
基于YOLOPose 的人体姿态估计轻量级网络
2023-10-27 10:31王红霞李枝峻顾
沈阳理工大学学报 2023年6期
王红霞李枝峻顾 鹏
(沈阳理工大学 信息科学与工程学院,沈阳 100159)
人体姿态估计是计算机视觉领域中对图片中人体关键点进行定位,在视频监控、智能驾驶等领域有着重要作用。
随着神经网络的迅猛发展,基于深度学习的多人姿态估计网络通常分为由下至上和由上至下两类。 2020 年,Cheng 等[1]提出了一种由下至上的HigherHRNet 网络,该网络在HRNet 网络末端添加了一个高效反卷积模块,并采用了多分辨率训练以及热图聚合策略,从而有效地解决了小人物关键定位不准确的问题。 2021 年,Geng 等[2]提出了解耦关键点回归(DEKR)网络,通过多个并行分支结构对每个关键点独立进行特征提取和回归,实现了关键点之间的解耦。 同年,Yuan 等[3]对HRNet 网络进行改进并提出了HRFormer 网络,该网络将多分辨率并行设计以及局部窗口自注意力引入HRNet,并在前馈神经网络中添加卷积操作,有效实现了断开连接的图像窗口之间的信息交换。 此外,Yang 等[4]提出了一种名为TransPose 的模型,该模型将变换神经网络引入人体姿态估计,能够捕获人体各部位的全局空间依赖关系,提高了模型识别准确度。
上述人体姿态估计网络虽提升了关键点定位准确度,但同时模型参数量或计算量也随之增加,致使模型运行效率低下,无法有效作用于实时性设备。 因此,本文重点研究如何使模型在具有较高关键点定位准确度的前提下有效减少模型参数量和计算量。
1 模型改进
YOLOPose[5]是一种无热度图,端到端,单阶段的联合检测方法。 与自上而下方法相比,该模型不需要通过目标检测算法以及单人姿态估计网络进行关键点定位,也不同于基于热度图的自下而上方法,其关键点后处理与多个前向传播被取消。 该模型在一次前向传播中联合检测出多人边框以及相应人体关键点,每个人体边框都对应一个人体姿态,从而形成单人关键点的固有分组。因此,本文选择YOLOPose 模型并进行如下改进。
1)选择轻量级MobileNetV3 网络作为骨干网络,加快特征提取速度。
2)使用损失函数WIOUV2 评估网络边框损失。
3)添加ECA 高效通道注意力机制保证网络识别准确度。
1.1 改进网络总体架构
本文对原始YOLOPose 模型具体做出如下改进。 为实现特征提取网络轻量化,本文删除了原始YOLOPose 模型骨干网络最后一个C3 模块,将删除了最后一层池化以及三个二维1 ×1 卷积的轻量级MobileNetV3-Small 网络作为新的骨干网络,保留了原始模型中特征提取网络的空间金字塔池化(SPP)层。 随后将不同尺度输出特征经过上采样输入到特征融合层中。 为进一步减少模型参数量,本文将特征融合层的卷积与C3 模块通道数由1 024、768、512、256 分别对应调整为512、256、128、96,同时为保持识别准确度,在特征金字塔(FPN)结构的上采样以及金字塔注意力(PAN)结构的卷积模块之前添加了ECA 注意力机制。最后,为更好评估模型性能,本文使用WIOUV2损失函数替换原有CIOU 边框损失函数。 其改进后总体网络架构如图1 所示。

图1 改进后总体网络架构图Fig.1 Improved overall network architecture diagram
1.2 骨干网络改进
原始YOLOPose 模型使用CSPDarkNet53 骨干网络,其首先会通过对输入图片进行切片操作。其次,使用4 个卷积及C3 模块对输入特征进行不同尺度特征提取,其中C3 模块由3 个卷积模块与1 个残差块Bottleneck 组成,C3 模块将输入特征映射为两部分,并通过跨阶段层次使用通道拼接操作进行合并。 最后,SPP 对输入特征进行一次卷积后分别经过5 ×5、9 ×9 以及13 ×13 的池化,并将不同池化输出特征与卷积输出特征进行通道拼接。
综上可知,YOLOPose 骨干网络主要由Focus、Conv 和C3 模块构成,带来了较大计算量,特征提取速度较慢。 因此,本文选择轻量级Mobile-NetV3 网络替换原有骨干网络,使得模型轻量化的同时保证网络的特征提取能力。
MobileNetV3[6]有Large 与Small 两个版本,本文将MobileNetV3-Small 作为新的骨干网络,其具体原理如下。 首先,MobileNetV3 网络将Block模块作为基本单元进行神经网络搜索,使得不同模块具有不同的宏观结构,并使用NetAdapt 算法对结构进行微调,减小了扩充层与每层的大小,Block 模块结构如图2 所示。 其次,MobileNetV3网络加入了SE 注意力机制[7],结构如图3 所示,图中X、U、分别为输入特征、卷积操作的结果特征、通道赋权操作的结果特征;H、W、C分别代表输入特征宽、高与通道数;H′、W′、C′则表示卷积操作之后的特征宽、高与通道数,图中Ftr为一系列卷积操作,Fsq(•) 表示全局平均池化操作,Fex(•,W)是指非线性变换操作,Fscale(•,•)代表通道赋权操作。 SE 注意力机制首先对输入特征进行卷积与全局平均池化操作,然后将尺寸为(1,1,C)的向量输入激活函数分别为ReLU 与σ的两个全连接层,最后与输入特征进行相乘操作,使得特征图在通道数不变的情况下每个通道具备不同的权重,并让其值保持在[0,1]区间。

图2 MobileNetV3-Small 的Block 单元Fig.2 Block unit of MobileNetV3-Small

图3 SE 注意力模块Fig.3 SE attention module
最后,MobileNetV3 基于ReLU6 函数重新设计出h-swish瓶颈残差激活函数,ReLU6 函数与hswish函数分别为
并使用h-sigmoid函数取代SE 结构原有σ函数,消除指数运算对模型运算速度的影响。h-sigmoid函数和σ函数分别为
1.3 特征融合网络改进
随着神经网络的层次加深,提取到的特征语义信息越加丰富,但特征位置信息也会逐渐丢失,YOLOPose 采取FPN 与PAN 来解决此问题。 首先将输入特征图送入FPN 结构,经过卷积和上采样操作,随后与骨干网络不同尺度输出特征进行融合并送入C3 模块,反复迭代,使其深层特征图包含更强的位置信息,最后PAN 结构通过下采样加强特征图语义信息并融合两个特征,使不同尺度特征图充分保留了语义与位置信息。
YOLOPose 在YOLOV5 原有特征融合结构基础上加深了一层,但增强特征融合能力的同时模型计算量和参数量也随之增多。 因此本文对特征融合层卷积通道数做出调整,并添加ECA 注意力机制保证模型的识别精度。 ECA 注意力机制[8]是一种改进的SENet 网络,其在SENet 基础上提出了无降维局部交叉信道交互策略,结构如图4 所示,图中h为自适应一维卷积核大小,σ表示激活函数。
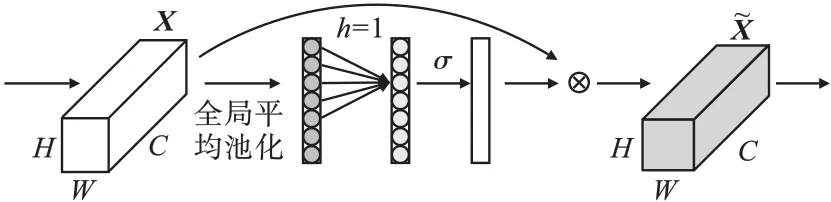
图4 ECA 注意力模块Fig.4 ECA attention module
ECA 将原有SENet 中全连接层替换成一维卷积,在避免维度缩减的同时捕获部分通道信息,减少了模型参数,具体原理如下。 首先,对输入特征进行全局平均池化,其次通过自适应大小为h的一维卷积及σ激活函数得到通道权重,并与输入特征进行通道相乘操作,得到加权后的特征图。决定h值自适应大小函数形式为
式中:h为自适应一维卷积核大小;b和γ决定了C与h的比例,b值设置为1,γ值为2;||odd表示取奇数操作。
1.4 损失函数替换
YOLOPose 损失包括边框、关键点位置以及置信度损失,其总损失公式为
式中:s为对象分割区域平方根;i,j分别代表真实边框横纵坐标;k表示s尺度的第k个锚框;Ltotal、Lb、Lkpts、Lconf分别代表总损失、边框损失、关键点位置损失以及关键点置信度损失;λb、λkpts、λconf表示不同损失权重,默认值为0.5。
1.4.1 边框损失
YOLOPose 采取CIOU 损失函数[9]评估边框损失,CIOU 损失函数公式形式为
式中:b,bgt分别代表预测及真实边框坐标;ρ是预测与真实框中心点欧式距离;c为包含预测和真实框的最小框对角线长度;IOU 表示预测框与真实框交并比;α为权重函数;ν为长宽比相似性度量。
1.4.2 关键点位置以及置信度损失
人体关键点标签为[x1,y1,v1,…,xt,yt,vt],预测结果为[x1,y1,c1,…,xt,yt,ct],其中t为标签及预测关键点序号;xt,yt分别代表第t个关键点横轴、纵轴坐标;vt为第t个关键点标签可见性标志,0 表示未标记,1 表示标记被遮挡,2 表示标记未遮挡;ct为第t个关键点的预测置信度。 关键点损失包括位置损失以及置信度损失。
基于热度图的自底向上人体姿态估计网络使用的L1 损失函数未考虑目标尺度与关键点类型对损失的影响,无法有效评估关键点损失。 而关键点相似度(OKS)损失预测关键点和真实关键点的接近程度,是一个与IOU 损失类似的相似性度量,尺度不变且不会造成梯度消失,更适用于估计关键点损失。 OKS 损失值介于0 和1 之间,计算公式为
式中:Nkpts表示第N个关键点;dt表示第t个真实与预测关键点欧式距离;kt是指第t个关键点权重。 置信度损失是基于可见性标志进行训练的,可见性标志大于0 的关键点标签置信度记为1,反之为0,其计算公式为
式中BCE 表示二分类交叉熵损失函数。
1.4.3 WIOUV2 损失
数据集中低质量图片会加重CIOU 损失函数对锚框中心点距离以及纵横比的惩罚,从而降低模型的泛化能力。 针对此问题,本文删除了原有CIOU 边框损失函数,并引入新的WIOUV2 函数[10]评估边框损失。 WIOUV2 损失函数计算公式为
式中:γ为调节因子,γ值越大,代表模型在低质量图片上的聚焦度更高;为单调聚焦系数,∗表示单调聚焦系数为非零自然数;为归一化因子;LWIOUV1表示基于距离度量构建出的具有两层注意力机制的WIOUV1 损失函数,WIOUV1 函数能够在IOU 值较大时降低对几何距离的惩罚,公式为
式中:LIOU为交并比损失;RWIOU函数的作用是放大普通质量锚框的LIOU。
WIOUV2 损失函数是基于Focal 损失函数[11]的交叉熵单调聚焦机制所构建的单调聚焦系数与WIOUV1 损失函数所提出的。 WIOUV2 函数不仅继承了WIOUV1 损失函数的优点且引入了归一化因子均值,解决了WIOUV2 损失函数在训练过程中因单调聚焦系数减小而导致后期收敛速度慢的问题,从而能够更好地评估边框损失。
2 实验与分析
2.1 实验数据和环境
本文所有实验均基于表1 环境运行。 采用公共OC_Human 数据集,该数据集存在严重的人体遮挡以及复杂背景,是多人姿态识别领域最具挑战性的数据集之一,包含5 081 张图片,标注人体姿态实例13 360 个。 训练前使用Mosaic、Fliplr等方式进行数据增强,设置初始学习率为0.01,预热学习率为0.1,批次大小为32,训练轮数为300,采用平均准确度、参数量及运算量对模型性能进行评价。

表1 实验环境Table 1 Experimental environment
2.2 消融实验
为比较不同方法对模型性能的影响进行消融实验,所有实验输入图片尺寸均为640 ×640,实验参数与环境保持一致,实验结果见表2。
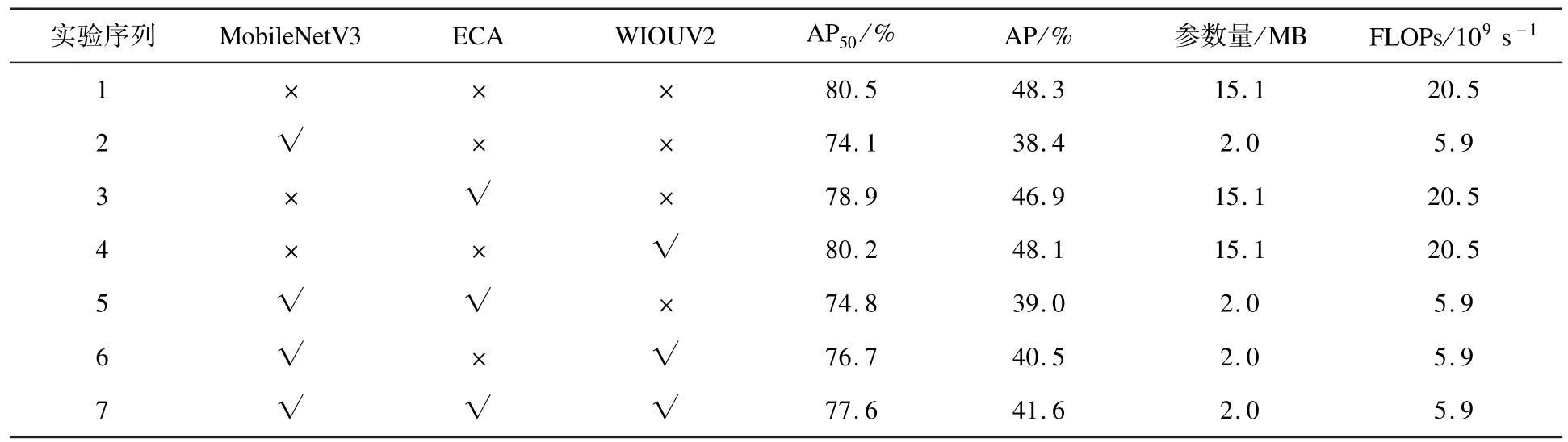
表2 消融实验结果对比Table 2 Comparisons of ablation experiments
首先,由表2 中实验1 和实验2 的对比结果可知,在采用轻量级骨干网络MobileNetV3 并减少特征融合层通道数的情况下,模型的准确度小幅下降,但模型参数量和计算量分别下降了86.8%和71.2%;其次,实验3 和实验4 的结果表明,添加ECA 注意力机制以及WIOUV2 损失函数后模型识别准确度变化不大,但并未引起参数量和计算量增多;从实验5 的结果看,在实验2 基础上单独加入ECA 注意力机制能够使预测准确度提升0.7%;实验6 的结果显示,与加入ECA 注意力机制相比,引入WIOUV2 损失对轻量化模型识别准确度提升尤为明显,其准确度上升了2.6%;最后将ECA 注意力机制与WIOUV2 损失函数同时加入轻量化模型,结果如实验7 所示,模型预测准确度相比实验5 和6 有了更大的提高。
消融实验数据表明,优化之后的模型在保持较高准确度的同时参数量和计算量均有明显降低,模型运行效率得到了有效提升。
2.3 对比实验
本文在OC_Human 数据集上对YOLOPose和本文提出的MWE-YOLOPose 模型进行了测试, 并 与 HigherHRNet[1]、 DEKR[2]、 HRFormer-B[3]、TransPose-H[4]模型进行了比较。 其中,HRFormer-B、TransPose-H 为自上而下的方法,而HigherHRNet、DEKR 采用由下至上的方法,对比结果见表3。

表3 不同算法结果对比Table 3 Comparisons of the results based on different algorithms
实验结果表明,相比目前主流的姿态估计模型HigherHRNet,本文提出的MWE-YOLOPose 模型不仅在AP 和AP50分别高13.9%和10.7%,而且参数量和计算量分别减少93.0%和87.7%。与HRFormer-B 模型相比,本文模型的预测精度有所下降,但网络模型参数量和计算量分别减少95.4%和51.6%。 同时对比DEKR 模型,本文模型在预测精度AP 上减少10.6%,但在AP50上获得了7.7% 的精度增长,参数量和计算量降低93.2%与87.0%。 此外,虽然自上而下的Trans-Pose-H 模型在AP 上比本文模型更具竞争力,但本文模型在AP50上仅下降5.1%,且参数量和计算量降低了88.6%和72.9%,算法运算效率更高。 最后,本文MWE-YOLOPose 对比原始YOLOPose 模型在精度AP50下降2.9%、AP 降低6.7%的情况下,参数量和计算量分别减少了86.8%和71.2%。
综上可得,本文提出的MWE-YOLOPose 模型对比原始YOLOPose 模型性价比更高,且在保持一定准确度的情况下,模型参数量和计算量大幅低于目前主流的自下而上和自上而下方法,有效降低了模型参数量和运算复杂度。
2.4 效果展示
为验证改进后模型性能,本文对预测结果进行了可视化。 图5 和图6 分别是部分图片标签及预测结果,两组图片分别包含单人、双人以及多人,且存在人体遮挡、部位缺失等特点。 从图6 中可见,单人标签的17 个关键点能预测出来,且构成了一副完整的人体骨骼,边框置信度达0.9。 其次,虽然图5 双人图片存在人体遮挡,但改进后的模型也能够比较准确地预测出遮挡关键点,边框置信度分别为0.8 和0.2。 图5 第三张图片背景为街道,且存在人群拥挤,关键点遮挡,人体部位缺失等特点,预测结果如图6 第三张图片所示,改进后模型不仅预测出小女孩的关键点与身后被遮挡男子的关键点,且对于缺失人体部分,模型也识别出存在部位关键点并进行了连接。 通过可视化分析可知,改进后模型在大幅降低参数量和计算量后,对多人姿态估计依然有着较好的识别效果。

图5 不同场景标签图Fig.5 Label map of different scene

图6 不同场景预测结果图Fig.6 Prediction results of different scenarios
3 结论
针对目前人体姿态估计方法为提升模型准确度导致模型深度加深,从而使模型参数量与计算量增多、模型运行效率低下的问题,给出了一系列的改进方案。 本文使用MobileNetV3 将骨干网络轻量化,调整通道数并引入ECA 高效注意力机制,同时采用了WIOUV2 损失函数评估模型损失。 实验表明,对比原始模型以及其他多人姿态估计方法,本文MWE-YOLOPose 模型参数量和计算量明显减少,同时保证了一定的模型识别准确度,具备较强的泛化性和鲁棒性,更易作用于实时性设备。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
建筑科技(2018年6期)2018-08-30
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
中国照明(2016年6期)2016-06-15
中国交通信息化(2016年5期)2016-06-06
发明与创新(2015年25期)2015-02-27
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
