
数据和知识挖掘技术的图书馆服务策略分析*
2014-04-02 07:09张艳
技术与创新管理 2014年4期
张 艳
(陕西省考古研究院,陕西西安710054)
1 引言
图书馆作为信息集散地与知识传播的主要渠道,其核心价值集中体现在服务质量的优劣及效率的高低。目前,随着信息化程度的加深,图书馆传播信息、分享知识的环境发生了巨大的变化,如信息渠道增多、信息量几何倍数增长,读者需求层次趋于多样化,查找信息的速度要求更快等。显然,传统的数据统计分析和查询检索机制,已不能满足读者日益增长的需求。因此,图书馆迫切需要建立一个现代的资料管理与用户信息分析系统,帮助管理者进行科学决策,以提升图书馆的服务质量。
基于基础数据知识和信息挖掘,是一种“从现存的大量的、不完全的、模糊的、随机的实际应用数据中,抽取或识别出隐含的、未知的、但又确实存在的信息,帮助决策者和管理者寻找数据潜在的关联,发现对决策者有价值的关系和模式,用于预测未来的趋势及决策行为”的思想方法与技术体系。因其所获信息一般具有先前未知、有效和实用的特征,现已广泛地应用于电信、电子商务及市场管理等领域。
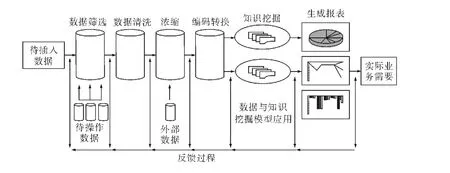
图1 数据与知识挖掘的处理过程
数据挖掘技术可以简单而有效的分析集中数据。对图书馆而言,首要的目的是利用它从模糊的数据中,获得对读者有用的知识,对管理者决策有用的信息,如发掘用户的兴趣,为个性化服务提供数据支持;评估和预测馆藏资源的建设,为采购项目的种类和数量提供有力地决策依据,从而提高图书馆和用户之间的互动质量。
2 数据与知识挖掘的一般过程
正确地使用数据挖掘,首先就得了解其一般的运作过程及相应的数据分析方法与技术。为了直观地显示数据挖掘应用的一般过程,我们基于对其功能与分析方法,构建了一个基于知识与数据挖掘的决策流程示意图(如图1)。
如图1所示,知识挖掘的一般过程可以描述为相对独立又相互关联的六个步骤。
第一步,数据的选取。这是整个过程中最为重要的环节。数据选取应紧紧围绕关注的问题和预期目标展开。如想了解读者的需求、使用模式及最优的馆藏资源配置,指导图书馆的建设,就要选择与其相关的读者借阅情况、书籍流通情况等数据。这些数据可以容易地从图书馆的基础数据找到。
第二步,数据的清洗。通过建立挖掘数据库,对选取的数据进行进一步甄别,剔除孤立的、不完整的和不具有任何含义的数据(如因操作员错误产生的不完整的数据等),以免导致挖掘过程错误的发生。
第三步,数据的浓缩。前一步进行的同时,利用图书馆以外的数据(如调查问卷等资源所得的数据),进一步补充、丰富数据库内容,以弥补现有数据的不足,使知识挖掘过程更加高效,并产生更好的效果。
第四步,数据的编码和转化。挖掘数据建立完善后,要将对不同的来源与格式的数据转换成数据挖掘算法的可用形式,以使所有的数据都适应计算机的处理要求(例如更改出生日期年龄,由“是/否”改为“1/0”,改变男/女到 M/F)。
第五步,知识挖掘的执行。选择一种有效的知识挖掘算法与模型,对数据进行分析,得出对决策有用的信息。分析内容主要包括:①实体之间的关联规则,如30%的学生没有在规定的时间归还借出的图书等;②分类信息,如读者群的分类、借阅图书的主题的分类;③倾向与分歧分析,如用户借阅资料兴趣偏好、或某类材料读者群倾向;④途径信息分析,如图书馆的网站上访问的最流行的路径。
第六步,报表的生成。结果的有效性某种程度上取决于其表现形式。数据挖掘的结果一般应采取图形图像、计划、图表等直观的形式来展现,以清楚地显示数据之间的相关性。因为其目的在于帮助观察者发现结果的意义,做出正确的决定。
需要说明的是,数据挖掘的过程是一个不断反馈的过程,各步骤也不是一次完成的,部分或全部可能还要反复的进行,直到达到预期结果。
3 图书馆服务数据挖掘案例分析
为了进一步理解如何利用数据技术提高图书馆管理,在此我们举一个有关图书馆馆藏建设与读者个性化服务信息决策分析过程的案例进行详细说明。
首先,根据设定的问题与目标,数据选取应重点选择与馆藏材料借阅及用户组群信息相关的数据,尤其是两者之间具有关联性的数据。具体而言,其内容与来源可分为以下八类:
1)用户查找与使用的馆藏资源数据。包括资料的标题、专题类别、学科分类、材料形式等。这些数据可以很容易地在图书馆的在线目录查询日志文件中找到。
2)有关用户身份、职业、供职部门的数据以及他们所借材料的类别,数量,时间长短,特定时期内借阅的频度,归还材料的及时与否等。这些数据可以从计算机管理日志系统中查找。
3)有关用户访问图书馆的网站路径数据。假设我们已经命名了网站的网页(例如,A,B,C,D等),在每个用户访问时,我们就可以查询用户登陆路径(例如,如果从A页转到C页,然后到D页,最后到B页,其访问路径就可描述为“ACDB”)。利用这些数据,可以找到最热门的网址和浏览一个网站最流行的路径。这些数据存储在图书馆的Web服务器日志文件中。
4)有关图书馆的“期刊集”(印刷或电子)的数据。有价值的数据包括:期刊名称,借阅人或部门、类型(印刷或电子式)、作者、供应商以及其它合集时期。另一重要的数据可能是期刊使用频率与用户数。这些数据,印刷材料可以从杂志的借阅登记表中获得;电子材料可以从保存在电子期刊托管服务器web日志文件接收。
5)相关馆际互借资料的数据。如用户群体、资料来源、获得资料时间及费用成本要求等。可用于分析的数据是用户的类别、部门,材料供应商,获得资料的时间及成本。
6)有关资料费用的数据。像书本、期刊(纸质的、电子版的),视听材料、电子订阅、电子书籍等。有价值的数据主要是资料题目,材质种类,收购的花费。
7)从研究机构获取的各种参数。如每类学校成员总数与各类成员的数量、部门数量及部门内课程设置类型和数量,即为图书馆分配的预算。事实上,很多时候上述参数常被作为决策过程中的一个标准。
8)问卷调查数据。通常涉及到用户对于图书馆所提供的服务的满意程度。被选择用于分析数据包括:每一个评级(满意、非常满意、一般)百分比和用户数量(例如30%或120名本科生-回答他们非常满意),用户类别,用户部门、用户的出生日期,用户的学历等。
其次,对选取的数据进行预处理,建立知识挖掘数据库。本研究案例中,主要希望发现两个关系:一是用户组和他们所借材料类型的关系;二是用户组和材料借用时间之间的关系。同时,我们也希望有一个指标,或者定义一个有关“材料的使用和它的可用性”指标,并据此看是否有增加或减少某个特定的材料的需要。由此,该任务中数据库内容至少应该包括用户信息、馆藏资源信息、借阅材料信息三大部分内容,各自信息数据可以作为数据库的一个字段。这里我们简单列出三部分内容所需数据字段表(表1,表2,表3)。

表1 用户信息表

表2 资料信息

表3 借阅数据表
根据以上表格,可以通过空位填充来丰富完善分析所需数据。需要注意的是,填表前首先对原始数据信息进行转化与编码处理,以适应计算机处理的通用形式。譬如可以把一个部门的名称转变成用数字代表(如管理和生产工程用11;矿物资源工程用12,环境工程用13等),把用户特征用大写英文字母代替(如本科生用P;硕士研究生用M;博士生用D;教授用PR、员工用E等)。如此编码,就可使数据量大大减少,从而提高数据处理的速度。对于材料的特征形式,一般可以分两类:一类是自然科学,包括数学、计算机、物理等;另一类是人文学科,包括哲学、文学、艺术等。
第三,使用SPSS Clementine数据挖掘算法,对数据进行聚合与分类,建立上述数据之间的关联,得出不同用户和借阅的材料类型(即每组用户群借阅不同类型材料比例),如图2。用户和归还材料时间之间(即每组用户归还材料时间的对比)关联性结论,如图3。
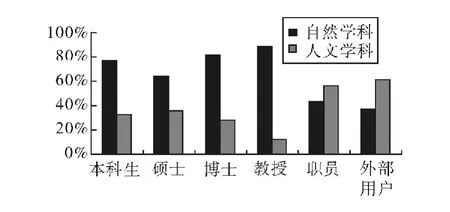
图2 不同读者群借阅资料学科类别比例对比
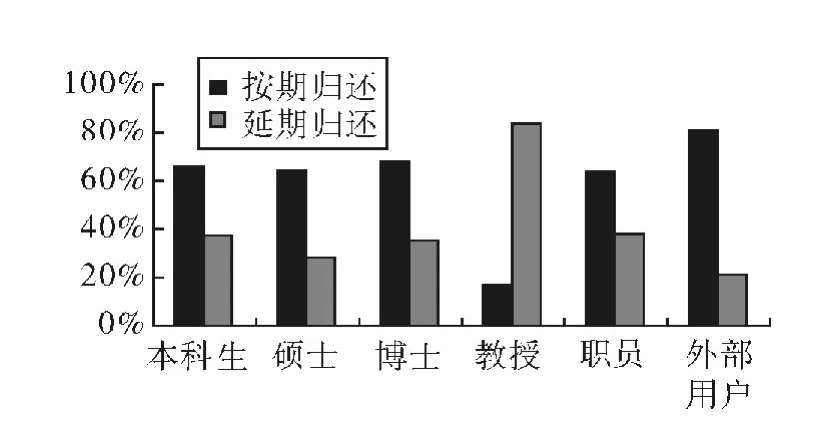
图3 不同读者群归还材料时间比例对比
要说明的是,本案例研究中并没有使用所有最初插入的数据,但他们可以用于其它不同的相关性分析中。由于他们已经插入表中,要获得其他相关性是非常容易的。导出类似的相关性的表也是非常简单的,只要在分析项目中加入相关的参数。最重要的是,确定适当的要素关系,以及最想获得的信息类型。
第四,分析统计表,对结果进行评估与解释,进而做出决策。首先,从图二中可以看出,64%研究生借的是关于科学方面的书,只有36%借阅文学书籍。不同读者群的阅读兴趣取向由此得以清楚表现,再结合服务不同读者的群数量比例参数,我们就可以馆藏资源进行合理的优化配置。从图3可以看出,83%教授还书的时间延迟,和其他人员形成了明显反差,据此我们可以制定有针对性制度建。
另外,仔细观察材料用途的数据,我们还可以通过关联材料的“借出数量“和”预订数量“,确定一个关于利用率指标公式.即:
材料的直接利用指标(IDAM)=预订用户数量/借出的数量
这个公式表示一种材料在一定时期内预定与借出数量之间的关系,并显示借出这种材料一个直接的可利用率。只要该指标随时间增加,对于这种材料的需求也随之增加。例如,在一年的一段时期内材料A被借10次,并在同一期间被预定5次,这意味着这种材料有5次不满足需要。它的IDAM指标是5∶10=0.5。及时增加这种资料的数量,这个指标将得到改善,也就不会有那么多的预定,且会被更多的使用。通过使用这些指标,我们可以确定一个界限,根据它可以很容易地确定是否有必要增加这种特定材料,以满足用户的需求。除此,认真观察分析后的数据,我们可以发现更多指标,帮助获得关于各种关系的有用结论。这些结论可以运用于图书馆的其他管理程序之中,帮助图书馆管理者看清楚图书馆发展趋势与方向,以提升图书馆的整体服务质量。
4 结语
本文以图书馆各区域的日常基础数据为分析对象,旨在说明数据挖掘技术是如何选择、使用和分析这些数据从而得出有用的结论和信息,提升图书馆的运作和服务。文中给出了图书馆所有数据资源的详细列表,并一步一步的详细描述了基于“知识发现和发掘”技术的分析方法和过程,介绍了一个应用该技术的基于真实数据的研究案例。另外,界定了一个提高馆藏资料利用率与可用性的指标。这个分析方法最终目的,是利用最新的数据挖掘技术,通过对已选取数据的分类、统计、分析进而得出有益的信息,帮助决策者进行决策和战略规划,从而构建一个更有效的内部程序机制,提升图书馆的服务质量与效果。
[1]杨 辉.基于数据挖掘技术提高图书馆服务质量[J].信息与电脑,2012(7):173-174.
[2]邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利出版社,2003.
[3]李文阔,李永先.数据挖掘在数字图书馆中的应用研究综述[J].新世纪图书馆,2012(2):30-32.
[4]叶新友,晁成春.数据挖掘技术在高效图书馆中的应用[J].新世纪图书馆,2005(1):50-51.
[5]陈京民.据仓库与数据挖掘技术[M].北京:机械工业出版社,2001.
[6]张永生,刘苗苗.基于数据挖掘的图书馆管理模式分析[J].科技资讯,2010(3):245.
[7]元昌安.数据挖掘原理与SPSS Clementine应用宝典[M].北京:电子工业出版社,2009.
[8]Meletiou A,Katsirikou A.Qualitative indicators of services of libraries and management of resources:methodologies of analysis and strategic planning[C]//Paper presented at the 15th Congress of Academic Libraries,San Antonio,TX,May,2006.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
小太阳画报(2018年1期)2018-05-14
电力与能源(2017年6期)2017-05-14
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
信息通信技术(2015年6期)2015-12-26
创业家(2015年5期)2015-02-27
小天使·一年级语数英综合(2014年8期)2014-06-26
电子设计工程(2014年18期)2014-02-27
