
大数据视角下的非结构化文本挖掘分析方法
2021-07-27 15:46黎伟健胡斌李威唐健玲肖西西
新媒体研究 2021年8期
关键词:情感分析
黎伟健 胡斌 李威 唐健玲 肖西西
关键词 非结构化文本;情感分析;分类分析
中图分类号 G2 文献标识码 A 文章编号 2096-0360(2021)08-0008-03
1 研究背景
根据IDC报告,当下数据以每年50%左右的速度快速增长,非结构化文本数据占比很高。因此,非结构化文本数据的挖掘分析显得尤为迫切和重要。
文本挖掘(Text Mining)又称为文本数据挖掘(Text Data Mining)或文本知识发现(Knowledge Discovery in Texts,KDT),是指从大量非结构化文本数据中抽取未知的、可理解的、最终可用的知识,并运用这些知识更好地组织信息,进而获取用户感兴趣或有用模式的过程[1-2]。文本挖掘流程大致可以描述为基于网页、文档、字符等非结构化文本数据,利用自然语言处理技术实现非结构化文本数据结构化,再结合机器学习、统计分析、可视化分析等技术进行挖掘分析,进而实现搜索引擎、舆情分析、新闻分类等。
目前,文本挖掘作为信息时代的重要研究领域,逐渐成为国内外学者的重点研究方向。本文将基于大数据视角,通过对文本挖掘分析方法进行梳理,总结海量文本分析流程,以期能有助于对海量文本开展情感分析和问题分类。
2 文本挖掘方法
采用“朴素贝叶斯算法”(Naive Bayes Classifier)和机器学习[3],对客户反馈的意见进行情感正负向判断,将客户反馈标记为1(正向)、0(中性)、-1(负向)3类。通过人工标注分类规则、机器运行相结合的方法对客户意见进行分类,发现用户反馈意见的主要内容,分析完成后会通过不断的人工校验优化分类规则,提高分析准确性。
2.1 客户情感倾向分析
在行业已有的情感分析模型[4]基础上进行优化,应用于客户反馈意见的情感倾向分析,具体分析过程(图1)如下。
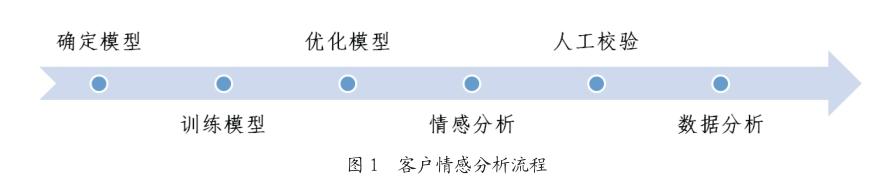
2.1.1 确定模型
使用机器学习方法对文本进行处理需要将文本编码为计算机容易处理的形式,本次采用One-Hot编码对文本进行处理。One-Hot编码,又称一位有效编码,其方法是使用N位状态寄存器对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。在本次分析中,寄存器的每一个状态即是一个词汇,如果文本中存在相应的词汇则为1,不存在则表记为0,最终将文本转换为由0和1组成的长度为N的数组,称为N维特征向量。其维度N为对训练数据进行分词、去重并去除停用词后的词汇数量。
在分类算法的选择上选用朴素贝叶斯分类器,在工业上广泛应用于垃圾邮件的分类。其基于贝叶斯定理,依據先验概率和似然函数对后验概率进行估计。在贝叶斯分类器中,训练的过程即是通过统计获取先验概率和似然函数取值的过程。在训练完成后,对特定文本进行情感判断即是计算在当前条件下特定情感的后验概率,并选取后验概率最大的情感类别作为分类器的输出。
2.1.2 训练模型
机器学习模型的表现受训练过程的影响较大。为了让训练集保持对全量数据的代表性,尽量保证训练集的分布与全量数据一致,在打乱原始数据后抽取了1万条数据进行人工标注。在权衡人力消耗等因素后,引入约2万条内容较为相似的开源数据集,总计约3万条数据对模型进行训练。
2.1.3 优化模型
使用训练好的分类器对小批量数据进行分类,并根据分类结果对分类错误的样本进行失效分析。有针对性地对分类器特征提取方面进行优化,提升模型的准确性。在实践中主要有以下情况。
1)由于训练集中未包含类似表述的文本,导致未能提取到任何特征,判断失败。这种情况需要添加一定数量的相似数据到训练集中。
2)文本特征被停用词表过滤导致未能提取到特征,或者无意义的词汇特征过多干扰判断。这种情况需要对停用词表进行修改,尽量避免无意义词汇进入特征和有意义词汇被过滤的情况。
3)文本被不恰当的分词导致判断错误。这种情况需要精细调整分词工具的用户词典,由于中文文本经常存在可被多种分词方式划分的情况,这时需要调整词典词频确保划分贴合实际含义。另外将否定词与其后紧接的词汇连起来划分为一个单独词汇也可提高模型准确性。
2.1.4 情感分析
应用优化后的模型对全量客户反馈的回答进行情感分类。
2.1.5 人工校验
深入分析行业前沿的情感分类AI模型,开展辅助验证(如讯飞等)。通过优化测试模型的算法源码,调整模型参数等手段,将情感分类模型的准确性的从82%提升至89.22%。
2.1.6 数据分析
通过分析客户反馈回答的情感倾向占比,及其与客户对产品的整体满意度评价等其他指标间的关系,可多维度客观地反映客户对产品的真实评价,此外可预测不同满意度客户的反馈回答的情感倾向。鉴于通常客户调研均以满意度、NPS等量化问卷调研客户对产品的满意度,答题成本相对较低,客户可能未认真回答,或未按照内心真实想法回答,而开放性问题答题成本相对较高,其反馈的意见通常为客户的真实评价,故对开放性问题的回答进行分析可更真实的获取客户的评价。
2.2 客户意见分类分析
通过人工标注分类规则、机器运行相结合的方法,对客户反馈的回答进行问题分类,聚焦客户反馈的问题类型,具体分析过程(图2)如下。
2.2.1 数据清洗
鉴于客户反馈意见中存在部分无意义的回答,故采用人工分析方式对客户反馈的回答进行清洗。正向评价的客户通常表达对产品的好评意见,回答可能会相对简单,存在3个字符以下的回答,如“好、满意、很满意”等,故正向评价的客户反馈回答的数据清洗标准为:删除全部为标点符号的回答;负向评价的客户更倾向于表达对产品的差评、使用产品遇到的问题、对产品的优化建议等,若字符太少,则无法有效表达,故负向评价的客户反馈回答的数据清洗标准为:删除全部为标点符号、少于3个字符的回答。
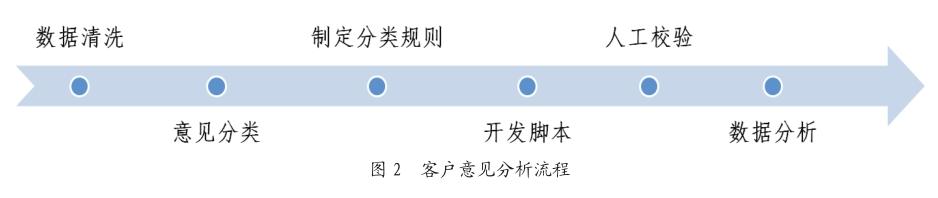
2.2.2 意见分类
通过机器分词与人工抽样查看相结合的方式对客户反馈的回答进行。通过机器分词,确定正负向评价的有效数据中客户提到的高频词汇,及其出现的频率,同时随机抽取总样本的5%逐个人工查看客户的回答,对客户的反馈进行分析归类。通常可将客户的反馈分为好评类、差评类、建议类3大类,好评类可具体分析客户反馈的回答中好评集中在哪些方面,相关的关键词是什么;差评类和建议类客户的反馈内容相对翔实,可分析客户反馈的回答中差评、建议集中在哪些方面,具体表现及相关关键词是什么。
2.2.3 制定分类规则
通过机器分词筛选出的高频关键词,以及人工查看确认的相关关键词,对比全量有效的客户反馈回答,确定客户的回答的具体类型,提取归纳客户意见类型的关键词及其逻辑关系,通过“and”“or”“not”等逻辑关系词制定相应的分类规则。同时,在制定规则的过程中,通过查看全量有效数据,不断增加新的观点进行迭代优化。制定分类规则时,需明确每个意见类型的定义,挖掘该意见类型的核心特质,并根据核心特质确定分类规则。如制定客户对客服服务态度的规则时,首先需确定客服相关的关键词,如“人工”“话务员”等,然后确定服务态度相关的关键词,如“态度”“语气”等,二者通常需同时出现才可进行筛选,可以“and”进行连接,此外撰写关键词时,除了提取客户原话中的关键词,也可通过日常表达选择关键词的近似词,如近义词等方法扩大关键词的词库。此外需注意,客户填写答案时易出现错别字,需将高频的错别字也放入规则,如“太度”等。
2.2.4 开发脚本
使用Python编写分类脚本与规则检查脚本。脚本读取编写好的分类规则进行词法分析,将规则由字符序列转换为标记(Token)序列,包含关键词,运算符(and、or与not)和界符(用于改变优先级的括号)三种标记。在分类时,先提取出标记序列中所有的关键词,逐一判断待分类文本中是否存在关键词,如存在则替换为布尔值“真”,否则替换为布尔值“假”。经过上述过程,此时的规则已经转换为一条逻辑表达式,表达式的运算结果即为待测文本是否符合该条规则。脚本开发完毕后,对全部开放性客户的回答进行问题分类,提升效率。
2.2.5 人工校验
通过不断的人工校验优化分类规则,主要是通过抽取部分的分类结果,人工对归类结果的准确性进行统计,同时查看归类错误、未纳入归类的客户原话,不断迭代优化分类规则,将归类准确性从最初的50%左右提升至76.51%。
2.2.6 数据分析
通过分析客户反馈的回答中的问题、建议等具体类型的占比,确定客户关注重点,若客户反馈了具体问题或建议,则根据意见占比确定优先级;若客户未反馈具体问题或建议,则可辅助其他方式,如竞品对标等挖掘客户评价的真实原因,有效利用客户的反馈挖掘有意义的信息。
3 方法合理性分析
鉴于客户回答开放性问题时,通常是有具体问题才会较有动力回答,故客户开放性问题回答中,主要以负向评价为主,本次分析27万的客户反馈中,仅14.62%为正向评价,且正向评价主要为无具体指向的好评,以人工分析为主,故不分析正向评价的分类分析的合理性;负向评价高达83%,分类分析主要应用于负向评价分析,故以负向数据的结果进行方法合理性分析。
3.1 情感分析方法准确性分析
随机抽取1 000条情感分析的数据结果,人工判断其情感倾向,与机器判断结果进行对比,发现客户的情感分类准确性从最初的82.00%提升至89.22%。
3.2 分类分析方法合理性和准确性分析
对所有负向评价的有效数据进行问题归类后,统计纳入归类分析的数据占比,分析问题归类的合理性,有效数据量为206 316,纳入问题归类的数据量为162 082,有效率为78.56%。针对有效数据占比低的问题进行抽样统计,发现未被纳入归类的问题中,确实无法被归类的占比为93%,主要原因为反馈内容无意义、非针对开放性问题对象的回答等。
对所有负向评价的有效数据进行问题归类后,统计纳入归类分析的问题的准确性,分析问题归类的准确性,共抽取2 065个样本,其中准确归类的数据量为1 580,准确率为76.51%。
4 實际可应用场景
以上梳理和总结的海量文本分析流程,可以应用于知识管理、客户服务、社交媒体数据分析等各类场景。
4.1 知识管理
管理大量文本文档时,一个很大的问题就是无法快速地找到重要的信息。例如,对于医疗行业来说,研发一个新的产品可能同时需要近十年的基因组学和分子技术研究报告。此时,基于文本挖掘的知识管理软件为此种“信息过剩”情况提供了有效的解决方案。
4.2 客户服务
文本挖掘和自然语言处理是在客户服务领域常被使用的技术。如今,利用调查、故障单、用户反馈等有效信息,文本挖掘技术可以用来改善客户体验,为客户提供快速高效的解决方案,以期减少客户对帮助中心的依赖程度。
4.3 社交媒体数据分析
如今,社交媒体是大多数非结构化数据的产源地,企业可以使用这些非结构化数据去分析和预测客户需求并了解客户对其品牌的看法。通过分析大量非结构化数据,文本分析能够提取意见,了解情感和品牌之间的关系,以帮助企业发展。
5 不足及展望
目前,按照分类分析流程开展的海量非结构化文本问题归类过程中,发现归类准确性不高的原因主要在于:一是样本量较大,客户反馈的开放性问题相对较为分散;二是非结构性文本、口语化表述较多,关键词不明显,导致分类规则无法包含全部用户的反馈;三是项目开展时间较短,模型及算法仍需完善,后续将通过经验沉淀继续优化分类规则。
根据每年的发文量来看,文本挖掘在近几年得到了快速发展[5]。随着文本挖掘研究的深入,其应用领域还将不断拓展,同时,随着大数据、云计算、人工智能等智能化的发展,未来将文本挖掘应用于大数据处理将面临更大的挑战。如何将文本挖掘与大数据、人工智能等更好地结合起来,是研究者所需面对的问题。
参考文献
[1]徐德金,张伦.文本挖掘用于社会科学研究:现状、问题与展望[J].科学与社会,2015,5(3):75-89.
[2]李尚昊,朝乐门.文本挖掘在中文信息分析中的应用研究述评[J].情报科学,2016,34(8):153-159.
[3]程显毅,朱倩著.文本挖掘原理[M].北京:科学出版社,2010.
[4]赵刚,徐赞.基于机器学习的商品评论情感分析模型研究[J].信息安全研究,2017,3(2):166-170.
[5]谭章禄,彭胜男,王兆刚.基于聚类分析的国内文本挖掘热点与趋势研究[J].情报学报,2019,38(6):578-585.
猜你喜欢
电子技术与软件工程(2016年15期)2017-04-27
软件工程(2016年12期)2017-04-14
电脑知识与技术(2017年5期)2017-04-08
电脑知识与技术(2017年3期)2017-03-27
智能计算机与应用(2017年1期)2017-03-23
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
读写算·教研版(2016年17期)2016-11-08
电脑知识与技术(2016年5期)2016-04-14
