
无回答与计量误差叠加时总体方差的校准估计
2024-05-04 11:38庞智强牛玺娟王朝旭
统计与决策 2024年7期
庞智强,牛玺娟,,王朝旭
(1.兰州财经大学统计与数据科学学院,兰州 730020;2.青海师范大学数学与统计学院,西宁 810008)
0 引言
在抽样理论中,研究者要处理两种类型的调查误差:抽样误差和非抽样误差。其中,抽样误差是由抽样的随机性引起的误差,非抽样误差是除抽样以外的其他原因引起的误差。在经典的抽样理论中,研究的估计误差主要是抽样误差,对非抽样误差研究较少。在估计总体未知参数时,非抽样误差在一定程度上比抽样误差更容易影响估计量的性质。
在抽样调查中,通常假设所有选定的单位都将全部参与调查,并且所有记录的结果都是对变量的真实测量。然而,由于客观条件的限制,难以完全避免非抽样误差的出现,使得调查得到的数据并不完整,从而会导致出现严重的错误推断。总体方差估计作为统计推断中非常重要的研究内容,同样存在上述困扰。因此,有必要开发能够最大限度应对非抽样误差影响的总体方差估计方法。
无回答误差和计量误差作为两种重要的非抽样误差,对总体方差的估计结果会产生至关重要的影响。无回答误差是估计研究变量总体方差过程中面临的重大挑战之一。Hansen 和Hurwitz(1946)[1]考虑了存在无回答误差时有限总体均值的估计问题;Chaudhuri 和Pal(2015)[2]提出了不同总体参数的估计量;Ahmeda 和Pal(2005)[3]探究了简单随机抽样下存在随机无回答时总体方差的估计问题;Singh等(2012)[4]针对两种不同的随机无回答,提出了总体方差的估计量;牛成英和庞志强(2014)[5]运用概率分析方法讨论了无回答对总体参数估计量抽样方差的影响。
除了无回答之外,估计总体方差时遇到的另一大挑战是计量误差。Singh 和Karpe(2009)[6]讨论了计量误差影响下总体方差的估计问题。在实际调查中,研究人员经常面临一些调查单元既存在无回答又有计量误差的情况。Tiwari等(2023)[7]讨论了无回答和计量误差叠加时有限总体均值的估计问题。
辅助变量在抽样调查中起着关键作用,恰当使用辅助信息能有效提高总体参数估计的准确性。使用辅助变量估计方差的技术最早由Das(1978)[8]提出,他重点讨论了已知辅助变量变异系数情况下的方差估计。随后Isaki(1983)[9]又将这一技术进行推广,探讨了当研究变量和辅助变量线性相关时总体方差的比率估计问题。当辅助信息可用时,总体参数的校准估计方法也被广泛应用于抽样调查。自Deville 和Sarndal(1992)[10]首次提出校准估计方法以来,该方法已成为统计学研究的一个重要课题。Tracy 等(2003)[11]、Singh 等(2020)[12]利用校准估计,提出了不同抽样设计下总体参数的校准估计量。Plikusas 和Pumputis(2007)[13]将校准估计的思想应用到总体协方差估计中,得到了不同约束条件下总体协方差的校准估计量。
本文考虑了无回答和计量误差叠加存在时有限总体方差的估计,并基于校准估计方法提出了分层随机抽样中方差的校准估计策略。在数值分析方面,从模拟和真实数据两个方面对所提校准估计量的性能进行了检验。
1 抽样基础理论
1.1 抽样框架
考虑一个容量为N的有限总体U,U={U1,U2,…,UN},现按照一定的标准对总体U进行分层,将其划分为L个互不相交的层,使得,h=1,2,…,L。设Y为研究变量,X、Rx分别为第一、第二辅助变量,其中,Rx为辅助变量X的秩。
本文采用无放回简单随机抽样方法(SRSWOR),抽样分两个阶段进行。第一阶段:先从第h层的总体Nh中抽取容量为nh的简单随机样本,且各层间的抽样均相互独立;再将每层得到的样本组合为一个新样本,称该样本为初始样本,记为Snh,h=1,2,…,L。设在第一阶段的nh个样本中,共有r1h个单元发生无回答。第二阶段:从初始样本Snh提供回答的部分中进行抽样,同样利用SRSWOR方法抽取一个容量为mh的样本,记为Smh。设在第二阶段的mh个样本中,共有r2h个单元发生无回答。
1.2 符号说明
本文中所用到的一些符号及其含义如下:
:研究变量Y对应的总体方差。
:第h层的校准权重,h=1,2,…,L。
Qh:第h层的独立权重,h=1,2,…,L。
1.3 随机无回答的概率分布
考虑第h层的情况:在第一阶段容量为nh的初始样本Snh中,设r1h表示由于随机无回答而无法获得信息的抽样单元数,则r1h可能的取值为0,1,2,…,nh-2。同理,设r2h为第二阶段容量为mh的样本Smh中发生无回答的抽样单元数,则r2h可能的取值为0,1,2,…,mh-2,且0 ≤r1h≤nh-2,0 ≤r2h≤mh-1。假设p1和p2分别表示nh-2 和mh-2 个可能值中发生无回答的概率,则r1h和r2h均为离散型随机变量,他们服从如下概率分布[3]:
其中,q1=1-p1,q2=1-p2。
2 校准估计量的构建
在本文中,假设无回答和计量误差仅存在于研究变量Y和辅助变量X之间,而不存在于研究变量Y和辅助变量的秩Rx之间。Singh等(2020)[12]给出了分层随机抽样设计下有限总体方差的校准估计方法,其校准估计量的一般形式如下:
基于上述讨论,本文提出了一种改进的校准估计量:
其中,是在新校准约束条件下最小化卡方距离得到的校准权重。
考虑各层估计量的一个复合类Th,
使得对函数g,成立。
2.1 校准估计方法
在分层随机抽样中,校准估计方法主要用于获得最优层权。为了得到合理的校准权重,要保证校准权重与原始权重Wh尽可能地接近。因此,需要建立校准权重与原始权重Wh之间的距离函数关系,一般选择比较简单的卡方距离作为两个权重之间的距离函数。在校准估计中,最小化距离函数即为最优化目标函数,拉格朗日乘数法是经常被用来求解最优化问题的一种方法。即要使卡方距离在校准约束条件下达到最小值。
本文用拉格朗日乘数法求解,结合卡方距离函数和校准约束条件,构造最优化问题的拉格朗日函数如下:
其中,λ1,λ2,λ3为拉格朗日乘子。
对式(3)两边关于求偏导,得:
将式(5)中的解代入校准约束条件中,根据等式关系可计算得到对应的拉格朗日乘子值为:
其中,det=aeh-af2-b2h+2bcf-c2e,det1=deh-df2-bgh+bif+cgf-cie,det2=agh-aif-bdh+cdf+bci-c2g,det3=aei-agf-b2i+bcg+bdf-cde。
常数a,b,c,d,e,f,g,h,i定义如下:
将计算得到的拉格朗日乘子值λ1,λ2,λ3代入式(5)中,便可得到最终的校准权重的值。
2.2 估计量的偏差和均方误差
为了得到校准估计量Tst(P)的偏差及其均方误差MSE 的表达式,作如下变换:
其中,d1h,d2h,d3h,d4h为函数在点处的一阶偏导数;同理,d11h,d22h,d33h,d44h,d12h,d13h,d14h,d23h,d24h,d34h为函数在点处的二阶偏导数。
为计算方便,此处附加一个约束条件:
现将式(7)至式(9)代入式(6),并用相对误差eih,i=0,1,2,3 的形式表示式(6),可得:
将式(10)代入式(3),则校准估计量Tst(P)可写为:
对式(11)作简单变换,然后两边同时取期望,得到校准估计量Tst(P)的偏差为:
进一步,得到一阶近似下校准估计量Tst(P)的MSE,其表达式如下:
对式(13)分别关于d2h,d4h求偏导,并令其偏导数等于0,得到d2h,d4h的最优解:
将式(14)代入式(13)中,得到Tst(P)最小的MSE:
令(xhi,yhi)和(Xhi,Yhi)分别为二元变量(X,Y)在第h层第i个单元对应的观测值和真实值,则研究变量Y与辅助变量X的计量误差分别为Uhi=yhi-Yhi与Vhi=xhi-Xhi,且计量误差Uhi与Vhi之间不相关。令、分别为研究变量Y、辅助变量X对应的计量误差的总体方差,可以得到当计量误差存在时估计量Tst(P)最小的MSE:
3 数值分析
本文从模拟数据和真实数据两个方面对所提校准估计量Tst(P)与现有校准估计量Tst(S)的性能进行比较。
3.1 模拟研究
在统计软件R 中进行模拟研究,对估计量的估计效果进行对比分析。将校准权重Ωh代入式(1),通过计算分别得到不存在和存在计量误差两种情形下估计量Tst(S)最小的MSE:
本文使用估计量的百分比相对效率(PRE)作为估计量的评价指标:
模拟数据中的总体参数说明见表1。为了使模拟过程顺利实施,本文采用了Singh 软件包中MASS 中的函数mvrnorm 生成服从正态分布的数据[12]。对于不同的控制参数Qh,在R 中进行1000 次循环,控制参数Qh的取值有六种情形。情形1:Qh=1.0。情形2:情形3:Qh=。情形4:Qh=。情形5:Qh=。情形6:Qh=。
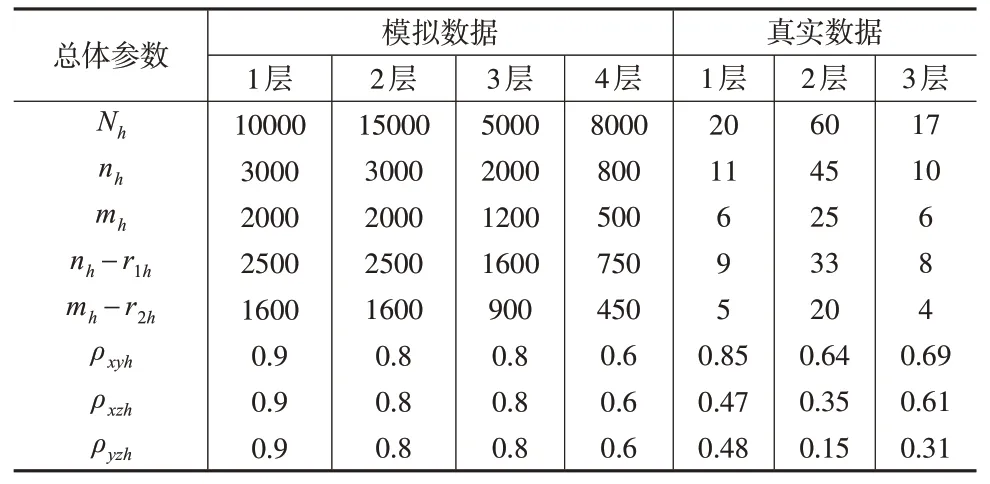
表1 总体参数说明
对于随机无回答的概率p1和p2,令他们分别取0.05、0.10、0.15 和0.20 四个值。下页表2 和表3 分别给出了校准前后的权重和PRE的模拟结果。

表2 模拟数据下校准前后权重对比

表3 模拟数据下的PRE结果
3.2 真实数据的应用
为研究校准估计量的实际应用性能,考虑一个真实数据集。为了尽可能准确地估计总体方差,本文有意考虑研究变量中某些数据的缺失,真实数据的总体参数情况仍然在表1中给出。
用于数值研究的总体来源于文献[14]。数据可在R软件的faraway软件包中的prostate文件中获得。
根据控制参数Qh,分别在不存在计量误差和存在计量误差两种情况下取不同值,真实数据在校准前后的权重和PRE分别在表4和下页表5中给出。
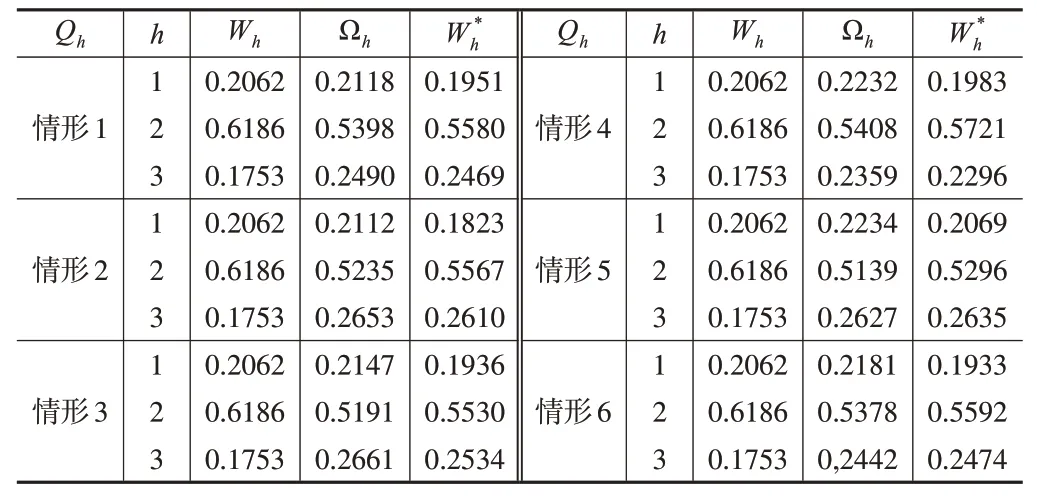
表4 真实数据下校准前后权重对比
综合表2至表5的结果,可以看出:
(1)从表2和表4可以看出,使用校准方法得到的权重与原始权重非常接近。这表明校准技术可以有效地优化权重,提高校准估计量的估计精度。此外,从表3 和表5可以看出,对于每个控制参数Qh,本文提出的校准估计量Tst(P)总是比Singh的校准估计量Tst(S)更有效。且对于无回答的概率p1,p2而言,当p1,p2∈(0.05,0.10) 时,校准估计量最有效。
(2)无论是模拟数据还是真实数据,存在计量误差的PRE都小于不存在计量误差的PRE。从表5还可以看出,在分层随机抽样下,无论Qh取何值,本文所提校准估计量Tst(P)在存在计量误差和不存在计量误差两种情况下,都优于现有校准估计量Tst(S)。
4 结束语
本文关注的是无回答和计量误差叠加存在时分层随机抽样中有限总体方差的估计问题。通过模拟分析和实际数据的应用研究可以发现,本文所提出的校准估计量Tst(P)在最小化非抽样误差的负面影响方面总是比现有校准估计量Tst(S)更有效。
在非抽样误差和总体方差估计方面,还存在一些重要的问题值得考虑:(1)本文仅考虑了分层随机抽样中无回答和计量误差同时存在时有限总体方差的估计,除分层随机抽样外,还可以考虑更多的抽样设计。(2)受模拟结果的启发,同时也考虑到处理非抽样误差问题的重要性,可以鼓励统计调查人员适当使用本文提出的校准估计量,将其应用于社会经济调查中。例如:估计社会不同阶层在节假日的开支变化,估计全国不同地区妇女的收入变化,等等。
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-05-25
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2020年23期)2020-12-15
中国外汇(2019年6期)2019-07-13
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
初中生世界·九年级(2017年10期)2017-11-08
中学生数理化·高一版(2017年2期)2017-04-25
现代营销·学苑版(2016年12期)2017-01-23
电测与仪表(2015年6期)2015-04-09
