
一种融合开发者问答社区信息的专家推荐方法
2019-01-23 08:15慕江林冉彪
现代计算机 2018年36期
慕江林,冉彪
(西华大学计算机与软件工程学院,成都 610039)
0 引言
软件开发者数量的增加促使了开发者社区规模变大。开发者社区StackOverflow上的用户量已经超过了600万,问答帖子超过1300万,每天产生的问答超过5万。提问者可在开发者社区中搜索回答。当提问者没有搜索到满意的帖子,提问者可发起新问题,等待领域相关的专家开发者回答。然而,开发者问答社区存在大量不同领域的问题帖,专家开发者需要耗费大量的经历筛选出自己领域相关的问题帖并给出相应回答。因此,大量问题贴不能获得满意回答,专家开发者无法提供领域内帮助,导致用户量减少、满意度和认可度下降。在资源数量庞大的情况下,如何为新问题贴提供相关领域内的专家开发者尤为重要。
对于开发者问答社区的专家推荐,研究人员抽取问题标签、标题和内容和专家标签、历史活跃领域等信息建立问题主题和专家主题模型,从而计算问题和专家之间的主题匹配度推荐。Martin等[1]基于KNN方法分析缺陷报告中潜在的主题和开发者特征的相似关系来推荐最佳缺陷修复者;Xin等[2]提取多个主题,计算跨域主题间的相似性进行跨域协作推荐;Mao等[3]基于开发者历史完成的任务和开发者声誉,给出了开发任务匹配模型,利用开发者的声誉增强进行开发者推荐;Y Tian等[4]对StackOverflow上开发者的历史数据分析,基于LDA模型,发现用户潜在兴趣,最终基于用户兴趣和协作投票为问题推荐专家。上述的专家推荐算法是基于主题之间的相似度推荐。基于文本抽取的主题词面临着关键词提取困难、噪声等问题,难以提取能够准备描述问题的关键词。问题主题词对比专家的描述信息词汇,即使两者有语义相似的词汇而词结构不同词被视为不同词汇,导致了推荐结果的准确率降低。
针对上诉问题,本文提出一种融合开发者问答社区信息的专家推荐方法。通过引入匹配度和参与度,将两者进行融合,结合自编码器模型,学习问题和专家之间的非线性语义关联,拟合问题对开发者的评分,最终推荐top-N专家。
1 问题-开发者关联度与参与度模型建立
问题和开发者的关系主要表现在两个方面:开发者标签和问题标签关联程度,开发者是否直接参与该问题。开发者标签信息是对发者对自身知识能力的总结评价,反映了开发者擅长的兴趣的领域,对开发者的能力评价有重要的作用。通过提取开发者标签和问题标签,计算相似度得出问题-开发者关联度矩阵。根据开发者是否直接参与到问题,以及其他开发者对该开发者参与问题打分,形成问题-开发者评分矩阵。
1.1 问题与开发者的关联度
问题与开发者的关联度,度量了开发者从事领域与问题的领域的相关程度,作为开发者是否能够准确回答问题的重要评价指标之一。每个开发者都有与之匹配的开发者标签,开发者标签由开发者本人填写,反映了开发者的知识结构。提问者提出问题时,选择任务标签信息来标识该任务所属的领域,使得同领域的开发者更容易发现、处理该问题。开发者标签和问题标签,通过集合来表示,通过Jaccard相关系数计算开发者标签集合和问题标签集合的关联度。定义开发者标签集合:问题标签集合Tq={tq1,tq2,...tqn},根据Jaccard相似度系数,问题-开发者相似度关联度计算如下:

dr表示问题和开发者的匹配度,当dr越大,关联度越高。例如,开发者标签问题标签为根据公式,匹配度sd=0.167。
1.2 问题-开发者参与度
开发者对问题的参与度展示了开发者与问题的直接关联,是评价是否针对该问题推荐开发者的直接指标。问题对开发者的直接评分,取决于开发者参与该问题获得其他开发者的赞同数和是否被该问题的发起者所接受。问题可由多个开发者共同参与,每个开发者给出自己的回答,针对该回答,其他开发者对该回答进行评价,根据被赞同数量进行评分值建立。如果该问题的赞同数目vc分别在0-50,50-100,100以上,则分别评为0.2分,0.6分,0.9分。任务发起者选取符合问题的答案来确定最佳答案。同一问题,接受者只能为一位开发者,va表示该答案是否为提问者所接受,不接受为最佳答案评分0.3分和接受为最佳答案评0.7分。两个方面综合评价问题对开发者的评分,分别为λ1+λ2=1,其中最终开发者对问题的评分可由如下公式计算:

例如,问题有3个开发者u1,u2,u3回答,u1给出的回答为问题的接受答案,u1,u2,u3获得赞同数量则u1,u2,u3对于问题的相应 得 分 为取。
2 融合关联度和参与度的问题-开发者矩阵评分值拟合
2.1 问题-开发者评分初始值
问题对开发者的评分值由综合问题与开发者的匹配度和问题开发者的参与度组成,通过选取适当的权重参数,得出问题-开发者评分值。定义σ1+σ2=1,问题-开发者初始得分值计算方式如下:

图2给出了问题-开发者初始值矩阵示意图,实心原点表示问题和开发者的仅有关联度值;空心圆表示问题对于开发者的仅有参与度值;空心圆中一点表示融合关联度与参与度后的值;空心圆中叉符号表示拟合后的评分值。软件开发领域众多,开发者和问题的领域有限,开发者和问题匹配度和参与度不为零的项较少,导致了融合匹配度和参与度矩阵较为稀疏。
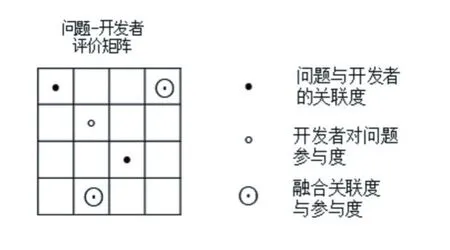
图1 问题-开发者初始值矩阵示意图
2.2 基于自编码器的任务-开发者评分拟合
问题-开发者匹配度和参与度形成的问题-开发者初始值仍然存在缺失数据,本文采用自编码器的协同过滤算法[6]对评分值进行拟合。如图2所示,设m个任务和n个开发者,任务-开发者评分矩阵R∈Rm×n,每一个开发者u∈U,任务集合t∈T,其中将缺失评分值的评分矩阵的一列输入到自编码器中,即可得到图3拟合评分值。
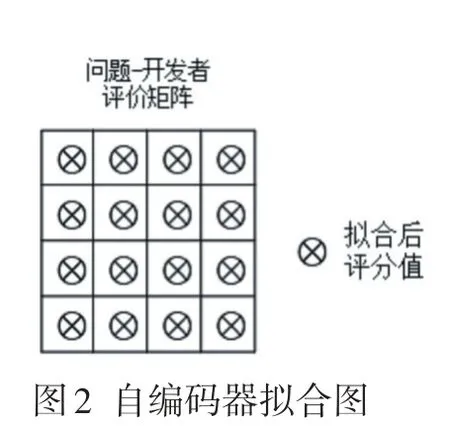
图2 自编码器拟合图
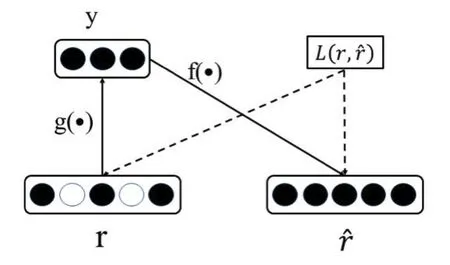
图3 自编码器拟合图
拟合评分值表示为:

其中,r为原始问题-开发者初始评分值,y为隐含层表示,rˆ为经自编码器拟合后的问题-开发者评分值。V和W为自编码器中的权重值参数,μ和b为偏置参数是激活函数。
为了使得模型输入输出误差最小,使用最小平方误差来衡量拟合评分值和原始评分值之间的误差:

为防止模拟过拟合,建立如下优化目标函数:
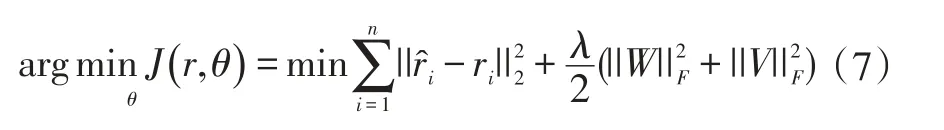
对于一个输入样本参数更新过程如下:
(1)前向传播:对每个输入样本,根据输入计算,隐含层输入Wr+μ、隐含层输出y、输出层输入V·y+b和输出层输出rˆ。计算输出误差向量:
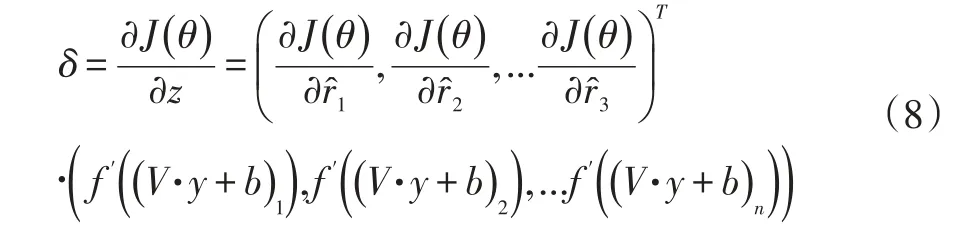
计算隐含层误差向量:
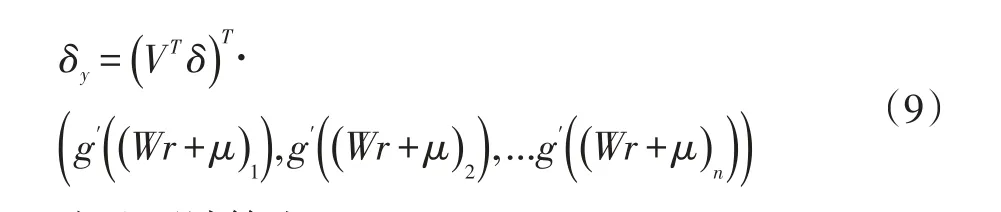
由此可计算出:
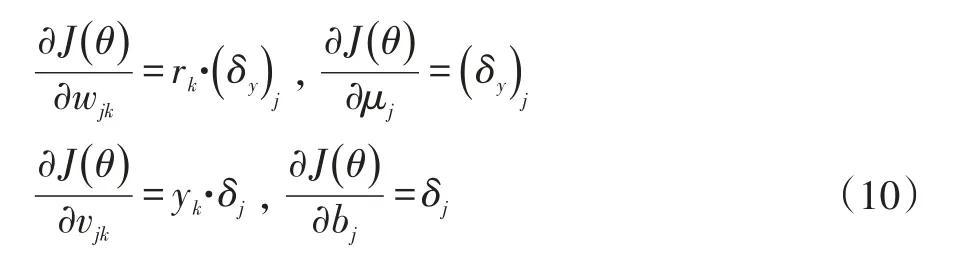
其中wjk和vjk分别表示输入层第k个节点和隐层第j个节点相连的权重参数,vjk与wjk类似。
(2)参数更新:对m个样本,l层的参数更新:
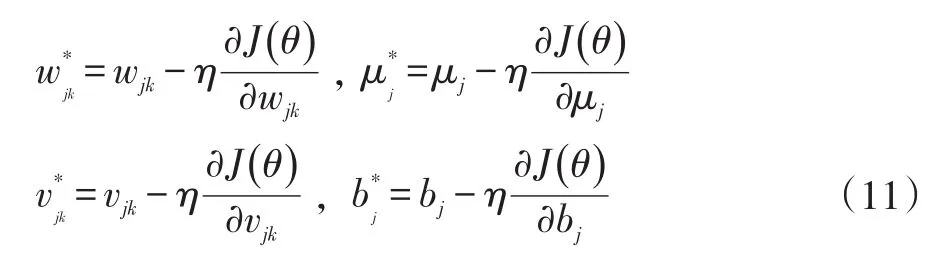
对于n个样本,初始化θ中的参数为( )0,1 的随机值,重复上述更新过程,即可求得θ。
3 融合开发者问答社区信息的专家推荐方法
融合开发者问答社区信息的专家推荐算法(Developer Community Information Fused Expert Recommendation,DCIFE_Rec),融合了问题和开发者的关联度和开发者对问题的参与度,多方面挖掘了问题和开发者之间的关系,能够有效地提高推荐的精度。图4为融合开发者问答社区信息的专家推荐方法的处理流程,按照矩阵行为问题、矩阵列开发者、填充匹配度和参与度值,分别建立匹配度和参与度矩阵。

图4 融合开发者问答社区信息的专家推荐方法
第1步提取开发者标签和问题标签,计算开发者和任务的关联度,根据关联度建立问题-开发者匹配度矩阵。
第2步根据开发者是否直接参与问题、开发者的答案是否提问题者接受以及该答案被其他开发者所赞同的次数计算开发者对问题的参与度,根据参与度建立问题-开发者参与度矩阵。
第3步融合开发者和问题的匹配度矩阵和参与度矩阵,得到问题对开发者评分值初始矩阵。
第4步利用自编码器学习拟合缺失问题对开发者的评分值矩阵。
第5步按照评分值排序,推荐top-N专家。
4 实验分析
为了验证本文所提出的算法的有效性,截取2008年StackOverflow问答社区数据进行分析,并与其他的推荐算法进行比较分析。
4.1 数据集
数据集以表的形式提供。其中,Posts表包含了问题提交信息和问题的回答信息,可通过表的查询,获得问题标签数据、回答问题的开发者、回答被赞同的数量和回答是否被接受。Users表存储了用户信息、用户标签。
4.2 评价指标
为了衡量推荐系统的性能,本文选取的平均准确度(Mean Average Precision,MAP)和覆盖率(Coverage)两个评价指标。
平均准确度用来衡量推荐结果准确程度,平均准确度的值越小,表示预测效果越好。平均准确度的计算方式如下,l表示推荐列表的长度,dc表示正确推荐的开发者个数,dw表示错误推荐的数量,包括把其他领域推荐给该问题的开发者个数。MAP可表示为:

覆盖率主要衡量推荐结果的覆盖范围.覆盖率定义被推荐的开发者占总开发者的比例,T为问题集合,U为开发者集合,u(t)表示推荐给问题的开发者集合,可以表示为:

4.3 实验设置
为了验证本文所提出的算法在预测效果提升和稀疏性处理,在准确率和覆盖率上对以下算法进行了比较分析:
(1)BaseCF_Rec算法[8]是基于问题-开发者参与度形成的问题-开发者矩阵进行的协同过滤推荐算法。BaseCF_Rec算法对原始问题-开发者矩阵评分值按照大小排序,生成top-N列表。
(2)MF_Rec算法[7]是基于问题-开发者参与度形成的问题-开发者矩阵进行的矩阵分解算法。MF_Rec算法在问题-开发者矩阵上进行矩阵分解出问题和开发者的隐语义表示,再通过隐含语义表示对评分值拟合,在拟合结果值上按照得分值排序,生成top-N列表。
(3)DCIFE_Rec算法是一种融合了问题与开发者关联度和开发者对问题的参与度的自编码器协同过滤算法。融合开发者问答社区信息的专家推荐方法利用问题和开发者标签计算匹配度,加权问题和开发者的关联度,有效的缓解了矩阵的稀疏性。
为了防止模型对训练集数据过拟合,采用交叉验证法,将实验数据分为三份,每次取其中一份作为测试集,其他两份作为训练集,θ最终结果为三次训练的平均值。模型训练参数设置如下表:?

表1 模型参数设置
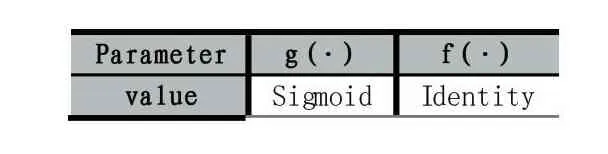
表2 激活函数设置
4.4 实验结果分析
在开发者推荐数量小的情况下,推荐正确率和覆盖率偏低,随着开发者推荐数量的增加,推荐的正确率和覆盖率都有所增加。BaseCF_Rec推荐算法基于问题-开发者矩阵的评分值直接排序,没有考虑问题和开发者的隐藏语义,推荐的准确率较低。MF_Rec推荐算法由于其问题-开发者的稀疏性,矩阵分解拟合的结果不太理想。加权标签匹配度的自编码器协同过滤推荐算法,由于其缓解了问题-开发者矩阵的稀疏性,推荐结果和覆盖率相比BaseCF_Rec算法和MF_Rec算法高。
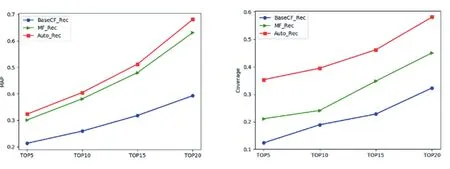
图5 准确度和覆盖率指标对比
5 结语
本文提出的融合问答社区信息的专家推荐方法,通过问题标签和用户标签匹配度、参与度,有效地缓解了传统协同过滤算法的稀疏性,使用自编码器,减少了模型训练时间,同时提升了模型性能。在以后的研究中,将综合考虑用户的活跃度、社交信息等信息,寻找更为精确的推荐算法。
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
网络安全与数据管理(2022年1期)2022-08-29
小学教学研究(2022年18期)2022-06-29
选煤技术(2022年2期)2022-06-06
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
甘肃教育(2020年24期)2020-04-13
劳动保护(2019年3期)2019-05-16
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
