
烟草市场规模估计的分层抽样策略研究
2022-06-07 06:01刘佳
中国市场 2022年14期






摘 要:当前,数据化经营成为生产力发展的重要方向,但以线下运营为主体的烟草行业,其数据采集能力仍有待进一步提高。随着行业市场分析的紧迫性日益加剧,烟草行业需要找到一条兼顾数据采集工作量与分析结果准确性的数据化市场规模评估机制。文章从门店抽样出发,在样本设计、样本检验、还原算法等层面进行了深入研究,提出了完整的市场评估方案并采用真实数据通过了方案测试,为今后烟草行业的市场规模研究提供了行之有效的解决办法。
关键词:分层抽样;还原算法;市场评估
中图分类号:F416.8文献标识码:A文章编号:1005-6432(2022)14-0184-07
DOI:10.13939/j.cnki.zgsc.2022.14.184
近年来,随着全行业推进供给侧结构性改革、加强市场监管和内部管理、完善专卖体制等政策,我国烟草行业整体保持良好稳定发展[1]。但在不同地区由于市场特点各不相同,其市场表现、发展模式、管理形式也不可避免的有所差异。因此,精准的地区市场状态的反映及评估,是进一步深化地市级烟草公司发展的有力武器。
市场状态评估主要受两个维度的影响:市场数据采集与还原算法。一个市场的状态是否良好,需要通过市场状态指标对投放效果进行回顾分析,从而予以判断。当前,卷烟市场状态指标主要包括条毛利率、社会库存与周存销比。笔者以西安市为例,由于门店机器采集普及率较低,大部分门店仍为人工采集,又由于人工采集受环境、人为因素的影响较大,人工操作的不确定性使得市场状态计算科学性存在一定的提升空间。
同时,在还原算法层面,现行方法也存在一些问题。当前还原算法根据样本门店的存销比对社会库存进行推估,这样并没有很好地考量样本可能包含的多维度特征,致使市场状态计算存在一定误差。
因此,本文从细化市场数据采集、改进还原算法的角度出发,以西安市为例对目前烟草行业市场状态评估所采用的抽样策略系统进行了细致探讨与优化设计,旨在为后续市场状态分析打好基础,用更有效的“系统大数据”帮助业务人员掌握更准确的“市场活情况”。
1 抽样方案设计
1.1 方案重点概述
当下,中国数据产业蓬勃发展,各行业纷纷拥抱数据化所带来的精细化管理、预判、执行等业务赋能。但目前国内商业数据采集尚未成熟,部分行业仍然极大地依赖人工采集,从而在数据精确度与可用性方面存在不足。面对烟草行业线下运营數据采集能力的不充分发展与行业市场分析的紧迫性之间的矛盾,探索出适合当下市场发展条件的数据修正一体化方案,对于烟草市场规模评估具有很强的实用与辅助指导意义。
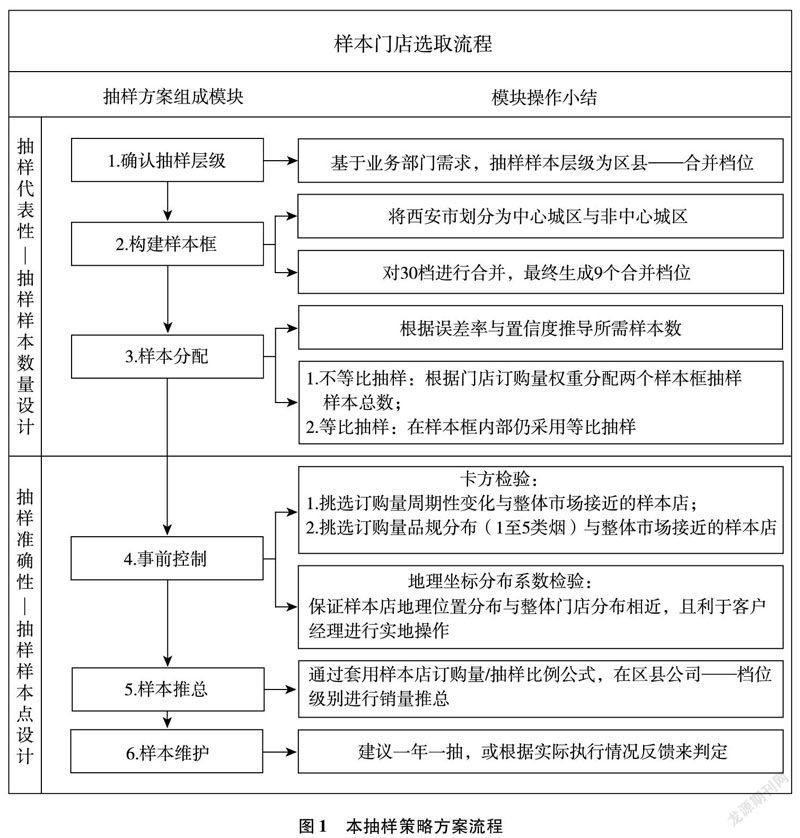
为此,首先,根据烟草市场规模评估所需数据的处理过程,制定了“修正市场状态数据源+升级抽样还原算法”的两步走方案。笔者规范了样本门店选取规则,同时重新设计门店抽样方案:①设计分层抽样算法,确保可抽样性的同时提高抽样效率;②采用非等比例抽样,分配中心城区和非中心城区样本数;③生成档位合集,提升抽样代表性;④利用卡方检验,保证样本能够合理反映市场情况;⑤分布指数检验,检查样本门店地理分布的可操作性。
其次,在完成数据修正后,根据抽样方案对还原算法进行相应调整:①细化还原计算层级;②设计科学推总还原算法。笔者根据上述策略方案在西安市进行了可行性验证,其误差率与可操作性均达到并超过预期水平。
1.2 方案流程设计
本方案从门店抽样的代表性与准确性出发,针对目前抽样中遇到的问题,诸如权重分配过于单一、样本框划分只依赖地区因素等,重点对样本数量与样本点进行设计与优化[2],从而在低成本的前提下实现了提高评估精度、改善评估描述力、增强抽样系统可维护性等目标。方案流程如图1所示。
1.3 方案测试范围
笔者选取了西安市数据进行抽样策略测试:①全量门店订购数据:2020年8月1日至9月6日;②全量门店静态标签数据(行政区、地址、门店编号、门店经纬度、门店档位),门店档位更新时间为2020年8月28日;③商品数据字典(卷烟代码,卷烟名称,品牌等)。
2 方案详述与结果
2.1 确认抽样层级并构建样本框
2.1.1 城区划分
西安市行政区划可分为中心城区和非中心城区:
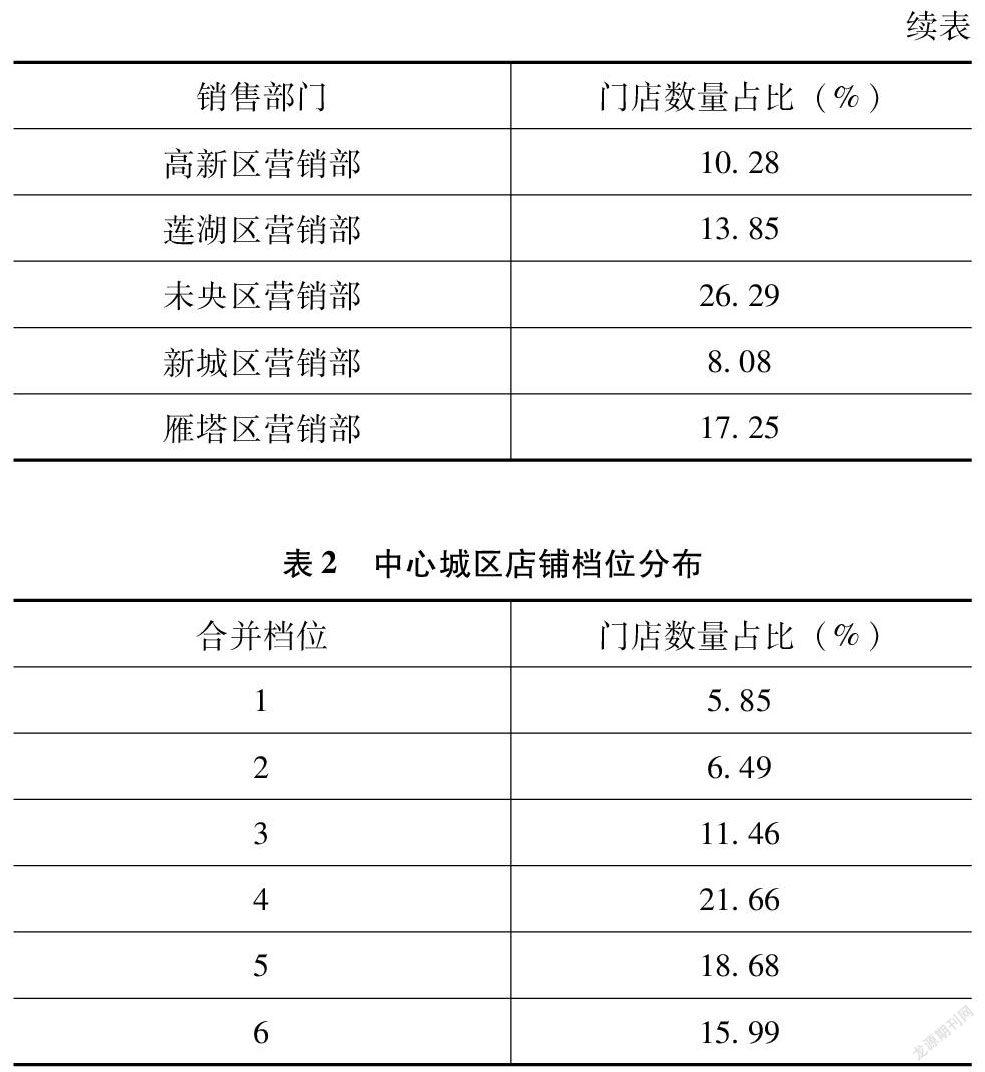
中心城区:未央区、新城区、碑林区、莲湖区、灞桥区、雁塔区、高新区。
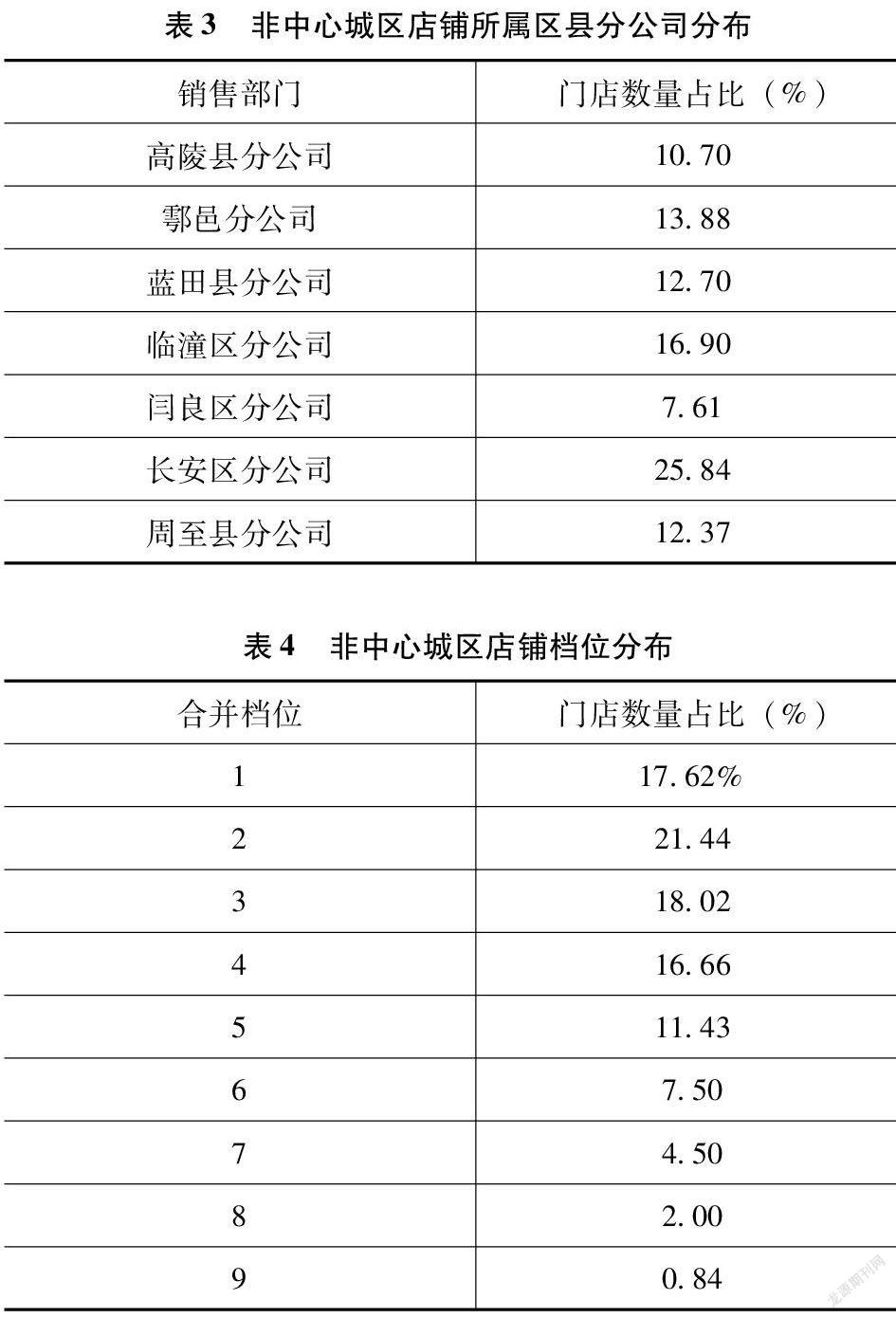
非中心城区:阎良区、临潼区、长安区、高陵区、鄠邑区、蓝田县、周至县。
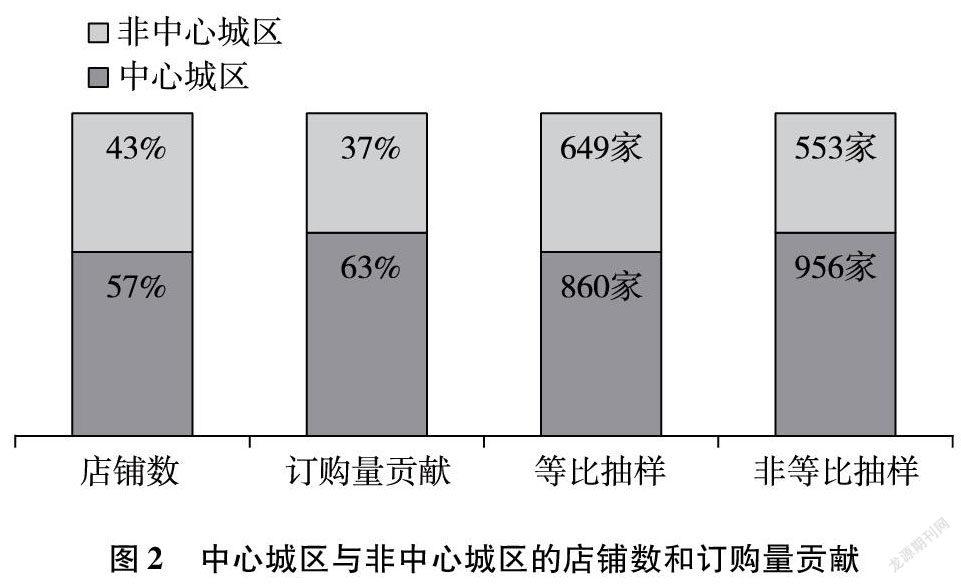
为了精准分析市场行情,抽样店铺需要充分考虑市场需求分布。传统抽样方法多采用简单直接的等比方式,即依照中心/非中心城区店铺总数比例分配抽样店铺,忽略了不同城区的商业发展状态。因此选择了考虑订购量贡献的非等比抽样[3]。图2对比了传统等比抽样和非等比抽样的抽样比例差异。
2.1.2 档位合并
除了地区属性外,门店同时还具有档位属性。传统抽样方法会直接对每一档进行抽样,导致分类过多,不利于后续分析。因此,需要在抽样前对档位进行优化合并处理。
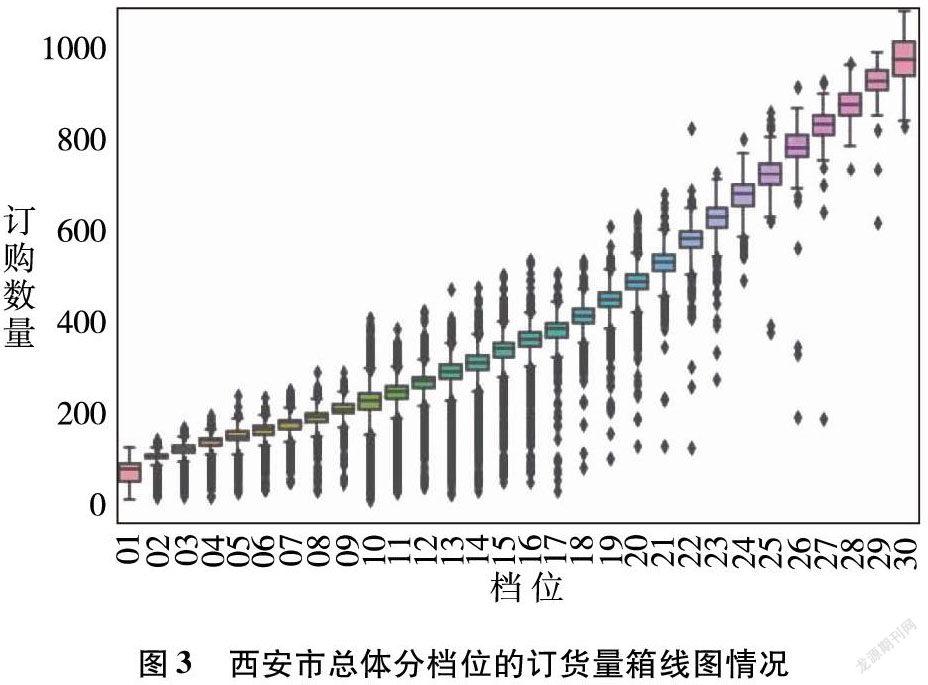
由图3可以看出,全市总体订购数量和档位数呈正相关,并随档位数递增。曲线平滑说明临近档位的订货量相近。因各区县内趋势和西安市整体趋势一致,故后续变异系数只针对全市计算。
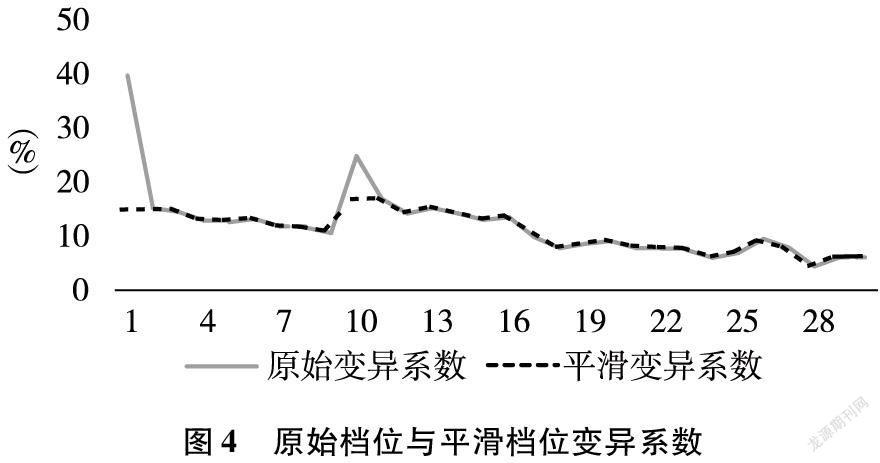
各档位的原始变异系数(变异系数 = 标准差/均值)如图4所示。变异系数能够量化档位零售店订购量的离散程度,可看到档位1和档位10订购量离散程度大。但档位1是订购表现差的门店集合,档位10则为新入市门店集合。 由于后续会对抽样门店进行事前控制筛选,且仅抽取开店6个月以上的门店,因此可忽略这两个档位的异常分布。
后对异常分布进行平滑处理,即用档位2、11的变异系数分别替换档位1、10,如图4虚线所示。
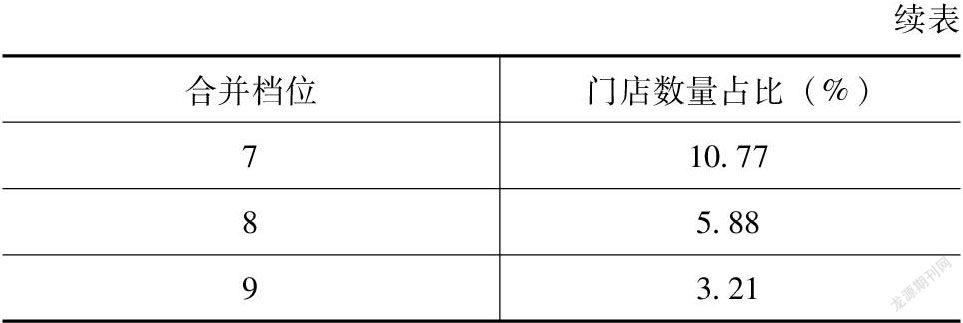
合并档位时,档位集合总数和集合中的档位数量会显著影响数据采集工作量与后续分析。笔者在测试后选择了“三档合一”为主的方案,即按照1-3,4-6,7-9,10-12,13-15,16-18,19-21,22-24,25-30合并档位。一方面可以契合图4平滑变异系数呈现的阶梯分布;另一方面平衡了抽样精确性与总人工工作量。
2.1.3 抽样框设置
第一,抽样框1:中心城区。表1、表2为分区域和档位的门店计数占比。
第二,抽样框2:非中心城区。表3、表4为分区域和档位的门店计数占比。
2.2 抽样样本数及误差估算
计算需抽取的样本量n0:
其中,d为抽样绝对误差,本方案取值2%;α为显著性水平,通常可以取α=0.05,此时置信度1-α=0.95;uα为标准正态分布在置信度为1-α时的分位数,在置信度为0.95时为1.96;p(0<p<1)是样本成数,一般在未知时,p通常取0.5,即p(1-p)可取0.25。按上述取值,可得n0=1536。
关于抽样设计的效率,可通过设计效应 (deff) 来确定[4]。对于本方案,分层设计效应可表示为:
当抽样方式为按比例的分层抽样时,nin=Wi , 分层设计效应为:
其中ρiccst=σ2bσ2是层间变差在总变差中所占的比重。可见本抽样的设计效应小于1,说明设计效率高于不放回的简单随机抽样。
综上,本抽样方案总样本需求个数在1500左右,符合西安烟草发展1500户样本的需求,故设定为1500;同时抽样误差控制在2%,显著低于省级文件要求的3%。
2.3 样本分配
确定样本总量后,笔者将样本等比例分配至各样本框。抽样框1(中心城区)需要抽出956个样本。
从销售部门来看,见表5。
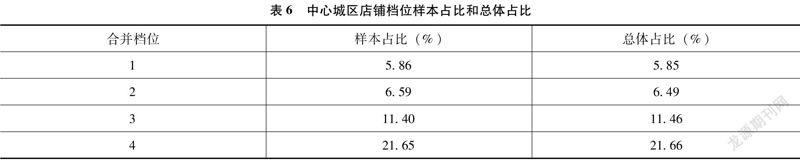
从档位来看,见表6。
抽样框2(非中心城区)需要抽出553个样本。从销售部门的分布来看,见表7。
从档位的分布来看,见表8。
2.4 事前控制
事前控制的目的是在选点前进行数据测算,确保所选样本点的个体对整体市场具有代表性及可操作性。
2.4.1 卡方检验
卡方检验是非参数检验的一种,可以统计样本的实际观测值和理论推断值之间的偏离程度,如果卡方值越大,则两者的偏差程度越大,反之则越小。卡方检验可以帮助选出与总体差异最小的样本,常用于分层抽样结果的检验[5]。
首先提出检验的原假设和备选假设:
原假设:该客户与该区域总体客户订购量,在半年与价类的分布保持一致。
备选假设:该客户与该区域总体客户订购量,在半年与价类的分布保持不一致。
卡方值表达式为:
其中,q代表的是每个客户的订购量的归一化值,Q代表的是每个区域×合并档位的总销售情况的归一化值,卡方值度量了每个客户的销售情况与其所在区域×合并档位的订购量差异大小。
χ20.95是常用的95%置信区间的卡方分布临界值,当计算出来的卡方值小于χ20.95(k-1),则在统计学意义上可以接受原假设。在本方案中,自由度k指代订购的烟类计数。
以未央区2档位为例,其每个店铺一共只有1-3类烟,自由度为2,卡方临界值为0.102587。未央区2档位应抽取12个样本,挑选卡方最低的前12个非新店铺,其卡方值都小于临界值,即证明试抽的样本店与区域×档位总体的订购量分布是一致的。
2.4.2 样本位置分布指數检验
为了保证抽取的样本店铺在地理位置上分布合理,利于客户经理进行实地操作,还需要进行经纬度分布的检验。
笔者通过观察店铺经纬度散点图来直观判断,但为了定量判断位置分布的一致性,仍需要继续计算样本分布指数。这里引入矩量母函数(mgf)的概念。mgf值对分布有唯一代表性,当mgf值相等时,这两个分布也相等。通过这个原理,就可以简单的利用二阶矩来进行检验[6]。
定义一个随机变量X的二阶距中心距为:
可以看到,二阶距就是X的方差。只需要比较抽样的样本和总体的经纬度的方差-协方差矩阵,即可判断两者的位置分布是否大致相近。
某区域经度方差=∑i(经度i-某区域经度的均值)2某区域店铺的个数-1
某区域纬度方差=∑i(纬度i-某区域纬度的均值)2某区域店铺的个数-1
某区域经纬度协方差=∑i(经度i-某区域经度的均值)(纬度i-某区域纬度的均值)某区域店铺的个数-1
由此,继续计算样本分布指数:
总体与样本的经度误差=总体经度方差-样本经度方差总体经度方差
总体与样本的纬度误差=总体纬度方差-样本纬度方差总体纬度方差
总体与样本的经纬度协方差误差=总体经纬度协方差-样本经纬度协方差总体经纬度协方差
样本分布指数=总体与样本的经度误差+总体与样本的纬度误差+总体与样本的经纬度协方差误差3
最终,笔者得到了每个区域的经纬度坐标的方差-协方差矩阵和样本分布指数,并发现其均小于100%。再结合每个区域的店铺散点图,可认为抽取的样本店铺位置分布大致符合原本店铺的位置分布情况。
2.5 样本推总
2.5.1 推总方法
采用分层抽样后,整体零售店铺可以按区县分公司×合并档位这两个维度进行划分。每一个区县分公司×合并档位,通常将其定义为一个MBD,其中包含的若干店铺的总订购量推总可由其中的样本订购量除以样本比例得到。
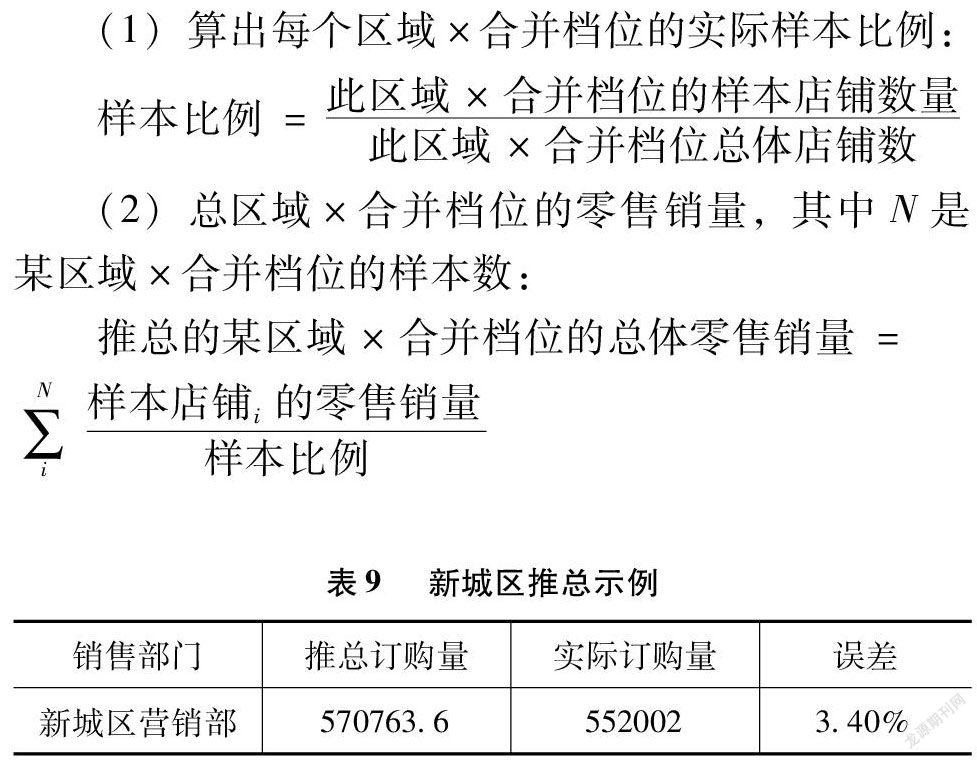
在表9中,实际订购量是新城区所有店铺的总订购量,误差=(推总订购量-实际订购量)/实际订购量。在误差较低时,可认为抽取的样本店与总体订购量情况一致。所得推总步骤如下。
(1)算出每个区域×合并档位的实际样本比例:
样本比例=此区域×合并档位的样本店铺数量此区域×合并档位总体店铺数
(2)总区域×合并档位的零售销量,其中N是某区域×合并档位的样本数:
推总的某区域×合并档位的总体零售销量=∑Ni样本店铺i的零售销量样本比例
(3)推总某区域的零售销量,其中n是某区域内合并档位的个数:
推总的某区域零售销量=∑ni某区域×合并档位i的零售销量
(4)推总西安市总体店铺的零售销量:
推总的西安市零售销量=∑14i区域i的零售销量
2.5.2 最细统计颗粒度
由于受到样本个数的限制,并非每一个MBD推总时都拥有足够的样本点。当MBD中样本个数较低时,该MBD的推估结果将不具有統计意义。在当前样本量级的基础上可以接受的最细颗粒度为:区县分公司×合并档位。
2.6 样本更新和退出逻辑
从数据来源稳定性出发,样本来源最好保持稳定,但由于卷烟销售是一个动态过程,为了获取市场的最新情况,建议样本一年刷新一次,或根据实际执行情况反馈判定。
在一年之中,如果抽中的样本店铺经营异常,如关店、不配合数据采集,应该查询本年度制定抽样方案时,该店铺所在的区域×合并档位的未抽中店铺,按照卡方值从小到大的原则,选择卡方值最小的1个店铺作为替代样本。
3 结论
高质量的数据是高质量分析的保证,在了解西安烟草当前样本门店选取和省级信息采集示范方案后,制定了当前的分层抽样方案,在可操作的前提下,有效提升了样本选择的代表性、覆盖面和准确性。该方案紧扣西安烟草当前数据执行现状,通过应用分层抽样算法,控制门店抽样误差率在2%,相比省级文件要求的3%误差率,提升了门店抽样准确率。另外通过对样本进行订购量结构、地理坐标位置验证,确保样本代表性及可操作性。
考虑到西安烟草目前使用样本门店销售数据进行市场销售状况还原,科学样本点选取可以提升市场还原精度,最大程度地复现市场卷烟营销现状,服务后续市场营销指标分析。
参考文献:
[1]王炜.精益管理理念在烟草专卖市场监管的应用研究[J].现代商贸工业,2019,40(29):118-119.
[2]方文玉. 抽样技术在烟草需求量调查中的应用[J].市场统计与信息, 2000(8):12-14.
[3]刘爱芹, 吴玉香. 分层抽样中样本量的分配方法研究[J].山东财政学院学报, 2007(4):49-53.
[4]L.基什.抽样调查[M].倪加勋,译.北京:中国统计出版社,1997.
[5]陈子玥,谭银亮,石芳慧,等. 上海市大学生电子烟和卷烟的使用现状及其影响因素[J].环境与职业医学,2020(8).
[6]刘文. 随机条件概率的一个极限性质与条件矩母函数方法[J].应用数学学报,2000, 23(2):275-279.
[作者简介]刘佳,女,汉族,陕西西安人,硕士研究生,工程师,现就职于陕西省烟草公司西安市公司信息中心,研究方向:通信与信息系统、网络安全与信息化。
