
基于LSTM网络的粮食干燥机水分预测与优化
2024-01-13 02:53谢辉煌张忠杰宋春芳
中国粮油学报 2023年11期
谢辉煌, 金 毅, 张忠杰, 尹 君, 宋春芳
(江南大学机械工程学院;江苏省食品先进制造装备技术重点实验室1,无锡 214122)
(国家粮食和物资储备局科学研究院;粮食储运国家工程研究中心2,北京 100037)
粮食干燥是一个复杂的非线性、时滞性以及多变量耦合的过程,且具有大批量、及时性的干燥需求,使得对干燥设备的工业化性能要求较高[1],国内粮食干燥设备自动化程度低,控制存在迟滞性,粮食干燥机出机水分无法精准预测是最为主要的问题之一[2]。把控出机粮食水分是粮食干燥最基本的要求,水分过高会导致粮食水分无法满足储藏条件,过低则会造成能源浪费以及品质劣变等问题,因此精准预测出机粮食水分对干燥机的调控具有至关重要的指导作用[3]。
较早的有关水分预测的方法主要是基于干燥经验以理论模型所建立的[4-9],这些模型存在建模复杂,求解困难,或是存在模型建立后假设过于理想化,对现实因素的考量并不充分等问题,其作为预测模型的局限性也越来越明显[10]。
近些年来,神经网络依靠其较强的自适应,自学习能力以及十分优越的逼近效果,被认为是一种处理复杂、非线性模型问题的有效方法,国内外也已经有一些将其应用于粮食干燥过程水分预测的分析,其中BP神经网络作为最常用的一类神经网络已有许多报道[11-13],而传统BP是一种静态的神经网络,网络的预测输出仅依赖于当前时刻的输入,比较适合输入较为平稳时,实际某一时间的粮食出机水分是受过去一段时间粮食干燥机状况的影响,采用依据序列的预测会更加合理且可以对数据突变有更好的抗干扰性能以及稳定性。
长短期记忆神经网络(LSTM)作为一种动态神经网络将时间序列的概念引入到神经网络的输入中,且可以挖掘长序列数据之间前后的信息关联,目前已经在翻译[14]、语音识别[15]、股票[16, 17]、天气[18]、剩余寿命[19]及轨迹[20]预测等多个领域得到了应用。研究基于LSTM算法建立稻谷干燥出机水分预测模型,进行了相关性分析,优化模型参数并与以往的预测算法模型进行对比,尝试得到预测性能更好的模型,以用于干燥机稻谷出机水分预测。
1 材料与方法
1.1 实验设备及方案
为方便实验,研究选用小型连续式谷物干燥机作为实验设备,以粮库的大型干燥塔为原型进行设计,以保证其结果的可靠性与真实性,采用顺流干燥,混流冷却的干燥工艺。
系统工作流程简图如图1所示,系统主要组成为储粮仓、粮食烘干机、送料装置。核心部分烘干机分为原粮段、干燥段、冷却段以及排粮段,由冷风机、加热装置以及热风机组组成。系统工作时,湿粮通过送料装置从储粮仓运输到烘干机,并通过上下位置开关控制进料过程,谷物从干燥机顶部落入后堆叠在烘干机内进行干燥作业,干燥后底部冷风器对谷物进行冷却,最后通过底部的闭风器以一定速率排出。
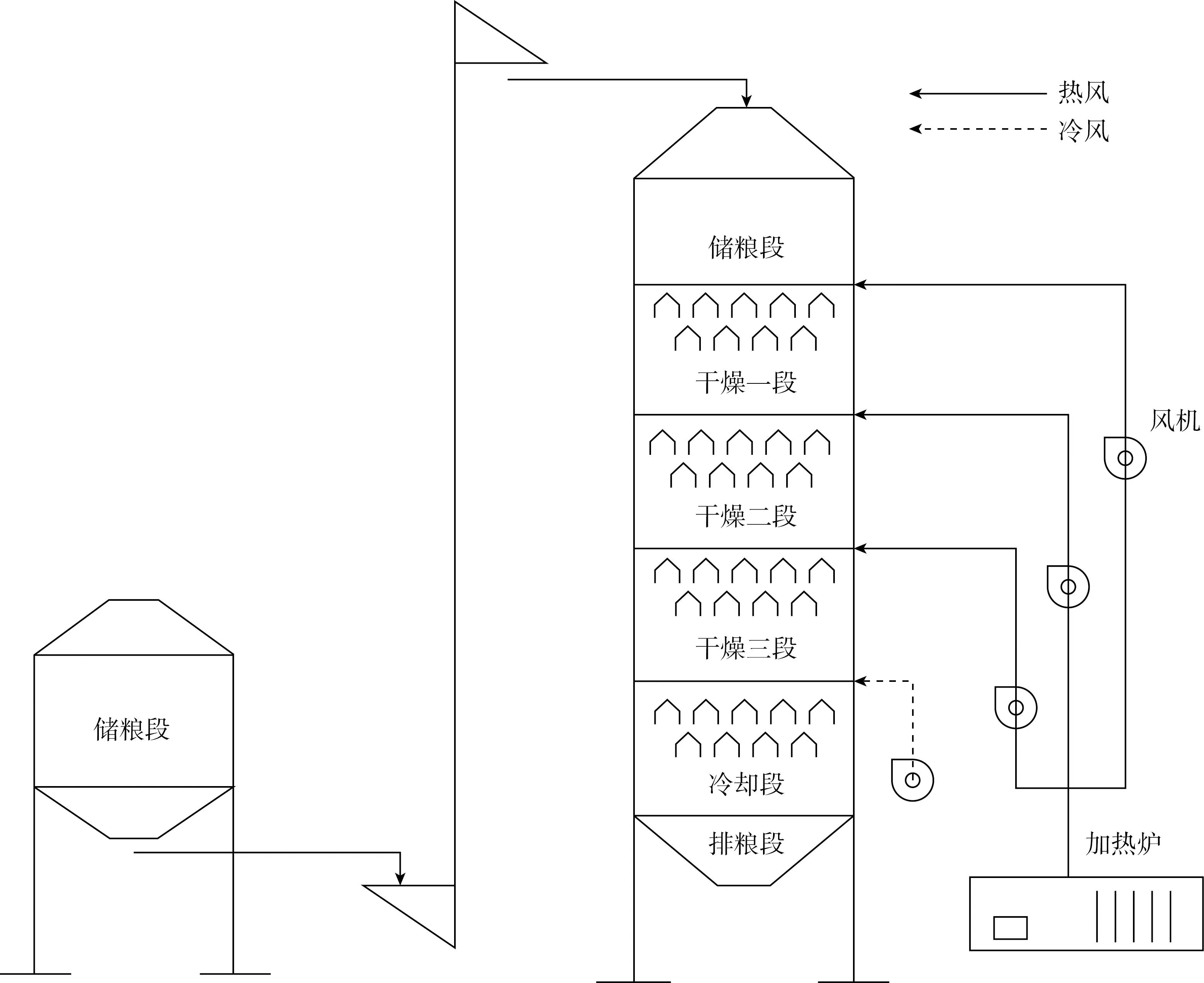
图1 系统工作流程简图
实验所选稻谷为当季采购的早籼稻美香占2号(广东广州),实验于2021年夏季在国家粮食和物资储备局科学研究院昌平中试基地进行连续实验。干燥期间系统连续运行进行数据采集,通过实验过程中不断改变各项干燥机参数及初始水分,获取多样性数据样本,以用于后期神经网络模型训练。
1.2 数据收集
粮食干燥过程中其出机水分会受多种因素的影响,环境状况会致使稻谷初始水分和温度的波动,而在干燥时干燥机的干燥作业条件,诸如干燥段温度、风速以及排潮管状况等都会直接影响粮食出机水分[21]。实验结合干燥中对出机水分影响较为主要的因素,以及设备本身所采集到的数据类别,使用PT100温度传感器采集各粮段温度(Td),RST0JWSH-5传感器采集各段排潮口温湿度(To,Ho),FST100-2001D传感器采集环境温湿度(Ten,Hen),PT2703水分检测仪采集稻谷进出口含水率(Min,Mout)采集间隔为1 min。干燥机内所采集的部分原始数据见表1,共计14项数据,并确定以稻谷出机水分作为网络模型的输出,剩余因素作为网络的输入项。

表1 粮食干燥机部分实验数据样本
1.3 数据处理
考虑到实验开始时的初始误差以及干燥过程产生的随机误差,共筛选出2 438组实验数据,由于采集数据量级不同且数据类别较多,为了降低训练难度,提高模型预测精度需要对数据按式(1)~式(3)进行标准化处理:
(1)
(2)
(3)

2 LSTM模型开发
2.1 模型描述
长短期记忆神经网络是一种改进的循环神经网络(RNN),由Hochreiter等[22]提出,不同于传统的RNN,为了在长序列问题上有更好的表现,LSTM通过引入门的机制,有效解决了长序列数据训练时梯度消失和梯度爆炸的问题。LSTM在传统的RNN基础上,增加了记忆单元,包括有遗忘门、输入门和输出门3个模块来控制内部信息的流入与流出,其记忆单元如图2所示,以序列的第t步为例。
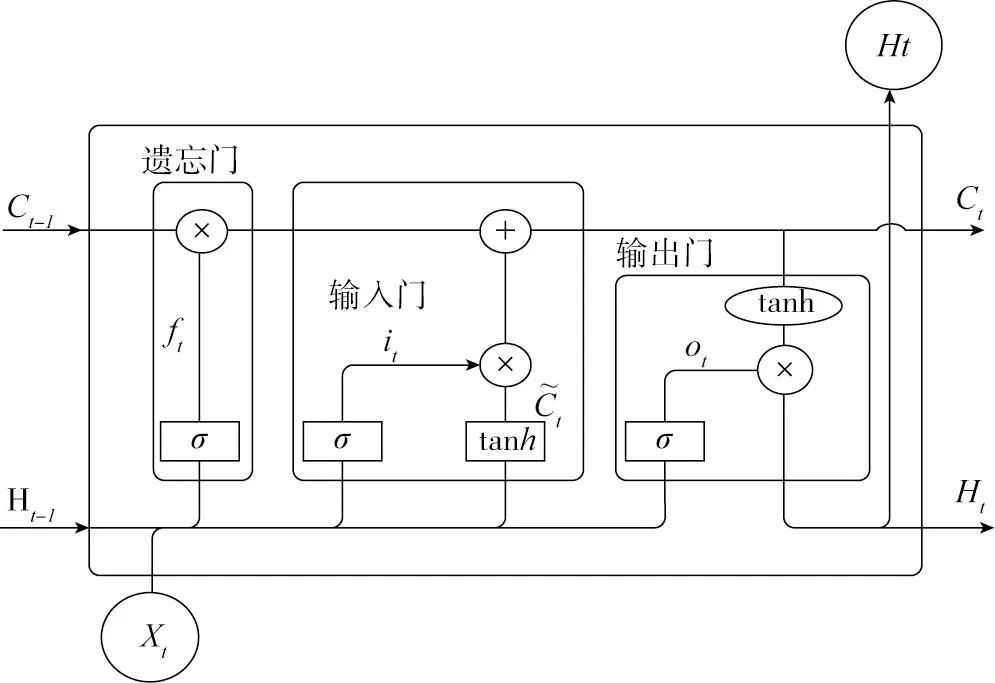
图2 LSTM记忆单元
2.1.1 遗忘门
遗忘门负责对上一时刻长期记忆单元进行筛选丢弃,它是依据网络输入节点的Xt和Ht-1去决定如何修改删除记录,相关计算公式见式(4):
ft=σ(Wf·[Ht-1,Xt]+bf)
(4)
式中:ft为遗忘门;σ为sigmod激活函数;Xt为t时刻的输入;Ht-1为t-1时刻的短时记忆输出;Wf为遗忘门权重;bf为遗忘门偏置。
2.1.2 输入门
输入门根据网络输入节点的Xt和Ht-1来决定需要添加到记忆中的新内容,相关计算公式见式(5)~式(7):
ii=σ(Wi·[Ht-1,Xt]+bi)
(5)
(6)
(7)
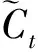
2.1.3 输出门
根据长期记忆单元Ct以及输入节点Xt和Ht-1的状态,输出输出值Ht,相关计算公式为:
ot=σ(Wo·[Ht-1,Xt]+bo)
(8)
Ht=ot×tanh(Ct)
(9)
式中:ot为输出门;Wo为输出门权重;bo为输出门偏置项;Ht为t时间点模型的所有输出。
2.2 稻谷出机水分LSTM预测模型构建
稻谷干燥是一个连续且复杂的过程,容易受稻谷自身因素、环境因素、干燥介质状况等不确定因素影响,需要考虑多项因素,但对于神经网络输入对象越多网络越复杂,过多的数据也会导致数据本身的精确度有所下降,研究输入与输出根据1.2节所述设定。LSTM预测模型结构如图3所示,由输入层、双LSTM层、dropout层、全连接层、输出层组成。输入层是具有序列性质的多特征输入,采用多层LSTM较单层有着更好特征表达能力,能够提高模型精度[23],dropout正则化可以使模型在训练时随机丢弃一些神经元从而减少局部特征的依赖性降低过拟合[24]。模型在LSTM隐藏层对特征进行提取后,依靠全连接层输出稻谷出机水分预测值。

图3 LSTM预测模型结构
2.3 模型训练
训练模型前需要对所采集的2 438条数据进行样本划分,考虑到LSTM的输入是三维张量(输入样本数,时间步长,输入特征维度),需要对输入数据进行重组,假定初始步长为100,一组输入即为100×13的矩阵,2 438条数据共计重组成2 339组输入,再按9∶1的比例划分训练集和测试集。模型的训练流程如图4所示,训练环境为win10操作系统,处理器型号Intel Core i5-4210M双核处理器,内存16GB,编程语言采用Matlab。

图4 基于LSTM的稻谷出机水分预测模型流程图
2.4 性能评估
将预处理后的数据用于模型的训练与测试,并采用均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R2)对模型的预测性能进行评估[25],其中RMSE,MAE越小表明精确度越高,而R2越接近1则说明预测与实际的差异越小。所有模型均重复训练10次并取平均值作为最终结果以减小算法带来的随机性误差。
(10)
(11)
(12)
3 结果与分析
3.1 影响因素相关性分析
由图5的相关系数分析可知,出机水分Mout与所选因素Min、To2、To3、Td1、Td2、Td3相关性十分显著,相关系数均大于>0.5,排潮口湿度与出机水分的相关性较弱,而在距离出粮口越近阶段采集的因素相关系数更大,影响程度更明显。
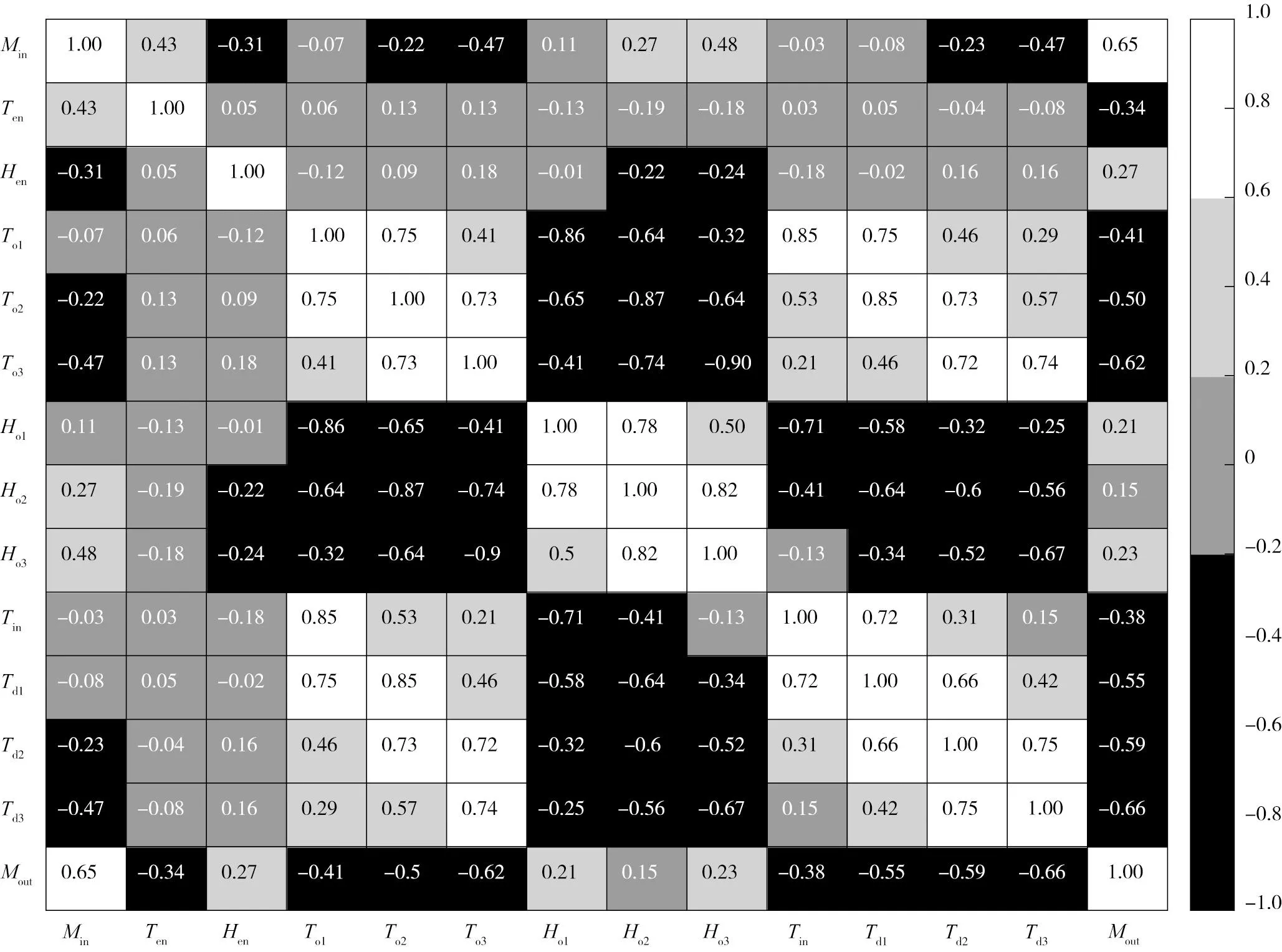
图5 出机水分与各因素的相关系数
3.2 模型超参数优化分析
采用Adam算法对模型进行优化,由于LSTM中的各项参数会对模型结果的精度,训练时间等有一定影响,需要对不同的模型参数进行优化分析,根据文献可得[26 , 27],LSTM模型参数主要包括有训练时的学习率,迭代次数epoch,批尺寸batchsize,以及网络框架中所涉及的输入时间步长,隐含层神经元数等。在训练过程中,使用RMSE作为损失函数来计算误差,损失loss代表训练过程中训练样本预测值和真实值的差异程度。在训练初期随着训练次数增加误差急剧下降,随后误差变化逐渐减小,继续训练达到一定次数后,误差基本稳定,因此无需过多的增加训练次数。
模型训练过程中,学习率决定了每次权重更新的步长,批尺寸数决定了权重更新的频率,迭代次数会影响模型训练精度以及时长。对不同的学习率(0.010、0.001)、批尺寸(50、100、150)和迭代数(50、100、200)训练下的模型进行测试,得到如表2所示的LSTM训练结果,批尺寸50,学习率0.001,迭代次数50次时,模型拥有较佳的训练效果及性能,此时模型迭代1 600次后误差基本平稳,训练时长为2∶10。
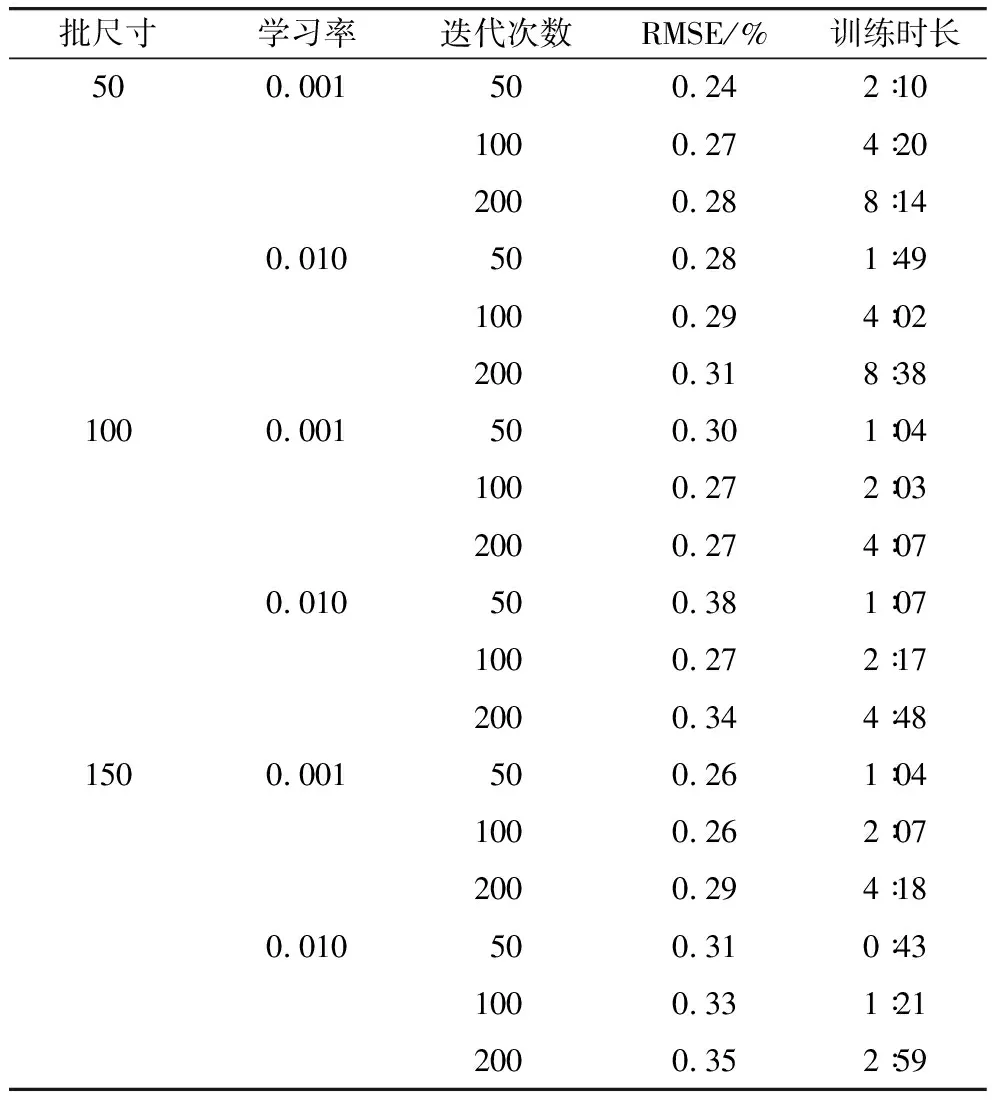
表2 不同训练参数下LSTM网络模型性能
同时为了探究网络结构参数(输入时间步长,LSTM层神经元数)对模型的影响,设置网络结构中输入时间步长10、40、70、100,以及LSTM层神经元数50、100、150、200,通过比较不同参数组合的RMSE、MAE、R2挑选最优结构参数,从表3中可以得到时间步长为40,隐藏层节点数为100×100时,RMSE、MAE和R2是最优的,分别是0.19%、0.23%和0.87。且可以发现当时间步长较短时,网络精度随着隐藏层神经元数的增加而提升,而当时间步长增加时,增大神经元数并不能使网络精度不断提升,复杂的隐藏层结构会导致过拟合的产生使得网络精度下降。综合得到整个网络的最优参数设置如表4所示。
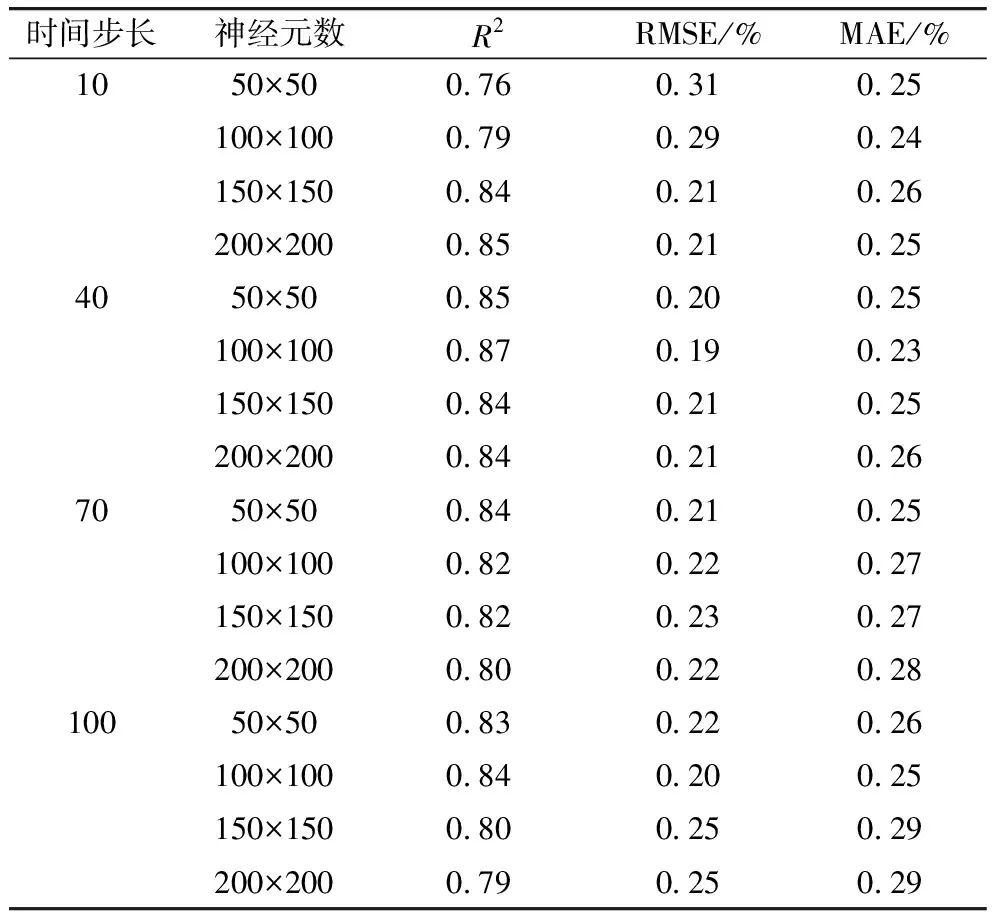
表3 不同LSTM网络结构参数下的性能评估
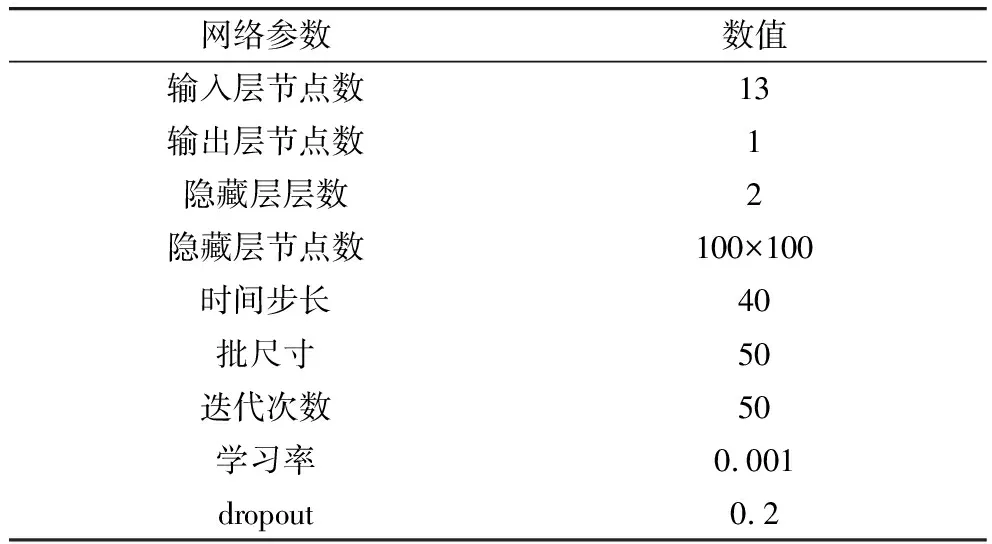
表4 LSTM模型参数优化结果
3.3 不同训练数据量模型性能分析
在最优训练参数下,对比分析不同训练数据量条件下的模型性能。结果如表5所示,可以看到随着训练数据量的增加,预测精度得到了提升,降低了模型的过拟合。在数据量较大时,模型预测性能提升效果下降。
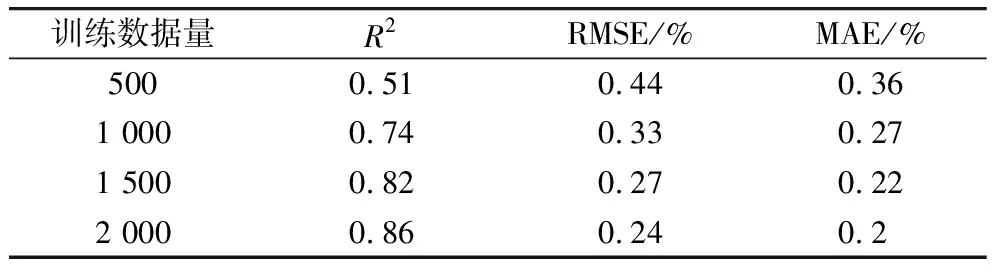
表5 LSTM模型参数优化结果
3.4 水分预测模型对比分析
为了验证研究所确立的LSTM模型优越性,将其与其他3种不同的算法进行对比(BP、ELMAN、NARX),由于这三类算法模型的参数较少,采用网格搜索的方法确立其最佳参数。此外,还对比了单隐藏层LSTM以及无dropout化的LSTM的预测效果。按照2.3节中划分的数据,选取测试数据229组作为测试样本,在相同的环境下进行运算且均采用效果最佳的网络模型进行测试,得到预测结果(图6)。由图6a可得,在所有算法中,所采用的LSTM相较于其他算法模型,预测结果更贴近于实际值,变化趋势也与真实值更为一致,表明LSTM在处理时间序列问题的效果更好。且针对数据突变,也做出了较为及时的判断变化,表明其较优的响应性能。此外可以看出,NARX由于同样具有记忆功能以及考虑了序列因素问题,在预测效果上次优于LSTM。而BP以及ELMAN不仅预测精度低,且其预测结果是依据一点数据,因此导致曲线噪点多且不平滑。为了使LSTM预测模型具有更好的预测效果以及防止过拟合,加入dropout并使用双隐藏层的网络结构,从图6b中可以看出结构优化后的LSTM预测性能得到了提升。

图6 各模型测试集预测曲线
从误差曲线图7中可以得到,采用的LSTM模型误差随样本序号变化波动幅度最小,而其他模型均在不同位置有着较大波动,证明该LSTM模型具有较强的计算力以及网络稳定性。
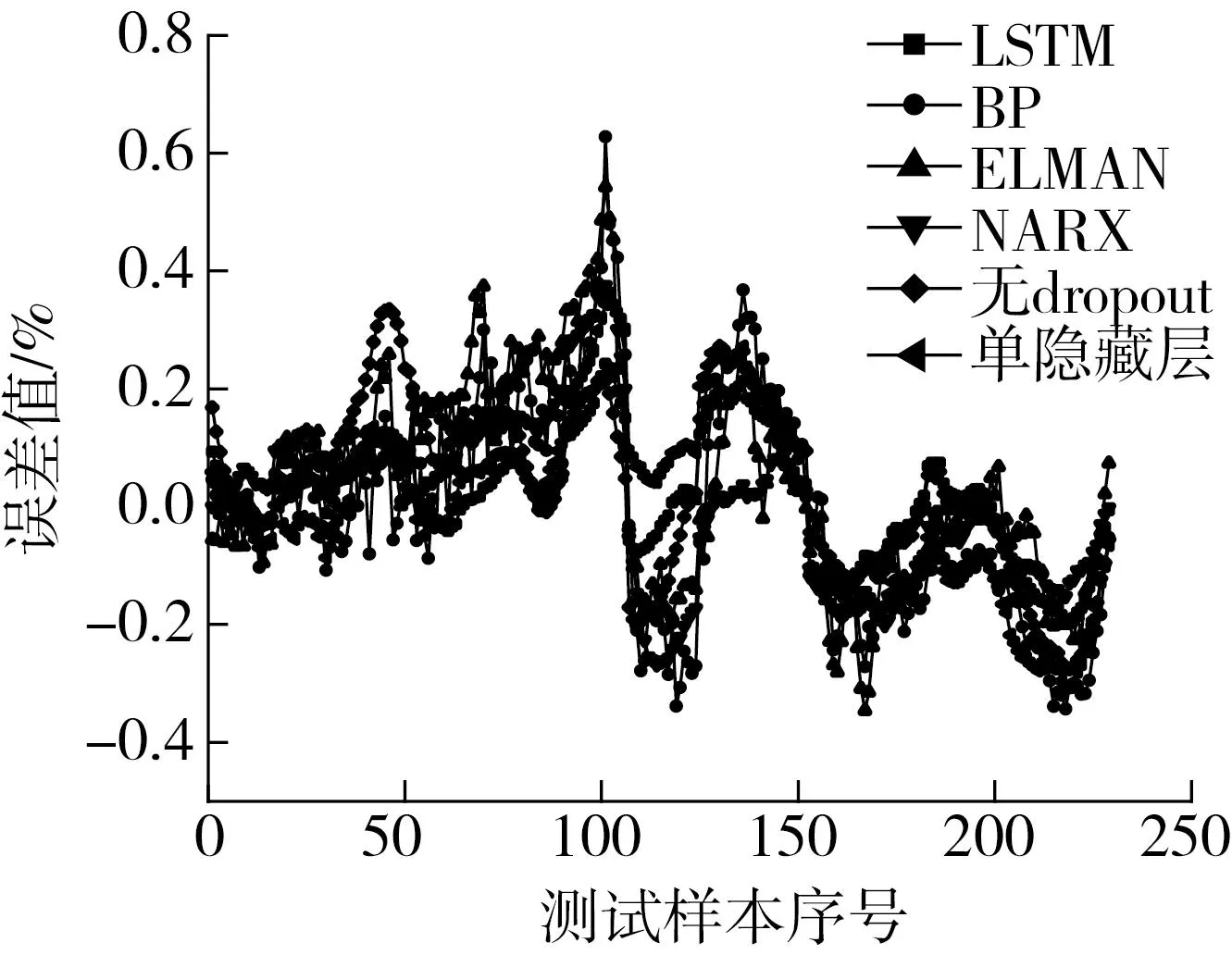
图7 各模型测试集误差曲线
由表6可知,LSTM模型的各项误差均为最低,MAE为0.12%,RMSE为0.20%且拟合度R2最高为0.94。相较于BP、ELMAN和NRAX,R2分别提升了20.51%、16.05%、11.90%,而较一般的LSTM,在优化结构后,相较于无dropout层和单隐藏层也均提升了8.82%、9.20%。这表明,使用该LSTM网络相较于其他模型可以更精确地预测稻谷出机水分,一定程度提高了预测效果。
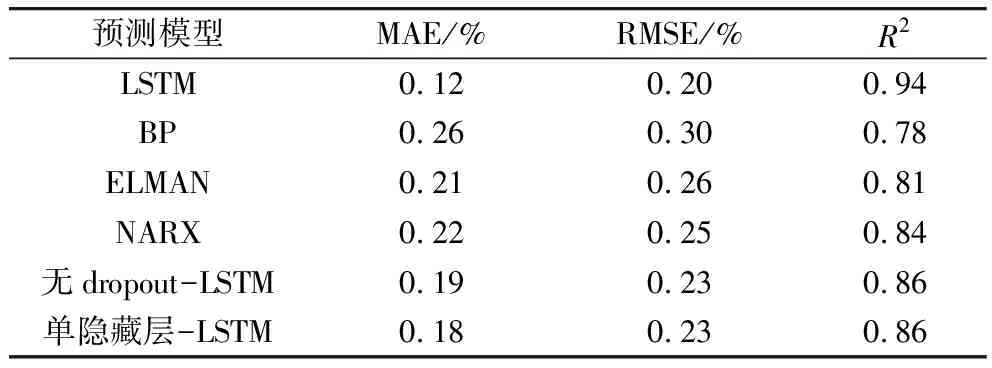
表6 各预测模型性能指标
研究所提出的优化LSTM模型明显优于其他算法模型,且相较于一般结构的LSTM,也有着更好的预测性能。基于LSTM算法,提取长时间序列特征对稻谷出口水分预测时,可以更好地逼近真实结果,模型预测结果平滑且精度和泛化能力更优。
4 结论
通过提取小型连续式谷物干燥机的多项时间序列特征,构建了基于优化LSTM的稻谷出口水分预测模型,分析了所选因素与出机水分相关性以及训练参数、结构参数、数据量对LSTM模型预测效果的影响,发现出机水分Mout与Min、To2、To3、Td1、Td2、Td3相关性显著且越靠近出粮口阶段的因素影响越显著,确立了最优参数设置为批尺寸50,学习率0.001,迭代次数50,时间步长40,神经元个数100×100,且有效增大数据量可以降低模型的过拟合。将优化的LSTM与BP、ELMAN、NARX等算法以及一般LSTM网络(无dropout,单隐藏层)进行对比,通过分析预测效果曲线以及性能评价指标,发现该优化的LSTM网络预测效果最佳,预测结果稳定且泛化性强,模型MAE、RMSE和R2分别为0.12%、0.20%和0.94,证明了该LSTM模型对于连续式干燥机的稻谷出机水分预测具有良好的实用性。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
科教新报(2021年39期)2021-11-04
装备制造技术(2021年1期)2021-05-21
今日农业(2020年15期)2020-12-15
有色冶金设计与研究(2019年2期)2019-05-08
小学生导刊(2017年34期)2017-07-09
新农业(2016年14期)2016-08-16
设备管理与维修(2016年5期)2016-03-16
福建轻纺(2015年3期)2015-11-07
河北科技大学学报(2015年5期)2015-03-11
