间已知,而上车位置未知。已有研究中,少有学者采用多种算法进行对比分析,且少有采用熵率方法度量乘客上车站点的准确率。因此,本文首先采用两阶段算法、改进K近邻算法和改进模糊C均值聚类算法估计乘客的上车站点。其次,就乘客上车站点的匹配率而言,将3种算法与传统时间窗算法进行对比分析。最后,采用熵率方法度量3种算法估计乘客上车站点的准确率。
1 数据描述与预处理
本文所使用的公交原始数据来自于珠海市城市公交系统,数据由AFC 和AVL 两个系统收集。在系统中截取2021年9月6日~10日的数据作为研究使用,获取了公交线路、站点及车辆编号等静态数据。
1.1 AFC数据
由于珠海市所有公交线路均为一票制,乘客每完成1 次有效刷卡,AFC 系统便会记录1 条刷卡数据,如表1 所示,包括:乘客的上车刷卡时间、线路编号、车辆编号、卡号及交易类型等主要字段,但AFC 系统并未记录乘客具体的上车站点信息。

表1 AFC数据示例Table 1 Example of AFC data
1.2 AVL数据
AVL系统通过将GPS设备装于公交车上,用于公交车实时监控,便于调度人员了解公交车的实际运行状况。目前,珠海市所有运营公交车均已安装车载GPS设备,该系统可以实时地收集公交车运行数据,并按照固定的时间间隔将数据上传至服务器,包括:公交车到站时间、公交车离站时间、经纬度坐标、速度及方向角等字段数据,如表2所示。
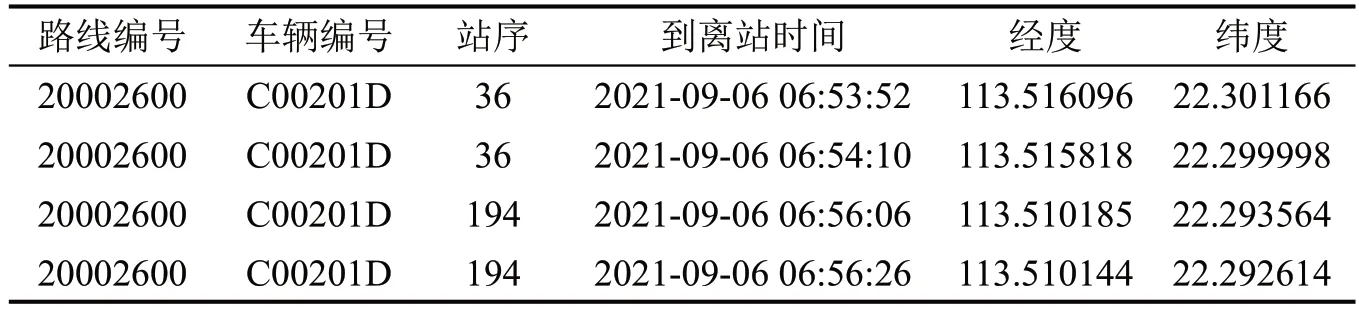
表2 AVL数据样例Table 2 Example of AVL data
1.3 数据预处理
设备失效和人为错误是导致部分数据异常的主要原因,在数据产生、上传及存储等过程中均可能发生。设备失效包括:刷卡设备、GPS 设备及系统设备等问题。人为错误包括:乘客上车忘记刷卡和多次刷卡等。由于上述错误,可能会导致数据缺失、数据重复、数据错误及相同字段在不同系统之间的数据不一致等错误形式。如果对其不进行科学的数据清洗操作,将会影响最终的研究结果。因此,需要对AVL 和AFC 系统中获取的原始数据进行预处理,具体如下。
(1)针对数据缺失情况,需要判断缺失数据能否通过其他已有数据代替,如果不能,则需要进一步判断能否运用插值、均值及经验判断等补全。如果上述方法均无法补全缺失数据,则需要删除缺失数据。
(2)针对数据重复情况,根据实际情况进行删除,数据重复常见于起始站或终点站。
(3)针对数据错误情况,常见的错误主要有公交到站时间大于离站时间、站点不属于此线路、时间错误、仅有部分GPS 数据及仅有GPS 数据无IC卡数据,或仅有IC 卡数据无GPS 数据等。如果是静态数据发生错误,则需要通过历史数据进行更改;如果是动态数据发生错误,可以酌情进行删除。
(4)针对相同字段在不同系统之间的数据不一致情况,首先,利用两个系统中字段相同且数据格式一致的数据将两个系统的数据进行关联操作;然后,对相同字段存在差异的数据进行标准化处理,或者选取其中一列数据作为基准。
经过数据清洗后,可以采用合理的算法对AFC和AVL数据进行匹配操作,以科学合理地估计每天每条线路每辆车在运营时间内的乘客上车站点。
2 方法
传统的时间窗算法作为识别乘客上车站点的一种基本方法,具有简单明了和易于理解的特点。正常情况下,乘客上车后,需要进行刷卡操作,第j名乘客的刷卡时间为Tj(j=1,…,μ),公交车到达第i站时间为Ti,A(i=1,…,m),离站时间为Ti,L(i=1,…,m),显然,乘客的刷卡时间应该介于区间[Ti,A,Ti,L] 内。但是,在公交车的实际运营过程中,往往会出现因设备误差或故障,高峰期间拥堵产生的车辆提前开门或乘客因车内拥挤产生的滞后刷卡,相邻两个公交站之间距离较近等问题,进一步导致了部分乘客的刷卡时间在公交车到站和离站时间窗之外,如图1所示。

图1 公交站点和乘客刷卡数据时空分布Fig.1 Spatial and temporal distribution of bus stops and passengers'swiping card time
由于部分乘客的刷卡时间置于车辆到站和离站时间窗之外,因此,部分学者引入了阈值[12],改进公交车的到站和离站时间窗,以提高时间窗外刷卡数据的匹配率,但是该方法在高峰期间可能会遇到某一站点上车人数过多或某一站点上车人数过少的情况,进而可能因阈值过大导致调整后的时间窗与后续时间窗存在交集或因阈值较小导致调整后的时间窗与调整前的时间窗相差不大,因此,可能会影响匹配准确率。
改进的公交车到站和离站时间窗为
式中:θ为时间窗阈值。
综上,无论时间窗算法是否有阈值,都会有一定比例的刷卡数据无法匹配,需要人工匹配。当样本数据达到一定数量时,该方法的效率会降低。因此,本文设计两阶段算法、改进K 近邻算法和改进模糊C均值聚类算法对城市公交1条线路上所有车辆的刷卡数据进行上车站点估计。由于熵率可以度量乘客出行的规律性,因此,为验证3 种算法的准确率,采用了熵率方法。
2.1 两阶段算法
第1阶段,算法采用可变阈值的时间窗方法初次匹配乘客刷卡数据和车辆到站离站时间;第2阶段,算法对第1阶段未匹配成功的乘客刷卡数据进行二次匹配,确定所有刷卡数据的上车站点。
2.1.1 第1阶段算法
基于式(2)和式(3),继续进行优化研究。基于第i站的离站时间Ti,L(i=1,…,m)与第(i+1) 站的到站时间T(i+1),A(i=1,…,m),提出带有可变阈值的时间窗方法,进一步提高乘客上车站点的匹配精度,具体算法如下。
Step 1 获取所有公交运营线路集合L={L0,…,Ly,…,Lk},k为线路总数,y为线路编号。
Step 2 选取某线路Ly,获取线路Ly在运营时间内的车辆集合B={By0,…,Byz,…,Bys},s为车辆总数,z为车辆编号。刷卡数据匹配上车站点集合P={P0,…,Px',…,Pt},t为匹配上车站点总数,x'为匹配上车站点编号。
Step3 选取某车辆Byz,获取车辆Byz的刷卡时间集合I={Iyz0,…,Iyzx',…,Iyzt},车辆到站和离站时间集合T={Tyz0c,…,Tyzic,…,Tyzmc},c={A,L},L 为车辆离站,A 为车辆到站,站点集合S={Syz0,…,Syzi,…,Syzm} 。
Step 4 确定可变阈值ψ。
(1)根据式(1),对某条线路全天的乘客刷卡数据进行第一次匹配,存在一定比例的刷卡数据匹配失败。
(3)由于刷卡数据介于两站之间,要么属于前者,要么属于后者。因此,选择集合tB中小于30 s的数据组成新集合tB_new,tB_new的平均值为σB。它将用于确定车辆B在线路Ly全天的可变阈值ψB=
(4)重复Step 2和Step 3,直到确定线路Ly所有车辆的可变阈值ψ。
Step 5 对车辆Byz在运营时间内的所有刷卡时间数据I和车辆到站离站时间数据T进行匹配运算。
(1)当i=1时(始发站)
如果Iyzx'≤(Tyz,1L+Ψ0),Ψ0为始发站的可变阈值,Ψ0=ψ(Tyz,2A-Tyz,1L),则乘客Px'在第1 站(始发站)上车,即Px'=1。
否则,i=i+2,继续进行匹配操作。
(2)当i >1时
Ψw和Ψq分别为中间站车辆到达和离开的可变阈值,Ψw=ψ(Tyzi,A-Tyz(i-1),L),Ψq=ψ(Tyz(i+1),A-Tyzi,L)。
如果Syzi=Syz(i+1),则需要做出如下判断:
① 如果Iyzx'≤(Tyzi,L+Ψq)且Iyzx'≥(Tyzi,A-Ψw),则乘客Px'在i站上车,即Px'=i。
②如果Iyzx'≥(Tyzi,A-Ψw)且Iyzx'<(Tyzi,A-Ψw),则乘客Px'上车站点匹配失败,即Px'=Null。
③如果Iyzx'>(Tyz(i+1),L+Ψq),则i=i+2,继续匹配。
④除上述3种情况外,i=i+1,继续匹配。
否则:
①如果Iyzx'≤Tyzi,A,则Px'=i-1。
②否则,如果Iyzx'≤Tyz(i+1),A,则Px'=i+1;反之,i=i+1,继续匹配。
(3)当i=m(终点站)时
如果Iyzx'≤Tyzm,A时,乘客Px'在第(m-1) 站上车,即Px'=m-1。
Step 6 如果集合B中仍有未匹配成功的刷卡数据,转至Step 3;否则,执行Step 2,直到所有线路的刷卡数据全部完成上车站点匹配。
2.1.2 第2阶段算法
经过第1阶段算法后,由于存在部分刷卡时间Iyzx'无法准确匹配公交车到离站时间Tyzic,因此,需要进一步设计一种算法,处理匹配失败的刷卡数据,实现每天所有运营公交线路的所有车辆的全部乘客的刷卡数据的完全匹配,具体如下。
Step 1 获取所有公交运营线路集合L={L0,…,Ly,…,Lk} 。
Step 2 选取某一线路Ly,获取线路Ly在运营时间内的所有刷卡数据I={Iyz0,…,Iyzx',…,Iyzt} 匹配上车站点的集合P={P0,…,Px',…,Pt},并对其进行完全匹配运算,将完全匹配后的上车站点集合定义为Pb={Pb0,…,Pbx',…,Pbt} 。
Step 3 进行数据完全匹配运算。
(1) 如果Px'=Null,在集合P'={Px'-1,…,0} 中寻找第1个不为Null 的元素,并记录此元素的位置d。同时,在集合P″={Px'+1,…,Pt} 中寻找第1个不为Null 的元素,并记录此元素的位置e。如果(Iyzx'-Iyzd)<(Iyze-Iyzx'),则Pbx'=Pd;否则,Pbx'=Pe。
(2)如果Px'!=Null,则无需再次进行完全匹配运算,即Pbx'=Px'。
Step 4 如果集合L中仍有未完成匹配运算的线路,转至Step 2;否则,算法终止。
2.2 改进K近邻算法
AFC系统中实时记录乘客的刷卡数据,包括刷卡时间和IC卡号等主要字段。由于不同乘客在同一站点上车的刷卡时间具有一定的连续性,因此,可以采用最近邻聚类算法识别乘客的上车站点。其中,数据集样本为某条公交线路全天的刷卡数据,选择曼哈顿距离作为距离计算的依据,聚类中心个数(K值)不超过公交站点总数S,因为,可能存在某站点无人刷卡的现象,且终点站乘客只下不上,具体运算步骤如下。
Step 1 算法初始化
刷卡数据I为线路Ly车辆Bz的上行或下行方向运行一次所产生的t条刷卡记录,上车刷卡时间I={Iyz0,…,Iyzx',…,Iyzt} 。选取Iyz0为聚类中心K0的初始值,即Iyz0∈K0。
Step 2 计算分类阈值ψ
以相邻公交站点之间的最小行驶时间为分类阈值,ψ=min{Tyzi,A-Tyz(i-1),L},i=2,…,S。
Step 3 计算距离
采用曼哈顿距离计算相邻两次刷卡数据之间的距离。假设Iyz(i-1)∈Ki,如果Di(i-1)=|Iyzi-Iyz(i-1)|>ψ,则Iyzi∈K(i+1);反之,Iyzi∈Ki。
Step 4 迭代操作
执行Step 1,Step 2 和Step 3,直至所有线路所有车辆的所有刷卡数据全部完成归类。
Step 5 站点匹配
首先,将第1 个刷卡数据Iyzx'与公交车到站离站时间数据T={Tyz0c,…,Tyzic,…,Tyzrc} 进行匹配操作。其次,如果Iyzx'与Iyz(x'+1)均属于Ki类,则Iyz(x'+1)的匹配结果与Iyzx'相同;反之,Iyz(x'+1)与公交车到站离站时间数据进行匹配。直至所有线路所有车辆的所有刷卡数据全部完成站点匹配。
2.3 改进模糊C均值聚类算法
模糊C 均值聚类算法是应用比较广泛且较成功的无监督机器学习的算法,通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属,达到自动对样本数据进行分类的目的。已有研究中,鲜有学者采用模糊C均值聚类算法估计研究乘客上车站点。因此,本文采用该方法进行上车站点估计,并将计算结果与其他算法进行对比。由于乘客上车刷卡数据是一系列的时间点,因此,对传统的模糊C均值聚类算法进行改变,针对两点距离的计算,采用曼哈顿距离替代欧式距离。
模糊C均值聚类算法通过引入隶属度矩阵,用于衡量当前样本属于某一类别的可能性大小,并不是完全绝对属于哪一类。当前样本可能属于第1类,也可能属于第2 类。假如样本数据F=(f1,f2,…,fg,…,fG)被划分为C=(c1,c2,cε,…,cρ)个类别,那么每个类别会有1 个类中心,即共C 个类中心,uεg为样本fg属于某一类别cε的隶属度,U=(u1g,u2g,uεg,…,uρg),数学模型为
利用拉格朗日乘数法对uεg和cε分别求偏导,即
具体运算步骤如下。
Step 1 算法初始化。根据式(6)初始化一个隶属度矩阵U(a),根据U(a)计算初始聚类中心C(a),确定模糊因子ξ,最大迭代次数和迭代停止阈值τ。
Step 2 根据U(a)和C(a)计算并更新隶属度矩阵U(a+1),然后,根据U(a+1)计算并更新聚类中心C(a+1)。
Step 4 站点匹配。首先,将第1个刷卡数据fg与公交 车到站 离站时 间数据T={Tyz0c,…,Tyzic,…,Tyzmc} 进行匹配操作。其次,如果fg与f(g+1)均属于cε类,则f(g+1)的匹配结果与fg相同;反之,f(g+1)与公交车到站离站时间数据进行匹配。直至所有线路所有车辆的所有刷卡数据全部完成站点匹配。
2.4 熵率法
上述3 种算法均可以估计乘客上车站点,但是,不同的算法表现出不同的准确性。因此,本文采用前文叙述的熵率方法进一步确定不同算法估计乘客上车站点的准确性。将每个乘客多天的所有出行的上车站点按照时间进行排序,形成一个上车站点序列X={X1,X2,X3,…,Xn-2,Xn-1,Xn},称之为上车链,因此,仅需要计算上车链的熵率。通过比较熵率大小,便可以确定不同算法估计乘客上车站点准确率关系。熵率方法的具体描述如下。
随机向量或随机变量X需要在有限集合E中取值,集合E是乘客可以选择的上车站点,概率分布为P(x)=Pr{X=x},x∈E,X的熵[13]为
X={… ,X-1,X0,X1,X2,…} 是一个随机过程,{Xn}是随机变量的序列,对于一个连续的部分过程(可能是无限的)(Xρ,Xρ+1,…,Xη), -∞≤ρ≤η≤+∞,H=H(X)为X的熵率,即的熵随n变化的渐近率,即
H(X1,X2,…,Xn)为随机变量(X1,X2,…,Xn)的熵。对于平稳的随机过程,熵率存在,为式(9)条件熵,即
本文假设乘客长期的公交出行是一个平稳的随机过程X。随机变量X表示乘客在某站点上车,用离散概率p(x) 表示。在实际中,上述公式中的联合概率分布和往往难以计算,通常采用估算方法进行熵率计算,常用的熵率估算方法有Plug-in Estimator、Lempel-Ziv Estimators、Context-Tree Weighting 及Burrows-Wheeler Transform(BWT)等。
由于BWT 是目前最好的无损压缩方法之一,且BWT能够把有限的记忆序列转化成分段平稳的无记忆序列,以此过程为基础估算原始序列的熵率。因此,本文选用Burrows-Wheeler Transform方法估算熵率[14],具体计算步骤如下。
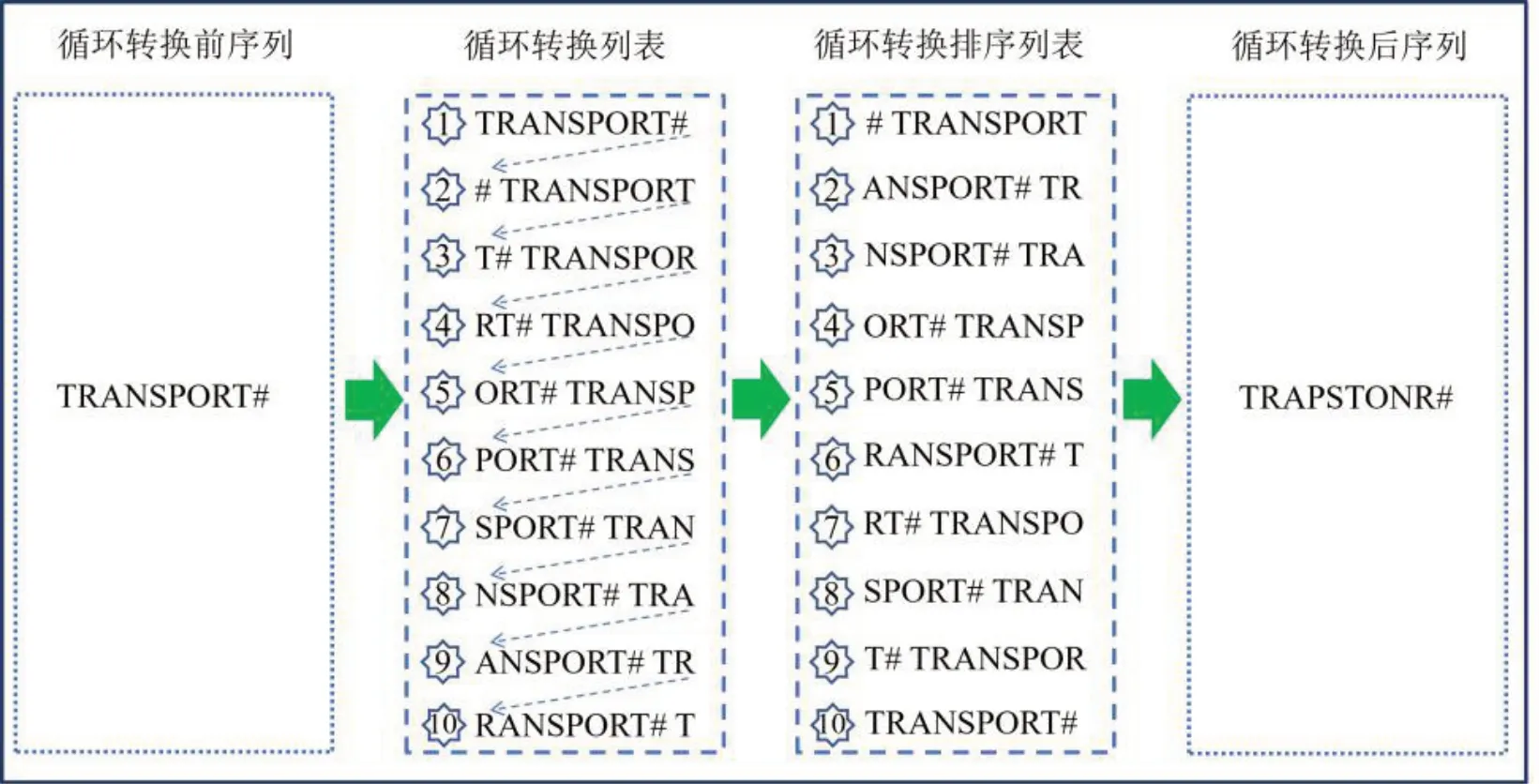
图2 BWT例子Fig.2 Example of BWT
Step 2 将新的序列分为r段,每段长度不必相同,但是分段长度相同是非常有效的。
Step 3 估计每段内的一阶分布。本文用Nr(x)表示符号x在第r段中出现的次数,用表示符号x在第r段中的概率估计,用表示第r段的熵估计,即
Step 4 通过各段熵的均值求出随机过程X,即乘客上车站点出行序列的熵率为
乘客N在3 d内乘坐线路A的出行序列如图3所示。图3(a)为上车链,可以看出该序列有2 个未知参数X1和X2。假设以下4 种情况,X1=2,X2=3;X1=2,X2=6;X1=5,X2=3 和X1=5,X2=6。通过计算4 条上车链的熵率,结果如图3(b)~(e)所示。可以发现,乘客上车链1 比上车链2、上车链3和上车链4具有更低的熵率,因此,上车链1表现出更强的出行规律性。上述案例可以进一步说明,熵率可以测度人们出行的规律性,熵率越小,出行规律性越强,能够反映不同算法估计乘客上车站点的准确率。
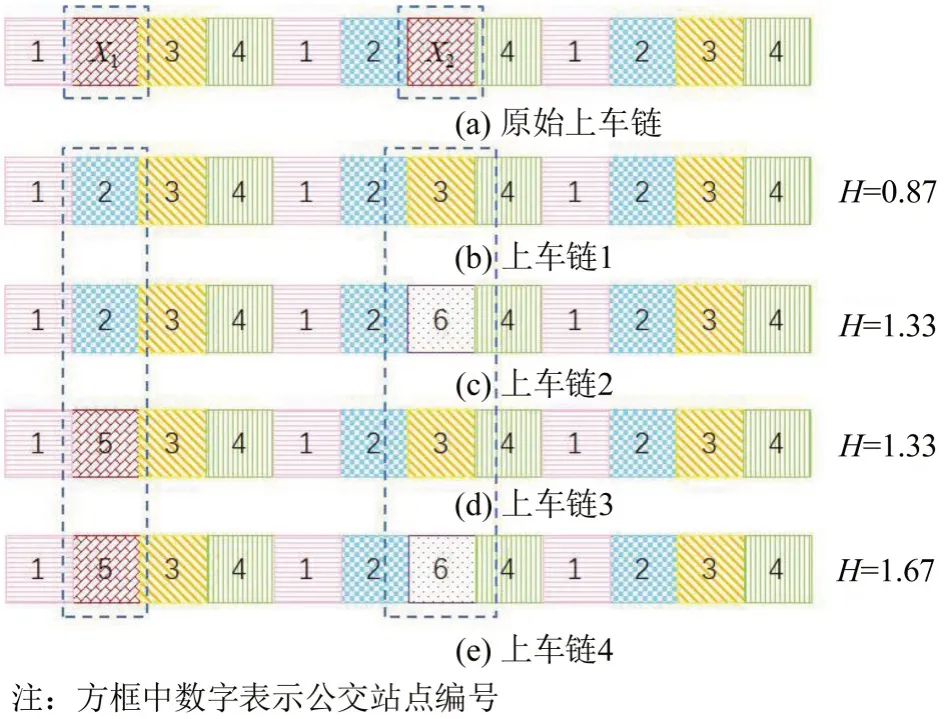
图3 不同序列的熵率对比Fig.3 Comparison of entropy rates of different sequences
3 案例与结果分析
选取珠海市2021年9月6日~10日AFC和AVL系统中18 路公交车(6:30-21:15)的运营数据,统计该线路运营时间内所有乘客的上车站点,线路布局如图4 所示。经过数据清洗后,刷卡数据共27028条。刷卡数据包括:普通卡、老人卡、学生卡、二维码、残疾人卡、员工卡及其他卡7 种类型。不同类型IC卡占比如图5(a)所示,18路公交运营期间刷卡数据具有早晚高峰特征,每天客流变化不明显,具有一定的规律性,如图5(b)所示。
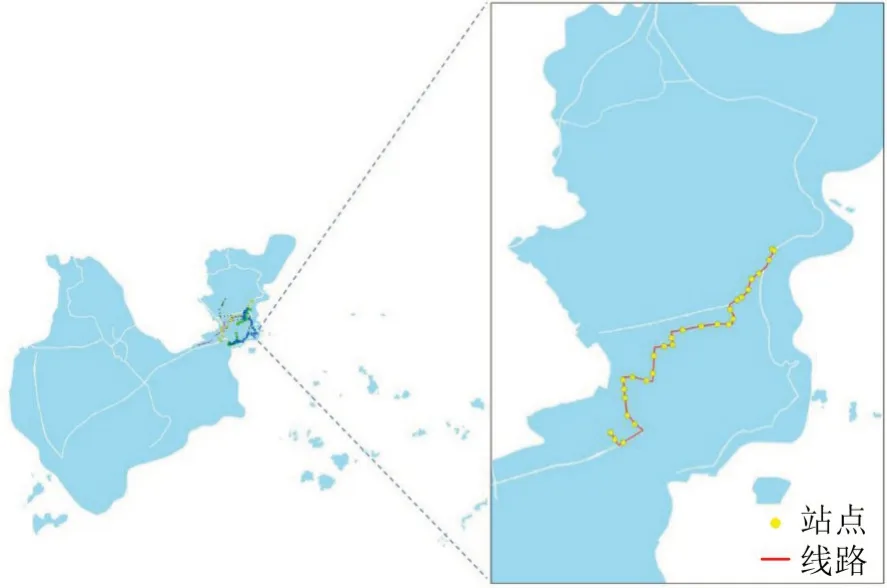
图4 珠海市18路Fig.4 Line 18 in Zhuhai
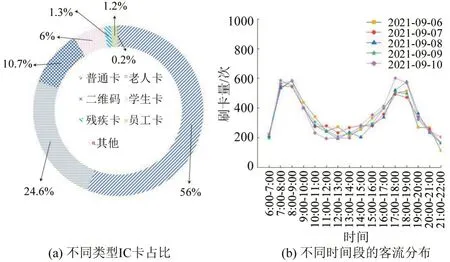
图5 18路公交不同类型IC卡占比及不同时间段的客流分布Fig.5 Proportion of different types of IC cards and passenger flow distribution in different time periods of No.18 bus
3.1 不同算法的匹配结果
采用传统时间窗算法、两阶段算法、改进K近邻算法及改进模糊C均值聚类算法对18路5 d的刷卡数据进行匹配计算,匹配结果如图6所示,图中,P0为传统的时间窗算法,P1为第1阶段算法,P1+2为两阶段算法,P3为改进K近邻算法,P4为改进模糊C均值聚类算法;虚线为5 d内P0与P1的平均匹配率。
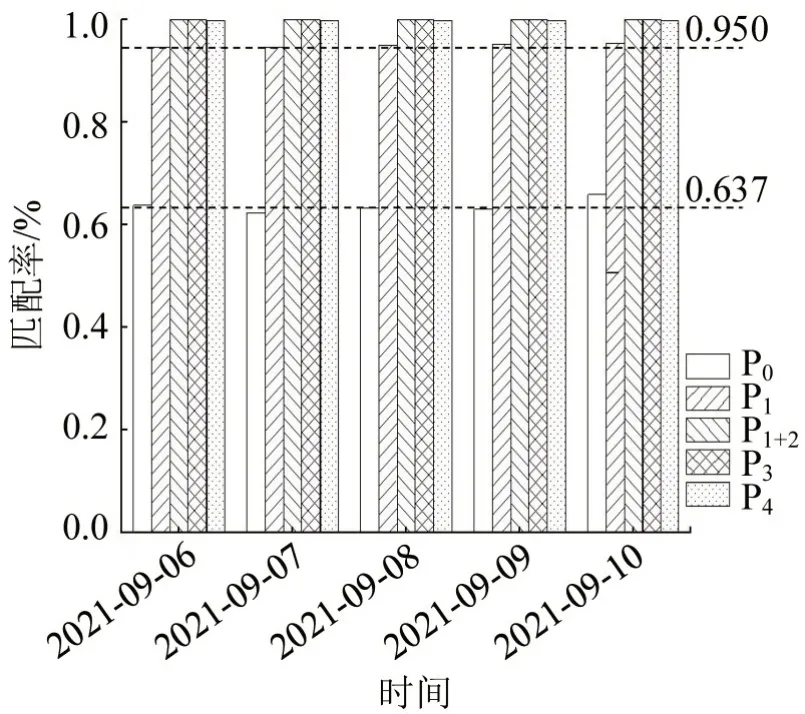
图6 乘客上车站点的匹配率Fig.6 Matching rate of passengers'boarding stops
由图6 可知,各种算法的匹配结果为P0<P1<P1+2=P3=P4。18 路刷卡数据匹配平均增长率为P1,比P0增长31.3%,P1+2、P3、P4较P0高36.3%,P1+2、P3、P4较P1增加了5.0%。发现P1+2、P3、P4这3种算法均可以实现所有刷卡数据的完全匹配。
3.2 熵率计算结果
虽然3 种算法均可以实现上车站点的完全匹配,但无法判断各种算法的匹配准确率。因此,可以通过熵率进行判断。本文采用熵率方法,结合3个维度的样本数据,深入探讨各种算法估计乘客上车站点的准确率。
(1)维度I
首先,根据IC 卡号,统计5 d 内的所有刷卡数据;其次,将统计后的刷卡总数按降序排序;然后,选择累计刷卡次数大于5次的前10%的IC卡号;最后,基于筛选后的IC卡号,采用3种算法分别计算,获取每个IC 卡号的上车链,并以此为基础计算各上车链的熵率。3种算法对维度I数据的熵率计算结果分布如图7所示,图中,虚线表示平均熵率。
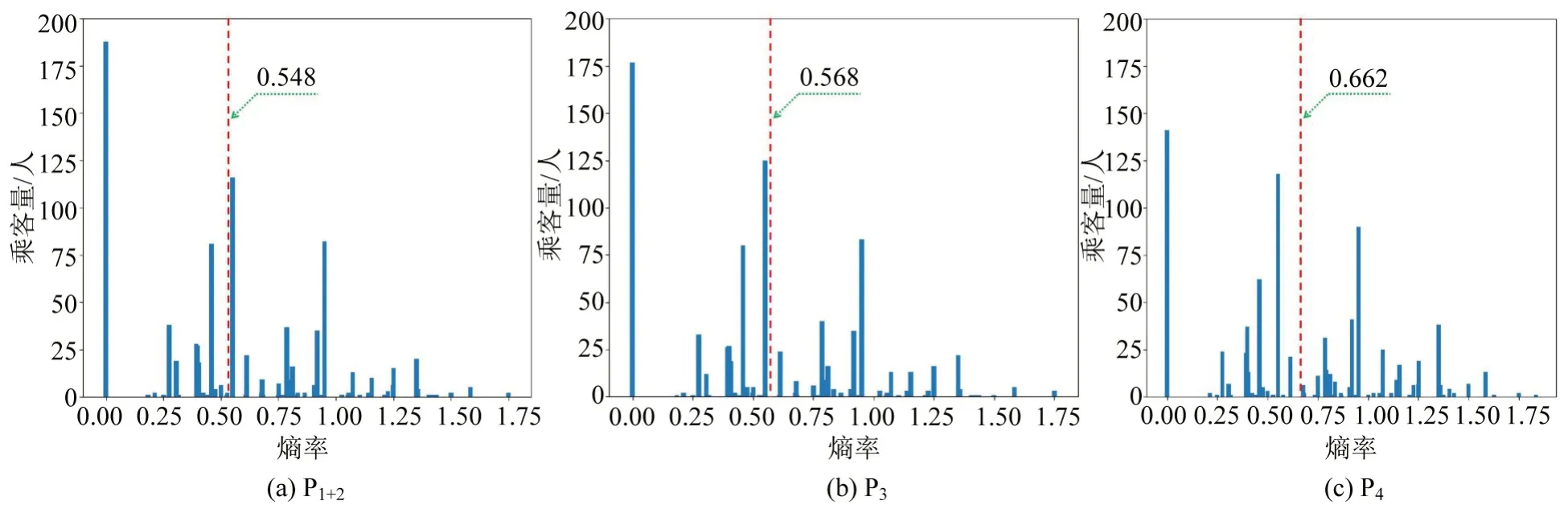
图7 3种算法在维度I的熵率分布Fig.7 Entropy rate distribution of three algorithms in dimension I
由图7 可知,3 种算法的平均熵率分别为H(1+2)<H3<H4。如前文所述,熵率越小,乘客出行的规律性越强。因此,从平均熵率来看,3种算法匹配乘客上车站点的准确率关系为P1+2>P3>P4。而P1+2和P3的平均熵率差异不大,匹配精度比较接近。
(2)维度II
首先,经过传统算法P0计算后,在所有匹配失败的刷卡数据中,选择累计刷卡次数大于5次的IC卡号;然后,根据筛选后的IC卡号,采用3种算法获取每个IC 卡号的上车链用于熵率计算。在维度II的数据中,3 种算法的熵率计算结果分布如图8 所示,图中,虚线表示平均熵率。

图8 3种算法在维度II的熵率分布Fig.8 Entropy rate distribution of three algorithms in dimension II
由图8 可知,维度II 的平均熵率结果与维度I相似,即H(1+2)<H3<H4,P1+2>P3>P4。
(3)维度III
首先,根据IC卡类型,对所有刷卡数据按照IC卡类型进行分类,选择每种类型中5 d 内累计刷卡次数大于5次的IC卡号;然后,根据筛选后的IC卡号,采用3种算法获取每种类型中每个IC卡号的上车链用于计算熵率。在维度III数据中,3种算法的熵率计算结果分布如图9 所示,图中,虚线表示平均熵率。
由图9 可知,除员工卡外,其他类型IC 卡的平均熵率分布结果与维度I和维度II相同。对于员工卡而言,熵率结果为H(1+2)=H3<H4。因此,从熵率的平均值来看,3 种算法匹配乘客上车站点的准确率关系为P1+2=P3>P4。由于P1+2和P3的平均熵率相等,因此,匹配精度相同。
为进一步验证上述某种算法更加适合于公交企业的实际应用,进行如下操作。首先,在数据库中,选择3个IC卡卡号,对应3名乘客;其次,采用3种算法统计3名乘客5 d的上车站点,形成9条上车链;最后,分别计算所有上车链的熵率,如图10所示。
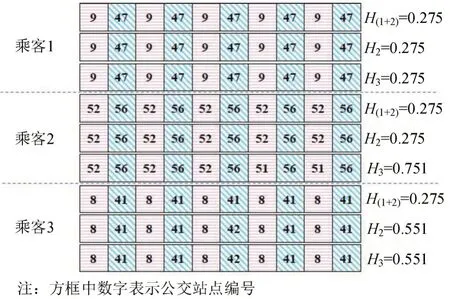
图10 3名乘客上车链的熵率Fig.10 Entropy rate of three passengers'boarding chain
由图10可知,就乘客1而言,3种算法对乘客1形成了相同的上车链,且熵率相同,因此,选取其中一种算法产生的上车链作为乘客1 的最终上车站点估计结果。就乘客2而言,P1+2和P3形成的上车链相同,与 P4不同,熵率计算结果为H(1+2)=H3<H4,因此,选择P1+2或P3产生的上车链作为乘客2的最终上车站点估计结果。就乘客3而言,P1+2形成的上车链与P3、P4不同,熵率计算结果为H(1+2)<H3=H4,因此,选择P1+2产生的上车链作为乘客3的最终上车站点估计结果。综上,并非某种算法完全优于或劣于其他算法,前文叙述的结果是基于3 个维度样本数据的平均熵率而言。因此,公交企业在实际应用的过程中,应该选择3 种算法中的最小熵率作为乘客上车站点估计的最终结果。
4 结论
(1) 熵率方法不仅可以反映乘客出行的规律性,还可以确定不同算法估计乘客上车站点的准确率。是一种估计乘客上车站点准确率的新方法。熵率越小,乘客上车站点估计的准确率越高。
(2)通过对比不同算法获取上车链的平均熵率发现,两阶段算法的准确率高于改进K 近邻算法,改进K 近邻算法的准确率高于改进模糊C 均值聚类算法。两阶段算法与改进K 近邻算法的准确率差异不大。
(3)公交企业在没有更好的方法可供选择时,可以采用熵率方法确定乘客上车站点估计的准确率,在具体应用时,应选择熵率最小的估计算法确定乘客的上车站点。
(4)在两阶段算法中,基于可变阈值设计了时间窗算法,克服了传统时间窗算法的不足。同时,两阶段、改进K近邻算法和改进模糊C 均值聚类这3种算法均可估计所有乘客的上车站点,与传统时间窗算法相比,进一步提升了乘客上车站点估计的匹配率。
猜你喜欢
房地产导刊(2020年7期)2020-08-24
校园英语·中旬(2019年4期)2019-05-13
小学生必读(低年级版)(2017年9期)2018-01-31
领导决策信息(2017年17期)2017-06-21
小学生·新读写(2016年5期)2016-05-14
幼儿画刊(2016年9期)2016-02-28
启蒙(3-7岁)(2016年10期)2016-02-28
妇女生活(2016年1期)2016-01-14
小学生时代·大嘴英语(2015年9期)2015-10-10
作文大王·笑话大王(2015年7期)2015-05-30
