
利用改进XGBoost 预测RH 精炼终点钢水温度
2023-09-28 03:55何江一王兴华王燕斌
材料与冶金学报 2023年5期
徐 猛, 雷 洪, 何江一, 韩 信, 王兴华, 王燕斌
(1.东北大学 材料电磁过程研究教育部重点实验室, 沈阳 110819;2.东北大学 冶金学院, 沈阳 110819; 3.建龙北满特殊钢有限责任公司, 黑龙江 齐齐哈尔 161041;4.沈阳东惠科国际贸易有限公司, 沈阳 113000)
在“十四五”时期,我国持续推进的新型工业化、城镇化建设对钢产品质量的适用性、稳定性以及可靠性提出了更高的要求[1].为了满足用户的需求,具有真空脱气脱碳、均匀成分和温度补偿等多种功能的RH 逐渐成为大多数高附加值钢产品生产的重要精炼环节[2].冶金工作者若能精确地预报RH 精炼终点钢水温度,就能缩短真空精炼时间,从而提高工作效率,减少钢产品性能的波动.
随着机器学习和数据挖掘的快速发展,许多机器学习方法在冶金领域崭露头角,这些方法包括神经网络[3]、支持向量机[4]、极限梯度提升(extreme gradient boosting,XGBoost)[5]等.林 云等[6]采用人工神经网络建立了RH 温度预报模型,该模型在偏差为±5 ℃时精炼终点钢水温度的命中率达到87%.王毓男等[7]采用多元回归分析方法建立了RH 精炼终点钢水温度的预测模型,该模型在偏差为±10 ℃时吹氧和未吹氧条件下的命中率分别为96%和99%.以上模型均为单一机器学习模型,在处理数据维度和预测精度方面的应用极其有限.曹宇轩等[8]在LF 炉温度预报模型中先采用最大相似法和邻近炉次法对数据进行筛选,再利用遗传算法对自动搜索结构的反向传播(back propagation,BP)神经网络进行优化,该模型在偏差为±5 ℃时终点命中率达到90.52%.李红利[9]利用贝叶斯优化算法对XGBoost 算法的参数进行优化,并与专家预估模型混合,实现了LF钢水温度的预估.
有研究表明,在机器学习中选取的输入变量过多或过少均会降低算法的运算效率和预测精度,并且单一机器学习模型还会存在一些局限性.因此,本文中以炼钢厂RH 现场数据作为研究对象,先 采 用 随 机 森 林(random forest,RF)[10]、Optuna[11]和XGBoost 算法相结合的方法来建立温度预测模型,通过随机森林的袋外(out of bag,OOB)[13]数 据评分 进行 特 征选 择,然 后 利用Optuna 框架对XGBoost 超参数自动优化,最后根据最优参数预测RH 精炼终点钢水温度.
1 数据预处理
本文中的数据源自炼钢车间RH 的生产数据.由于部分数据存在噪音、缺失值、数据量纲不统一等问题,因此对数据进行预处理十分有必要.将筛选后的数据进行归一化转换,具体转化公式为
式中:xi为输入的各特征变量;ximax,ximin为各独立样本数据的最大值和最小值.
2 基于随机森林特征选择
特征选择是利用最少的特征尽最大可能表达现有数据.这种方法能够减少计算量,提高学习算法的运算效率,从而增强模型的泛化能力.随机森林方法是进行特征选择的有效方法,具体方法如下:①提取预处理后的数据集,将全部的特征作为特征子集,计算出各特征的重要性并按照降序排列;②给定剔除比例,从当前的特征子集中依次剔除相应比例的次要特征,每执行1 次剔除得到1个特征子集,不断剔除次要特征直至剩余4 个特征;③比较步骤②中得到的各特征子集所对应的OOB 评分,将OOB 评分最高的特征子集作为选定的特征集.
为了减少训练样本分布对实验结果的影响,采用五重交叉数据确定特征集[13].具体过程如下:先将全部的训练数据随机分为等量的5 份,选择其中4 份作为训练数据选取特征集;然后更换其中1 份数据,重复实验,这样得到5 组不同的特征集;最后选用出现次数较高(出现次数≥3)的特征作为最终的特征集.
3 XGBoost 优化算法建模原理与方法
3.1 XGBoost 算法
XGBoost 算法[14-15]的核心思想来源于提升树,通过不断地添加提升树,使其集成在一起形成1 个强分类器.其目标函数为
式中:l(yi,)为损失函数,为预测输出,yi为真实输出为正则化项,fk为第k棵树模型,T为每颗树的叶子数量,W为叶子权重值,γ为叶子数量惩罚正则项,λ为叶子权重惩罚正则项.
XGBoost 算法的目标函数引入节点权重等正则项,主要是用来降低模型的复杂度,避免过拟合.同时,损失函数还采用式(3)的二阶泰勒展开式,这样可以有效提高算法的收敛速度和准确性.
式中:gi和hi分别是损失函数的一阶导数和二阶导数.
3.2 GBDT 和LightGBM 算法
梯度提升决策树(gradient boosting decision tree, GBDT)算法[16]是将决策树与Boosting 思想相结合的一种算法.它采用迭代方式进行训练,每轮训练均是在上一轮训练的残差(用损失函数的负梯度来替代)基础上进行的.在回归问题中,每轮迭代产生1 棵决策树,迭代结束时会得到多棵决策树,将所有决策树的结果累加到一起可作为最终结果.
LightGBM 算法[16]以GBDT 算法为基础,采用Histogram 的决策树算法将连续特征离散化,并利用单边梯度采样(gradient-based one-side sampling,GOSS) 和 互 斥 特 征 捆 绑 (exclusive feature bundling,EFB)技术达到降维的目的.其中,GOSS 可以大幅度降低信息增益计算的复杂度,而EFB 可将许多互斥的特征绑定为1 个特征.
3.3 Optuna 框架
为实现高效自动超参数优化、减轻人工调参负担以及提升准确性,在第三方库中调用了Optuna 模块.Optuna 是一个专为机器学习设计的自动超参数优化软件框架[17],主要特征是并行的分布式优化、Python 形式的超参数空间搜索,以及轻量级、多功能、跨平台的架构.该框架的优化方法默认为基于树状结构Parzen 密度估计的非标准贝叶斯优化算法[18],它通过转换生成过程来模拟,用非参数密度替换先前配置的分布.
式中:y*为观察后找到的最佳值;ζ(x)是对不同的观察值{xk}观察形成的密度,使得相应的损失f(xi)<y*;g(x)是通过剩余观察值形成的密度.
3.4 建模流程
基于特征选择和XGBoost 优化,RH 精炼终点钢水温度预测模型的构建思路如下:①在炼钢车间现场采集RH 生产数据,并对数据进行预处理和特征筛选;②将筛选后的数据作为XGBoost模型的输入项,并将其转换为最小化目标函数的问题,利用迭代学习优化总体预测结果;③采用Optuna 框架对XGBoost 进行超参数优化,以此提高模型的预测精度,减小预测误差;④训练和测试预测模型并输出预测值,利用模型评价标准进行分析,同时评估所用方法模型的性能.该模型整个框架如图1 所示.

图1 RH 精炼终点钢水温度预测模型框架Fig.1 Prediction model framework for the temperature of molten steel at the end of RH vacuum refining
3.5 实验评价指标
模型的有效性评估一般采用均方根误差(RMSE)、平均绝对误差(MAE)、控制精度下的命中率(符合误差允许的样本数与总预测样本数的百分比)和运行时间来进行评价.RMSE 和MAE分别反映了模型误差平方的期望值与精确度.计算公式如下所示:
式中:n为总预测样本数,yi为第i个样本的温度测量值为第i个样本的温度预测值.
4 实验分析
4.1 数据集
经预处理后,炼钢厂的258 炉数据只剩下255 炉,从中随机选取75%的数据(191 炉)作为训练集来训练模型,剩下25%的数据(64 炉)作为测试集来验证温度模型的预测能力.
4.2 特征选择
对采集所得数据进行特征选择,筛选的特征变量一共包括12 种,如表1 所列.表2 列出了采用随机森林方法筛选的结果.特征变量为进站钢水温度、进站钢水氧质量分数、插入管次数、真空时间、铝加入量和进站钢水碳质量分数.
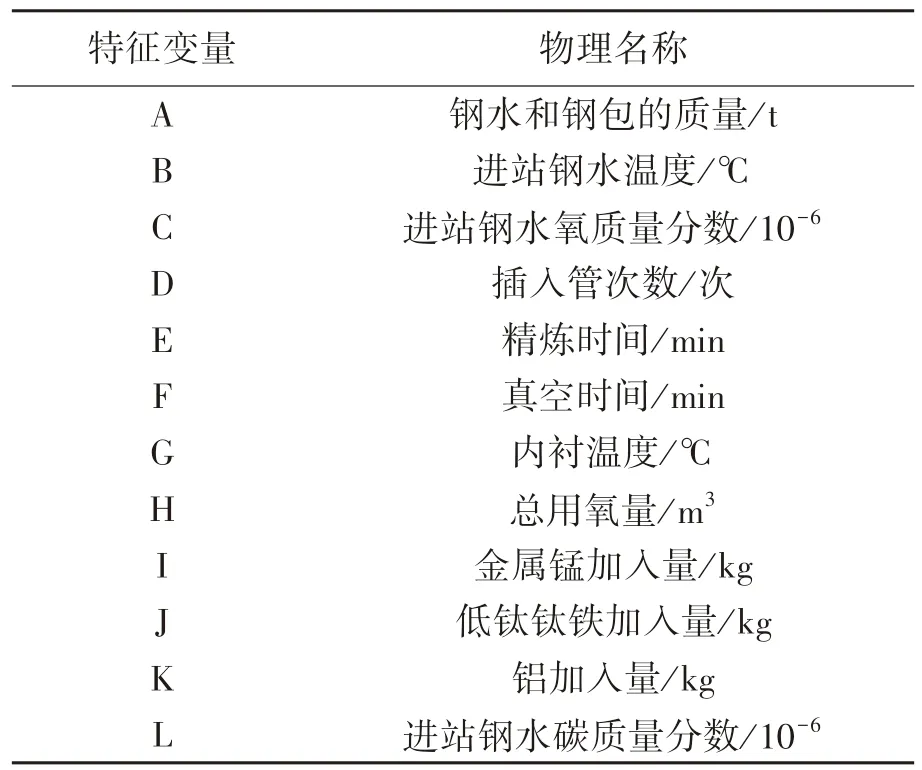
表1 RH 精炼终点钢水温度预测特征变量Table 1 Characteristic variables for the temperature of molten steel at the end of RH refining

表2 RH 精炼终点钢水温度预测特征变量选择结果Table 2 Characteristic variables for the temperature of molten steel at the end of RH refining after selection
4.3 超参数优化
文献[5]中通过调试XGBoost 的学习率、树的数量和深度提高了模型的预测效果.XGBoost 的目标函数已引入正则化项,在超参数调试中再加入L1 正则化、L2 正则化及叶子能够含有的最少样本数.表3 列出了XGBoost 超参数取值范围及Optuna 框架优化XGBoost 后所选取的一组最优超参数.

表3 XGBoost 超参数取值范围及最优超参数Table 3 Value ranges and optimized values for XGBoost superparameter
4.4 模型性能分析
为了验证模型预测效果, 本文中采用Python3.6 进行编程,分析了GBDT,LightGBM,XGBoost 这3 种模型在Optuna 框架下超参数优化前后的预测结果.其中,GBDT 模型选取的优化超参数为学习率、树的数量、树的深度、随机种子、叶子能够含有的最少样本数、内部节点再划分所需最小样本数.LightGBM 模型选取的优化超参数为树的数量、学习率、树的深度、最大叶子数量、L1正则化、L2 正则化.
由表4 可知,RH 精炼终点的钢水测量温度最大值为1 607.00 ℃,最小值为1 582.00 ℃,极差为25 ℃.未优化和优化后的模型预测钢水温度的极差范围为12~17 ℃,均小于钢水温度测量值的极差.其中,XGBoost 模型在超参数优化前钢水温度最大值为1 603.69 ℃,比测量值的最大值低3.31 ℃;其最小值为1 590.70 ℃,比测量值的最小值高8.7 ℃,极差仅为13 ℃.经超参数优化后,XGBoost 模型钢水温度最大值为1 607.29 ℃,比测量值的最大值高 0.29 ℃; 其最小值为1 591.31 ℃,比测量值的最小值高9.31 ℃,极差为16 ℃.

表4 测量温度及模型预测温度的特征值Table 4 Eigenvalues of measured temperature and model predicted temperature ℃
图2 给出了RH 精炼终点钢水温度的预测值与测量值的误差.可以看出,在超参数优化前,GBDT,LightGBM 和XGBoost 这3 种模型的温度误差主体(25%~75%数位分布)分别为-3.43 ~2.45 ℃,-3.22~2.34 ℃和-2.61 ~3.31 ℃.其中,XGBoost 模型中的RH 精炼终点钢水温度误差的主体 较 宽, 为5.92 ℃; GBDT 模 型 次 之, 为5.88 ℃;LightGBM 模型中钢水温度误差的主体最窄,为5.56 ℃.这3 种模型经过超参数优化后,相应的钢水温度误差主体分别为-2.92 ~2.31 ℃,-2.49~3.03 ℃和-3.52 ~1.81 ℃.LightGBM 模型的箱体较宽,为5.52 ℃;XGBoost 模型次之,为5.33 ℃;GBDT 模型的箱体最窄,为5.23 ℃.经超参数优化后,GBDT,LightGBM 和XGBoost 这3 种模型的箱体宽度分别减小了0.65,0.04,0.59 ℃,这表明合理的超参数选择能够有效提升模型的准确度.

图2 RH 精炼终点钢水温度预报误差Fig.2 Error between the predicted value and the measured value of the temperature of molten steel at the end of RH vacuum refining
结合图3 和表5 可知:优化前的GBDT,LightGBM,XGBoost 这3 种模型在偏差为±5 ℃时RH 精炼终点钢水温度的命中率分别为81.25%,79.68%,84.37%,经超参数优化后它们的命中率分别为87.50%,84.37%和92.18%,分别提高了6.25%,4.69%和7.81%.
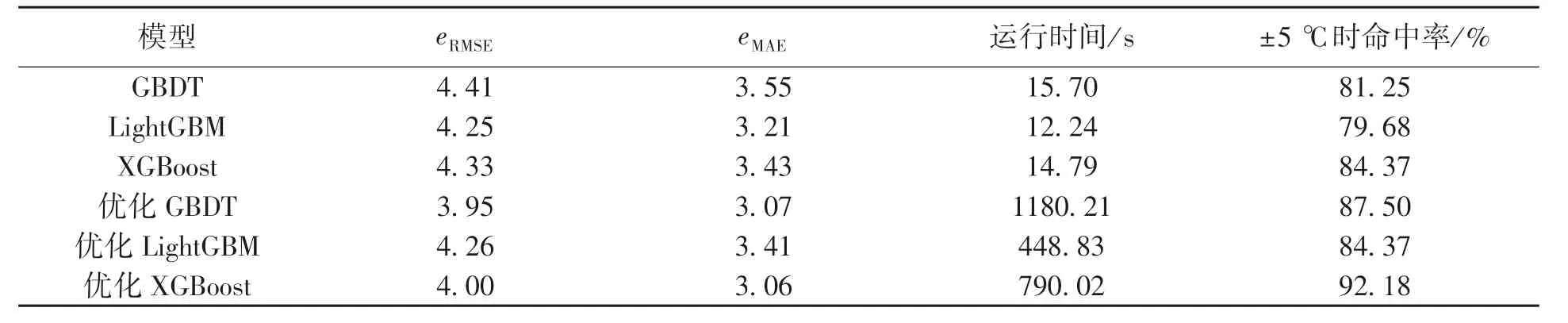
表5 在Optuna 框架下3 种温度预测模型优化前后结果的对比Table 5 Comparison of three temperature prediction models before and after optimization of Optuna

表6 不同XGBoost 超参数优化方法预测结果的对比Table 6 Comparison of prediction results of different XGBoost hyperparameter optimization methods

图3 RH 精炼终点钢水温度预测结果Fig.3 Predicted temperature of molten steel at the end of RH refining
由表5 还可知:在偏差为±5 ℃时优化前的XGBoost 模型RH 精炼终点钢水温度的命中率比GBDT 模型的命中率高3.12%,比LightGBM 模型的命中率高4.69%;优化后的XGBoost 模型在偏差为±5 ℃时精炼终点钢水温度命中率比优化后的GBDT 模型命中率高4.68%,比优化后的LightGBM 模型高7.81%.就均方根误差而言,优化后的GBDT 模型最小,为3.95;优化后XGBoost模型次之,仅比优化后的GBDT 模型高0.05.就平均绝对误差而言,优化后的XGBoost 模型最小,为3.06,优化后的GBDT 模型次之,比优化后的XGBoost 模型小0.01.综上所述,XGBoost 模型命中率更高,具有更好的拟合效果.
此外,表5 还给出了采用Optuna 框架对超参数进行迭代寻优所需的计算耗时.优化后的GBDT,LightGBM 和XGBoost 模型的运行时间分别为1 180.21,448.83,790.02 s.LightGBM 模型运行时间最短,这是因为LightGBM 模型在GBDT 模型基础上进行了GOSS,EFB 及带深度限制的Leaf-wise叶子生长策略等改进;而XGBoost 模型运行时间稍慢,这是因为它采用了基于预排序方法的决策树算法,该预排序算法的优点是能精确地找到分割点,但是缺点也很明显,即在空间和时间上的消耗大.
从表 6 中可看 出, 当采 用 随机 搜 索(randomized search, RS)[19]、 网 格 搜 索(grid search,GS)[19]和Optuna 框架对XGBoost 模型进行超参数优化后,在偏差为±5 ℃时钢水终点温度的命中率分别提高了3.13 %,6.1 %和7.81 %.此外,计算耗时最短的是Optuna 框架,其次是RS,计算耗时最长的是GS,且RS 和GS 的计算耗时分别是Optuna 框架的1.21 倍和4.83 倍.这是因为GS 属于穷举搜索算法,它会将各个参数的可能取值进行排列组合,尝试每一种组合,最后选择出表现最好的参数组合;而RS 则是利用随机数去求函数近似最优解.
5 结 论
(1)正确选择XGBoost 模型的超参数对预测结果尤为重要.本文中选择的超参数为树的数量、树的深度、学习率、L1 正则化、L2 正则化及叶子能够含有的最少样本数.
(2)利用Optuna 框架优化GBDT,LightGBM,XGBoost 3 种模型的超参数,优化后模型的命中率得到明显提升,3 种模型在偏差为±5 ℃时RH 精炼终点钢水温度的命中率分别提高了6.25%,4.69%和7.81%.
(3)采用Optuna 框架、网格搜索和随机搜索对XGBoost 模型进行超参数优化,经Optuna 框架优化的XGBoost 模型在偏差为±5 ℃时RH 精炼终点钢水温度的命中率最高(92%),且计算耗时最短.
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
山东冶金(2019年2期)2019-05-11
中国生殖健康(2019年11期)2019-01-07
长江丛刊(2018年31期)2018-12-05
NBA特刊(2017年8期)2017-06-05
法大研究生(2017年1期)2017-04-10
当代工人(2016年11期)2016-07-19
安徽冶金科技职业学院学报(2015年3期)2015-12-02
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
