
利用AFW-BPNN模型实现微博真伪信息识别*
2024-01-02 07:44曹弘毅
西安工业大学学报 2023年6期
冯 楠,曹弘毅,李 妮
(西安医学院 卫生管理学院,西安 710021)
微博平台具有用户数量大、主观性强以及传播链长的特点,通过引发了社会多元主体的参与,形成了一个复杂的信息传播网络,这种复杂性造成信息识别困难。有意散播的谣言严重威胁社会秩序[1],因此,对微博信息进行准确识别在提高用户信任方面发挥着重要作用。研究表明,虚假信息呈现出多种形式,其主要特点包括以下几个方面:信息发布者通常选择匿名身份,以此来规避个人或法律责任[2];虚假信息在语言风格上具有情绪化特点,借助读者情感的复杂性来加强信息的影响力[3];虚假信息往往缺乏来自官方渠道或可信媒体的实证资料[4]。这些特点使虚假信息具有一定的误导性。
在识别方法上,国内外学者提出了许多有效的识别模型。文献[5]提出了一种基于图卷积网络(GCN)的虚假信息识别模型。该模型采用了引入图结构信息的方式,有效地利用了信息传播网络中的关系信息,取得了较高的准确率。文献[6]提出了一种基于知识增量的虚假信息检测方法。该方法将已有的真实信息与未知信息进行比对,通过发现其差异性来识别虚假信息,取得了较好的效果。文献[7]提出了一种基于卷积神经网络(CNN)的虚假新闻识别模型。该模型采用了不同的卷积核对文本进行特征提取,并将多种特征融合起来进行识别,相比于传统方法实现了更好的分类结果。文献[8]提出了一种基于深度卷积神经网络和关联矩阵分解的虚假信息识别模型。该模型通过学习关键特征和互动模式,提高了虚假信息的有效性和鲁棒性。文献[9]中提出了一种基于深度学习和情感分析的虚假新闻识别模型。该模型结合了文本内容和情感信息,有效地提高了真假信息的分类准确率。
在特征选择上,学者们主要通过三方面的特征进行识别。其中,文本特征是指微博文本内容的相关特征。文献[10]研究了一种分析和检测评论垃圾信息的方法,即通过比较评论文本与其他评论或原始文本的相似度来识别不真实评论。文献[11]提出了一种基于图文一致性的方法,通过比较网络上流传的图片、文本和视频等信息的一致性,来判断其真伪程度。文献[12]提出基于语言结构和情感极性的方法,则是利用自然语言处理技术来挖掘文本信息的结构特征和情感色彩,从而进行虚假评论的识别。用户特征是指微博账号的相关特征。文献[13]提出了一种基于评论产品属性情感倾向评估的虚假评论识别研究。他们通过分析用户评论产品的行为和情感倾向,结合用户的一些基本信息,如关注量、粉丝量、发帖频数和互动次数等因素,来识别虚假评论。文献[14]]提出的微博用户特征分析与分类研究,则是通过对用户的认证信息、性别、年龄、地域等因素进行分析,可以有效识别出潜在的虚假账号。传播特征是指微博信息传播时的相关特征。网络传播时信息的扩散方式受网络拓扑结构的影响,因此通过分析微博信息传播网络的结构属性,可以有效地识别虚假信息[15]。文献[16]提出的融合用户历史传播信息的微博谣言检测,则是基于用户之间的社交关系,通过分析用户历史上的传播信息,来判断当前信息是否真实。
然而,现有研究往往只侧重于某一方面的特征提取,难以反映微博信息的全貌。本文提出综合考虑微博信息的多元特征可提高信息真伪的识别精度。综合考虑文本、用户和传播三方面的特征,更全面地反映微博信息的真实情况,从而有效解决微博真伪信息识别问题。
1 方法构建
1.1 模型设计
BP神经网络作为一种深度学习的方法,对烟叶褐变程度[17-18]、农产品质量评估[19]、人脸图像识别[20]等方面具有较好的识别精度,可以利用BP神经网络自动识别系统替代人工识别。本文采用BPNN模型来综合考虑微博信息的多个特征,包括文本、用户和传播三方面的特征,并充分考虑三者之间的相互关系。
在提取微博信息的文本特征、用户特征和传播特征的基础上,将不同的类型的特征进行融合,合并作为输入变量,建立基于BPNN模型的微博信息的识别模型,如图1所示。
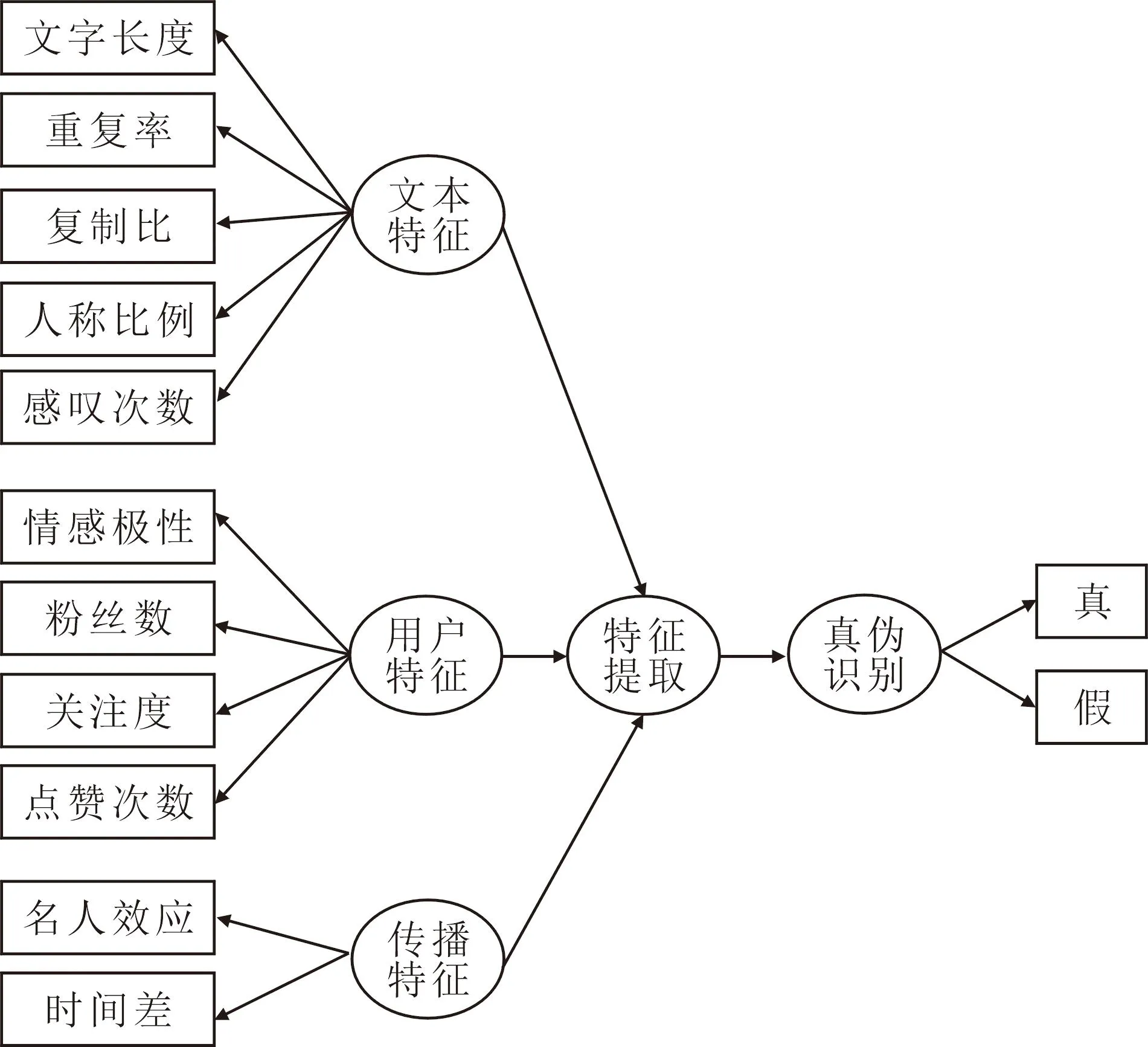
图1 微博信息真伪识别模型构建
1.2 方法理论
在BP神经网络中,权重(W)和偏置(B)是用来调整和更新神经元之间连接强度的参数。神经网络的学习和优化过程涉及到一种称为反向传播(Backpropagation)的算法。
反向传播算法基于梯度下降的优化原理,通过计算模型预测输出与实际输出之间的误差,然后根据误差来更新权重和偏置。具体而言,算法首先进行前向传播,将输入样本数据通过权重和偏置的线性变换和激活函数映射,得到模型的输出值。然后计算输出值与实际标签之间的误差,这个误差可使用各种损失函数来度量,例如交叉熵损失(Cross-Entropy Loss)。
反向传播算法从输出层开始,根据链式法则计算每一层对应的梯度。通过计算梯度,我们可以知道在当前权重和偏置情况下,每个参数对误差的贡献程度。然后,根据梯度和学习率(Learning Rate),我们可以更新权重和偏置的数值,使其朝着减小误差的方向进行调整。具体计算步骤如下:
① 前向传播(Forward Propagation)
计算每个神经元的加权和:对于第i层的第j个神经元,计算加权和
Z[i][j]=∑(Z[i-1][k]*W[i][j][k])+B[i][j],
(1)
式中:Z[i-1][k]为前一层第k个神经元的输出;W[i][j][k]为连接第i-1层第k个神经元和第i层第j个神经元的权重;B[i][j]为第i层第j个神经元的偏置。
应用激活函数g()对加权和进行非线性映射,得到当前神经元的输出
A[i][j]=g(Z[i][j])。
(2)
② 计算损失(Loss)
(3)
③ 反向传播(Backpropagation)
初始化梯度矩阵dW和dB,将其设置为零矩阵。从输出层开始,逐层反向计算每个神经元的梯度。对于输出层第i个神经元,计算其梯度
dZ[L][i]=∂L/∂A[L][i]*g′(Z[L][i]),
(4)
其中:∂L/∂A[L][i] 为损失函数对输出层第i个神经元输出的偏导数,g′()为激活函数的导数。
对于隐藏层(第L-1层)第j个神经元,计算其梯度
dZ[L-1][j]=∑(W[L][i][j]*dZ[L][i])*
g′(Z[L-1][j]),
(5)
其中W[L][i][j]为连接第L层第i个神经元和第L-1层第j个神经元的权重。根据梯度,更新权重和偏置
对于第i层第j个神经元的权重W[i][j][k],更新规则为
W[i][j][k]=W[i][j][k]-α*
A[i-1][k]*dZ[i][j],
(6)
其中α为学习率,A[i-1][k]为前一层第k个神经元的输出。
对于第i层第j个神经元的偏置B[i][j],更新规则为
B[i][j]=B[i][j]-α*dZ[i][j]。
(7)
重复上述步骤,直到计算出所有层的梯度并更新完所有的权重和偏置。通过多次迭代和反向传播,神经网络可以逐渐学习到输入数据中的特征,并优化权重和偏置的数值,以提高对输入数据的预测能力。
2 数据来源与处理
2.1 数据来源
通过采集新浪微博数据管理中心的热门话题数据,内容涵盖娱乐、生活、体育等多个领域。该数据集共包括1 000个样本,根据信息、用户、话题和传播路径中的属性特征[21-22],选取了11个指标构建用户信息的数据集。这些指标包括:文本特征、用户特征和传播特征,包括文字长度、词语重复率、感叹词数量、账号ID、粉丝数、关注量、转发次数、时间差等多方面的因素。
2.2 特征提取
2.2.1 文本特征提取
在连续词袋模型(Continuous Bag-of-Words,Text-CBOW)的基础上引入贝叶斯假设算法,建立改进的Text-CBOW算法,Text-CBOW模型生成的词向量可以用于各种自然语言处理任务,词向量可以作为这些任务的输入特征,提高模型的性能和泛化能力。如图2所示。
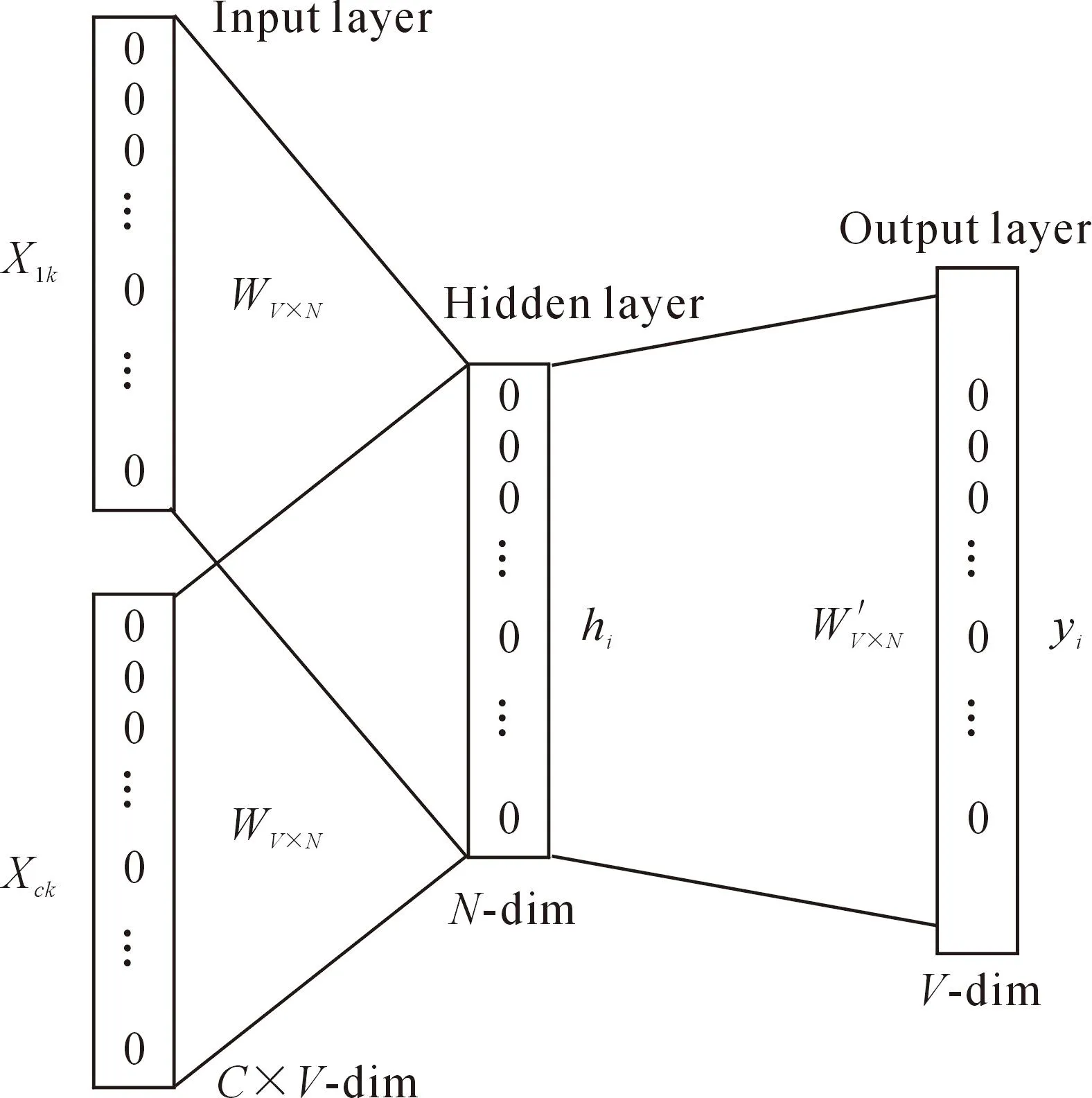
图2 Text-CBOW算法流程图
Text-CBOW算法由输入层、隐藏层、输出层连接而成,利用基于概率统计的共轭矩阵窗口来提取特征词汇。本文采用频率算法(Term Frequency-Inverse Document Frequency,TF-IDL)将微博不同长短的语句进行词性分割,用one-hot将语句编码为[0,1,1,1,0,0,1]形式的向量,记录分割后的名词、动词和形容词等词频,根据PageRank公式计算不同词汇的权重,将权重高的作为关键词。计算公式如下
(8)
其中,PR(Ti)是微博文本中存在的词汇,C(Ti)是微博中的词汇数量。
2.2.2 用户特征提取
DeepFM模型适用于稀疏特征的提取,常用于User ID和Item ID的特征分析。用户特征涉及社会多方面的交互联系,本文以微博用户的账号信息为依据,采用DeepFM算法提取用户的属性特征。用户信息对于微博的真伪检测至关重要[23-24],提取内容包括用户账号、性别、省份和粉丝数等方面的个人信息,以及浏览内容、发文频率、转发次数等方面的行为特征。
DNN模型提取用户信息的高维特征,可不经过embedding层的向量压缩,能同时学习用户属性和行为方式的组合特征。DNN计算公式如下
ypred=sigmoid(yFM+yDNN)。
(9)
2.2.3 传播特征提取
以微博谣言的传播时间为依据,采用时间序列预测模型(Autoregressive Integrated Moving Average Model,ARIMA)提取微博传播的时间差特征。微博虚假信息从产生到消亡是一个随时间变化的过程,而虚假信息的爆发期具有迅猛、短暂的特点[25-26]。ARIMA的关键步骤如下
(10)
其中p为微博传播事件的自回归项数,q是移动平均项数。
虚假信息一经传播,会相应地出现一系列辟谣言论,且辟谣消息扩散更快。因此,距离虚假信息的时间越长,是虚假信息的可能信越小,将当前微博评论时间距离源微博的发布时间作为时间差特征。时间差特征的计算如下
T=T评论-T发布。
(11)
2.2.4 权重自适应特征融合
权重自适应特征融合方法可以将不同特征进行融合,并根据其重要性给予不同的权重,能够实现特征表达并提高识别精度[20]。下面是对11个特征进行融合的计算公式和过程说明。
1) 归一化处理:对每个特征进行归一化处理,将其转化到一个相同的尺度上。假设特征集合为X={x1,x2,…,xn},其中xi表示第i个特征。对于每个特征xi,可以使用如下的归一化公式
(12)
2) 向量交叉乘积:将每个特征xi与其他所有特征进行向量交叉乘积运算,并将结果保存在一个矩阵M中。矩阵M的维度为n×n,其中n为特征的数量。具体地,矩阵M的第i行第j列的元素表示特征xi与特征xj的向量交叉乘积的结果。向量交叉乘积可以用如下公式表示
cross productij=normalizedxi*
normalizedxj。
(13)
3) 相乘后的权重:在求得矩阵M后,需要为每个特征指定一个权重。权重可以根据特征的重要性进行设定,或者使用其他自适应的方法来计算。假设特征权重的集合为
W={w1,w2,…,wn},
(14)
其中wi为第i个特征的权重。可以将矩阵M中的每个元素与对应的特征权重相乘,得到加权后的结果。具体地,矩阵M的第i行第j列的元素与特征权重wi和wj的相乘可以表示为
weighted productij=cross productij*wi*wj。
(15)
通过以上三个步骤,可以使用权重自适应特征融合方法将给定的11个特征进行融合,并得到交叉相乘后的融合结果,以便更好地反映特征之间的关系。
3 结果与讨论
3.1 特征提取结果
文中收集了1 000条微博信息,并提取了各种特征,包括文本特征、用户特征和传播特征。其中,文本特征包括微博长度、词语重复率和感叹词数量,用户特征包括账号ID、粉丝数和关注量,而传播特征则考虑了转发次数和时间差等因素。这些特征已经整理并列于表1中。旨在通过整合多元化的特征,构建出一个精准、全面且有一定信息量的微博信息识别模型。
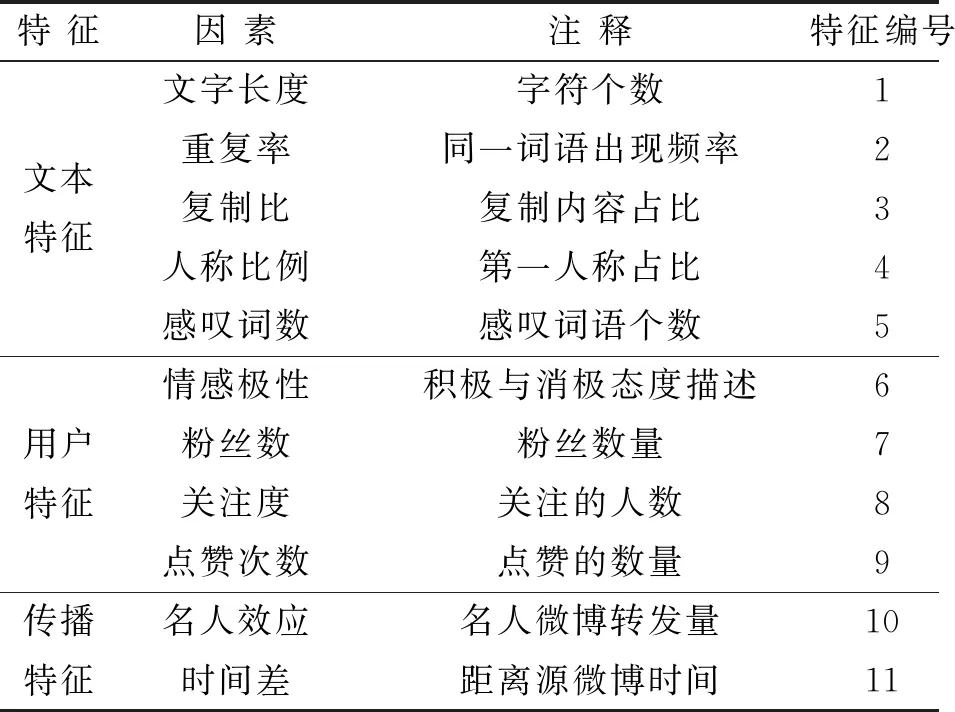
表1 特征提取结果
3.2 研究结果
从图3中的特征权重值可以观察到,重复率(特征编号2)和人称比例(特征编号4)的权重值分别为0.20和0.15,相对其他特征来说较大。这表明重复率和人称比例在微博真伪信息的识别中具有较高的重要性,对最终的识别结果有较大的贡献。除了重复率和人称比例这两个特征外,其他特征的权重值在0.05~0.1之间。这些特征的权重值相对较小,说明它们对于微博真伪信息的识别作用相对较弱。
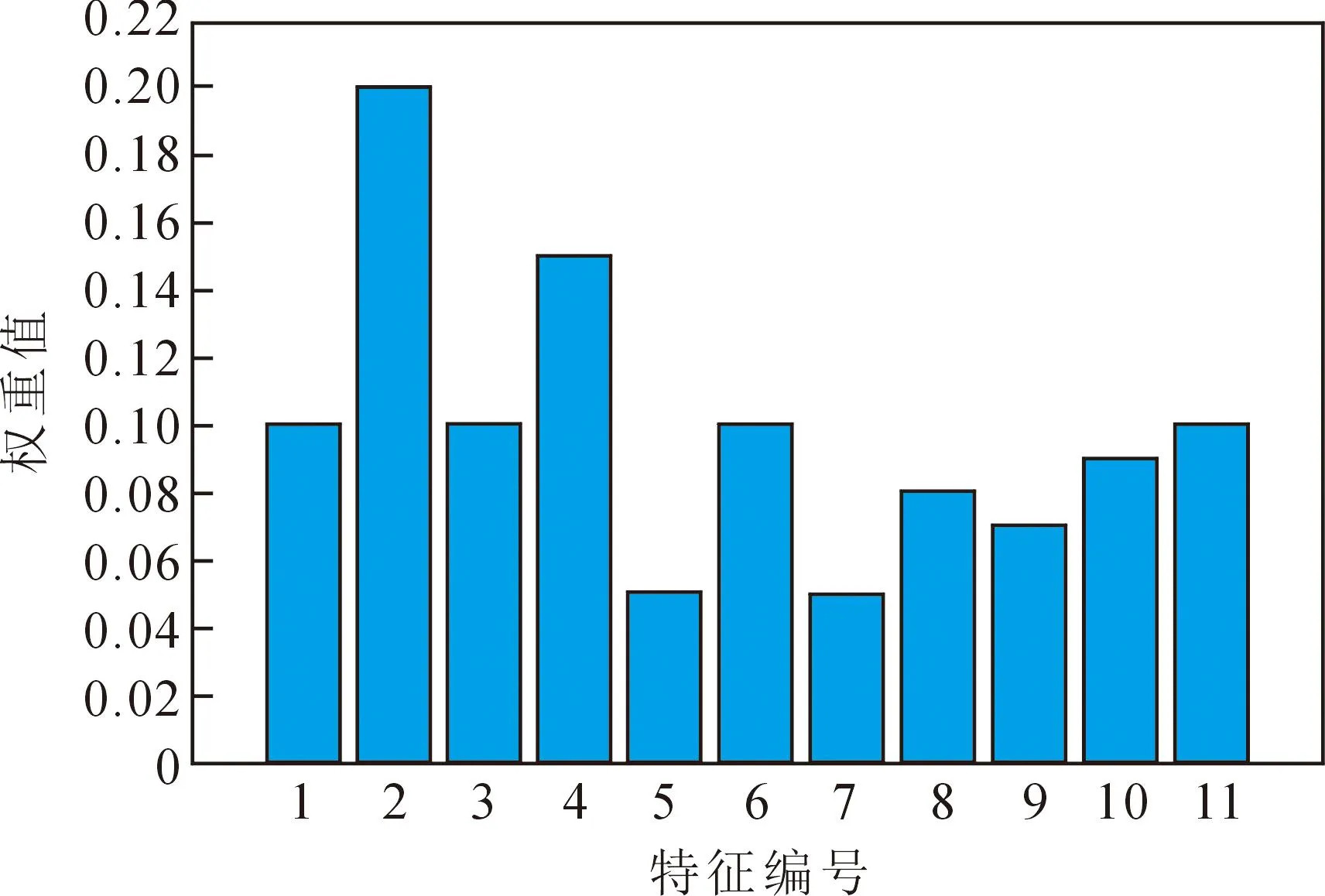
图3 适应权重分析
需要注意的是,特征权重的大小并不一定直接决定特征本身的重要性,它们的大小也受到模型训练过程的影响。因此,在BPNN模型中,我们需要进行多元特征融合,以提高微博真伪信息识别的准确性和鲁棒性。
该BPNN模型以1 000个样本11个特征构成的[11*1000]矩阵作为输入变量,因变量矩阵在Matlab中编辑为
target=zeros(1 000,2);
target=(1:700,1);
target=(701:1 000,1)。
在隐藏层通过调整神经节点个数来提升识别精度,得到最优识别精度的节点个数为8,输出结果为真伪两种类别。模型架构如图4所示。
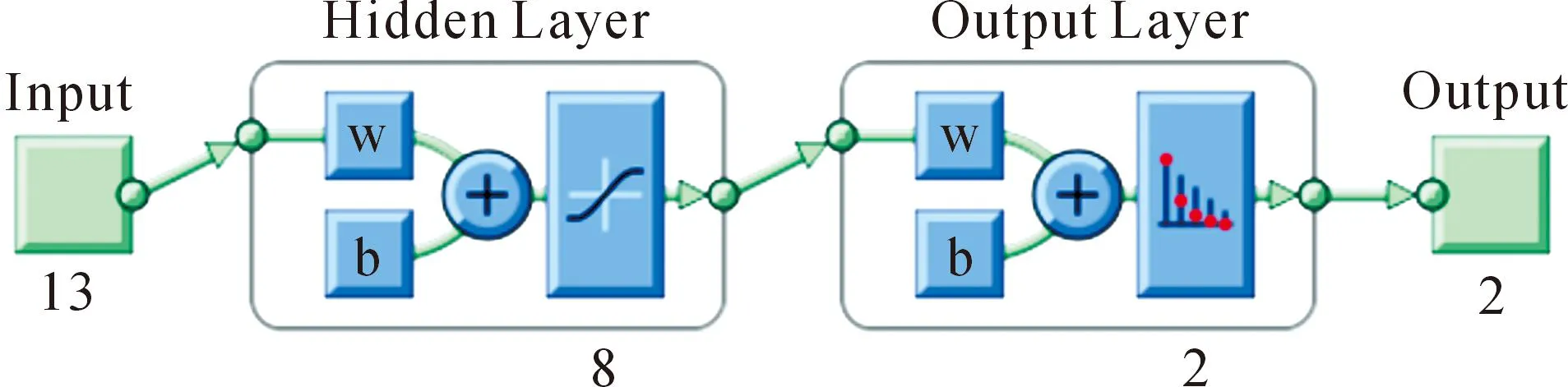
图4 BPNN模型架构
设置训练集、验证集、测试集的比例为70%∶15%∶15%,以贝叶斯算法对BPNN模型反复训练,通过试错法调整迭代次数为50次,大大提高了模型的收敛精度。在训练集、验证集、测试集和全样本中,模型的识别准确率分别为:94.1%,93.3%,98.0%,94.6%。识别结果如图5所示。

图5 BPNN模型识别结果
为了进一步评估模型的性能,可以根据ROC曲线的形状来判断模型的准确性。曲线在左上角的接近于上边界表示了模型的较高真阳性率和较低假阳性率,这是一个理想的情况。根据图6的结果显示,在训练集、验证集、测试集和全样本中,ROC曲线都位于对角线的左上方,这表明模型的拟合效果非常出色。同时,代表真伪类型的“Class1”和“Class2”的ROC曲线几乎与上边界重合,这说明构建的BPNN模型在预测微博信息的真伪方面具有很好的性能。
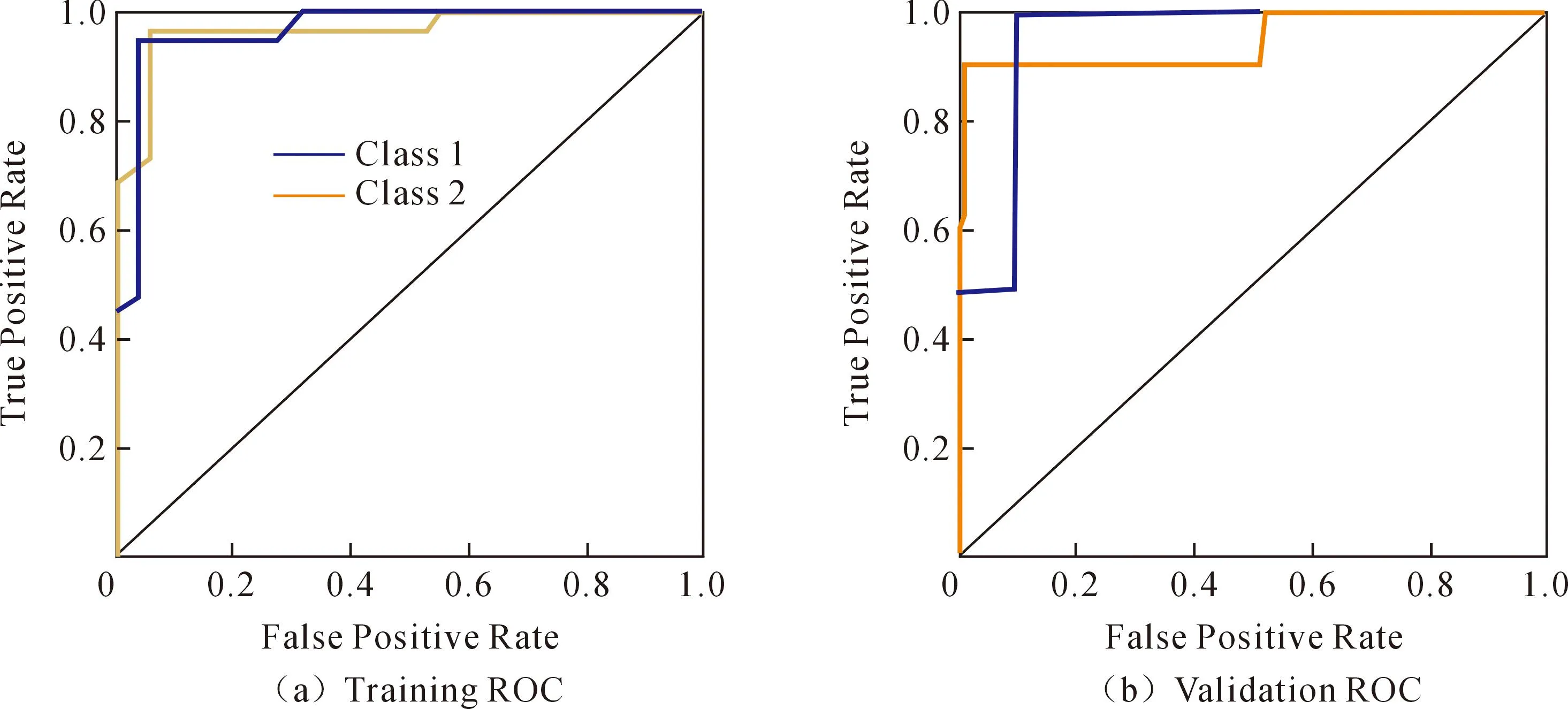
图6 BPNN模型评估
4 结 论
1) 以1 000条微博事件信息样本为研究对象,进行识别训练。其中真实信息700条和不实信息300条。针对微博信息的属性特点,分别提取文博的文本特征、用户特征、传播特征,包含文字长度、复制比、情感极性、关注度、时间差等11个参数。选用提取的特征参数,以数字“1”“2”分别代表真实信息和虚假信息,建立了微博信息真伪的识别模型。在微博用户兴趣识别的研究中,图像,博文和用户标签合成的多模数据比单一模块的数据分类识别精度能够提高10%。在微博用户社交信任评估中,将四个不同的因素通过熵权法来统一量化,可以提高可信节点的识别。鉴于融合特征在一定程度上能够提高识别精度,本文在建模过程中,利用自适应权重的方法将11个因素的特征向量相互融合,并建立了微博真伪信息识别的BPNN模型。
2) 在微博信息的分类识别结果上,相关学者通过扩展上下文特征和匹配特征词的方法,对微博中的灾害信息识别正确率达到74%。在公共卫生事件中,通过引入用户历史特征和情感特征,使用DNN网络对谣言识别准确率达到94%。而另一项研究中,引入时空特征的二元逻辑回归模型,在公共卫生事件中的谣言识别准确率达到98%。由此可见,针对微博的具体内容特征,需要采取合适的特征提取和模型方法,才能达到最优的识别精度。本文设置训练集、验证集、测试集的比例为70%∶15%∶15%,采用贝叶斯算法训练,将[11*1 000]的输入特征矩阵转化为[2*1 000]的分类矩阵,整体预测效果提升到94 .5%。
3) 文中的理论意义在于完善了信息识别的方法。具体体现为:与已有单一特征(文本特征、用户特征和传播特征)识别方法相比,本文建立的基于BPNN模型的微博真伪信息识别研究,将单一的微博特征运用自适应权重法转化为融合特征,进而更好地适用于模型训练和真伪识别。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19
中国信息化(2022年5期)2022-06-13
自然杂志(2021年6期)2021-12-23
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
现代装饰(2018年5期)2018-05-26
电信科学(2017年6期)2017-07-01
北京航空航天大学学报(2016年6期)2016-11-16
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
