
基于改进的DeepLabV3+网络模型的杂交水稻育种父母本语义分割研究
2023-12-29 08:43温佳梁喜凤王永维
浙江大学学报(农业与生命科学版) 2023年6期
温佳,梁喜凤*,王永维
(1.中国计量大学机电工程学院,浙江 杭州 310018;2.浙江大学生物系统工程与食品科学学院,浙江 杭州 310058)
在杂交水稻种子的生产环节中,杂交水稻制种时的高效授粉不可或缺,而杂交水稻授粉花期短,种植规模大,要在短时间内完成大面积授粉,对于劳动力的要求较高。杂交水稻制种授粉机器人能有效解决劳动力短缺和杂交水稻种植规模大的问题,提高授粉效率,其作用方式为在水稻父本上方驶过,将父本花粉吹向两侧水稻母本,因此,在杂交水稻制种阶段,精确识别和区分水稻父母本尤为重要。由于杂交水稻制种中水稻父本与母本的颜色和纹理较为相近,给传统的图像处理方法带来一定困难,使得传统方法不适于对此类颜色、纹理差别较小的作物进行区分。因此,研究使用深度学习方法对杂交水稻制种授粉阶段的父本与母本进行区分十分重要。
目前,国内外学者针对水果及其他农作物特征的识别和提取方法主要有传统图像处理、深度学习方法等。传统的水果及其他农作物的分割方法实现过程需要极为复杂的图像预处理[1-2]或交互[3],通常采用阈值分割算法[4]和边缘检测算法[5]对图像进行区分和提取,但是这些算法仅适合用于特征明显、背景较为简单的情况。在杂交水稻制种授粉阶段,水稻父母本颜色、纹理区别不大,传统的检测算法难以进行特征提取,而基于深度学习的算法能对这种颜色、纹理差别较小的农作物实现自动化分割[6],提高图像分割的精确性。陈进等[7]使用层数更深的U-Net 模型进行水稻籽粒图像分割,加快了网络的收敛速度,提高了网络的泛化能力。胡春华等[8]基于SegNet 与三维点云聚类方法对大田杨树苗叶片进行分割,提高了分割精度。王俊强等[9]将DeepLabV3+与条件随机场(conditional random field, CRF)结合使遥感影像边界更加清晰。慕涛阳等[10]将卷积注意力机制嵌入DeepLabV3+网络结构,减少了无关特征对识别精度的影响。LI 等[11]使用OCRNet联合融合技术对跨域建筑屋顶进行分割,提高了分割效果。除此之外,基于深度学习的语义分割还广泛应用于医学[12-13]、桥梁[14]、交通[15]、遥感数据[16]等各方面,但是在农田杂交水稻父母本的分割上应用较少。部分网络针对高分辨率的图片特征丢失较多,细节恢复方面还存在较多问题,针对数据集较小的样本无法满足精确性和预测速度的要求。
本研究提出了一种改进的DeepLabV3+语义分割模型,为实现精度高、模型训练快的杂交水稻父母本分割,将较低层次信息和较高层次信息初步融合作为原低层次信息的输入,使得网络获得更加密集的信息,增强网络对于细节的提取能力,从而达到预期目的并取得分割结果提供模型支撑,也为早期杂交水稻制种授粉机器人对水稻父本中心线的路径提取提供依据。
1 数据采集及预处理
1.1 图像数据采集
实验数据采集日期为2021 年9 月13 日(晴天)和2021年9月15日(阴天),图像采集地点为浙江省嘉兴市海宁市杂交水稻育种试验田基地和当地农民种植田地,采样实验数据有一定差异,有利于增强训练网络的鲁棒性和测试难度。图像采集设备为华为Mate 20 Pro 手机,采集3 648 像素×2 736 像素的图像,共730张。
1.2 图像数据增强
为获得杂交水稻制种授粉阶段大量父母本的训练数据样本,可通过图像数据增强预处理的方法,对图像进行水平翻转、垂直翻转、缩放等一系列处理,获得原始数据量数倍的数据量。本实验对图像进行垂直翻转和水平翻转处理,图像数据增强后结果如图1所示,共获得原始数据量3倍的数据量,即2 190张水稻图像。

图1 晴天和阴天的水稻样本处理图像Fig.1 Images of rice sample treatments on sunny and cloudy days
1.3 图像标注
为训练网络对水稻制种授粉阶段的父本与母本进行区分,需要对数据增强后图像进行图像标注,图像标注也是极为重要的一步,标注的精确程度影响后续的图片预测。本实验使用开源工具Labelme软件对图像进行标注,结果如图2所示。对图像标注后的文件格式为JSON 格式,将其转化为PASCAL VOC格式后进行后续训练操作。

图2 使用Labelme软件进行图像标注Fig.2 Image labeling via Labelme software
2 网络结构模型
DeepLabV3+语义分割网络模型[17]是由原DeepLabV3 网络模型[18]改进而来的,将整体网络分为编码结构和解码结构2 大模块,即采用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)模块和解码模块二合一的方式实现语义分割,添加一个解码模块能细化分割结果,尤其是沿着目标对象边界的分割结果,其主干网络为Xception网络模块。
考虑到网络结构的实时性和易部署性,将原模型DeepLabV3+_Xception 主干网络的Xception网络模块替换为MobileNetV2,但DeepLabV3+_MobileNetV2 模型中MobileNetV2网络模块的低层特征提取结构过于简单,对于轻量化的MobileNetV2网络结构特征提取效果甚微。为提高网络特征提取效果,本研究又提出一种联系较为紧密的低层特征分级提取方法,如图3所示,将MobileNetV2网络结构中较低层次和较高层次的分级特征先提取出来,针对特征图像不同的高、宽、通道数进行不同的卷积和上采样处理,然后将不同层次的信息进行第1 次融合,以提升MobileNetV2 网络结构的特征提取能力,为第2次与ASPP模块处理后的特征信息融合做准备。
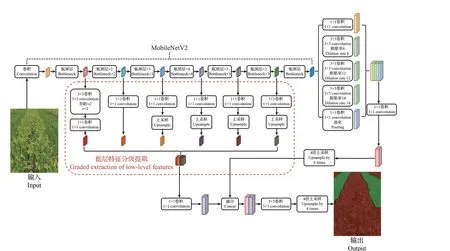
图3 改进的DeepLabV3+网络模型结构图Fig.3 Structure chart of improved DeepLabV3+ network model
由图3可知,改进的DeepLabV3+网络模型编码结构主要是由主干网络和ASPP 模块组成,主干网络选用轻量化网络结构MobileNetV2,ASPP模块包含1 个1×1 卷积分支、3 个3×3 空洞卷积分支和1 个全局池化层的分支,其中,3个3×3空洞卷积分支通过使用不同的膨胀率(分别为6、12、18)构建不同感受野的卷积核,在分辨率损失较小的情况下,获得多尺度的物体信息,使得图像中不同尺寸的物体都能得到较好的信息提取效果。首先将各个分支的特征信息用1×1 卷积层进行融合,得到新的高层次的特征信息,然后在解码结构部分上采样,还原至与低层次分级特征信息有着相同高和宽的特征尺度,与从主干网络所引出的低层次分级特征信息进行融合,再使用3×3 卷积细化特征层,最后使用双线性插值法4 倍上采样使图像大小恢复至输入图像的原始尺寸。其中MobileNetV2 网络模块采用倒残差结构(inverted residual structure),即先使用1×1 卷积升维,然后使用3×3 深度卷积(depthwise convolution)提取特征信息,最后使用1×1 卷积降维,这样的处理能使高维信息通过ReLU 激活函数后丢失的信息更少,倒残差结构有步距(stride,s)为1和2的2种结构,如图4所示。

图4 MobileNetV2网络模块的倒残差结构Fig.4 Inverted residual structure of MobileNetV2 network module
MobileNetV2 网络模块操作步骤如表1 所示,c为输出特征矩阵的通道数(channel),n为瓶颈层(bottleneck)的重复次数,即倒残差结构的重复次数。操作流程分为8 步,第1 步将原图进行卷积操作,步距为2;第2—8 步进行瓶颈层操作,重复次数分别为1、2、3、4、3、3、1,在重复次数大于1的瓶颈层操作中,步距只针对瓶颈层的第1层,后续重复瓶颈层的步距均为1。
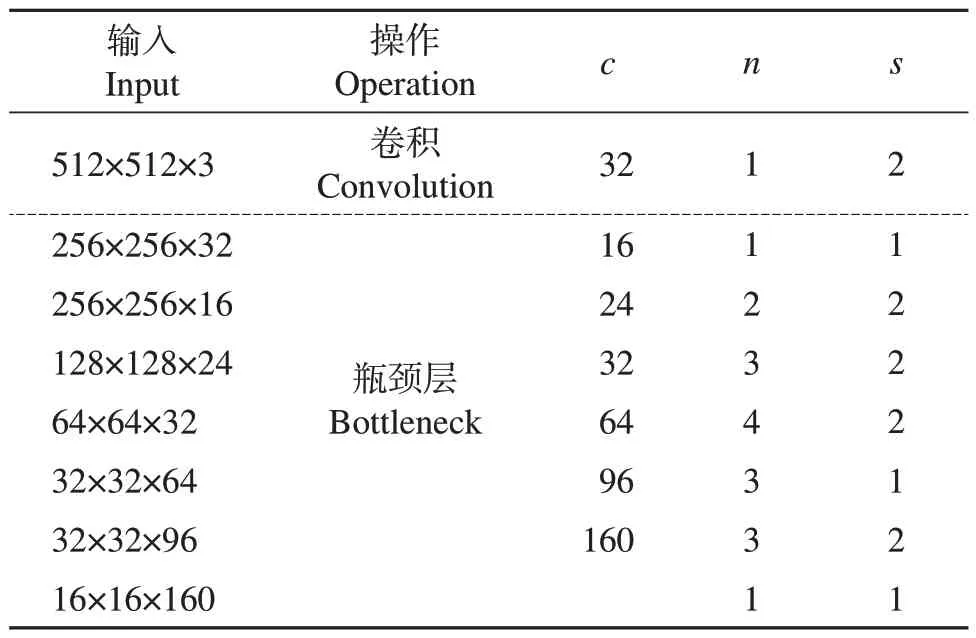
表1 MobileNetV2网络模块整体操作步骤Table 1 Overall operation steps of MobileNetV2 network module
3 评估指标
评估指标用于评价语义分割模型的检测精度,是衡量语义分割模型是否适用的重要指标,常见的评估指标有平均像素准确率(mean pixel accuracy, mPA)、精确率(precision)、平均交并比(mean intersection over union, mIoU)和召回率(recall),上述指标都是建立在混淆矩阵(confusion matrix)[19]的基础之上的。
混淆矩阵就是统计分类模型的分类结果。真正例(true positive, TP),样本的真实类别是正样本,并且模型识别的结果也是正样本;假负例(false negative, FN),样本的真实类别是正样本,但是模型将其识别为负样本;假正例(false positive, FP),样本的真实类别是负样本,但是模型将其识别为正样本;真负例(true negative, TN),样本的真实类别是负样本,并且模型将其识别为负样本[20-21]。
精确率又称查准率,表示在模型识别为正样本的所有样本中真实类别为正样本的占比。精确率计算公式如下:
召回率又称查全率,表示模型正确识别为正样本的数量与真实类别为正样本的总体数量的比值。一般情况下,召回率越高,说明有更多的正样本被模型正确预测,模型的效果越好。召回率计算公式如下:
召回率=TP/(TP+FN)×100%.(2)
像素准确率(pixel accuracy, PA)指每个类别下预测正确的像素数量与该类别像素总数的比值,mPA是所有类别PA的平均值,计算公式如下:
式中:pii、pij分别表示类别i被预测为类别i、类别j的像素个数;k表示不包括背景的类别数。
mIoU 是分割任务的标准指标。交并比(intersection over union, IoU)指目标掩膜与预测掩膜公共区域的像素个数与两者总像素个数的比值。mIoU是所有类别IoU的平均值,计算公式如下:
式中:pii、pij分别表示类别i被预测为类别i、类别j的像素个数;k表示不包括背景的类别数。
4 模型训练与实验结果分析
4.1 模型训练
本实验环境的配置为Windows 10 操作系统、Intel(R)Core(TM)i7-10875H@2.30 GHz×16 线程中央处理器(central processing unit, CPU)、16 GB 随机存储器(random access memory, RAM)、NVIDIA GeForce RTX 2060显卡和Pytorch深度学习框架。
将收集的2 190张图像分为训练集(60%)、验证集(20%)、测试集(20%)。采用随机梯度下降法进行优化,初始学习率设置为0.000 1,每个步骤都进行优化,动量因子设置为0.9,训练批大小设置为4,轮次设置为500,具体参数如表2所示。

表2 DeepLabV3+网络模型训练参数设置Table 2 Train parameter setting of DeepLabV3+ network model
由于使用了迁移学习的预训练模型,因此训练损失能快速收敛到较小的数值。改进的DeepLabV3+网络模型的损失曲线如图5 所示,通过观察发现验证损失值能下降到0.3 左右,训练损失值能下降至0.2 左右,且波动较小,说明模型已经收敛至稳定状态,如继续训练,损失值的下降幅度很小,此时可以停止训练。改进后DeepLabV3+网络模型的mIoU曲线如图6 所示。从中可知,经过500 轮次训练,mIoU可以达到77.9%。
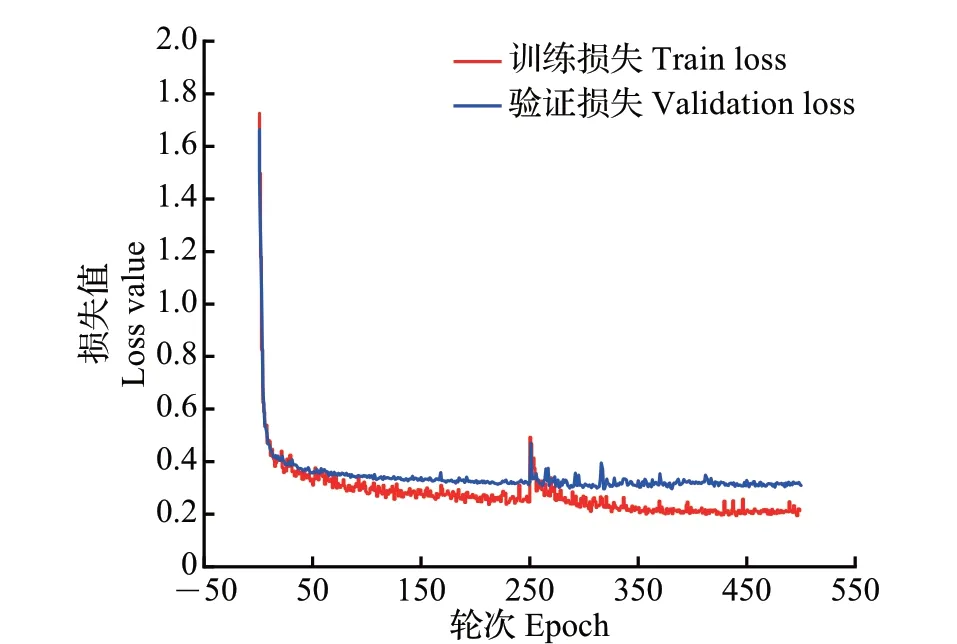
图5 改进的DeepLabV3+网络模型损失曲线Fig.5 Loss curve of improved DeepLabV3+ network model

图6 改进的DeepLabV3+网络模型平均交并比曲线Fig.6 mIoU curve of improved DeepLabV3+ network model
4.2 改进的网络模型与原网络模型指标数据对比
为验证改进的网络模型质量,对改进后的模型与原模型各项指标进行对比实验。改进的DeepLabV3+网络模型与原DeepLabV3+网络模型的损失曲线、mIoU曲线、多项参数对比结果分别如图7~9所示。
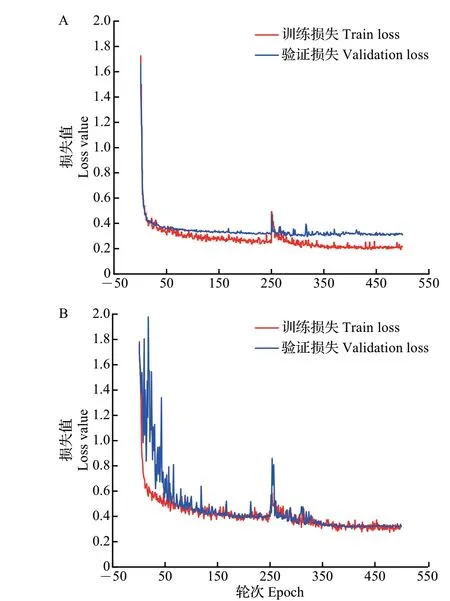
图7 改进的DeepLabV3+网络模型(A)与原DeepLabV3+网络模型(B)损失对比Fig.7 Comparison of loss between the improved DeepLabV3+network model (A) and the original DeepLabV3+network model (B)
从图7 中可知,在模型训练损失方面,与原DeepLabV3+网络模型相比,改进的DeepLabV3+网络模型损失曲线波动较小,更容易收敛;改进的DeepLabV3+网络模型比原DeepLabV3+网络模型的训练损失收敛速度更快,原模型训练损失值最低只能下降到0.3,而改进后的模型训练损失值最低能达到0.2,训练损失值较原模型降低了0.1。
从图8中可知,将改进的DeepLabV3+网络模型和原DeepLabV3+网络模型mIoU曲线进行对比,原模型(DeepLabV3+_Xception)的mIoU 为75.8%,而改进后的模型(DeepLabV3+_MobileNetV2)的mIoU为77.9%,整体增长了2.1个百分点。并且,改进后模型的mIoU曲线收敛速度更快,改进的DeepLabV3+网络模型的mIoU参数在50轮次训练时就能达到稳定,而原DeepLabV3+网络模型的mIoU参数达到稳定需要300轮次训练。

图8 改进的DeepLabV3+网络模型与原DeepLabV3+网络模型的平均交并比对比Fig.8 Comparison of mIoU between the improved DeepLabV3+network model and the original DeepLabV3+ network model
mIoU、mPA、平均精确率、平均召回率的具体结果如图9 所示。类别_0(class_0)代表背景部分,类别_1(class_1)代表杂交水稻育种父本,类别_2(class_2)代表杂交水稻育种母本,总体(overall)代表总体参数值。
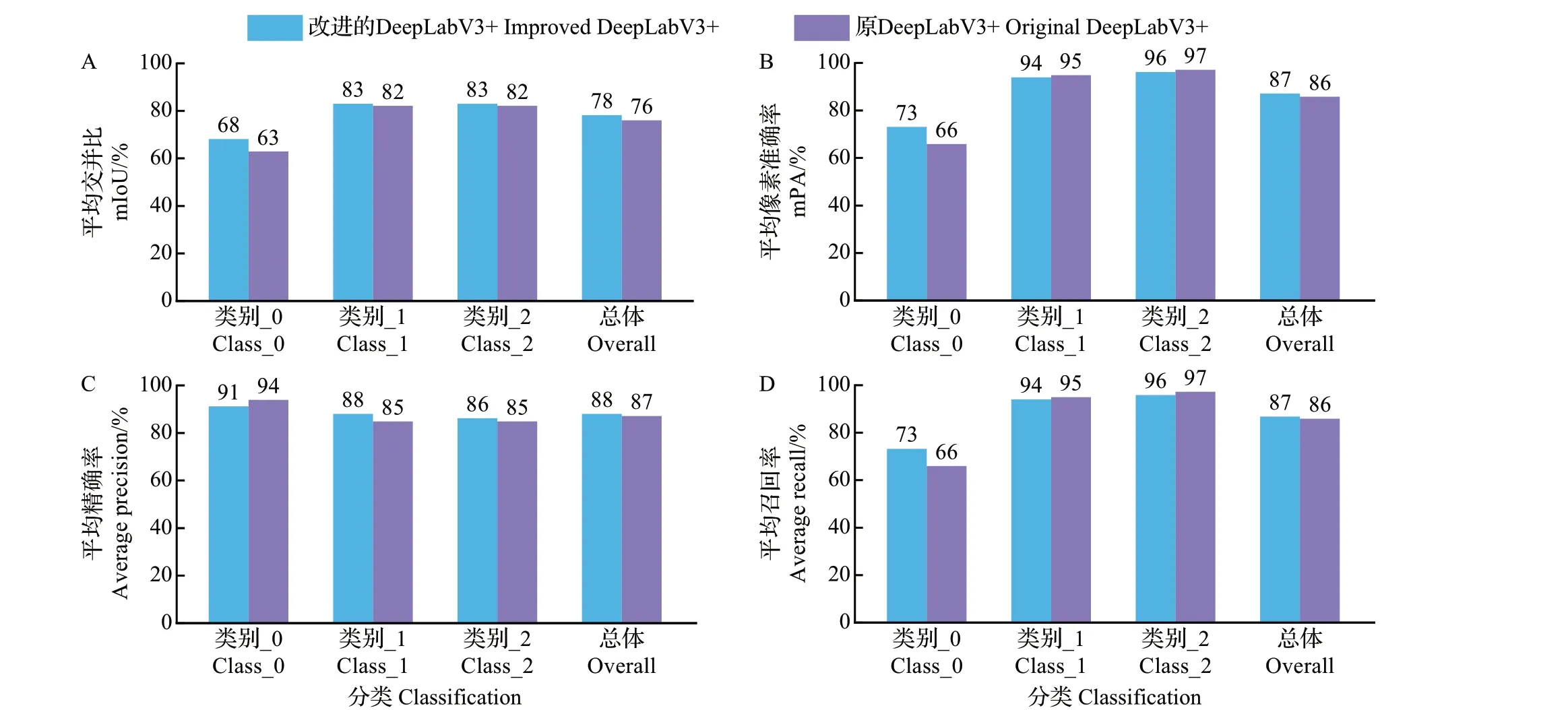
图9 改进的DeepLabV3+网络模型与原DeepLabV3+网络模型的多项参数对比Fig.9 Comparison of multiple parameters between the improved DeepLabV3+ network model and the original DeepLabV3+network model
由图9可知,在代表杂交水稻育种父本和母本的类别_1和类别_2方面,改进的DeepLabV3+网络模型的平均精确率分别高于原DeepLabV3+网络模型3个百分点和1 个百分点,能达到88%和86%;改进的DeepLabV3+网络模型的mIoU 在类别_0、类别_1 和类别_2 方面,分别高于原DeepLabV3+网络模型5 个百分点、1 个百分点、1 个百分点,能达到68%、83%和83%;在总体上,改进的DeepLabV3+网络模型的mPA和平均召回率均比原DeepLabV3+网络模型高出1个百分点。
分别利用原DeepLabV3+网络模型和改进的DeepLabV3+网络模型进行图片预测实验,2种模型分割杂交水稻育种父母本的比较结果如图10所示。从中可知,与原始图像对比,2种网络模型所训练的mIoU相差约2%,改进的DeepLabV3+网络模型的预测结果显示,图片在预测杂交水稻制种父母本的边界细节上效果更加明显。原DeepLabV3+网络模型的预测结果(图10F)显示,图像右上角边界处理较差,与改进后网络的预测结果(图10I)对比发现,后者对边界的处理更加细致,更加接近所对应的真实标签图像结果。由原DeepLabV3+网络模型预测结果(图10E)可知,图片上端对于杂交水稻父本的分割处理存在少量错误,即将背景误判为杂交水稻父本,其原因在于背景部分的杂草与杂交水稻父本外形较为相近,未经改进的网络在训练样本较少的情况下,无法对低层与高层信息建立更加紧密的联系,区分背景的能力较差,导致分割不精确;而与改进后网络的预测结果(图10H)对比可知,后者的分割处理更加准确,更加接近所对应的真实标签图像结果。
4.3 改进的DeepLabV3+网络模型与其他网络模型对比
为验证分割的有效性,利用本实验所建立的数据集,将改进后的DeepLabV3+网络模型与目前主流的分割网络模型FCN、U-Net、原DeepLabV3+以及先进网络模型OCRNet 进行对比,评估指标对比结果如表3 所示。结果显示,先进网络模型OCRNet 较主流网络模型FCN、U-Net、原DeepLabV3+分割精度更高,本研究中改进后的DeepLabV3+网络模型在mIoU、mPA、平均召回率、平均精确率上都比其余4 种网络模型更加精确,相较于其他网络模型更具优势,分割效果最好。虽然U-Net、FCN 和OCRNet网络模型分割效率较高,但是mIoU较低。此外,改进后的DeepLabV3+较原DeepLabV3+图片预测用时更少,即预测速度更快。
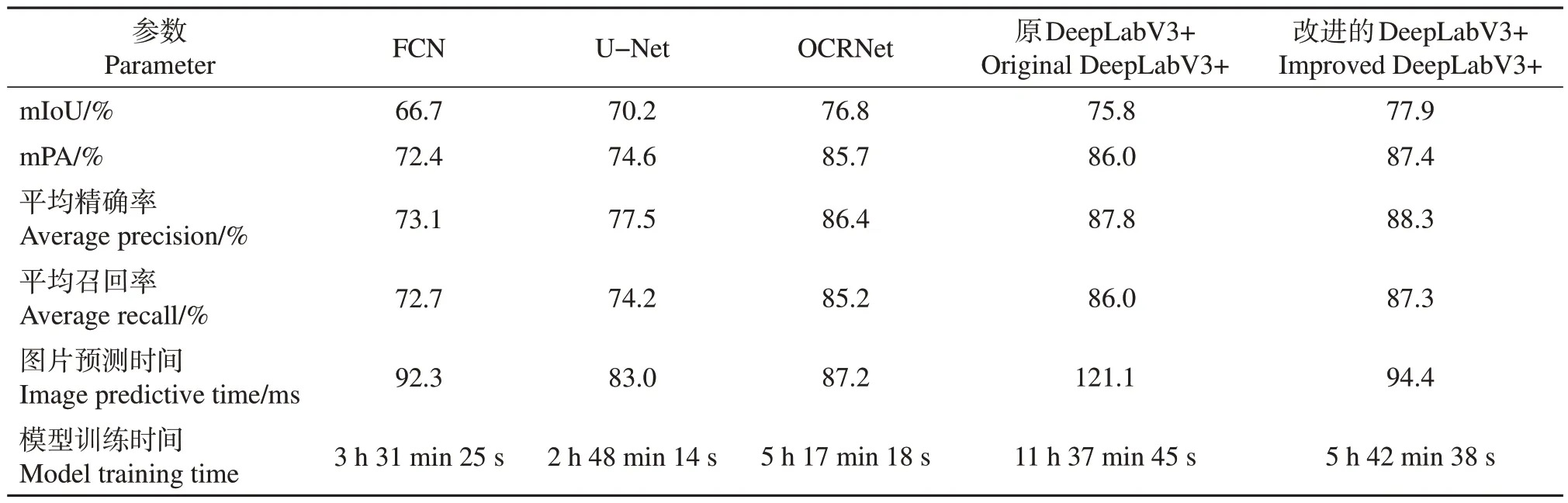
表3 不同网络模型参数对比结果Table 3 Comparison results of parameters of different network models
5 结论
为提高杂交水稻父母本的分割精度和预测效率,本文提出一种基于DeepLabV3+框架改进的杂交水稻制种父母本图像识别的语义分割模型,将原模型卷积神经网络中的骨干网络部分Xception 网络模块替换为轻量化的MobileNetV2 网络模块,并对MobileNetV2 网络的低层特征提取进行改进,提出了一种联系较为密集的信息提取方法,减少了浅层网络信息丢失,提高了图像的分割精度,也改进了深度网络模型在移动设备中实时性较差的问题。将本研究改进的DeepLabV3+网络模型与主流网络模型FCN、U-Net、原DeepLabV3+以及先进网络模型OCRNet进行对比,实验数据结果表明,改进后的DeepLabV3+网络模型对于杂交水稻制种父母本的分割效果要优于上述主流网络模型和先进网络模型,满足区分杂交水稻制种父母本的精度和实时性要求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
广西林业科学(2016年2期)2016-03-20
新校长(2016年8期)2016-01-10
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
商事法论集(2014年1期)2014-06-27
小说月刊(2014年11期)2014-04-18
电视技术(2014年19期)2014-03-11
