
空间通道双重注意力道路场景语义分割
2023-03-16 12:54王小玉林鹏
哈尔滨理工大学学报 2023年5期
王小玉 林鹏

摘 要:无人驾驶领域的一个重要问题就是在低功耗移动电子设备上怎样运行实时高精度语义分割模型。由于现有语义分割算法参数量过多、内存占用巨大导致很难满足无人驾驶等现实应用的问题,并且在影响语义分割模型的精度和推理速度的众多因素中, 空间信息和上下文特征尤为重要,并且很难同时兼顾。针对该问题提出采用不完整的 ResNet18 作为骨干网络,ResNet18 是一个轻量级的模型,参数量较少,占用内存不大;同时采用双边语义分割模型的技术,在两条路径上添加通道空间双重注意力机制,来获取更多的上下文信息和空间信息的想法。另外还采用了精炼上下文信息的注意力优化模块,和融合两条路径输出的融合模块,添加的模块对于参数量和内存的影响很小, 可以即插即用。以 Cityscapes 和 CamVid 为数据集。在Citycapes 上, mIoU 达到77.3%;在 CamVid 上,mIoU 达到66.5%。输入图像分辨率为1024×2048时,推理时间为37.9ms。
关键词:无人驾驶;实时语义分割;深度学习;注意力机制;深度可分离卷积
DOI:10.15938/j.jhust.2023.05.013
中图分类号: TP391.41
文献标志码: A
文章编号: 1007-2683(2023)05-0103-07
Semantic Segmentation of Unmanned Driving Scene
Based on Spatial Channel Dual Attention
WANG Xiaoyu, LIN Peng
(Harbin University of Scienceand Technology,Computer Scienceand Technology,Harbin 150080,China)
Abstract:An important issue in the field of unmanned driving is how to run real-time high-precision semantic segmentation models on low-power mobile electronic devices. Existing semantic segmentation algorithms have too many parameters and huge memory usage, which makes it difficult to meet the problems of real-world applications such as unmanned driving. However, among the many factors that affect the accuracy and speed of the semantic segmentation model, spatial information and contextual features are particularly important, and it is difficult to take into account both. In response to this problem, it is proposed to use the incomplete ResNet18 as the backbone network, design a bilateral semantic segmentation model, and add a channel space dual attention model to the two paths to obtain more contextual and spatial information. In addition, the attention optimization module that refines the context information and the fusion module that integrates the output of the two paths are also used. Take Cityscapes and CamVid as data sets. On Citycapes, mIoU reached 77.3%; on CamVid, mIoU reached 66.5%.When the input image resolution is 1024×2048, the segmentation speed is 37.9 ms.
Keywords:driverless technology; real-time semantic segmentation; deep learning; attention mechanism; depth separable convolution
收稿日期: 2022-04-04
基金項目: 国家自然科学基金(61772160);黑龙江省教育厅科学技术研究项目(12541177).
作者简介:
林 鹏(1997—),男,硕士研究生.
通信作者:
王小玉(1971—),女,教授,硕士研究生导师, E-mail:wangxiaoyu@hrbust.edu.cn.
0 引 言
随着人工智能与汽车交通的结合, “自动驾驶” 热潮被掀起,如何准确、快速地检测路况、路标等信息成为目前研究的热点目标[1]。许多研究人员逐渐将注意力转向了对道路场景的理解。主要领域之一是道路场景的语义分割[2]。
基于深度学习的图像语义分割作为计算机视觉中的一项基本任务,旨在估计给定输入图像中所有像素的类别标签,并呈现出不同颜色区域掩模的分割结果。
2014年,文[2]提出的全卷积神经网络(FCN),被誉为深度卷积神经网络的奠基之作,标志着分割领域正式进入全新的发展时期。与之前所有图像语义分割算法最大的不同在于,FCN 用卷积层代替分类模型中全部的全连接层,学习像素到像素的映射。并且,提出了在上采样阶段联合不同池化层的结果,来优化最终输出的方法[2]。目前很多的优秀的基于深度学习的图像语义分割算法都是基于 FCN 的思想实现的[3]。2015 年, 剑桥大学在 FCN 的基础上,实现了突破,提出了 SegNet 模型[3]。从那时起,更多的语义分割算法被开发出来,并且分割的准确性一直在提高,如deeplab 系列[4],多路级联模型(refinenet)[4]和 PSPNet 等[5]。
近年来,深度学习在图像语义分割方面有了很大的进步。在自动驾驶等领域有着很大的应用潜力。但是算法模型大多关注对图像分割准确率的提升,其计算成本和内存占用较高,模型的实时性得不到保证[6]。在许多实际应用中,对于模型的实时性也有很高的要求。根据这一需求,目前最常用的 ENet,MobileNet 系列也随即被提出[7]。实时进行语义信息分割技术逐渐分化一个新的领域。
在实时语义分割的任务中,为了提高推理速度,有的模型采取缩小图片尺寸的操作,有的采取删减特征图通道的操作,但是这些操作都会丢失一些空间信息[7]。这是因为初始图像经历了多次卷积和池化,最终导致初始图片被模型加载后,特征图的分辨率由大变小。对于分割任务来说,获取丰富的上下文信息和空间信息、高分辨率的特征、深层特征的语义信息,可以更好地提高模型的分割精度[8]。
近年来,在实时语义信息分割算法中,双边分割网络算法(BiSeNet)在语义分割任务上获得了瞩目的成绩[9]。本文在 BiSeNet 的基础上,上下文路径以轻量化模型 ResNet18 作为骨干网络。引入两个空间通道
双重注意力机制CBAMT和CSSE模块。通过在上下文路径的轻量型特征提取网络引入 CBAMT 模块,从空间和通道两个维度来判断应该学习什么特征[10]。然后使用注意力优化模块(ARM),强化对轻量型特征提取模型不同阶段的特征学习[11]。通过在空间路径引入CSSE 模块获取更多的空间特征,并且可以利用深度可分离卷积减少参数量。最后使用特征融合模块(FFM) 将两条路径的输出进行融合。
1 本文算法
BiSeNet其结构如图1所示,双边分割网络设计有2条支路结构:空间支路和上下文支路。空间支路解决空间信息的缺失;上下文支路解決感受野小的问题,获取丰富的上下文信息[12]。两条路径采取的方法分别为:在空间支路中,输入的图像经过三层由大卷积核组成的卷积层的卷积,将输入图像压缩成原图尺寸 1/8 的特征图,这样就保留丰富的空间信息。并且这些卷积层的卷积核都是小步长的,经过这些卷积层的学习,最终可以生成高分辨率的特征[13];在上下文支路中,将全局平均池化添加到支路中,获取最大的感受野。并且还添加注意力机制来指导特征学习。
1.1 基于空间和通道的双重注意力机制单元
文[3]提出一种轻量的空间通道双重注意力机制 CBAM,
可以在通道和空间维度上进行注意力关注[14]。CBAM 由两个单独的子模块组成,分别是通道注意力模块(CAM)和空间注意力模块(SAM)。前者是关注于通道,后者是关注于空间。这样的优点是不仅可以很好地的控制模型的参数量,并且能够将其加入到当前已有的模型结构中。总之,CBAM 是一种随插随用的模块。
1.1.1 CAM
对输入的特征图 G(H×W×C)分别进行基于宽高的整体最大池化和平均整体池化,得到两张 1×1×C特征的图像。 然后将它们发送到一个双层神经网络(MLP),这个双层神经网络是共用的[15]。第一层神经元个数为C/r(r为减少率),激活函数为Relu; 第二层神经元个数为 C。 然后将MLP 输出的特征相加并由 sigmoid 激活。生成最终的通道注意特征图 M_c。最后,用乘法将 M_c 和输入特征图 G 相乘。生成的特征图即为空间注意力机制模块需要的输入特征图G′。
1.1.2 SAM
SAM将 G′作为输入特征图。首先进行以通道为基础的最大全局池化和平均全局池化。然后将两个特征图H×W×1拼接操作,即通道拼接。经过 7×7 卷积,降维为一个通道,即H×W×1。随后由 sigmoid函数生成特征图G″。最后将 G″和 G′进行乘法操作,生成最后的特征图。
1.2 改进的空间支路
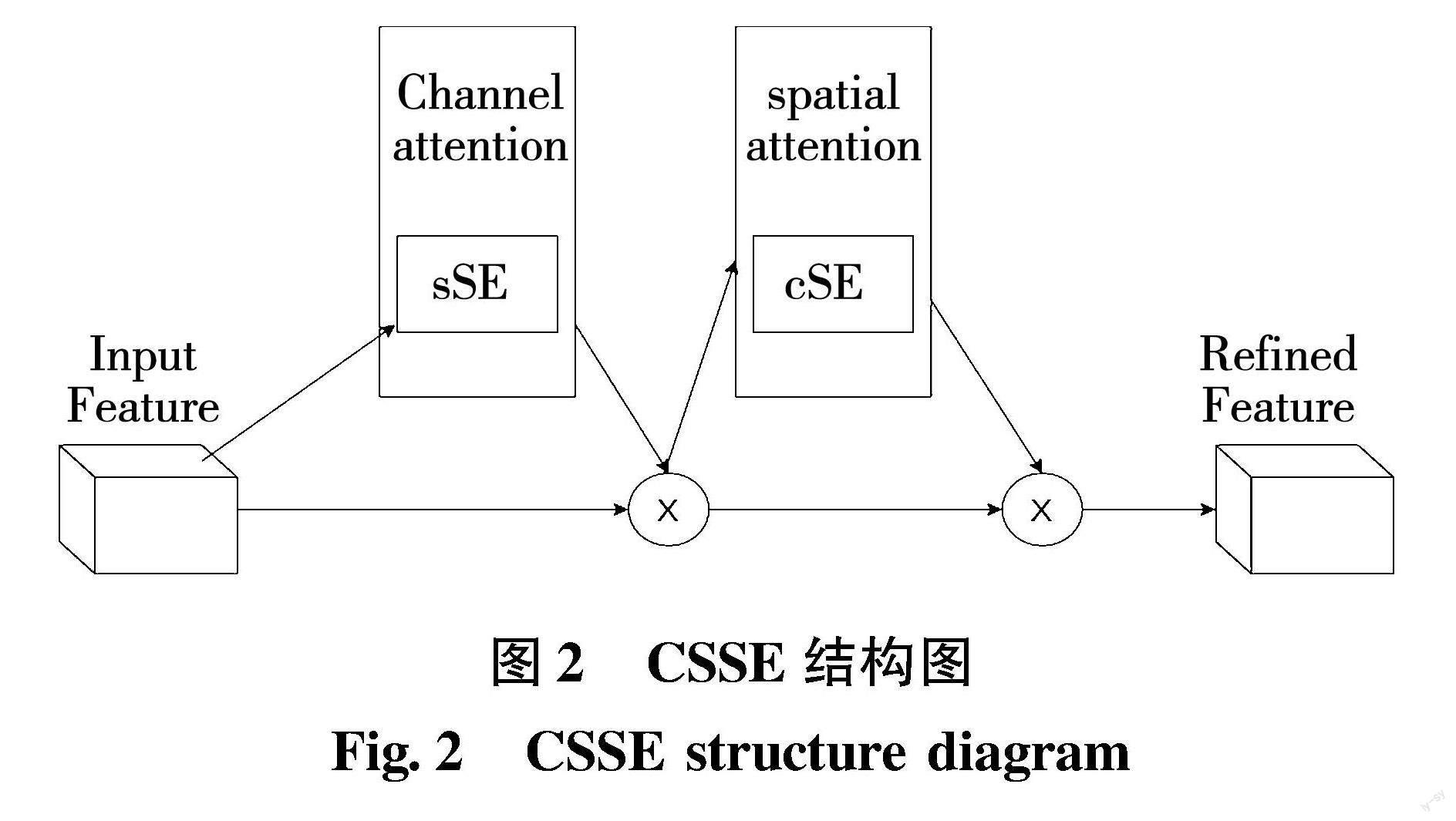
为了使语义分割模型有更好的分割效果,可以通过将低级的空间特征和庞大的深层语义信息相结合来提高模型的分割精度[15]。本文提出的空间路径是由 3 个卷积组成。第一层包括一个步长为 2 的卷积,剩下两层是步长为 1 的深度可分离卷积[15]。然后是批标准化(BN) ,和以线性整流函数(ReLU) 作为激活函数。此外本文还在空间路径上添加通道空间模块(CSSE)。具体算法如下:特征图 H×W×C 经过全局平均池化,得到特征图 1×1×C。然后经过两个 1×1×1 的卷积处理,最终得到一个 C 维向量。 然后用 sigmoid 归一化函数得到对应的 mask,最后乘以通道分组得到信息校准后的 M′特征图。sSE 模块类似于 SAM。具体过程是直接在特征 M′(H×W×C)上使用 1×1×1,将特征图 M′卷积成为 H×W×1 的特征图。然后用 sigmoid 进行激活得到空间特征图。最后应用它直接对原始特征图完成空间信息的校准。CSSE 模块是将 cCE模块和 sSE 模块以串联的方式连接,并且通过实验证明,
组成的 CSSE 对模型的分割效果的也有提升。CSSE结构如图2所示。
1.3 改进的上下文支路
在原始模型中,为了可以有更大的感受野和更多的语义信息, BiSeNet 设计了 Context path[15]。并且使用 Xception 作为特征提取的骨干网络[16]。Xception 可以快速缩小特征图以获得大感受野,来编码高级语义上下文信息[16]。本文提出的改进的上下文路径使用轻量级模型 ResNet18 作为特征提取骨干网络,并且在路径中额外添加了 CBAMT 模块。
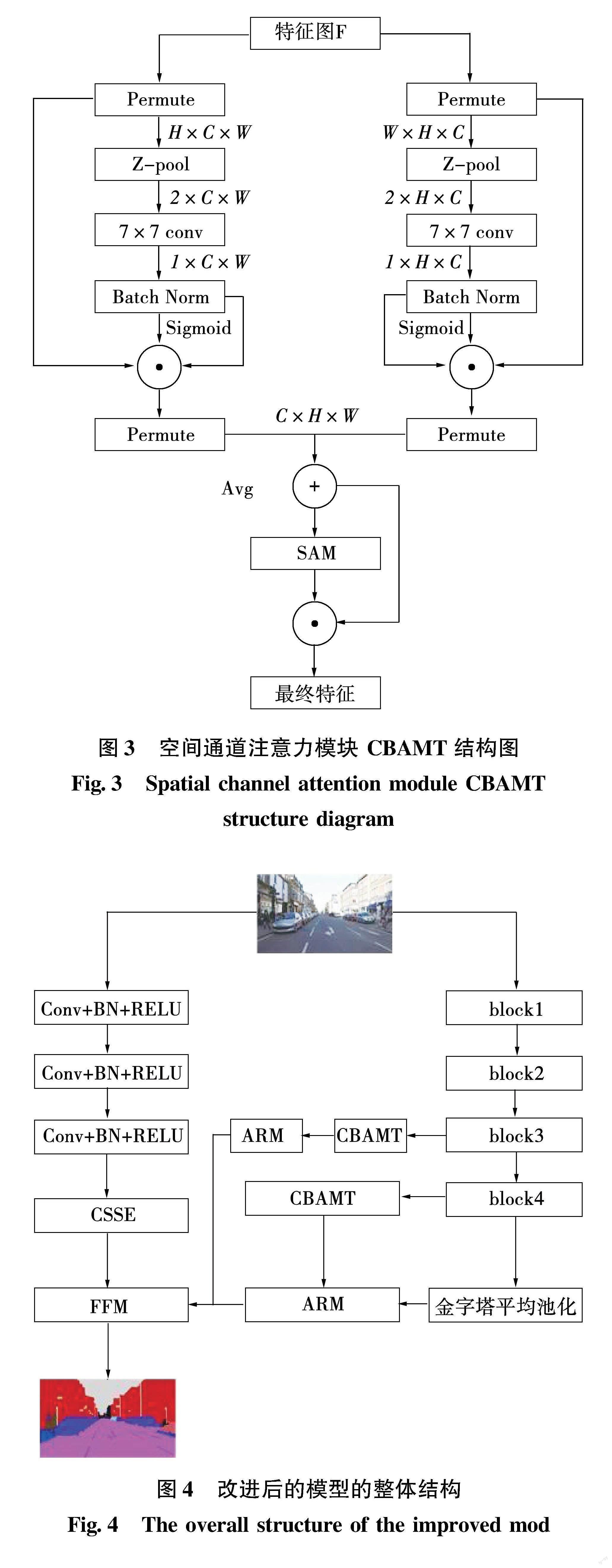
本文的特征提取的骨干网络是由4个block 组成,每个 block 由两个 3×3 的卷积和 BN 层,以及 relu 组成。此外,本文提出的 CBAMT 模块是基于文[6]中提出的一种 triplet attention 方法。该方法使用三重分支结构来捕获维度交互,从而计算注意力的权重,实现通道和空间的交互[16]。
本文提出的改进后的 CBAMT 模块,采用了 triplet attention(三重分支)的思想,三重分支结构 3 个并行分支分支组成,其中两个分支主要负责维度 C 与维度 H 或 W之间的交互[17]。最后一个分支类似于 SAM,用于构建空间感知模块[17]。最后,将所有分支的输出进行平均水平聚合。
CBAMT将 CAM 模块的输出特征图 F′利用两个平行的包含 Z 池化层,用于维度交互的分支,将维度 C 与维度 H 或 W 的维度进行交互,将两个输出结果相加得到特征图F″。然后使用特征图 F″作为 SAM 的输入以得到最终特征。
Z池化层的作用是将维度 H 和 W 的张量减少到 2 维,并将该维度的平均池化特征和最大池化特征聯系起来,这使得该层在减少其深度的同时保持真实张量的丰富表示,这有利于后续计算[18]。最后,改进的上下文路径中保留了全局平局池化结构,这样可以为模型提供全局上下文信息,更好地增强模型分割效果。CBAMT 模块结构如图3,改进后的整体网络模型如图 4 所示,以及 Z-pool 计算:
Mc(F)=σ((AvgPool(F),MaxPool(F))(1)
式中:F为输入特征图;σ为 sigmoid 激活函数;AvgPool和MaxPool分别表示全局平均池化和全局最大池化,f7x7表示卷积操作时,卷积核大小为7。
1.4 特征融合模块(FFM)
特征融合模块的功能是把来自空间支路的特征和上下文支路的特征融合[18]。之所以需要 FFM 来融合两者,是由于前者是低层次的特征,后者是高层次的特征[18]。具体流程:将来自空间支路和上下文支路的特征进行向量拼接的操作,得到特征图 H,然后对特征图 H 进行全局平局池化,得到 1×1×C 向量。最后通过类似 SENet 中的通道权重相乘,对特征图 H 重新进行加权,得到最后的特征图 H′。图5显示了该模块的结构。
1.5 注意力优化模块(ARM)
原始模型还针对上下文路径设计了 ARM,如图6所示。首先为了获得整体上下文语境信息,使用全局平局池化。来帮助模型学习特征,来强化特征提取网络不同阶段的特征学习。此外还可以简单地完成整体上下文语境信息的集成。并且不必利用上采样,计算成本可以忽略不计。
1.6 注意力优化模块(ARM)
上下文路径中添加了两个辅助损失函数来更好地监督输出。主损失函数和辅助损失函数都使用 Softmax函数为式(2)[19]。辅助损失函数监督模型的训练,主损失函数监督整个 BiSeNet 的输出(Lp)。添加两个特殊的辅助损失函数监督 Context Path 的输出(Li)借助参数 α 以平衡主损失函数与辅助损失函数的权重,如式(3):
Loss=1n∑ili=1n∑ilogepi∑iepi(2)
L(X|W)=lp(X:W)+α∑Kili(Xi:W)(3)
其中:lp为主要的 loss;li为辅助的 loss;Xi为ResNet第 i 个阶段的输出特征;
K=3,ɑ为1。在训练过程中,只使用了辅助 loss 进行训练。
2 实验结果与分析
2.1 数据集
本文使用两个数据集,均是城市道路场景数据集,分别为 Cityscapes 数据集和 CamVid 数据集。这两个数据集是道路场景语义分割中最常用来进行模型评估的数据集[19]。CamVid 数据集有 11 个类别;而 Cityscapes 包含两类,一类是 5000 张带有高质量像素级标签的精细图像,一类是 20000张带有粗糙标签的附加图,本实验使用的是Cityscapes 中 5000 个高质量像素级标签的精细图像进行实验。最后从速度即推理时间以及精度两个方面与Baseline 模型进行对比,分析模型的分割性能,并且通过可视化结果展示模型的分割性能。
2.2 参数设置
本文实验环境为 Win10 操作系统,Nvidia RTX 1080Ti 6GB,Python3.9编译环境,Pytorch1.9 框架。具体参数为“bitchsize=8,momentum =0.9,weightdecay=5×10-4。采用“poly”学习率,power=0.9。本文采取随机梯度下降优化算法(SGD)进行模型训练,并使用“poly”学习策略,其公式为:
η=η*(1-itermax_iter)power(4)
其中:初始学习率为 2.5×10-2。iter 是当前的迭代次数; max_iter 是总迭代次数[19] 。设置为1000(即产生1000个 epoch)。功率值固定为 0.9;主要和次要损失平衡参数设置为 1。
2.3 消融实验
本文还做了在相同条件下CBAMT 和 CSSE 这两个模块对模型性能的提升的有效性试验结果见表 1。从表1可以看出,CBAMT 和 CSSE两个模块均可以提高模型分割精度,而且CBAMT 的提升效果要优于CSSE。
2.4 算法整体性能分析与比较
本文使用的Baseline模型是个人实现的ResNet18版本的BiSeNet模型。
2.4.1 分割精度
模型性能采用平均交并比(mIOU)来衡量,计算公式为
mIoU=1k+1∑ki=0pii∑kj=0pij+∑kj=0pji-pii(5)
本文算法与其他算法的分割结果的对比如表2所示。由表 2 可见,本文模型的精度与原BiSeNet 对比,在Cityscapes和 CamVid 上分割精度度提高了1.6%和 1.1%。
2.4.2 推理速度
在测试速度实验中,Baseline模型在Cityscapes上的推理时间为21.5ms,在CamVid上的推理时间为35.5ms,结果如表3所示。
本文模型在Cityscapes上的推理时间为37.9ms,在CamVid上的推理时间为24.5ms,证明本文网络本文网络充分满足实时语义分割的要求。
总之,从速度和精度两个方面综合分析,本文提出的模型在Cityscapes和Camvid数据集上,比BiSeNet(Res18)在推理速度与分割精度之间实现了更好的平衡,与ENet相比,在精度得到了显著提升,其次与目前常见的MobileNet1相比,推理時间接近,精度方面有所提升。但是MobileNet1采用分组卷积,同时模型也没有考虑到空间信息,而且模型层数还是较多,而且对硬件要求,比如GPU较高。而且由于分组卷积,导致在多次重复实验中,偶尔会出现分割效果很差的情况,通过查看文献得知,可能与分组卷积会导致模型学废,后续会对这方面继续研究。
2.4.3 可视化结果
本文提出的模型在CamVid上的分割效果以及与Baseline模型的比较如图7所示。首先,前三列图像分别是初始图、标签图和模型的分割效果图。从前三者可以看出,改进后的模型有着很好的分割性能。另外该模型对不同物体的分割效果是有所区别的。其中较大物体的分割效果较好,基本可以准确识别其类别,例如树木。相反,对于很小的物体的分割结果存在一些问题。比如存在部分细小物体没有识别等问题。另外模型同样存在当前大多数实时分割模型对没有标记的物体分割非常混乱的通病。通过观察本文模型与Baseline模型的实际分割效果图(即最后一列图像)的对比,可以看出改进后的语义分割模型的的分割效果优于基础模型。
2 结 论
本文对语义分割算法的准确度和实时性表现进行深入分析,提出了一种空间通道双重注意力道路场景分割模型。在保证分割准确度的同时兼顾模型的实时性。上下文路径的 CBAMT 模块可以获取更多重要的上下文特征信息, 空间路径的 CSSE获取了更丰富的空间信息。实验证明,本文提出的模型在精度和速度的平衡性优于原 BiSeNet 模型。所构建的注意力机制以及轻量级模型对于其他研究者具有参考意义。由于本文算法仅对道路场景数据集进行深入测试,对于其他类别缺乏针对性,在后续研究中,会考虑结合具体图像分割目标进行模型设计,进一步提升模型的实用性能,并且对实际的目标进行研究和测试。
参 考 文 献:
[1] JIA Gengyun, ZHAO Haiying, LIU Feiduo, et al. Graph-Based Image Segmentation Algorithm Based on Superpixels[J]. Journal of Beijing University of Posts and Telecommunications, 2018, 41(3): 46.
[2] 黄福蓉.用于实时道路场景的语义分割算法CBR-ENet[J].中国电子科学研究院学报,2021,16(3):27.
HUANG Furong. Semantic Segmentation Algorithm CBR-ENet for Real-time Road Scenes[J]. Journal of China Academy of Electronic Sciences, 2021,16(3):277.
[3] CANAYAZ M. C+EffxNet: A Novel Hybrid Approach for COVID-19 Diagnosis on CT Images Based on CBAM and EfficientNet[J]. Chaos, Solitons & Fractals, 2021, 151: 111310.
[4] 祖宏亮. 基于模糊聚类的图像分割算法研究[D].哈尔滨:哈尔滨理工大学,2020.
[5] 吕沛清. 基于改进U-Net的肝脏CT图像自动分割方法研究[D].哈尔滨:哈尔滨理工学报.2022:
[6] TANG X, TU W, LI K, et al. DFFNet: an IoT-perceptive Dual Feature Fusion Network for General Real-time Semantic Segmentation[J]. Information Sciences, 2021, 565: 326.
[7] ZHANG R X, ZHANG L M. Panoramic Visual Perception and Identification of Architectural Cityscape Elements in a Virtual-reality Environment[J]. Future Generation Computer Systems, 2021, 118: 107.
[8] A Method to Identify How Librarians Adopt a Technology Innovation, CBAM (Concern Based Adoption Model)[J]. Journal of the Korean Society for Library and Information Science,2016,50(3):
[9] 张立国,程瑶,金梅,等.基于改进BiSeNet的室内场景语义分割方法[J].计量学报,2021,42(4):515.
ZHANG Liguo, CHENG Yao, JIN Mei, et al. Semantic Segmentation Method of Indoor Scene Based on Improved BiSeNet[J].Acta Metrology,2021,42(4):515.
[10]高翔,李春庚,安居白.基于注意力和多标签分类的图像实时语义分割[J].计算机辅助设计与图形学学报,2021,33(1):59.
GAO Xiang, LI Chungeng, An Jubai. Real-time Semantic Segmentation of Images Based on Attention and Multi-label Classification [J]. Journal of Computer-Aided Design and Graphics, 2021,33(1):59.
[11]YIN J, GUO L, JIANG W, et al. Shuffle Net-inspired Lightweight Neural Network Design for Automatic Modulation Classification Methods in Ubiquitous IoT Cyber-physical Systems[J]. Computer Communications, 2021, 176: 249.
[12]RNZ M, AGAPITO L. Co-fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects[C]//2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017: 4471.
[13]CHEN Y C, LAI K T, LIU D, et al. Tagnet: Triplet-attention Graph Networks for Hashtag Recommendation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 32(3): 1148.
[14]任天赐,黄向生,丁伟利,等.全局双边网络的语义分割算法[J].计算机科学,2020,47(S1):161.
REN Tianci, HUANG Xiangsheng, DING Weili, et al. Semantic Segmentation Algorithm for Global Bilateral Networks[J]. Computer Science, 2020, 47(S1): 161.
[15]LI J, LIN Y, LIU R, et al. RSCA: Real-time Segmentation-based Context-aware Scene Text Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 2349.
[16]SAFAE El Houfi, AICHA Majda. Efficient Use of Recent Progresses for Real-time Semantic Segmentation[J]. Machine Vision and Applications,2020,31(6):45.
[17]MARTIN F. Grace, PING Juliann. Driverless Technologies and Their Effects on Insurers and the State: An Initial Assessment[J]. Risk Management and Insurance Review,2018,21(3):1.
[18]WEI W, ZHOU B, POAP D, et al. A Regional Adaptive Variational PDE Model for Computed Tomography Image Reconstruction[J]. Pattern Recognition, 2019, 92: 64.
[19]FAN Borui, WU Wei. Sufficient Context for Real-Time Semantic Segmentation[J]. Journal of Physics: Conference Series,2021,1754(1):012230.
(編辑:温泽宇)
猜你喜欢
作文小学中年级(2022年9期)2022-09-08
科学(2020年3期)2020-11-26
小哥白尼(军事科学)(2020年8期)2020-05-22
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
