
基于双通道混合网络模型的调制方式识别方法研究
2023-10-27 10:32费顺超张成璞
沈阳理工大学学报 2023年6期
费顺超张成璞
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
信号调制方式识别是通信侦察及软件无线电领域的一个重要研究方向。 调制方式是区别不同调制信号的主要特征之一,识别调制方式可为后续的信号解调、实施电子干扰等非合作通信任务提供必要的信息[1]。 传统的信号调制方式识别算法主要分为两类:一类是基于决策理论的最大似然假设检验方法[2-3];另一类是基于特征提取的识别方法[4-5]。 前者是对不同调制方式做出不同的假设,得到不同假设下调制信号的似然函数,然后将其值与预定义的阈值进行比较,实现调制信号的分类,该方法计算复杂度高且需要充分的先验知识,信号识别率不高;后者是通过小波变换[6]、循环谱[7]、高阶累积量[8]等方法提取目标信号的特征,然后针对不同的信号特征通过分类器实现调制信号的分类,该方法需要人工提取信号特征,适用场景受限。
近年来,深度学习在计算机视觉、语音识别等领域取得了显著的进展,受到研究人员的广泛关注。 与传统方法相比,深度学习可以自动学习复杂数据的特征,无需人工提取。 文献[9]在RML2016.10a 数据集中使用卷积神经网络(CNN)成功识别出11 种调制信号,但最大平均识别准确率不足75%;文献[10]使用残差网络(ResNet)识别11 种不同的调制信号,识别准确率相较于CNN 提升不大,但模型复杂度却大大提高。 文献[11]引入长短期记忆神经网络(LSTM),构建了一个CNN-LSTM 级联的神经网络,其分类准确率比单一网络稍高;文献[12]提出双通道的CNN-LSTM 网络,当信噪比为0 dB 时,平均识别准确率可达到87%;文献[13]将自动编码器与CNN 相结合,不仅降低了训练时间,而且识别准确率比CNN 提高了1.2%;文献[14]引入CNN、LSTM 与深度神经网络(DNN)组合的多模型神经网络(CNN-LSTM-DNN,CLDNN)用于调制方式识别,并与CNN、CNN-LSTM 等模型进行了对比,结果表明,该网络针对不同数据集的识别准确率均最高,可达到85%左右。 文献[11 -14]均使用混合网络模型实现信号调制方式识别,但识别准确率仍有待提升。
为进一步提高调制方式识别方法的准确率,本文将CNN、LSTM、ResNet 及DNN 进行组合,提出一种基于双通道混合网络模型的调制方式识别方法,并通过仿真实验分析该方法的性能。
1 传统网络模型
1.1 ResNet 网络
ResNet[15]是一系列残差块堆叠而成的深层神经网络,残差块中包含两个卷积层,同时将输入与卷积层输出以跳层连接的方式进行相加。 Res-Net 网络结构如图1 所示。 图中:Conv 表示卷积层;ReLU 表示激活函数;x表示输入;f(x)表示卷积层输出;F(x)表示残差网络输出。
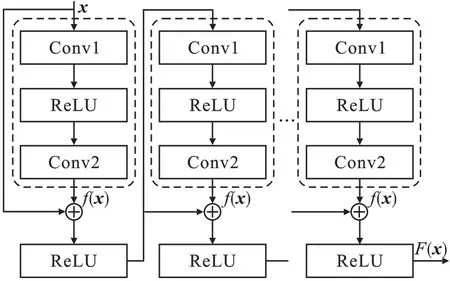
图1 ResNet 网络结构Fig.1 ResNet network structure
对于深层神经网络,不引入残差的情况下,网络的输出为f(x) =x;引入残差后网络的输出为F(x) =f(x) +x,移项后得到f(x) =F(x) -x,只要f(x)→0,就可以得到恒等映射F(x)→x,大大降低了网络拟合的难度。
1.2 LSTM 网络
LSTM 是深度学习中处理序列问题最常用的模型,该网络由遗忘门Ft、输入门It和输出门Ot组成,其结构如图2 所示。 图中:ht-1为网络前一时刻的隐藏状态;Ct-1为前一时刻的记忆单元;xt为当前时刻的输入;σ表示激活函数;表示候选记忆单元;ht表示当前时刻的隐藏状态;Ct表示当前时刻的记忆单元。
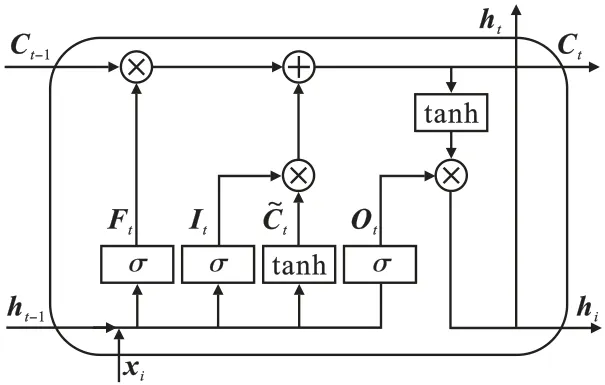
图2 LSTM 网络结构Fig.2 LSTM network structure
遗忘门Ft、输入门It、输出门Ot的计算式分别为
式中:Wxf、Wxi、Wxo、Wxc和Whf、Whi、Who、Whc分别表示不同的权重参数;bf、bi、bo、bc分别表示不同的偏置参数。
1.3 混合网络模型
典型的混合网络模型有CNN-LSTM 和CLDNN,两种混合网络结构如图3 所示,图中FC表示全连接层。
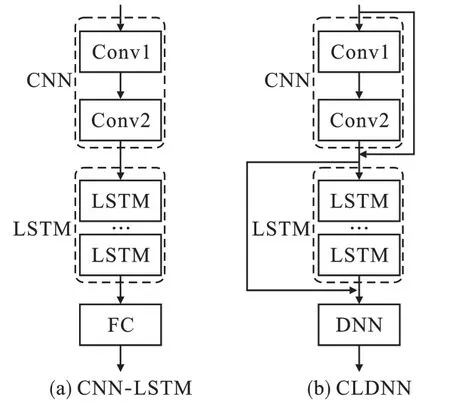
图3 两种混合网络结构Fig.3 Two hybrid network structures
由图3(a)可见,CNN-LSTM 在CNN 后级联LSTM,再连接到FC,完成信号的分类;由图3(b)可见,CLDNN 是由CNN、LSTM、DNN 组成的混合网络模型,CNN 与LSTM 模块均对输入和输出进行了拼接,最后连接到DNN,完成信号的分类。
2 CLRD 网络模型
鉴于传统网络模型存在调制方式识别率不高的问题,本文将CNN、LSTM、ResNet 和DNN 模型进行组合,提出一种双通道混合网络(CNNLSTM-ResNet-DNN,CLRD)模型。
信号数据的空间特征一般使用CNN 提取,但随着网络层数加深,不可避免地出现梯度消失或梯度爆炸,导致网络性能下降,但ResNet 可以很好地解决该问题。 对于N个残差块组成的残差网络,其输出a[N]可以表示为残差块所有输出的累加与第k层网络输入a[k]的和,表达式为
式中:a[i]表示第i层网络的输入;w[i]表示第i层网络中所对应的权重参数;f(•)表示图1 虚线框内的两层卷积运算。
针对式(5)进行反向传播运算,设损失函数为l,运算后可得
信号数据的时序特征使用LSTM 提取,LSTM 具备长时记忆功能,是提取时间序列特征的最佳选择。 LSTM 中的记忆单元由Ft和It控制,Ft控制上一时刻记忆单元Ct-1的保留程度,It控制当前时刻候选记忆单元的保留程度,当前时刻记忆单元Ct的计算如式(7)所示。 当前时刻的隐藏状态ht由输出门进行控制,其计算如式(8)所示。
综上,使用本文提出的CLRD 模型,可以充分提取信号的空间和时序特征,以此提高信号调制方式识别的准确率。 CLRD 网络结构如图4 所示。 图中:Concatenate 表示特征融合;Dense 表示密集层;Batch Norm 表示批量归一化。
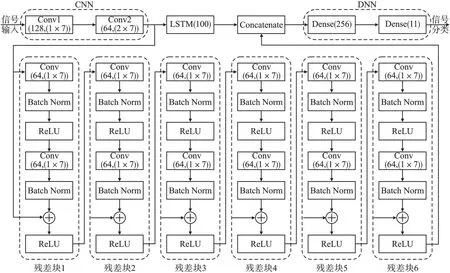
图4 CLRD 网络结构Fig.4 CLRD network structure
由图4 可见,CLRD 模型由两层卷积层、上支路两层LSTM 网络、下支路6 个残差块组成的残差网络以及两层全连接层共四个部分组成。
首先将信号数据输入到两层卷积层中:第一层的卷积核为(1,7),填充为(0,6),步长为1,得到的输出数据维度保持不变,仅通道数变为128;第二层的卷积核为(2,7),填充和步长不变,得到的输出数据宽度减半且通道数变为64。
然后将CNN 模块的输出输入到并联支路(由上支路两层LSTM 网络和下支路6 个残差块共同组成):上支路两层LSTM 网络的隐藏单元个数为100;下支路6 个残差块中的卷积核为(1,7),通道数同样保持64 不变,并使用Batch Norm 技术提升收敛速度。 将两条支路的输出进行拼接,完成特征融合。
最后将并联支路的输出输入到DNN 网络(由两层全连接层和分类器组成),用来对数据进行降维和分类。 其中,两层全连接层的隐藏单元分别为256 和11,最后一层采用Softmax 作为激活函数,输出11 维的概率向量,通过概率值最大的索引得到分类结果。
3 仿真实验及模型性能分析
本文采用RML2016.10a 公开数据集进行仿真验证,该数据集模拟真实信道环境,加入多径衰落、高斯白噪声等影响因素。 其中包含了11 种调制类型:8 种数字调制(CPFSK,GFSK,BPSK,QPSK,8PSK,PAM4,QAM16,QAM64)和3 种模拟调制(WBFM,AM-DSB,AM-SSB)。 信噪比的范围为-20 ~18 dB,间隔为2 dB。 相同信噪比下每种调制方式的样本数为1 000,故总样本数为220 000。 每个样本包含I 路和Q 路分量,采样点长度为128,即单一信号的样本格式为2 ×128。
3.1 仿真实验
实验使用Pytorch 深度学习框架完成所有网络模型的搭建和测试。 对信号数据集采用分层抽样的方式,在同一信噪比下将相同调制方式数据量的70% 作为训练集(抽取3% 作为验证集),30%作为测试集,确保训练的公平性。 在所有网络结构中均使用Adam 优化器,训练模型时的批量大小为512,损失函数使用交叉熵,学习率设置为5 ×10-4,其余参数保持默认值。
将上述处理完成的信号数据集直接送入CLRD 网络模型,参数保持一致,仿真得到损失值随训练次数变化的曲线,如图5 所示。
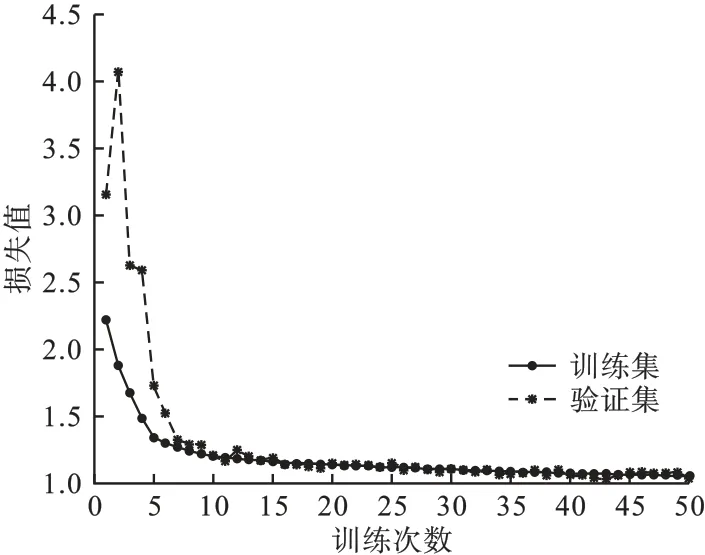
图5 CLRD 网络损失函数曲线Fig.5 Loss function curve of CLRD network structure
由图5 可见,训练次数在45 左右时,损失值趋于稳定,表明网络在此刻的拟合效果最好。
使用LSTM 网络提取信号的时序特征时,层数过少可能导致提取特征不充分,层数过多则加大训练成本,最终都会影响信号的识别准确率,因此实际应用中LSTM 的层数一般不超过3 层。 固定其余参数,设置LSTM 网络中隐藏单元个数为100,在不同的网络层数下,得到信噪比大于-2 dB时的识别准确率,如表1 所示。由表1 可知,两层LSTM 网络可以更好地提取信号特征,识别准确率更高。

表1 LSTM 层数对准确率的影响Table 1 Effect of the layer numbers of LSTM on accuracy
3.2 不同网络模型对比
仿真测试中,分别选取了CNN、ResNet、LSTM、CNN-LSTM、CLDNN 模型与CLRD 模型进行比较。 CNN 模型第一层采用256 个1 ×7 的卷积核,第二层采用80 个2 ×7 的卷积核;CNNLSTM 模型在CNN 基础上级联LSTM 网络,隐藏单元个数设置为100;CLDNN 模型采用文献[14]的网络结构。 测试得到6 种网络模型的识别准确率曲线如图6 所示,各网络在信噪比大于-4 dB时的平均识别准确率如表2 所示。

表2 不同网络模型的平均识别准确率对比Table 2 Comparisons of average recognition accuracy of different network structures
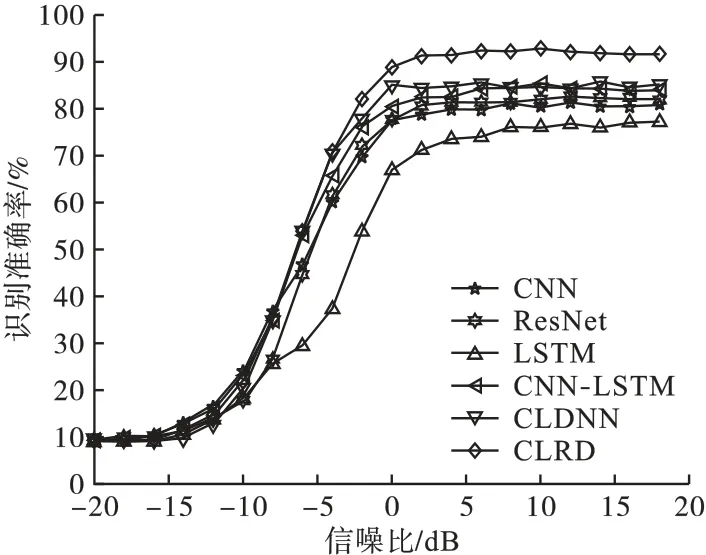
图6 不同网络模型的识别准确率对比Fig.6 Comparisons of recognition accuracy of different network structures
由图6 和表2 可见,当信噪比大于-4 dB 时,CLRD 模型的平均识别准确率明显高于其余5 种模型,可达到90.69%。 用于对比的5 种模型中,CLDNN 模型表现最好,LSTM 模型表现最差。CLRD 模型的识别准确率比CLDNN、 CNNLSTM、ResNet、CNN、LSTM分别提高了7.87%、9.36%、12.69%、14.74% 和25.06%。 相较于CLDNN 模型,本文提出的CLRD 模型引入了深度残差网络,避免了因增加网络深度而造成网络退化,从而提高了信号识别准确率。
3.3 CLRD 模型性能分析
为进一步分析CLRD 模型性能,图7 给出了该模型对11 种信号的识别准确率,图8 给出了信噪比为2 dB 时的混淆矩阵图,图中SNR 表示信噪比。

图7 各类信号的识别准确率对比Fig.7 Comparisons of recognition accuracy of various signals

图8 混淆矩阵图(信噪比为2 dB)Fig.8 Confusion matrix diagram (SNR is 2 dB)
由图7 可知:当信噪比小于-12 dB 时,各类信号识别效果均很差;随着信噪比增加,识别准确率开始稳步提高,当信噪比达到2 dB 时,大多数信号的识别准确率开始趋于稳定,只有WBFM、QAM64 两种信号的识别效果较差。
由图8 可知,CLRD 模型对CPFSK、BPSK、QPSK、PAM4、GFSK、AM-DSB、AM-SSB、8PSK信号的识别准确率接近100%,对QAM16 信号的识别准确率为92%,对QAM64 信号的识别准确率为85%,对WBFM 信号的识别准确率仅有40%。
4 结论
针对传统调制方式识别方法存在识别率不高的问题,提出了一种可以直接处理原始I-Q 信号的双通道混合网络( CLRD) 模型。 基于RML2016.10a 数据集对该模型进行了仿真验证,结果表明,本文提出的方法可完成对11 种调制信号的有效识别,且在信噪比大于-4 dB 时,平均识别准确率达到90.69%,比CLDNN、CNNLSTM、ResNet、CNN、LSTM 分别提高了7.87%、9.36%、12.69%、14.74%和25.06%。 本文提出的方法在调制方式识别领域具有一定的实用价值。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电信科学(2016年9期)2016-06-15
电测与仪表(2016年13期)2016-04-11
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
