
一种结合文章信息的新闻评论情感分析方法
2022-12-02 11:55杨一璞朱永华高海燕高文靖
上海大学学报(自然科学版) 2022年1期
杨一璞,朱永华,高海燕,高文靖
(1.上海大学上海电影学院,上海 200072;2.上海大学生命科学学院,上海 200444)
情感分析是分析人们在文本中所表现出的意见、观点、情感态度的研究领域.如今,互联网快速发展,新闻媒体平台以及各种社交媒体平台每天产生大量的内容,其中包括用户产生的大量评论.对这些信息进行自动的情感分析,在多个方面具有潜在的应用价值.例如,企业可以了解用户对特定事件和话题的态度,把握公众意见,及时掌握舆情以便做出相应的决策.另外,透过对商品和服务相关内容的评价,企业还可以及时了解市场口碑,便于进一步提高产品及服务质量.
传统的情感分析方法大致可以分为基于情感词典的方法和基于机器学习的方法.基于情感词典的方法需要构建由情感词组成的情感词典,通过设计一系列规则,如Turney[1]利用词语间的点互信息(pointwise mutual information,PMI)对文本进行情感分类.这种方法往往高度依赖情感词典的构建以及规则的设计,难以应对隐含的情感内容.而基于机器学习的方法则通过有监督的方式,利用提取的特征训练分类器.机器学习方法在许多任务中的有效性都得以证明,其效果往往依赖于特征工程.近年来,深度神经网络在情感分析以及文本分类等领域得到了应用.与传统机器学习方法中特征往往比较稀疏的情况不同,深度神经网络的方法将文本转换成密集向量,并将所获文本的高层表示用于分类.
就新闻评论或微博评论等内容而言,现有的方法往往只集中于对评论文本本身的分析.这些评论具有篇幅普遍较短的特性,如果仅利用其文本内容进行特征提取可能不足以充分利用其语义以及背景信息.对于新闻事件而言,不同话题或主题往往对评论的情感基调有一定影响,因此引入评论的源文章信息就具有现实意义.本工作提出了一种基于支持向量机(support vector machine,SVM)和K均值(K-means)聚类的情感分类模型,并且将词频-逆文档频次(term frequency-inverse document frequency,TF-IDF)特征融入词袋特征.实验结果表明,本方法相较于其他传统方法有较好的分类效果,同时证明了采用K-means聚类的方法引入文章信息可以提升分类效果.
1 相关研究
文本分类是自然语言处理中的重要研究内容,而情感分析则被认为是文本分类的一个分支.情感分析的目的是识别文本中所表达的整体情感,这些文本可以是网络评论、文章、微博等内容.传统的方法通常通过有监督的方式,利用词袋(bag-of-words,BoW)模型训练分类器.Pang等[2]利用unigrams和SVM取得了比其他方法更好的分类效果;Gamon等[3]利用自然语言分析工具获得了深层语言结构特征,并将其加入其他表层特征,提升了分类的准确率.此外,基于词典及规则的方法也得到广泛应用,这种方法往往依赖于情感词典的构建以及规则的设计.吴杰胜等[4]构建了包括表情符号词典在内的多部情感词典,并设计了转折、递进、假设等句间分析规则以及句型分析规则,将情感词典与规则集结合,实现了对中文微博的情感分析;王志涛等[5]在情感词典和规则集的基础上,结合表情符号信息,对微博进行情感分析;姜杰等[6]将规则扩展成规则特征,并将其嵌入基本特征,结合机器学习的方法训练情感分析模型;马丽菲等[7]针对影评分类问题构建了电影领域的本体,对特征词进行扩展,以决策树作为分类器对扩展后的特征进行训练,显著提升了分类的准确率.
近年来,由于深度神经网络具有较强的特征提取能力,多种基于深度神经网络的情感分析方法被提出.在传统机器学习方法中,特征往往具有稀疏以及维度较高的特性.为了解决这一问题,词嵌入(word embedding)[8]将高维特征嵌入到一个维度较低的连续向量空间,每个单词被表示为实数域上的一个向量.这些特征向量是通过连续词袋模型(continuous bag-of-words,CBoW)、Skip-gram等算法在大规模语料训练所得到,其中受到最广泛应用之一的word embedding模型就是Word2Vec模型[9],许多方法都通过该模型获得词向量,并将其作为文本的表示.Kim[10]利用卷积神经网络(convolutional neural network,CNN)在预训练的词向量的基础上进行句子分类任务,包括情感分析任务以及问题分类任务;朱晓亮等[11]首先利用TextRank算法对文本进行关键句提取并去除冗余信息,然后利用词向量表示提取关键句后的文本,将其作为字符级卷积神经网络的输入,训练分类模型.不同于以上方法,Johnson等[12]直接将CNN应用于高维的one-hot向量,学习小范围文本区域的embedding,利用单词顺序提升文本分类的效果.为了获取文本中较长序列的语义信息,诸如循环神经网络(recurrent neural network,RNN)及其变体的序列模型也被应用于情感分类任务[13-19],然而在缺乏大量训练数据的情况下,这些深度模型不能很好地拟合.
本工作提出的基于SVM的新闻评论情感分析模型,利用了bag-of-ngrams特征并与TFIDF特征相结合,同时引入评论的源文章信息作为特征的补充,通过聚类将源文章主题对新闻评论的影响引入评论文本的情感分析.
2 方法介绍
2.1 模型框架
本工作针对新闻评论的情感分析,构造并结合多种特征,提出了基于SVM和K-means的情感分类模型.该模型的具体流程如图1所示.
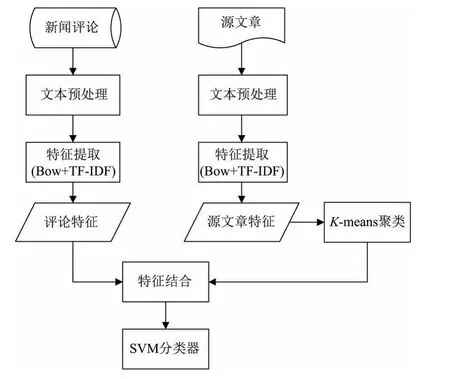
图1 本模型框架图Fig.1 Framework of this model
首先,对新闻评论以及评论的源文章分别进行文本预处理,包括去掉重复的、存在空值的数据,去除数据中无意义的符号,单词小写转换以及去停用词等步骤,得到清洗后的数据进行下一步特征提取.其次,特征提取部分通过BoW词袋模型对文工作进行特征表示;并结合TF-IDF赋予特征权重,分别得到评论文本与源文章文本的向量特征表示.然后,将K-means聚类算法应用于所得的源文章特征向量,得到文本的聚类信息,并将其作为附加特征与评论文本的特征结合.最后,将结合后的特征与情感标签一起作为输入,训练SVM分类器;将测试数据输入训练好的SVM分类器,即可得到预测的情感标签.
2.2 特征提取
BoW是常见的通过向量的方式表示文本特征表示方法.向量的维度是根据文本所构建的词典大小,向量每一个维度表示文本中每个单词出现的频次.然而,这种方法无法表示文本中单词的顺序,使得语义会有一定损失,因此往往采取与n-gram结合的方式进行特征表示,这也称为bag-of-ngrams.这样的特征表示方式仍然存在不足,一些单词虽然在语料中出现的频率很高,但是其本身并没有太多语义信息,因此本工作采用结合TF-IDF的方式,给特征分配不用的权重,以此形成更高效的特征表示.
TF-IDF算法是一种在信息检索领域常用的算法,用来衡量由大量文本构成的语料库中一个词对于某篇文本的重要程度.单词i在文本j中的权重值为
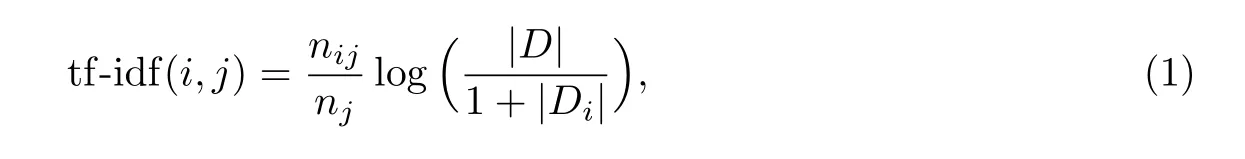
式中:nij为单词i在文本j中出现的频次;nj为文本j的单词总数;|D|为语料库中文本总数;|Di|为语料库中包含单词i的文本数量.
2.3 K-means聚类
聚类是一种无监督学习方法,可以将无标签的数据自动划分为几类.在得到源文章的特征后,本工作使用聚类算法对源文章数据进行划分.新闻评论表达的是用户对新闻所描述事件的态度与看法,因此新闻的主题或话题内容会对评论的整体情感基调有不同的影响.本工作通过K-means聚类的方式,将源文章信息引入新闻评论的情感分析模型,以便构建更丰富的特征,提升情感分析的效果.K-means算法可以分为如下几个步骤:
(1)从源文章特征向量中随机选取K个特征向量,代表K个簇的初始质心;
(2)计算每一个数据点到K个质心的距离,并将数据点分配到距离自身最近的质心所在的簇中;
(3)将所有数据点完成划分后,计算每一个簇所有数据点的平均值,将其作为新的质心;
(4)重复(2)、(3)这2个步骤直至数据点划分趋于稳定.
经过聚类后,源文章特征被划分至K个簇中.同一个簇中的文章在主题或语义上有更高的相似度,而不同簇之间的文章则在主题和语义上有更大的区分度.通过聚类的方式,就不需要对源文章主题类别进行额外标注,即可完成对源文章类别的划分.完成划分后的类别信息即可作为特征,与新闻评论特征进行进一步结合,提升分类器的效果.
2.4 SVM多分类策略
SVM是经典的有监督机器学习方法,可用于线性和非线性分类.原始的SVM只适用于二分类,对于多分类任务则需要采用相应的策略.常见的多分类策略有一对一(one vs.one,OVO)法和一对多(one vs.rest,OVR)法.
一对一法对每2个类别样本设计一个分类器,对于n个类别的样本,则需要设计个分类器.一对多法则对含有n个类别的样本构造n个分类器,在每个分类器在处理样本时将某一个类别归为一类,将其余样本全部归于另一类.本方法所采用的SVM为基于一对多策略的线性SVM.
3 实验
3.1 实验设置
为了验证本模型的有效性,本工作采用了Yahoo Labs Webscope的英文数据集Yahoo News Annotated Comments Corpus(YNACC)[20-21],并选取了其中带有情感标签的新闻评论数据作为数据集.情感标签分为4个类别,分别为正向、负向、中立以及混合类别.利用这些情感标签即可进行有监督的情感分类.数据集中也包含了新闻评论源文章的URL信息,本工作根据其提供的地址获得了部分源文章信息,部分信息由于网址失效未能获取.
此外,评论数据存在一定程度的类别不平衡问题,即评论数据中的情感类别标签存在比较明显的分布不均衡现象.针对这一问题,本工作采用了过采样的方式,分别尝试了合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)和随机过采样算法,增加少数类样本.经过过采样处理后的数据统计信息如表1所示.

表1 数据集统计信息Table 1 Statistics information of the dataset
针对数据集中的文本,本工作使用NLTK工具包进行去除符号、去停用词等预处理,将数据集中的数据按照4∶1的比例划分为训练集和测试集.
实验采用的评价标准为Precision、Recall、F1值和Accuracy这4个指标,计算公式分别如(2)~(5)所示,其中TP(true positive)表示为实际为正类、预测也为正类的样本数量;FP(false positive)表示为实际为负类、预测为正类的样本数量;FN(false negative)表示为实际为正类、预测为负类的样本数量;TN(true negative)表示为实际为负类、预测也为负类的样本数量:

由于本实验为多分类任务,故对以上Precision、Recall、F1值这3个评价指标取Macro平均值,即先对每一个类计算指标值,然后对所有类的指标取算数平均值;Accuracy则取值为被正确分类的样本数除以所有样本数.
3.2 实验结果及分析
对本工作提出的基于SVM和K-means聚类的情感分析模型和其他baseline模型进行对比,并对实验结果进行分析.涉及的方法如下:
AvgWordvec:将word2vec预训练模型[9]的词向量作为单词的特征表示,将评论中所有单词的词向量均值作为评论文本的特征,输入到SVM分类器中进行训练;
K-means+uni:使用unigram词袋特征表示评论文本,加入TF-IDF权重信息,并使用Kmeans对源文章进行聚类,得到源文章特征,最后利用结合后的特征训练SVM分类器;
K-means+bi:使用bigram二元词组作为评论文本特征,将TF-IDF权重信息与特征结合进行加权,并使用K-means对源文章进行聚类,得到源文章特征,最后利用结合后的特征训练SVM分类器;
K-means+tri:以trigram三元词组作为评论文本特征,利用TF-IDF权重信息对获得的评论文本特征进行加权,并使用K-means对源文章进行聚类,得到源文章特征,最后利用结合后的特征训练SVM分类器;
K-means+uni+bi:使用unigram和bigram作为评论文本特征,利用TF-IDF权重信息对获得的评论文本特征进行加权,并使用K-means对源文章进行聚类,得到源文章特征,最后利用结合后的特征训练SVM分类器;
uni+bi+tri:和本方法的区别是此方法未使用K-means聚类,仅使用unigram、bigram和trigram作为评论文本特征,并加入TF-IDF权重信息,训练SVM分类器;
K-means+uni+bi+tri:本工作提出的基于SVM和K-means的情感分析方法,除使用unigram、bigram和trigram多重特征对评论进行表示外,还加入TF-IDF权重信息,对特征进行加权,并使用K-means聚类对源文章特征进行表示,将其与评论特征进行结合后,使用SVM进行模型训练.
表2为不同方法的实验结果对比.
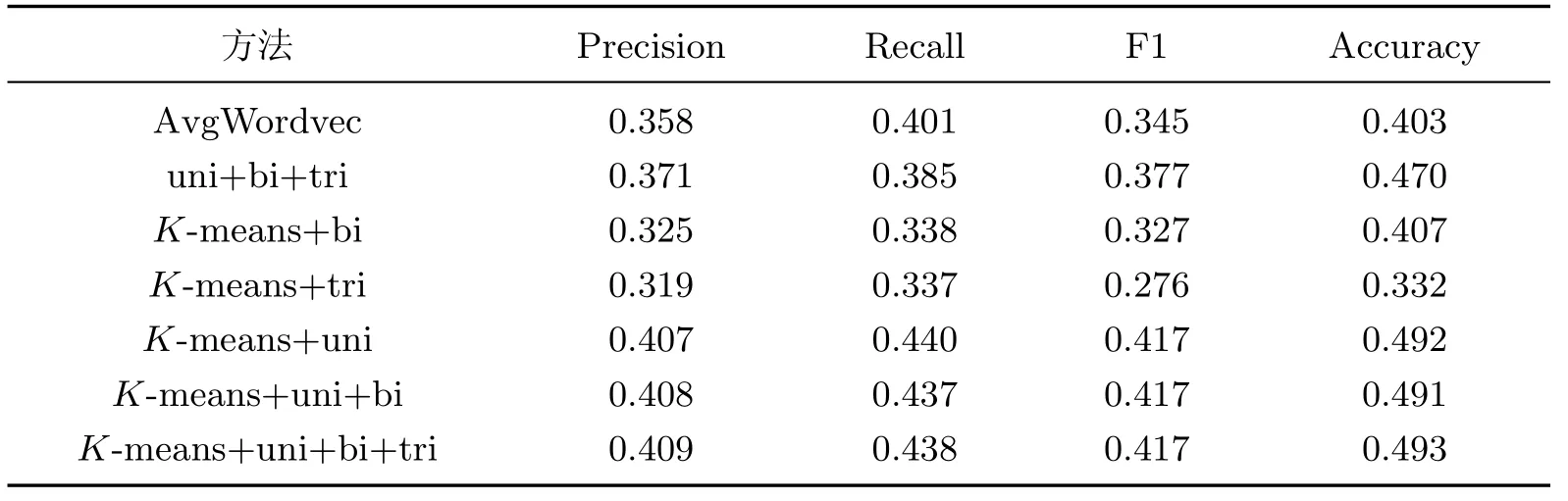
表2 不同方法的实验结果对比Table 2 Comparison of different experimental results
表2的结果表明,本工作提出的基于SVM和K-means聚类的情感分析模型取得了优于其他方法的效果.在所有未使用K-means聚类的方法中,AvgWordvec的分类效果最不理想.该方法使用预训练的词向量对单词进行表示,并将单词词向量的均值作为评论的特征,未能表示单词的顺序信息,使得部分语义信息缺失.相比之下uni+bi+tri方法的效果有明显提升,该方法在词袋模型的基础上结合了二元词组和三元词组特征,在一定程度上保留了单词出现的顺序信息,TF-IDF特征的加入使得模型能够根据各个单词和词组的重要程度对特征进行加权,提升分类的效果.
在使用了K-means聚类对源文章特征进行表示,并与评论特征进行结合的所有方法中,K-means+tri的效果最差,K-means+bi方法其次.这2种方法分别只考虑了三元词组特征和二元词组特征,特征表示过于单一,缺失了评论文本的基础语义信息.K-means+uni的方法相比于只使用bigram的方法F1值提高了10.2%,Accuracy提高了8.5%.对比只使用trigram的方法,该方法的F1值提高了14.1%,Accuracy提高了16%,在同样采取单一特征的情况下,该方法效果有明显的提高,体现了unigram特征对区分文本的重要性.K-means+uni+bi方法在该方法的基础上加入了bigram特征,效果没有明显变化,说明unigram对于评论文本而言可以表示更为基本的语义信息.而在此基础上加入bigram和trigram的方法在各项评价指标上有略微提升,体现了多种词组特征对于文本语义有补充作用.
本工作提出的基于SVM和K-means聚类的情感分析方法取得了上述对比方法中最优的分类效果.在与uni+bi+tri方法的对比中,本方法在F1值上提升了4%,在Accuracy上提升了2.3%,证明了通过K-means方式能够对新闻评论的源文章信息进行分类表示,并与新闻评论特征和结合,可以提升分类的准确率,证明了本方法的有效性.
3.3 变量分析
为了研究在在进行Bag-of-ngrams特征构造时,不同特征维数对分类效果的影响,本工作对采用不同特征维数的模型进行了对比实验(见表3).
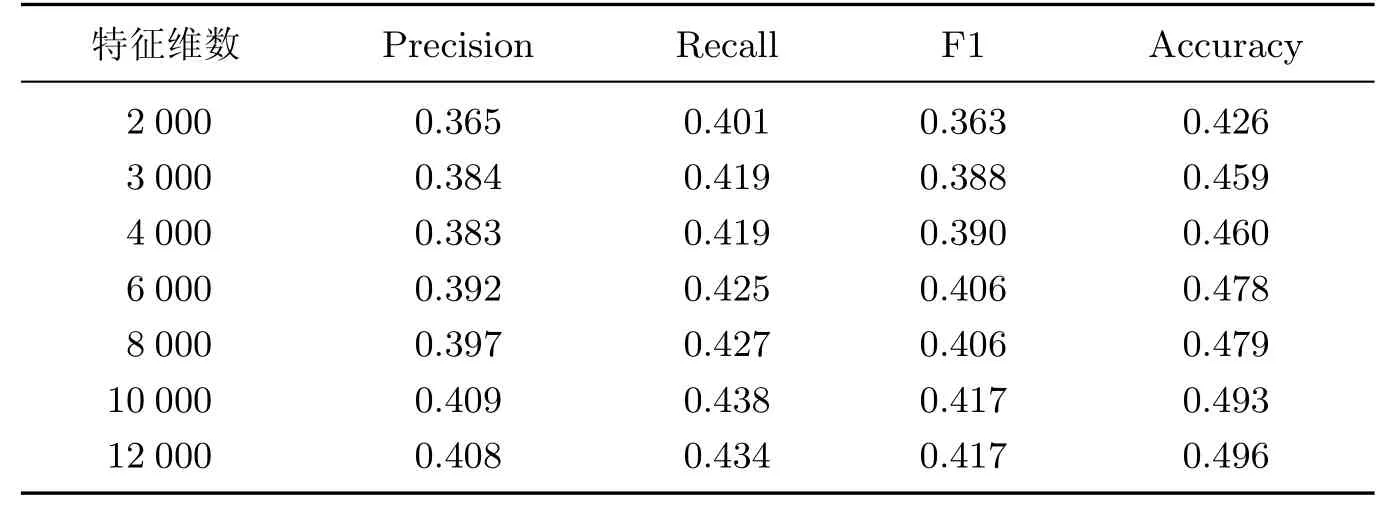
表3 特征维数对实验结果影响Table 3 Impact of feature dimension on experimental results
结果表明,模型的F1值和Accuracy这2项指标随着特征维数的增加而提高,当特征维数达到10 000时2项指标趋于稳定;而Precision及Recall在特征数取10 000时达到最高值,之后随着特征维度升高趋于稳定并略有下降.因此,本方法将特征维数确定为10 000.
考虑到SVM分类器参数对实验结果的影响,本工作同时对SVM分类器的参数C进行了不同设置,对不同参数下模型分类效果进行对比(见图2).
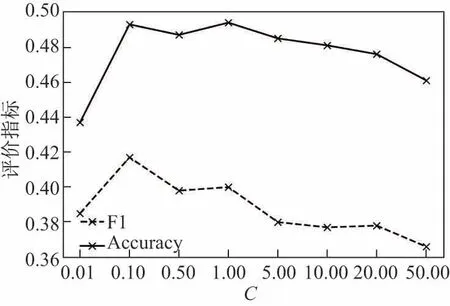
图2 分类器参数C对分类效果的影响Fig.2 Impact of parameter C on classification performance
实验结果显示,模型在C取值较小时有更好的分类效果;当C取值大于1.00时,分类效果随参数的增大而变差.根据实验结果,本方法将SVM分类器的参数C设置为0.10.
在对文章进行K-means聚类的过程中,K值的选取对聚类效果有很重要的影响.好的聚类结果能使同一簇内的数据有更大的相似性,即同一簇内的文章具有更相似的主题或语义信息.因此,聚类的结果将影响到最终评论特征的质量以及模型最终的分类效果.本工作通过实验对比了K-means聚类方法中K取不同值时模型的最终效果(见图3).
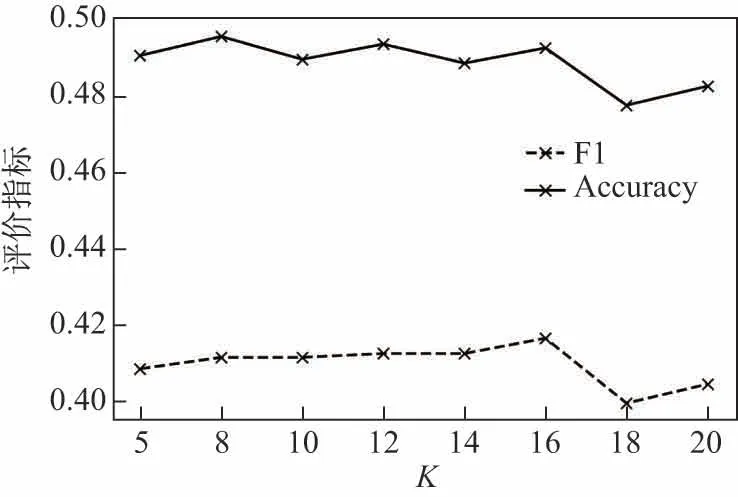
图3 不同K值对分类效果的影响Fig.3 Impact of different K values on classification performance
实验结果显示,Accuracy随K值的增大呈小范围浮动,F1值随K取值的增大而增大;当K值大于16时,2项指标均有明显下降.因此,根据实验结果本工作将K值设置为16.
4 结束语
本工作提出了一种基于SVM和K-means聚类的新闻评论情感分析方法.考虑到新闻文章主题或话题内容对其评论情感产生的影响,本方法通过K-means聚类的方式对新闻文章进行簇的划分,将这种主题或语义的差异进行表示,并结合新闻评论特征训练SVM分类器.实验结果表明,该方法取得了优于其他对比方法的效果,证明了采用K-means聚类的方法引入文章信息可以提升分类效果,验证了该方法对于新闻评论情感分析的有效性.此外,构造更低维度和更高效的特征来提升方法的分类效果,也是需要进一步研究的内容之一.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电子产品世界(2022年4期)2022-04-21
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
