
航空发动机性能图像纹理片段划分方法
2023-09-14 05:45蔡舒妤师利中
航空发动机 2023年4期
蔡舒妤,史 涛,师利中
(中国民航大学航空工程学院,天津 300300)
0 引言
航空发动机作为飞机的核心部件,其健康状态和性能极大地影响着飞机的安全,发动机性能数据作为反映其运行状态的重要依据,为异常诊断与预警[1-3]、飞行品质监控与改善[4-6]、排放与环保评测[7-9]等方面的研究提供了重要的数据支持。
近年来,深度学习智能算法为航空发动机的故障诊断提供了新思路,基于性能数据的智能诊断方法成为研究热点。车畅畅等[10]提出了基于深度学习的发动机故障融合诊断模型,利用深度学习模型得出故障分类置信度,后对多次故障分类结果进行决策融合,得出更准确的诊断结果;钟诗胜等[11]分析民航发动机飞行历史数据,结合深度置信网络建立基于不均衡样本驱动的民航发动机故障诊断模型;Zhang 等[12]针对基于卷积神经网络忽略数据的时间序列信息问题,提出了一种基于递归神经网络的旋转机械故障类型识别方法,并在2 个公共数据集上取得了很好的效果;Park 等[13]提出了一种基于深度学习的液体火箭发动机起动瞬态故障检测与诊断方法,建立发动机起动过程中潜在故障类型的数据集,用于训练深层神经网络,并利用实际发射地面试验数据验证了该方法的有效性;Guo 等[14]提出基于混合特征模型和深度学习的无人机传感器故障诊断方法,利用短时傅立叶变换将故障信号变换为相应的时频图,然后利用卷积神经网络提取图像特征,实现了无人机传感器的故障诊断;Chen等[15]针对电气传动系统,提出了一种基于数据驱动和深度学习相结合的方法来处理早期故障;Manjurul I 等[16]提出了一种自适应深度卷积神经网络,利用试验台采集的数据验证了所提出的故障诊断方法的有效性。
然而深度学习在故障诊断领域仍然存在不适应性。基于深度学习的故障诊断方法需要大量高质量的数据,才能取得良好的诊断性能。然而实际的发动性能数据故障样本远远小于正常样本,会影响深度学习模型的检测结果,使诊断模型结果向大样本倾斜[17]。目前解决不平衡故障诊断问题时通常有2 种手段:第1 种是从数据增强方面入手,如利用生成对抗网络(Generative Adversarial Network,GAN)[18-19]生成和原始数据相似的数据样本;第2 种是对数据进行预处理,如采用过采样和欠采样技术来平衡故障数据和正常数据之间的数量差异。然而,通过GAN 进行训练对样本数量要求严苛,训练样本太小会导致模型无法学习到真实样本的分布,训练样本太多会脱离发动机实际工况;对于过采样预处理,会复制少数样本以扩充样本量,但容易出现过度拟合问题,而欠采样预处理减少了大多数类的样本数,难免造成信息丢失。针对以上问题,本文提出航空发动机性能图像纹理片段划分方法。
1 发动机性能图像的纹理特征表示
1.1 发动机性能数据图像化
发动机性能数据图像化通过建立各发动机性能数据值域与RGB 彩色空间的映射关系,将高数据维度的性能参数数据转换为2 维性能图像,保持性能数据的细节,为性能参数之间和性能数据之间的关联分析提供高效、直观的支持。
对于任意发动机性能参数,其性能数据值域空间[imin,imax]与RGB彩色空间[0,255]的映射关系,如图1所示。
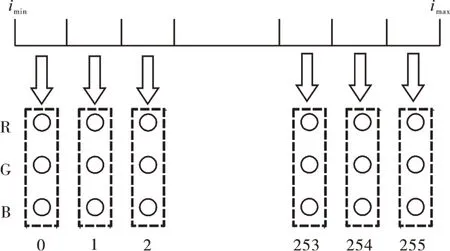
图1 发动机性能数据图像化映射
假设vij表示第i个性能参数在第j个时刻采集的数据值,则vij∈[imin,imax]其中imin为第i个性能参数取值的最小值;imax 为第i个性能参数取值的最大值,则发动机性能数据图像化公式为
式中:RGB为计算所得颜色分量值。
由此转化的性能图像横轴为时间,纵轴为各性能参数取值。
1.2 基于分形盒维的性能图像纹理特征表示
分形维数理论是对非光滑、非规则、非完整等的极其复杂形体定量分析的重要参数,是形体的复杂度、粗糙度的度量[20]。可将分形维数理论引入发动机性能图像的纹理特征表示[21-22]。
假设大小为M×N的发动机性能图像中,任意像素点(x,y) 定义其灰度值函数为I(x,y),均满足I(x,y)∈[0,255],且1 ≤x≤M,1 ≤y≤N。
构建图像的灰度空间,如图2 所示。性能图像灰度空间中,X轴、Y轴分别表示图像像素点的坐标值,Z轴表示图像像素点的灰度值。取边长为ε的分形盒,像素点(x,y)的分形盒维数为

图2 灰度空间
定义像素点(x,y) 处的纹理特征维数为Nε(x,y),即以像素点(x,y)为中心,边长为ε的邻域内像素分形盒维数最大值和最小值的差值
纹理特征维数如图3所示。

图3 纹理特征维数
纹理特征维数表示了像素点ε-邻域内的纹理特征,通过图像化方法将独立且离散的性能数据相融合。这种融合既包含了不同参数间的关联,同时包含了不同时刻参数的关联。
2 基于高频次生长树的图像纹理片段划分
发动机性能图像中,纹理片段出现的不同频次表征了性能状态的不同。高频次纹理片段体现性能的稳定,低频次纹理片段体现性能的波动。可通过对性能状态频次的提取,实现高低频次纹理图像纹理片段的划分。
2.1 高频次生长树理论
依据发动机性能数据特点,性能图像中的每一列对应于飞机某时刻各参数的性能状态,每一行对应于某个参数各飞行时刻的性能状态。可通过性能图像每列像素的纹理特征维数表示图像性能状态。
式中:k为图像性能状态的列数,1 ≤k≤N。
高频次生长树理论如图4 所示。将发动机性能图像中每个性能状态定义为1 颗种子,其初始状态为,计算该性能状态在图像中出现的频次Pk。当频次Pk大于等于一定阈值T时,种子开始第1轮生长;第n轮生长可表示为当频次Pk小于一定阈值T时,种子则停止生长。该过程持续进行,直至所有种子停止生长。

图4 高频次生长树
2.2 基于高频次生长树的图像纹理片段划分算法
本文提出一种基于高频次生长树的图像纹理片段划分算法建立数据集,算法流程如图5所示。
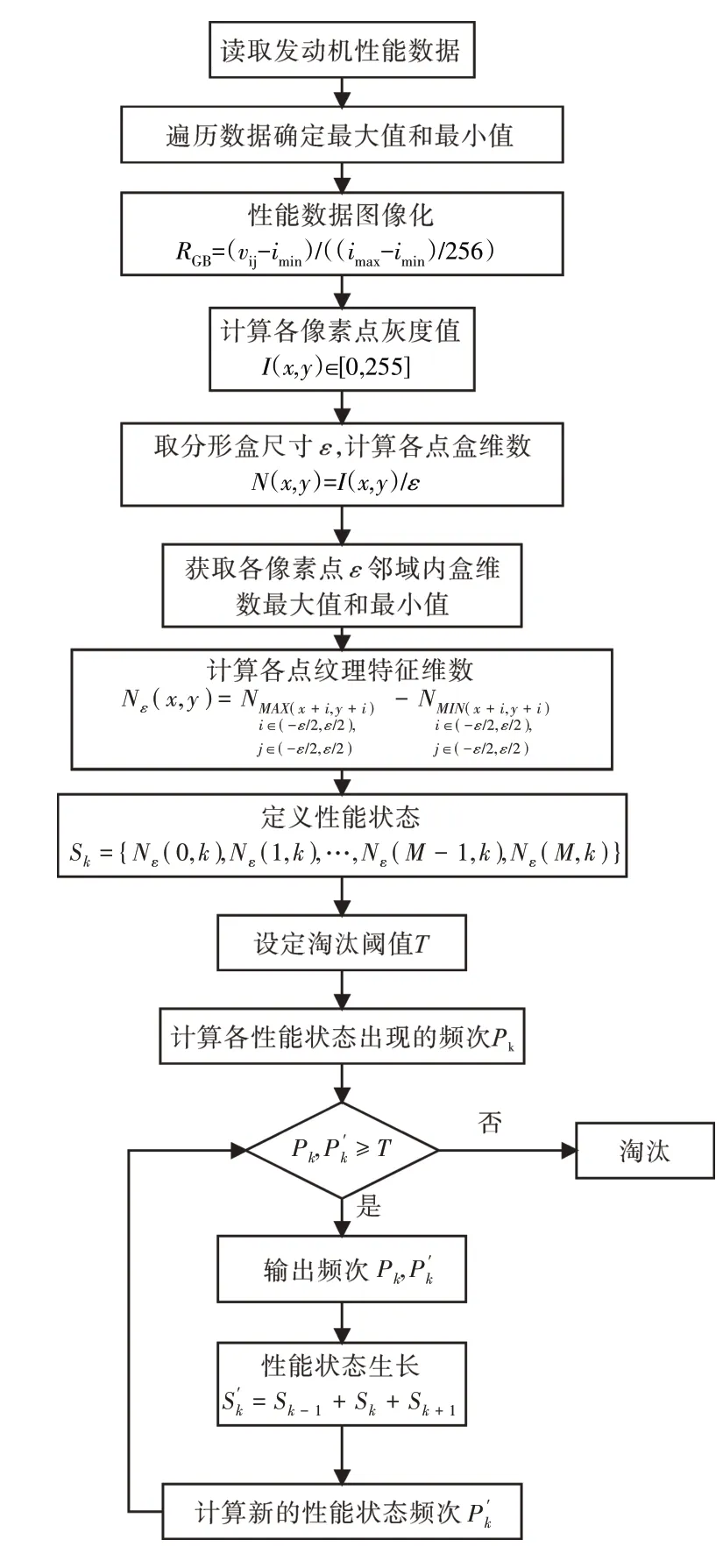
图5 算法流程
算法的具体步骤:
(1)性能数据图像化。输入发动机性能参数,确定其性能数据值域空间[imin,imax]。
(2)依据式(1)建立与彩色空间的映射关系,实现发动机性能数据图像化。
(3)计算分形盒维数。取边长为ε的分形盒,根据式(2)计算性能图像中每个像素点的盒维数N(x,y)。
(4)计算纹理特征维数。计算像素点ε邻域内分形盒维数的最大值和最小值,根据式(3)计算纹理特征维数Nε。
(5)计算性能状态的频次Pk。记图像中每列特征维数为一种性能状态,计算各性能状态在性能图像中出现的频次Pk。
(6)高频次生长。当性能状态的频次Pk小于阈值T则淘汰,大于阈值T 时输出Pk,然后依据式(4)开始生长,计算新性能状态的频次P'k再与阈值T比较,重复此过程直至所有性能状态生长完成;
(7)依据性能状态频次,对图像进行划分。
3 实例验证与分析
3.1 性能数据图像化方法验证
为验证基于高频次生长树纹理分析的发动机性能图像纹理片段划分方法,选取12 个航段的发动机性能参数数据,包括左右发低压转子振动值N1V(low pressure compressor rotor vibrate)和高压转子振动值N2V(high pressure compressor rotor vibrate),本文采用的数据均来自于某航空公司译码后的QAR 数据,其数据信息见表1。

表1 各航段性能数据
3.1.1 本文图像化方法验证
依据性能数据与颜色空间映射关系,将性能数据转化成2 维性能图像,各航段性能数据对应性能图像如图6 所示。从图中可见,对于正常航段A~J所对应的性能图像,其存在明显的主色调区域,局部区域呈现相对统一的颜色,如图中红框所示,说明该性能状态平稳。

图6 各航段性能图像
对于异常航段K和L,其性能图像纹理细密,说明性能状态波动较大,平稳性差,使得图像颜色变化较大,难以维持局部稳定色调。
3.1.2 时频图像化方法验证
常用的图像化方法有短时傅里叶变换法,利用短时傅里叶变换法对发动机性能数据进行图像化,生成的时频图像如图7所示。

图7 各航段时频图像
2 种方法图像化所需要的时间见表2。从表中可见,本文提出的图像化方法的运算效率优于时频法的。

表2 图像化时间结果对比
图像的细节纹理可以用图像信息熵的大小来衡量,反映了图像中平均信息量的多少,信息熵越大,说明图像中所包含的细节纹理越多。
式中:i表示某像素点的灰度值;j表示某像素点领域灰度值;pij表示某像素点的2维特征。
信息熵计算结果对比见表3。从表中可见,本文方法生成的图像信息量远远大于时频法所得的图像,在融合不同时刻不同性能参数的情况下,保留性能数据更多的细节,减小信息损失。
3.2 数据集建立验证
3.2.1 本文方法建立的数据集
在性能图像的基础上,依据基于高频次生长树的图像纹理片段划分算法,对性能图像纹理片段进行划分,结果见表4,从表中可见,本文提出的算法可以对完整的性能图像进行精细划分,将其划分为高频次图像纹理片段和低频次图像片段。其中低频次图像纹理片段1189张,高频次图像纹理片段1181张,消除了数据不平衡。
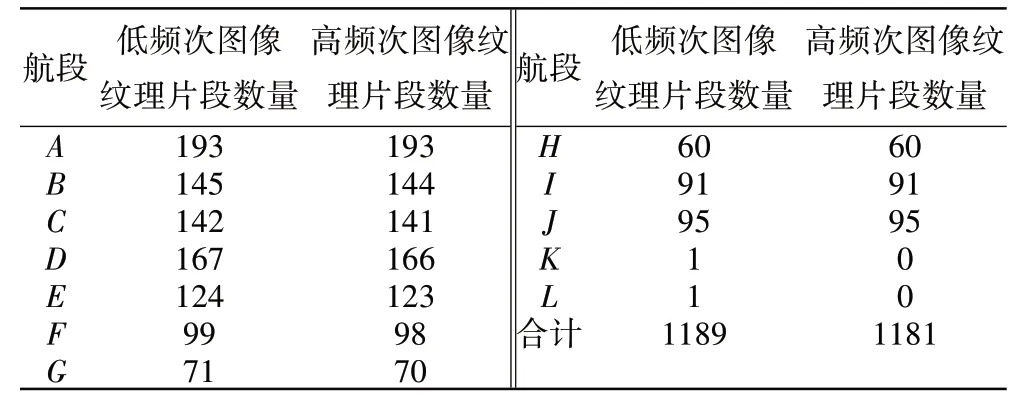
表4 性能图像划分
对于正常航段,划分后的低频次图像纹理片段数量与高频次图像纹理片段数量接近,增强了低频次图像纹理片段的数量,并且真实客观,不损失信息细节;对于异常航段,均为低频次纹理片段,印证了前文的假设,即高频次纹理片段正常,低频次纹理片段异常。
高、低频次图像纹理片段部分样本分别如图8、9所示。从图中可见,高频次图像纹理片段与低频次图像纹理片段差异明显,高频次图像纹理片段多数较宽,表明该性能状态平稳,低频次图像纹理片段窄小,表明该性能状态波动大。
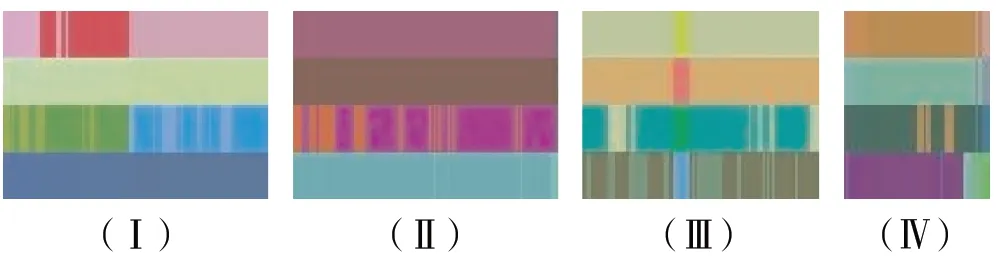
图8 高频次图像纹理片段部分样本
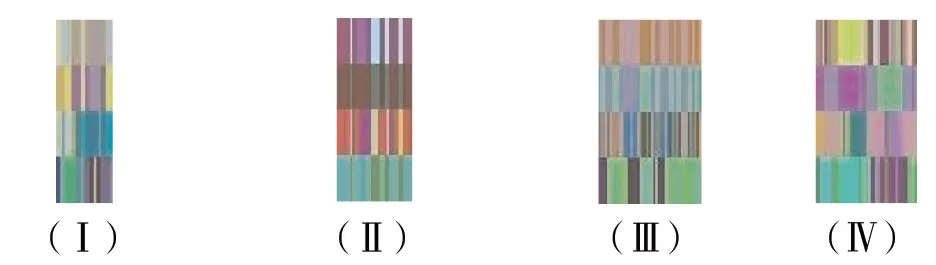
图9 低频次图像纹理片段部分样本
根据式(5)计算高频次和低频次图像纹理片段的信息熵,结果见表5。从表中可见,高频次图像纹理片段的熵值均小于低频次图像纹理片段熵值,这是因为高频图像纹理片段在纹理变化上较为稳定,能够维持稳定色调,低频图像纹理片段颜色变化波动较大,难以维持稳定色调,进而导致信息熵增加。

表5 信息熵计算结果
选取正常航段A~J与异常航段L~L中的高频次和低频次图像纹理片段,按照不同比例构建数据集,见表6。

表6 本文方法构建的数据集
3.2.2 时频方法建立的数据集
时频图像中横轴每一点对应一列性能数据,以100 列数据为一组对图像进行划分,建立数据集d,结合过采样方法建立数据集e,结合欠采样方法建立数据集f,见表7。
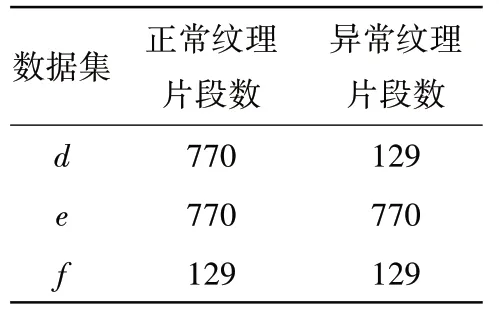
表7 时频法构建的数据集
3.3 应用验证与分析
基于VGG16、ResNet18和ResNet50深度学习网络模型对本文方法建立的数据集a、b和c,和传统方法建立的数据集d、e和f分别进行对比验证,网络模型参数设置见表8。
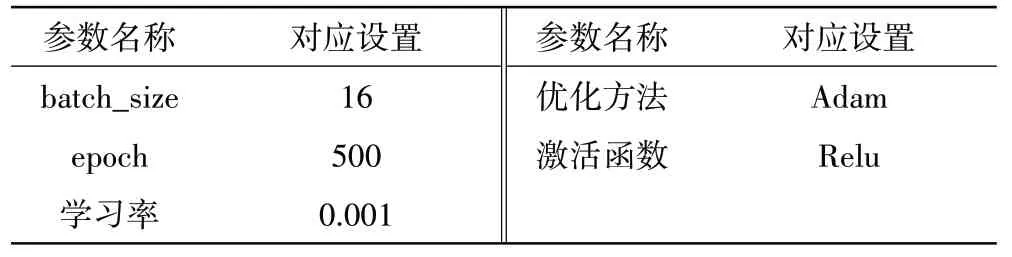
表8 网络模型参数设置
3.3.1 本文方法建立的数据集上的训练准确率
VGG16、ResNet18 和ResNet50 模型在数据集a、b 和c 上训练过程的准确率变化如图10~12所示。

图10 VGG16在数据集a、b和c的准确率曲线

图12 ResNet50在数据集a、b和c的准确率曲线
从图中可见,VGG16 模型在数据集a上,随着训练次数增加,准确率略微上升,在数据集b和数据集c上,准确率先突增后保持不变。造成这种结果是因为数据集a中正常样本和异常样本数量几乎一致,浅层卷积神经网络无法提取更深层次的图像特征,最终导致准确率很低。数据集b中正常样本和异常样本数量的比例为1∶2,数据集c中为2∶1,VGG16 模型将所有输入样本识别为数量占多数的样本类型,反而导致准确率高于数据集a,可以看出浅层卷积神经网络效果不好。
ResNet18 和ResNet50 这2 种模型的准确率变化趋势相似,首先随着训练次数增加,准确率先不断上升,上升到一定程度后开始稳定,最终达到收敛。其中数据集a的准确率最高,数据集b和数据集c的准确率相近且都低于数据集a,这是因为数据集a中的高频和低频图像纹理片段数量接近,深度学习模型能够准确的学习高频次和低频次图像纹理片段的特征,消除了数据不平衡对识别精度的影响。
3.3.2 时频法建立的数据集上的训练准确率
VGG16、ResNet18 和ResNet50 模型在数据集e、b 和c 上训练过程的准确率变化如图13~15所示。
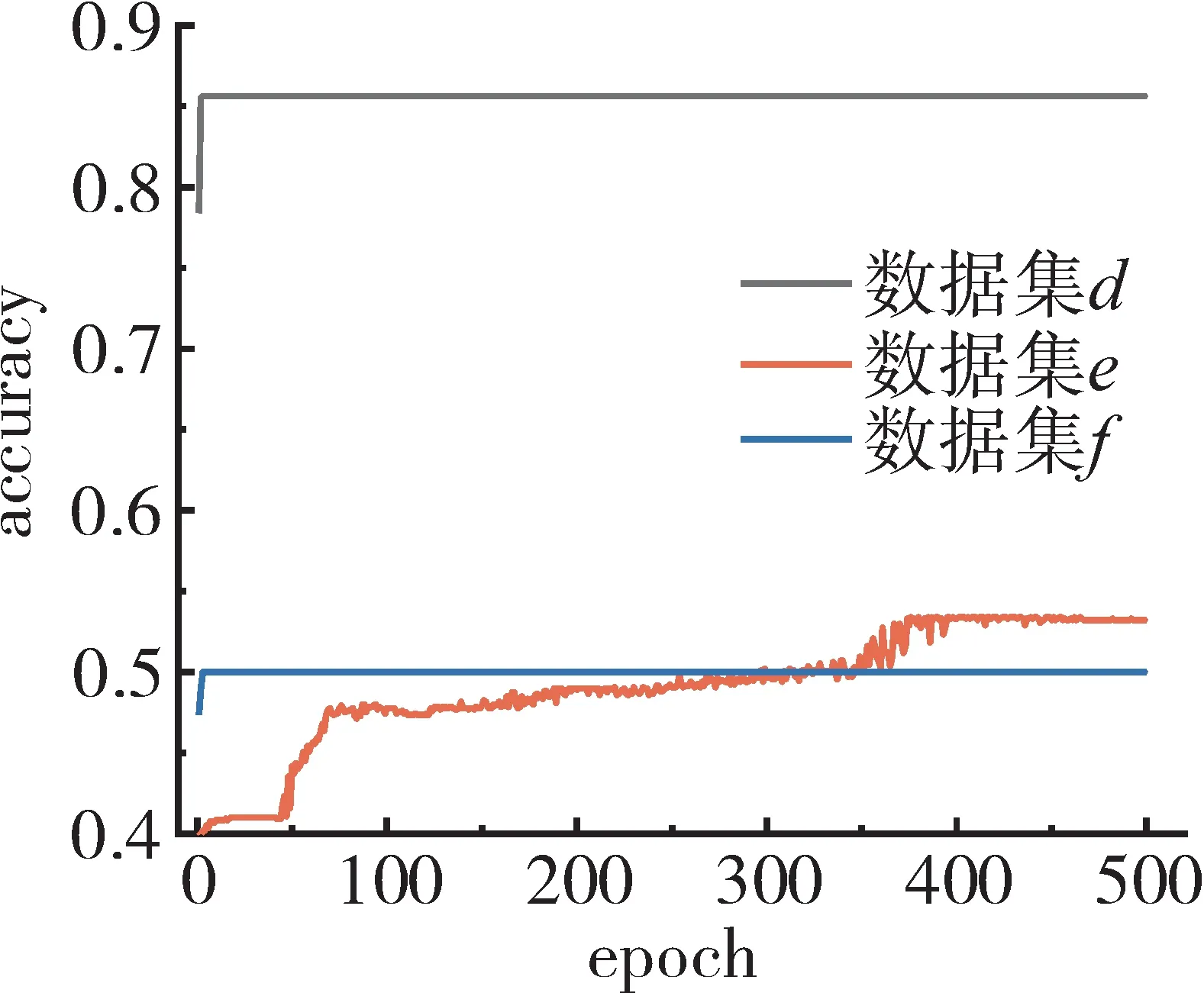
图13 VGG16在数据集d、e和f的准确率曲线

图14 ResNet18在数据集d、e和f的准确率曲线

图15 ResNet50在数据集d、e和f的准确率曲线
从图中可见,VGG16模型在数据集d和f上,准确率先迅速上升后保持不变,在数据集e 上准确率逐渐上升,最终达到收敛。数据集d中正常样本和异常样本数量的比例接近6∶1,正常样本数量远远大于异常样本数量,VGG16 模型将所有输入样本识别为正常样本,反而达到较高的准确率。
ResNet18 和ResNet50 这2 种模型的准确率变化趋势相似,首先随着训练次数增加,准确率快速上升,到一定程度后开始稳定,最终达到收敛。经过采样方法建立的数量平衡数据集e和f相较于数量不平衡的数据集d在准确率上提升不明显,且ResNet18 和ResNet50 模型在数据集d、e和f上的准确率均低于数据集a、b和c。
选取各数据集80%作为训练集,20%作为测试集,训练准确率和测试准确率作为评价指标,分别为
以数据集a为例,在VGG16 模型上,随着训练次数不断增加,训练集中检测正确样本数量不断增多,训练集样本总数不变,当训练次数分别达到50、100、200 和500 次时,根据式(6)计算训练训练准确率,分别为52.38%、53.23%、53.60%和54.03%,保存训练次数为500 次的模型对测试集进行测试,测试集样本总数不变,根据式(7)计算得到测试准确率为48.73%。在ResNet18 模型上,随着训练次数不断增加,训练集中检测正确样本数量不断增多,训练集样本总数不变,训练准确率逐渐增加,当训练次数分别达到50、100、200 和500 次时,训练准确率分别为76.60%、81.96%、83.65%和84.08%,保存训练次数为500 次的模型对测试集进行测试,测试准确率为80.34%。在ResNet50 模型上,其训练准确率的变化趋势与ResNet18模型相似,但最终训练准确率测试准确率较高,分别为91.72%和88.37%,这是因为ResNet50 网络层数多于ResNet18网络的,提取信息量更多。
上述3 种模型在6 种数据集上的训练准确率、测试准确率和运算时间分别见表9、并如图16所示。

表9 3种模型在各数据集上的准确率和运算时间

图16 3种模型在各数据集上的运算时间对比
在准确率方面,VGG16 在数据集b、c和d上的训练准确率和测试准确率相同,这是因为数据集中正常样本和异常样本数量不平衡,VGG16 模型无法进行有效学习,导致将输入样本都识别为数量占多的样本类型,在数据集a、e和f上的准确率均低于ResNet18和ResNet50;这2 种模型在数据a的训练集和测试集上的准确率都达到最高,其中ResNet50 模型的准确率最高,分别为91.72%和88.37%,这是因为数据集a中的正常样本和异常样本数量接近,减少了数据不平衡对模型准确率带来的影响;数据集e训练集和测试集的准确率相差最大,这是因为过采样的方法只是对少数样本进行随机复制以增加样本数量,造成过拟合现象,从而导致这训练集上的准确率远高于测试集;数据集f 是通过欠采样方法得到,欠采样方法随机丢弃多数样本以达到数据平衡,这样会丢失有用的信息,导致准确率难以提升。
在运算时间上,由于本文所采用的ResNet 中的残差结构减少了运算量,50 层的ResNet 模型运算时间仍略低于16 层的VGG 模型的,且准确率远高于VGG16模型的,ResNet18模型运算时间最短,相较于ResNet50模型的运算时间最多提升65%,但准确率略低于ResNet50模型的。
传统的过采样或欠采样方法得到的平衡数据集不仅准确率提升有限而且容易发生过拟合问题,本文提出的方法不但避免了过拟合问题,而且准确率提升明显。
4 结论
(1)在运算速度方面,本文方法能够快速完成性能数据向性能图像的转化,时间复杂度较低。
(2)在划分效果方面,本文方法在保留原始数据信息的同时,对性能数据进行图像化降维并精细划分,为建立包含数量相近的正常样本和异常样本的数据集提供了保障。
(3)在应用效果方面,利用本文方法划分生成的数据集相较于采样方法得到的数据集在深度学习模型的性能异常检测中效果更好。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
软件(2020年3期)2020-04-20
民用飞机设计与研究(2019年2期)2019-08-05
摄影之友(影像视觉)(2018年12期)2019-01-28
中国交通信息化(2018年5期)2018-08-21
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
汽车与新动力(2015年1期)2015-02-27
