
基于混沌云量子蝙蝠CNN-GRU大坝变形智能预报方法研究
2024-01-15 05:56陈以浩李明伟安小刚王宇田徐瑞喆
哈尔滨工程大学学报 2024年1期
陈以浩, 李明伟, 安小刚, 王宇田, 徐瑞喆
(1.交通运输部水运科学研究院, 北京 100088; 2.哈尔滨工程大学 船舶工程学院,黑龙江 哈尔滨 150001)
大坝安全关乎国民经济和人民生命财产安全,大坝变形预报是大坝安全管理的重要组成部分,然而,大坝变形受库水位、材料特性、温度、时效、气候等[1]多种因素耦合影响,变形主控因素变化频繁,内在影响机理错综复杂,导致很难对其做出精确的预报。因此,大坝变形预报一直是被广泛关注的热点问题。
传统预报方法主要包括:时间序列模型、灰色GM模型、回归预测模型和混合模型等[2],传统预报方法因为大坝变形时间序列的高非线性和不确定性,很难满足大坝变形预测精度的要求[3]。随着机器学习和人工智能技术的快速发展,目前极限学习机、支持向量机和人工神经网络等多种机器学习和人工智能算法[4-11]开始被用于大坝变形预报。李明等[12]应用综合自回归移动平均(auto-regressive integrated moving average,ARIMA)模型,构建非平稳时间序列模型对监测数据进行分析处理。罗德河等[13]应用时间序列原理建立变形预报自回归滑动平均(auto-regressive moving average, ARMA)模型研究大坝变形预报。范千等[14]针对大坝变形具有强非线性的特点,基于SVM方法建立大坝变形预报模型。此类方法能较好地解决传统方法难以解决的问题,但以上模型均具有一定的局限性。基于梯度下降法BPNN方法容易陷入局部极值,而导致过早收敛,收敛速度较慢;支持向量机模型的超参选择决定着模型的预报精度,但目前尚未出现统一的支持向量机超参优选方法,因此上述方法的不足限制了其在工程中的大规模应用。
近年来深度学习因其良好的数据挖掘能力已经被尝试用于预报领域,并且取得了优异的效果[9]。沈细中等[15]结合模糊系统和神经网络提出了自适应神经模糊系统预报模型。张豪等[16]结合经验模态分解和SVM来进行大坝变形预报。梁嘉琛等[17]提出了一种结合经验模态分解和自回归滑动平均模型的大坝变形预报模型。为进一步提高大坝变形预报精度,本文针对大坝变形非线性动力系统的强非线性特点,引入CNN和GRU深度学习网络,设计面向大坝变形数据空间特征提取的卷积深度学习网络架构和基于GRU的大坝变形时间序列特征提取深度学习网路,完成构建面向大坝变形预报的CNN-GRU组合深度学习网络;为获取组合深度学习网络超参,引入CCQBA算法对超参进行优选,建立了CNN-GRU-CCQBA大坝变形组合深度学习智能预报方法。基于大坝实测变形数据开展预报试验研究,测试建立方法的可行性和优越性。
1 CNN-GRU-CCQBA大坝变形组合深度学习预报方法提出
1.1 基于CNN的大坝变形数据特征提取
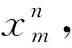
(1)
式中的“*”号实质是让卷积核f在第n-1层所有关联的特征图上做卷积运算,然后求和,再加上一个偏置参数,并取激活函数得到最终激励值的过程:
卷积前与卷积后的特征图尺寸对应关系为:
Wb=(Wf-F+2Z)/S+1
(2)
Hb=(Hf-F+2Z)/S+1
(3)
式中:W为宽度;H为高度;下标b表示后方,下标f表示前方;F为滤波器的尺寸;S为卷积步长;Z为零填充的圈数。
CNN的误差反向传播分为卷积层和池化层2种不同的情况,卷积层见式(4)。
(4)
由于池化层没有权重参数,因此,误差项只需要向前传播即可,对于最大池化,下一层的误差项的值会自动传递到上一层对应区块中的最大值所对应的神经元,而其他神经元的误差项的值都是0,对于平均池化,下一层的误差项的值会平均分配到上一层对应区块中的所有神经元。因此,只需要由输出层开始计算误差项,按层反向计算,即可完成CNN的权重参数更新。
1.2 基于GRU的大坝变形数据特征提取
影响大坝变形的温度、水压力、时效分量等因素各自呈现出一定的周期性变化,一般来说,各个影响分量的周期是不规则变化的、变周期的,难以具体去描述,这也造成了其周期特征人工表示的困难。考虑到这种情况,本文利用RNN深度学习网络来自动提取大坝变形非线性动力系统的时间特征。经过CNN卷积和池化操作处理的序列变成了高维张量,在输入到RNN之前,将其进行展平操作,变成一维序列。一维序列经过GRU循环处理,最终输出为多个时刻不同的特征张量。
常用的RNN有LSTM和GRU 2种。考虑到GRU在处理序列建模问题时,在网络内部引入重置门和更新门,效果优于传统RNN,当使用固定数量参数时,在CPU时间的收敛性以及参数更新和泛化方面,GRU要胜过LSTM[19],为此,本文选用GRU网络挖掘大坝变形非线性动力系统的时间特征。此时,GRU控制门以及状态计算为:
zt=φ(Wz·xt+Uz·ht-1)
(5)
rt=φ(Wr·xt+Ur·ht-1)
(6)
(7)
(8)

GRU的训练算法是沿时间反向传播算法(back-propagation through time, BPTT)。GRU的误差项与DNN和CNN有所不同,定义为损失函数对隐藏输出的偏导数,即如式(9)所示。误差项沿时间的反向传播如式(10)和(11)推导所示。
(9)
(10)
(11)
1.3 CNN-GRU大坝变形深度组合预报网络建立
基于CNN和GRU的大坝变形深度组合预报网络由3个部分组成:1)CNN网络的空间特征提取层,包括CNN输入层、CNN卷积层、CNN池化层;2)GRU网络的时间特征提取层,包括GRU输入层、GRU隐藏层和GRU输出层;3)在GRU输出层后设置一个全连接层,映射为大坝变形值。在学习过程中,首先,对大坝变形多因素变量组成的二维矩阵进行数据的初步处理,将处理后数据作为CNN的输入层,经过卷积操作后完成特征提取,获取多个特征图。将特征图利用最大池化进行采样,实现其维度的自动压缩,获取一个二维张量,然后将这个二维张量进行重塑操作,即将二维向量展开为一维向量,使其符合GRU学习网路的输出格式,完成大坝变形非线性动力系统的空间特征提取。然后,将新构造的大坝变形特征向量作为GRU层的输入,由GRU的隐藏层完成循环和门控计算,实现大坝变形非线性动力系统的时间特征提取。深度组合预报网络架构如图1所示。
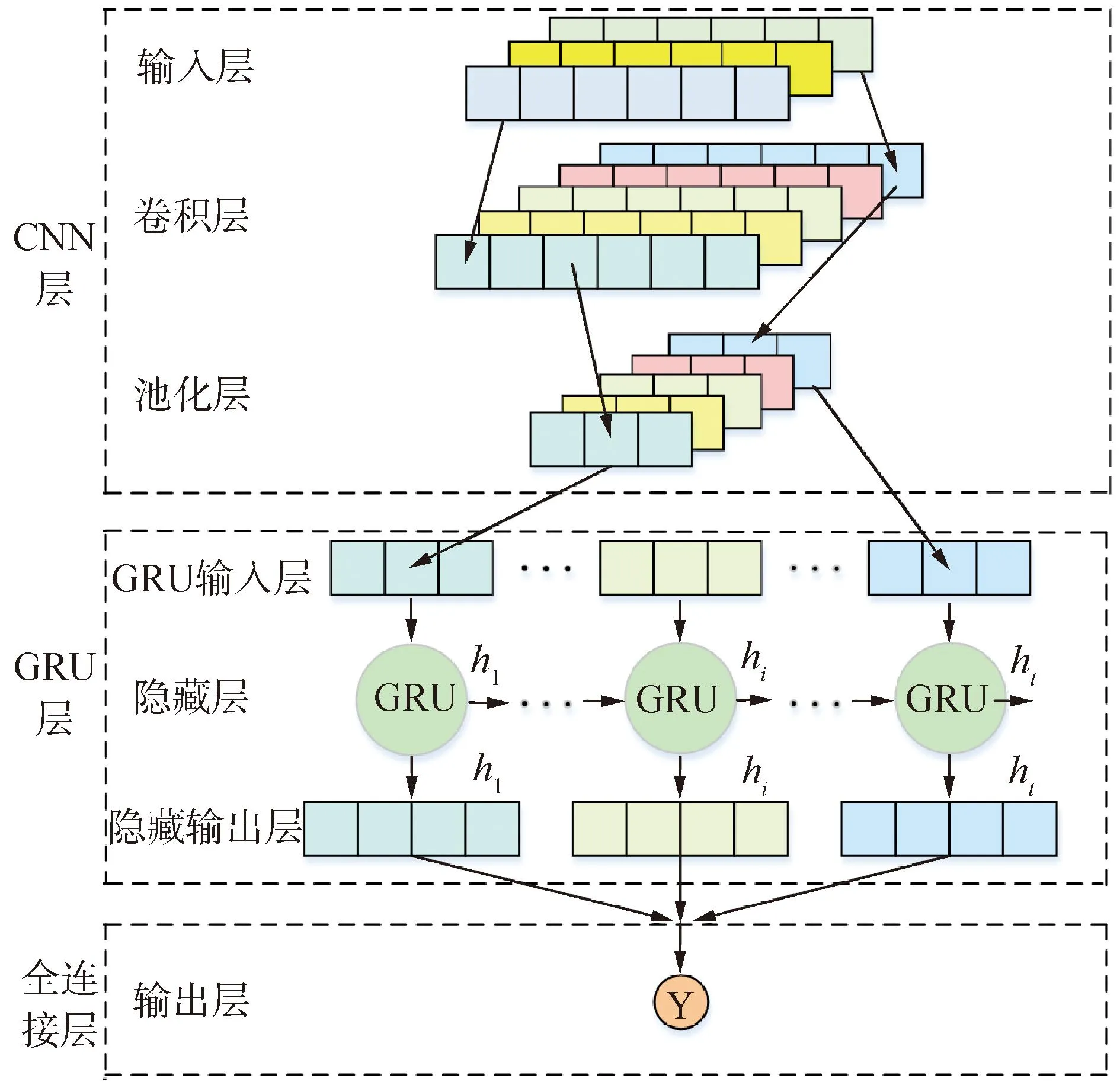
图1 CNN-GRU大坝变形组合学习网络架构Fig.1 CNN-GRU dam deformation combination learning network architecture
1.4 基于CCQBA的预报网络超参优选方法
深度学习模型的参数分为2种,层与层之间的连接权重参数和模型的超参。一般来说,权重参数的调节可以通过深度学习框架来设置某种权重参数优化算法,本文设置的为反向传播算法。而模型的超参数则需要人为去设定,并通过不断地尝试修改,最终选择合理的超参。人工调参不仅需要大量的实践经验,而且耗费的时间也较长。为此,本文采用智能优化算法替代人工调参,实现超参数自动优选。
蝙蝠算法(bat algorithm, BA)具有收敛速度快,结构简单,搜索能力强等特点,是广大学者研究的重点算法之一。针对BA的不足,本文基于量子理论、混沌理论和云模型提出了混沌云量子蝙蝠算法(chaotic cloud quantum bat algorithm, CCQBA)[20],及经典测试函数开展优化试验,效果良好,为此本文尝试将其应用于CNN-GRU大坝变形深度组合预报网络的超参优选,以进一步提高预报精度。
CCQBA算法的优化过程如下:种群内每一个个体为CNN-GRU的超参组合,对CCQBA进行编码;种群位置、频率和响度初始化后,采用量子蝙蝠算法进行位置更新。经过一定的迭代次数,将每个个体当前的最优位置视为一个新种群,并根据适应度对新种群进行排序。将新种群分为2部分,具有较好适应度值的部分继续在云模型中进行局部搜索,以加快搜索速度;具有较差适应度值的部分进行混沌全局扰动,以增加种群多样性。CCQBA算法的实现过程如下,具体信息请参考文献[20]。
1)基本参数设置。设置蝙蝠种群的大小(n)、迭代循环的最大数目(gen)、频率范围([fmin,fmax])、扰动尺度因子(dissca)、混合执行参数(mixexe)、聚合参数(σ)、停止条件(tol)。

4)迭代代数初始化。令t=1,tt=1。

6)更新迭代循环。更新t=t+1,tt=tt+1。
7)计算新精英种群的适应度值。Iftt≤mixexe×n,则转到步骤5);否则,使用每个个体当前的最佳位置生成一个新的种群,该种群使用个体的适应值进行排序。新种群分为2部分:一部分由较好个体组成,大小为(1-dissca)×n,另一部分由较差个体组成,大小为dissca×n。通过局部云搜索在较小范围内搜索较好的个体,以产生新的优秀个体。对较差个体施加全局扰动,且在这种新的扰动后会得到优秀个体。形成精英种群的规模为n,从而可以计算每个个体的适应度值。
8)计算新精英种群的适应度值。令tt=1;然后,返回步骤5)。
CCQBA流程图如图2所示。
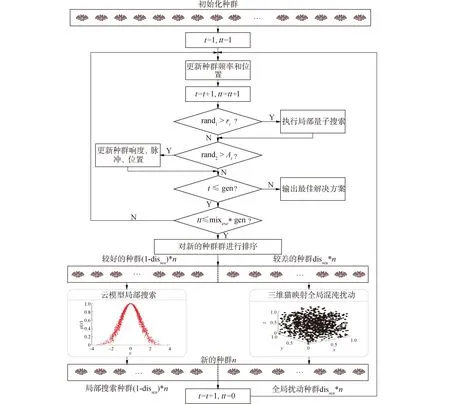
图2 CCQBA优化流程Fig.2 CCQBA optimization flowchart
1.5 CNN-GRU-CCQBA大坝变形集成预报方法建立
随着CNN-GRU组合深度学习网络的不断训练,网络损失会不断降低,但是仅仅能说明获得网络不断逼近所用的训练数据,不能说明在其他时刻数据也表现良好。因此,将训练数据对应的回归误差值作为CCQBA的适应度函数显然不充分。为此,本文将试验数据集分为训练数据集、检验数据集和测试数据集3部分。训练数据集用于CNN-GRU组合深度学习网络训练,训练完成后,计算检验数据集的回归误差,为了提高优化得到组合深度学习网络的泛化性能,将训练数据集回归误差和检验数据集回归误差之和作为CCQBA的适应度函数值,用于CNN-GRU组合深度学习网络优化。CNN-GRU-CCQBA集成预报流程设计如下,流程图如图3所示。
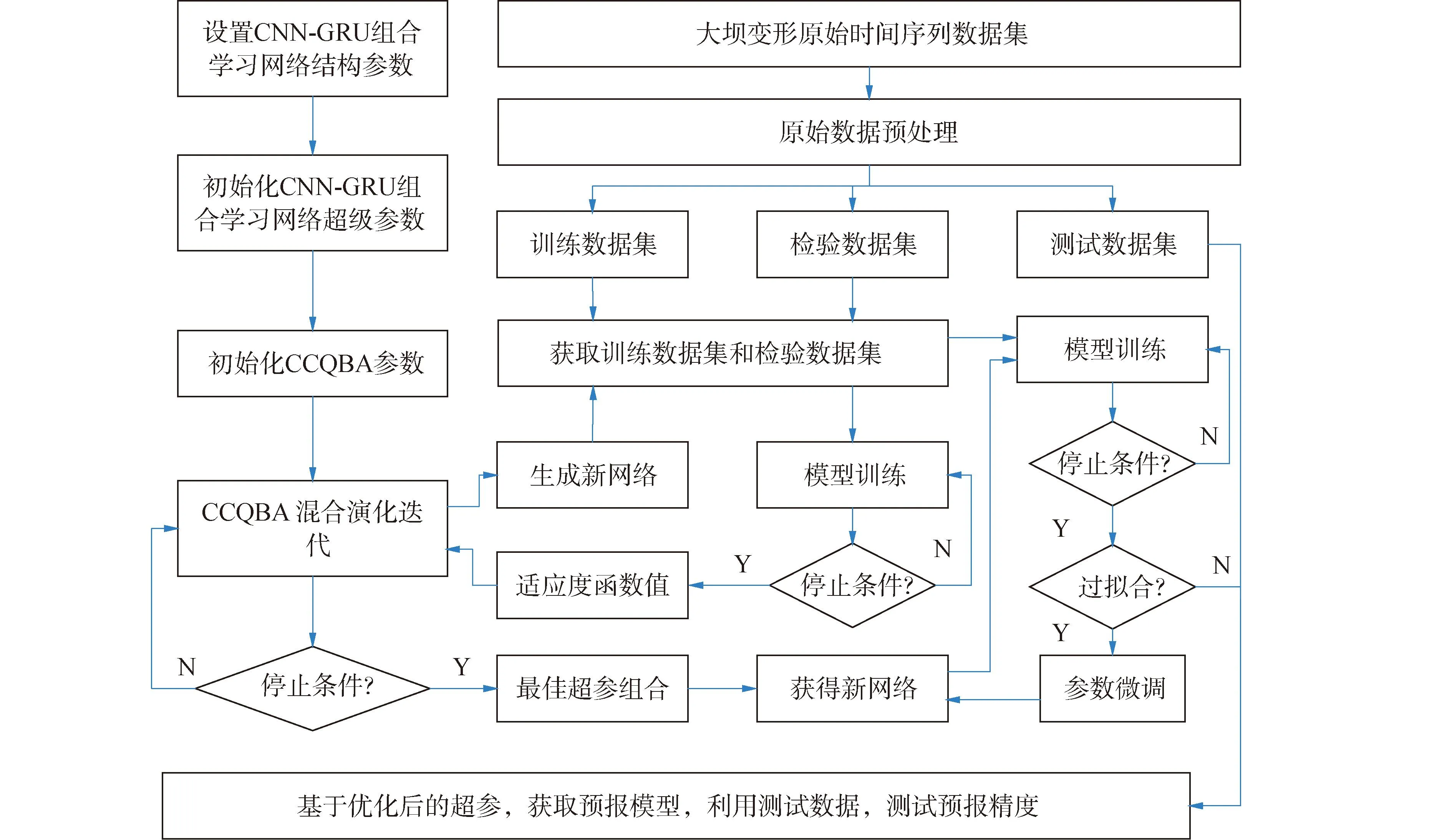
图3 CNN-GRU-CCQBA大坝变形预报方法流程Fig.3 Flow chart of CNN-GRU-CCQBA dam deformation prediction method
1)数据预处理。大坝变形时间序列以及影响因素序列经过数据归一化,使其值域变为[0,1]。然后处理其格式,使其满足CNN-GRU-CCQBA的训练要求。
2)模型结构及参数初始化。初始化CNN-GRU组合学习网络的输入维度、卷积核数量、卷积核尺寸、池化尺寸、GRU隐藏节点数等网络超级参数;设置CNN-GRU组合学习网络的卷积层数、池化层数、卷积与循环结合方式和激活函数等网络结构参数;根据算法参数上下限,初始化CCQBA各参数的上下限。
3)内置模型训练。将1)训练数据输入到CNN-GRU模型中获得模型输出;根据模型的输出值和标签值计算每层网络的误差项;按照梯度更新公式,对每层的权重梯度进行更新。判断是否达到训练轮数,若没有达到,则重复上述网络训练流程,反之则停止训练,跳转到5)。
4)CCQBA演化迭代。根据3)中训练完成的CNN-GRU组合学习网络,将1)中的训练数据集和验证数据集分别代入到新网络中,获得网络在训练数据和验证数据上的损失函数值,将两者加和作为适应度值反馈给CCQBA算法,进行演化迭代。
5)最优超参数训练与验证。将所得的最优超参赋值给新的CNN-GRU组合学习网络,基于训练数据进行训练,基于验证数据对其进行验证。当其满足训练轮数时,判断是否存在过拟合(训练集预测误差很小,测试集预测误差较大)或欠拟合(训练集与测试集预测误差均较大)现象。若存在,则对模型进行微调并重复5);若不存在,则获得优化后的深度组合学习网络。
6)模型精度测试。使用测试数据对5)中所得到的模型进行预报实验,测试预报精度,获取预报模型。
2 实例分析
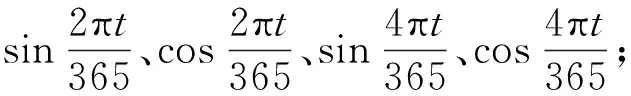
(12)
式中:Di为第i个数据归一化后的结果;di为时间序列中的第i个数据;dmax为时间序列中的最大值;dmin为时间序列中的最小值。
2.1 对比模型及算法选取
1)对比模型选取。
为了对比分析本文建立的预报模型的预报性能,选用ANN、CNN、GRU、CNN-GRU 4种预报网络分别开展预报试验。为了确保超参优选可比性,利用CCQBA算法分别优化上述4类网络的超参,其中,优化变量包括:输入维度、卷积核数量、卷积核尺寸、池化尺寸和GRU的隐藏节点数。利用ANN-CCQBA、CNN-CCQBA、GRU-CCQBA和CNN-GRU-CCQBA 4种预报方法分别开展预报试验。经优化获得上述4种预报模型参数如表1所示。

表1 对比模型超参数设置Table 1 Compare model superparameter settings
2)对比算法选取。
为了测试CCQBA算法在优选CNN-GRU大坝变形深度组合预报网络超参过程中的性能,本文选取随机搜索(RS)、网格搜索(GS)、蝙蝠算法(BA)、量子蝙蝠算法(QBA)和CCQBA 5种算法开展超参优选对比试验。基于试验样本数据,经试算确定上述5种算法的参数设置如表2所示。

表2 对比算法参数设置Table 2 Comparison algorithm parameter setting
2.2 预报精度评估指标
本文选取均方根误差(root mean square error,RMSE)和平均绝对百分比误差(mean absolute percentage errors,MAPE)作为预报精度评估指标,计算公式为:
(13)
(14)

2.3 预报表现及算法优化性能分析
1)模型预报表现分析。
在进行深度学习之初,其权重参数通常是随机生成的较小实数,在具体的训练过程中,随机梯度下降算法不断迭代至合适值,但是即使对应于相同的回归结果,其权重也极有可能不同,再具体测试过程中很可能产生不同的结果。因此,为了减弱波动性对预报性能测试的影响,所以,在相同的超参数设置下,独立的进行了20次预报实验,并将这20次结果取平均,作为模型的最终预报结果。基于CCQBA算法确定的模型超参,依次完成了ANN、CNN、GRU、CNN-GRU 4种网络的预报实验,预报结果与真实值对比见图4,预报精度评估值见表3。

表3 预报模型的精度评估表Table 3 Accuracy evaluation table of prediction model
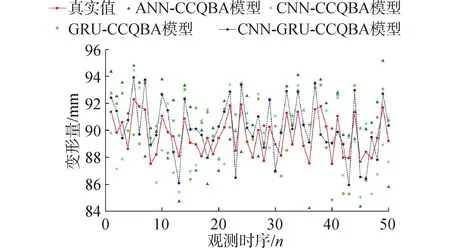
图4 预报模型结果对比Fig.4 Comparison chart of prediction model results
从表3可以看出,单独使用CNN和GRU深度学习网络对大坝变形进行预报时,其EMAP精度指标分别达到了2.207 9%和2.133 3%,而在ERMS指标上,分别达到了2.043 3和1.975 1,与ANN模型的2.689 4%和2.486 7相比有了明显改善,但CNN和GRU模型之间相差不大。当使用CNN-GRU组合预报网路进行大坝变形预报时,预报精度评估指标EMAP和ERMS分别为1.649 0%和1.524 6,其取值明显小于CNN和GRU单独预报网络。这表明针对大坝变形非线性动力系统演化特点,基于CNN模型深度挖掘序列空间特征和基于GRU模型深度挖掘序列时间特征,有效提升了CNN-GRU组合预报网络对大坝变形非线性动力系统的模拟精度,进而获得了更精确预报结果。由此可见,根据大坝变形非线性动力系统特点,通过对CNN和GRU深度学习网络的优化组合实现大坝变形预测,对于提升大坝变形预报精度的尝试是可行的。
2)算法优化性能分析。
考虑到群智能优化算法的随机性,分别使用RS、GS、BA、QBA和CCQBA 5种算法对CNN-GRU模型优化20次,取20次4种算法每一代的适应度值的平均值绘制进化曲线,4种算法在优化CNN-GRU组合网络超参过程中的进化曲线如图5所示。
从图5不难看出,在对CNN-GRU组合网络超参进行优选时,GS和RS算法前期的收敛速度较慢,而BA算法前期的收敛速度快。这主要是因为GS和RS算法是一种随机搜索算法,随机性较强。而对于深度学习网络,不同的参数对预报精度的影响程度是不同的,当某个重要超参数收敛在一个小范围内时,网络的精度可能会相对较高,如果在此时使用的是随机搜索,很容易直接跳出这个局部而错过较优参数,而BA算法是启发式搜索算法,它们在搜索的过程中会根据固定的规则去执行全局搜索或是局部搜索,因此更加适合深度学习网络的超参数优选。因此导致BA算法收敛速度大于GS和RS算法。
对比BA算法和QBA算法,不难发现,在进化初期,因为量子计算的引入,增加了每代计算耗时,所以降低了收敛速度,但是也正式量子计算的引入,使得种群当陷入边界局部最优时,种群会自动跳离边界,从而跳出局部最优位置,避免了陷入局部最优,持续搜索到更优解。与QBA相比,CCQBA通过基于混沌映射的全局扰动和基于云模型的局部加速,获得了更优秀的进化曲线,混沌扰动使算法在进化后期能够不断跳出局部极值,解决了进化后期易陷入局部最优的难题,云模型在进化后期能够加速最优解局部搜索,进而提升收敛速度。同时,从CCQBA迭代曲线可以发现,该算法前50次迭代收敛速度较快,因此,模型若在前50代停止训练,将降低CNN-GRU超参组合的优化结果;而在50~200次迭代,因收敛已趋于平稳,所以模型训练停止条件对优化结果影响不大。
因此,基于CCQBA进行CNN-GRU大坝变形深度组合预报网络超参优选用于提高预报精度的尝试是可行的。
3 结论
1)本文从大坝变形非线性动力系统时间序列的强非线性出发,提出了一种基于CNN网络、GRU网络和CCQBA算法的CNN-GRU-CCQBA大坝变形组合深度学习智能预报方法。
2)与ANN、CNN和GRU模型对比,CNN-GRU网络模型显著降低了预测误差,极大地提升了预测精度。
3)与RS、GS、BA和QBA算法对比,CCQBA算法具有更好的收敛性能,能够为CNN-GRU模型提供更优质的超参组合。
4)实际应用结果表明,本文方法有效预测了大坝变形趋势,且与监测数据具有较好的拟合性,能够为大坝变形的精准预报提供了新的方法参考。
5)模型精度提高势必会导致模型复杂度增加,优化时间会有所提高,可进一步开展基于并行计算方法开展大坝预测模型加速训练优化方法研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
百科知识(2018年6期)2018-04-03
电视技术(2014年19期)2014-03-11
中国三峡(2013年11期)2013-11-21
