
Learning power Gaussian modeling loss for dense rotated object detection in remote sensing images
2023-11-10 02:16YngLIHiningWANGYuqingFANGShengjinWANGZhiLIBitoJIANG
CHINESE JOURNAL OF AERONAUTICS 2023年10期
Yng LI, Hining WANG, Yuqing FANG, Shengjin WANG, Zhi LI,Bito JIANG
a Department of Space Information, Space Engineering University, Beijing 101416, China
b Beijing Institute of Remote Sensing Information, Beijing 100192, China
c Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
KEYWORDS
Abstract Object detection in Remote Sensing (RS) has achieved tremendous advances in recent years, but it remains challenging for rotated object detection due to cluttered backgrounds, dense object arrangements and the wide range of size variations among objects.To tackle this problem,Dense Context Feature Pyramid Network(DCFPN)and a power α-Gaussian loss are designed for rotated object detection in this paper.The proposed DCFPN can extract multi-scale information densely and accurately by leveraging a dense multi-path dilation layer to cover all sizes of objects in remote sensing scenarios.For more accurate detection while avoiding bottlenecks such as boundary discontinuity in rotated bounding box regression, α-Gaussian loss, a unified power generalization of existing Gaussian modeling losses is proposed.Furthermore, the properties of α-Gaussian loss are analyzed comprehensively for a wider range of applications.Experimental results on four datasets (UCAS-AOD, HRSC2016, DIOR-R, and DOTA) show the effectiveness of the proposed method using different detectors,and are superior to the existing methods in both feature extraction and bounding box regression.
1.Introduction
Object detection has developed rapidly in RS and has been applied to marine rescue, disaster prediction, urban monitoring and other areas.Classical detection models use horizontal bounding boxes to locate objects, which includes one-stage object detectors1–3and two-stage detectors.4–6Unlike natural imagery, RS images are recorded by satellites from an aerial perspective, so that objects are densely arranged and appear in arbitrary orientations.Moreover, complex background and large aspect ratio also make horizontal detectors unable to locate the target accurately.By contrast, using oriented bounding boxes can reduce the overlap with background areas and draw the edges of objects precisely.Therefore, it is necessary to conduct researches on rotated object detection for RS images.Current rotated object detection algorithms are designed for different issues.For example, two-stage rotated object detectors7–9are utilized for feature extraction.R3Det10applies one-stage detectors to combine speed and accuracy.Some works11–13are designed for optimizing the position regression of the rotating boxes.Other works14,15are anchor-free frameworks without parameters of anchor boxes.Summarizing the above, current rotating object detection faces two major challenges:
(1) Effective multi-scale feature extraction.Objects in RS images cover a wide range of size variations due to the spatial resolutions of satellite sensors, also due to the size variation between classes (e.g., airport vs.vehicle)and in the class (e.g., carrier vs.fishing vessel).Therefore, the general structure of feature extraction is difficult to extract features of various RS targets, thus increasing the difficulty of object detection effectively and completely.
(2) Accurate bounding boxes localization of arbitraryoriented objects.Massive small objects are densely arranged with cluttered backgrounds in remote sensing images, making it difficult to detect specific locations.For large aspect ratios objects in some categories, small angular changes may lead to large Intersection over Union(IoU) deviation during bounding box regression,which requires other metrics to redefine the regression loss.In addition, the definitions of bounding boxes and the periodicity of the angle will also affect the performance of localization.Therefore, there is still a need to further increase the accuracy of positioning for rotating objects during detection.
In this paper, we provide powerful solutions to the above problems.First,a new feature extraction structure is proposed,which uses a dense multi-path dilation layer to cover all sizes of objects densely in RS images.This structure extracts multi-scale semantic information accurately and efficiently,and performs feature transfer and fusion in deep neural networks.In addition, for more accurate rotated bounding box regression, a new transformation of loss is designed based on existing Gaussian modeling regression losses.Solutions above can be easily integrated into object detector to organize an end-to-end detection network.This also helps improve the detection performance without enhancing the training difficulty.
To summarize, the key contributions are summarized as follows:
(1) To enrich the spatial representation of semantic features,we explore a new sub-network called DCFPN.It can expand the scale ranges of receptive fields, and extract feature maps densely and effectively; and therefore, further improves the ability to detect objects of various sizes in RS images.
(2) We propose α-Gaussian loss,a unified power generalization of existing Gaussian modeling losses including GWD,16KLD,17and KFIoU,18to obtain an accurate and reliable rotated bounding box regression.Experiments show that our approach outperforms existing regression losses based on gaussian distribution, and improves the detection efficiency.
(3) We analyze the properties of α-Gaussian loss comprehensively.Specially, through theoretical analysis, it is shown that the proposed approach can also be applied to other Gaussian-based regression loss using related statistical distances (such as Bhattacharyya Distance19(BD)).
(4) We perform extensive experiments on four publicly datasets, UCAS-AOD,20HRSC2016,21DIOR-R22and DOTA.23Experimental results show excellent performance of our approach.
2.Related work
2.1.Rotated object detection
To avoid effects of dense horizontal overlapping bounding boxes and represent target locations accurately,rotated object detection uses rotated bounding boxes to represent arbitraryoriented objects, as shown in Fig.1.ROI Transformer,7ICN,8CAD-Net,24AOOD25and SCRDet9are two-stage rotation detectors focusing on feature extraction and fusion.More recently, oriented R-CNN26designed a light-weight oriented RPN and rotated RoI alignment to promise accuracy and efficiency.DODet27proposed a new representation scheme of oriented objects and a localization-guided head to alleviate the spatial and feature misalignment.R3Det10designed a feature refinement module in single-stage rotation detector to obtain fast speed and better accuracy.Gliding Vertex13and RSDet28accurately described the rotated object by regressing the four vertices.Axis Learning15proposed an anchor-free method to reduce computational complexity in one stage.O2-DNet14located each rotated object by predicting a pair of middle lines of the object.Hou et al.29proposed feature pyramid and feature alignment module based on one-stage cascade detector.RADet,30FFA,31DRN32generated fine feature maps for rotating object, and improve the feature representation ability of network for rotating object.LO-Det33designed new channel aggregation and constraint head structures for lightweight detectors.Although these rotating object detectors have made experimental results on public datasets, some issues still remain.
The key point of rotated object detection lies in the accurate positioning of large aspect ratios objects in complex environments.To predict the rotated bounding box more accurately,the regression loss needs to be further optimized.
2.2.Bounding box regression loss
Most detectors extend l1,l2-norm or their variants as regression loss of bounding box.For instance, Fast R-CNN1uses smooth L1 loss34which independently regresses four variables of the horizontal box, ignoring the correlation between the variables and affecting the accuracy of locating.UnitBox35firstly introduced IoU loss function to regress the prediction box as a whole unit in bounding box prediction.Tychsen-Smith and Petersson36proposed Bounded IoU Loss for object detection to maximize the IoU within the ground truth and the Region of Interest(RoI).A series of IoU-variants loss such as GIoU,37DIoU and CIoU38are subsequently developed for horizontal box regression.Focal-EIOU39and RIoU40pay more attention to high IoU objects.
These functions cannot be used directly in rotating object detection.Not only because rotation detectors have an additional angle parameter which may lead to boundary discontinuity during angle rotation, but the rotating IoU is indifferentiable as well.From the perspective of regression loss optimization, SCRDet9adds a constant factor calculated by IoU to smooth L1 loss, which is more straight forward and effective to solve the problem of the boundary discontinuity.CSL11changes the regression problem of angular prediction into classification.DCL41proposed a new encoding mechanism that further solved the boundary discontinuity problem introduced by long edges definition of bounding box.CenterMap42converted the oriented bounding box regression into the center-probability-map-prediction issue to recognize the target locations and the background pixels.PIoU Loss is proposed by Chen et al.12to accumulate the contribution of all pixels in internal overlapping and calculate directly,which utilize both angle and IoU in regression,and is applicable to both horizontal and rotated bounding boxes.Zheng et al.43designed a projection method to measure the intersection area and solve the uncertainty of convex aroused by arbitrary rotation.BBAVectors44first regresses boundary-aware vectors and obtains the bounding boxes by detecting the center keypoints of the targets.In addition, to tackle the insensitivity to square-like problem and boundary discontinuity issue in rotating detection fundamentally, a series of regression loss function are generated based on Gaussian distribution.Yang et al.16proposed a differentiable loss based on the Gaussian Wasserstein Distance (GWD) by converting the box in arbitrary direction to a two-dimensional Gaussian distribution.Normalized Wasserstein Distance (NWD) is designed by Xu et al.45to estimate the similarity between bounding boxes by their corresponding Gaussian distributions for tiny object detection.Based on Gaussian distributions, Llerena et al.46also presented a similarity measure using the Hellinger Distance.KLD17calculates the Kullback-Leibler Divergence(KLD) between the Gaussian distributions and converts it to the regression loss form.Compared to previous works, KLD dynamically adjusts the gradients of each parameter in bounding box on the basis of the properties of the object.Yang et al.proposed KFIoU18to utilize Gaussian distribution modeling and mimic the mechanism of SkewIoU inherently by Kalman filter, with no need for additional hyperparameter tuning.
2.3.Gaussian based metrics for rotated bounding box
Using different statistical distances to measure Gaussian distribution,we firstly model a rotated bounding box B(x,y,w,h,θ)as a 2-D Gaussian distribution N(m,Σ) by the following formula:
where R denotes the rotation matrix, and Λ denotes the diagonal matrix of eigen value.Specifically, the center point m is represented by the center coordinates of the box, and the covariance matrix Σ is represented by its width, height and rotation angle in the Gaussian distribution.Thus, the regression of rotated boxes can be changed into the distance measure of two Gaussian distributions, as shown in Fig.2.In the new parameter space, N(mt,Σt) and N(mp,Σp) express Gaussian distribution of ground-truth box and predicted box severally.Different distance metrics are shown as follows.Gaussian Wasserstein Distance16is expressed as:
Kullback-Leibler Divergence (KLD17):
KFIoU18uses Kalman filter to obtain the distribution of the intersection area:
Then the area of corresponding rotating boxes is calculated:
3.Proposed methods
3.1.DC-FPN

Fig.2 Visualization of representing a rotated bounding box B(x,y,w,h,θ) by a two-dimensional Gaussian distribution modeling N(m,Σ).
Objects in RS images usually have large differences in size, so the feature maps output by neural networks must be able to cover different receptive field scales to extract complete object features.FPN47uses the pyramidal structure of convolutional networks to extract high-level semantics throughout.First, it utilizes the bottom-up structure to extract feature maps at different scales, following the top-down structure to up-sample these feature maps.The up-sampling results are then merged with the corresponding bottom-up layers through lateral connections,and finally it outputs feature maps of higher pyramid levels and thus fuses stronger semantic information.However,for the case of larger input image in remote sensing scenes,the receptive field size of the top feature extraction layer should match the input image size to obtain a desired performance,which requires to stack more layers to ensure that the receptive field sizes are appropriate.Nonetheless, with the deepening of the convolutional layer, there will be a contradiction between the feature maps resolution and the receptive field size, that is, high-level feature maps are always with quite low resolution.At the same time,with the stacking of convolutional layers, there is only elements adding and merging between different receptive fields, but no communication and propagation between semantic information.All of these result in the limitation of detection performance and bring great challenges to the design of feature extraction structure.
To solve effectively, we design Dense Context Feature Pyramid Network (DCFPN) on the basis of FPN, as shown in Fig.3.The Dense Context (DC) module utilizes multipath dilation layers with different dilation rates to extract rich semantic information in large receptive fields of various sizes.In addition, we introduce dense connections to address the vanishing gradient problem in deep networks, while further merging and propagating multi-scale information to enhance semantic information exchanges.
The basic FPN outputs the last layer of each stage as C2 to C5 in the bottom-up pyramid.Then connected to the topdown pyramid, the output low-resolution feature maps are sequentially up-sampled and element-wise added with the matching Ci to obtain the corresponding feature map set from P2 to P5.
For the purpose of extracting underlying semantic information and increasing the receptive field scale, we join the extra{P6, P7} layers into the top-down pyramid based on the official settings of FPN, so that the network can detect more targets of different sizes.
Moreover, adding a DC module after C5 can obtain larger receptive fields without significantly increasing the computational overhead, which supports the feature transfer and enhances the exchanges of contextual information among the deep network.This structure provides global information for large objects in high resolution images, and is conducive to the feature extraction of dense small objects.Inspired by the dense structure,48the DC module consists of cascade dilated convolutional layers,hence the neurons of intermediate feature maps are capable of encoding semantic information from multiple scales.Besides, neurons in each layer are densely connected to tackle the gradient disappearance issue in deep convolutional networks, while covering the semantic information of multi-scale large receptive fields.Each layer can be described as:
where Ak,r(∙)denotes the convolutions with the filter size k=3 and dilation rates r of 3, 6, 12, 18, 24, which respectively correspond to the densely stacked layer y1to y5.An extra upsampling skip connection U(∙) is added in parallel with the dilated convolutional layer to directly transfer more precise locations of features which can be described as:
where C denotes the feature map extracted by the bottom-up pyramid.Finally, the outputs of the DC module and the C5 layer are attached with 3 × 3 convolutions and layer fusion,then generate P(∙) to perform feature fusion.Later, the classification and regression subnetworks cooperate to implement object detection.The above can be expressed as follows:
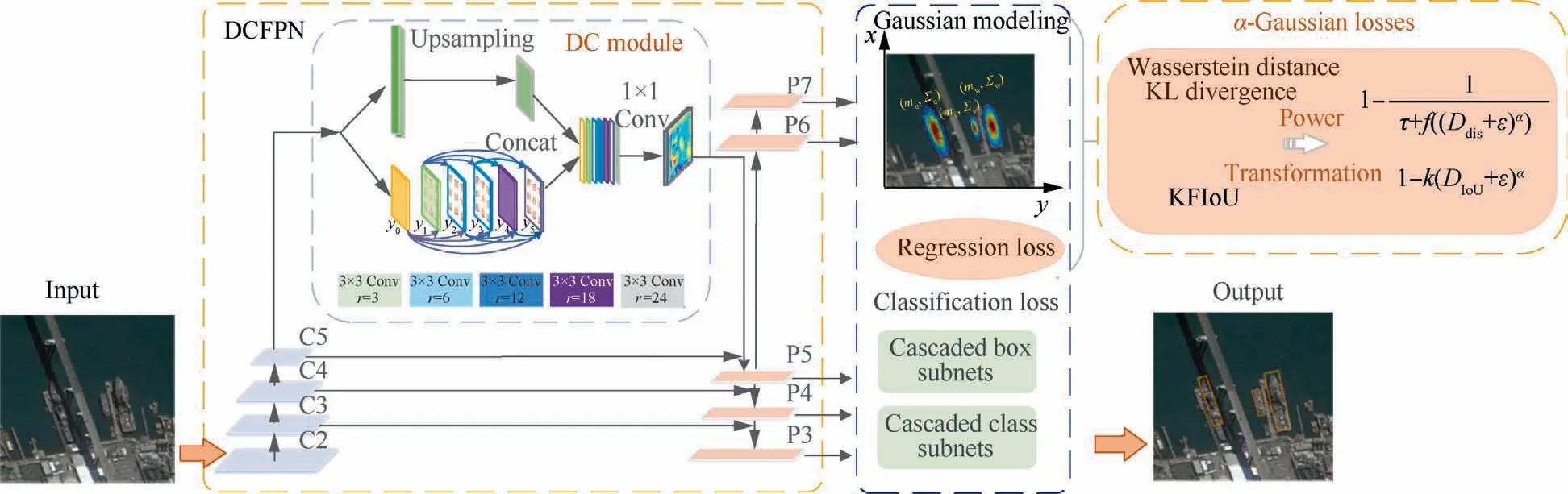
Fig.3 Network artitecture for rotated object detection, containing the proposed DCFPN and α-Gaussian losses for rotated bounding box localization.
where Det(∙) represents the object detection process for input image I and object OP,S(∙)represents the classification subtask and the regression subtask in our proposed model.
As shown in Fig.4, the basic FPN model cannot extract enough features for the object of interest.In contrast,DCFPN has achieved improvements in feature extraction, which is more advantageous for acquiring various objects in RS images.The extracted features are more significant, the shape is clearer, and the location is more accurate, which prove that our method obtains more powerful feature information and achieves performance increase.Furthermore,a visual comparison of the feature maps is performed,as shown in Fig.5.FPN may have feature omission in the initial extraction process(see the airplane in Fig.5(b)for details).While the DCFPN module proposed in this paper can highly distinguish the object of interest,suppress the background and noise,and refine the feature extraction effectively.
3.2.α-Gaussian losses for rotated bounding box regression
Many kinds of objects appear with large aspect ratios such as bridge, ship, airport and harbor in remote sensing scenarios.Especially after introducing the angle parameter in rotated object detection,small changes in angle,center point position,and aspect ratio will all affect the regression and convergence speed of the network.Thus, the difficulty of object detection precisely is increasing.
Recent advances in arbitrary object detection convert the ln-norm metric or IoU-based loss within the ground-truth box Bp(xp,yp,wp,hp,θp) and the predicted box Bt(xt,yt,wt,ht,θt)into the calculation between two probability measures N(mp,Σp) and N(mt,Σt).The introduction of Gaussian distribution and probability measures solve the problem of inconsistency between metric and loss, boundary discontinuity and square-like problem.These different Gaussian modeling probability measures can be uniformly expressed as
There are two ways to transform the probability measures into regression losses.For distance metrics such as GWD16and KLD,17current methods generally use nonlinear functions f(∙) to Ddis, and the regression loss can be denoted as:
where hyperparameter τ modulates the entire loss.For IoU metrics such as KFIoU,18the regression loss is described as:
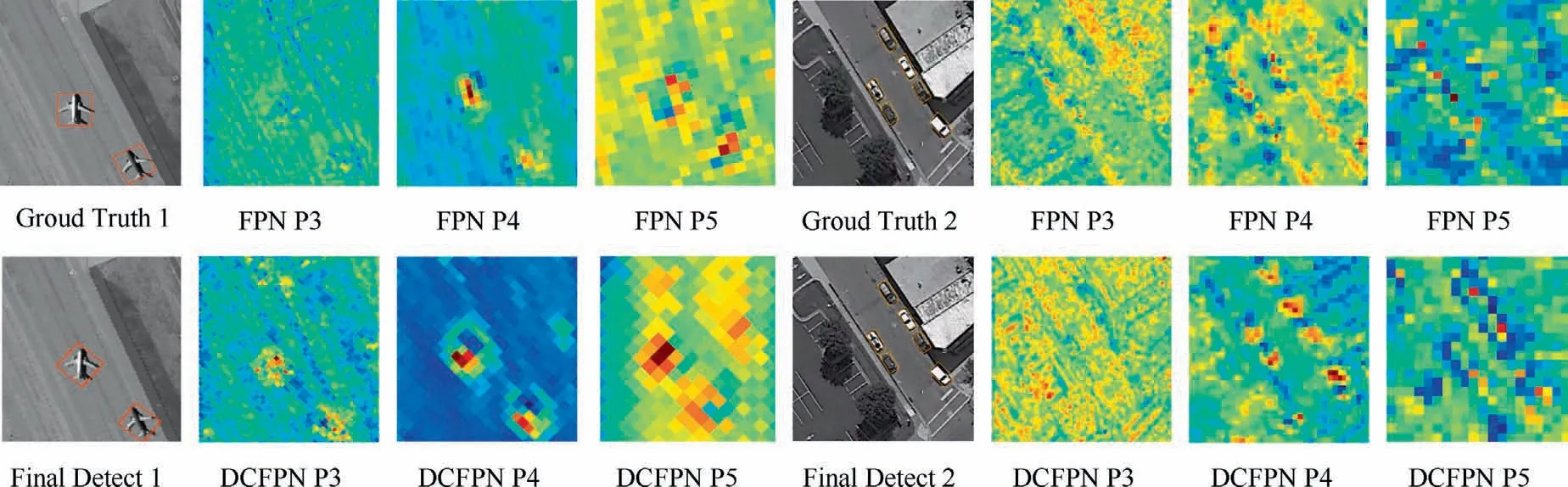
Fig.4 Visualizations of pyramid features in FPN and our proposed DCFPN for two kinds of objects(airplane and vehicle,left half and right half).For each kind,first row represents the ground truth and obtained features of P3,P4 and P5 pyramid layer in FPN.The second row represents the final results and features of P3, P4 and P5 pyramid layer obtained by DCFPN.

Fig.5 Visualization of feature maps.
where k(∙) is the loss concerning function.
To enhance the performance of object localization, we utilize the Box-Cox transformation49to the loss function based on Gaussian distribution metric.(The Box-Cox transformation has been applied for converting the Cross Entropy (CE)loss into the Generalized Cross Entropy (GCE) loss50to improve the robustness of noisy labels in classification tasks.He et al.51applied it to transform the IoU loss to an α-IoU loss, thus improved the performance of horizontal object detection on multiple datasets benchmark).We perform Box-Cox transformation on the existing Gaussian modeling regression loss function, and simplify the parameters in form to make the regression smoother and more expressive,also easier to train and converge.The power transformation of Gaussian modeling regression loss, α-Gaussian loss is calculated as follows:
where α>0, and ε represents the regularization term.
We use Fig.6 to compare IoU loss, Gaussian based losses including GWD, KLD and KFIoU, and the corresponding α-Gaussian losses.Fig.6(a)depicts the change of losses with two different aspect ratio cases.Fig.6(b)demonstrates the effect of the center point offset on different loss function.Fig.6(c)explores the relationship between angle difference and losses.It can be seen from the figures that α-Gaussian losses maintain the monotonicity of losses based on Gaussian distribution.Furthermore,with the changes of aspect ratio,offset and angle difference, the original IoU and Gaussian based losses represented by solid lines change more drastically and are more sensitive to large errors, especially when the predicted value is close to the true value.In most cases, our α-Gaussian loss in dash lines has a more stable and moderate trend compared with the corresponding loss,which makes the network training easier.
3.3.Properties of α-Gaussian losses
As α-Gaussian losses may extend to different forms and variants corresponding to Gaussian modeling loss functions.We analyze and summarize the properties theoretically before using.
(1) Monotonicity.For both distance and IoU metrics loss functions, we let Piand Pjbe the predicted bounding boxes of models Tiand Tj, GT is the ground truth.The following deduction can be drawn:
By calculating min LGuassianand min Lα-Guassian, the corresponding optimal solution of the model can be obtained.The above inference indicates that Lα-Guassianis consistent with LGuassianin monotonicity.
(2) Scale invariance.For LGuassianwith scale invariance such as KLD, the transformed Lα-Guassianstill has the affine invariance, which can be described as follows:

Fig.6 Comparison of different losses in three cases of rotating boxes.

Hence, the scale invariance of KLD is proved.
(3) Horizontal detection task.For the horizontal detection task, we set the rotation angle term in parameters to 0 after using the Gaussian modeling and calculating the bounding box.Then,the loss function based on distance metric is approximately comparable to the l2-norm loss.Meanwhile, the IoU-based loss function in Gaussian distribution has not changed and can also be used directly.As a result,the α-Gaussian losses are also applicable to the regression loss in horizontal detection task.
(4) Universality.To demonstrate the universality of our power transformation of Gaussian modeling regression loss, we introduced a new Bhattacharyya distance(BD19).In our definition of Gaussian distributions, the Bhattacharyya distance is defined as:
Then we apply the power transformation and, the final regression loss is written as:
Comparable with KLD,BD is also scale invariance.Therefore, the extended loss of BD also conforms to the previous three analysis.In subsequent experiments, it is proved that our loss has performance improvement in BD compared to the original function.
3.4.Overall loss function
We employ RetinaNet6as our baseline.The rotated bounding box is denoted as (x,y,w,h,θ).The overall training loss is:
where hyper-parameter λ1,λ2control the trade-off.N indicates the number of anchors.The classification loss Lclsdenotes focal loss.6pndenotes the n-th probability of different classes,tnrepresents the label of n-th object.objnis a binary number,objn= 1 as objects and objn= 0 as background.Lα-Guassianis the regression loss where bnand gtnrepresent the n-th bounding box and ground-truth.
4.Experiments
We evaluate our proposed method on four typical datasets of remote sensing images, UCAS-AOD, HRSC2016, DIOR-R and DOTA.The following subsections introduce datasets,implementation details, ablation study and overall comparison, respectively.
4.1.Datasets
UCAS-AOD20consists of 1510 aerial images(659×1280 pixels) in two categories of 14596 objects, including vehicles and planes.In accord with DOTA,23we sample 1110 images as the training set and 400 as the testing at random.
The HRSC201621dataset contains 1061 ship images which are captured from Google Earth and annotated with rotated box.The spatial resolution ranges from 2 m to 0.4 m.The sizes of images in the dataset cover from 300 × 300 to 1500 × 900.We split the dataset into training,validation and test set which contains 436 images, 181 images and 444 images respectively.
DIOR-R22is an oriented object detection dataset composed of large-scale RS images, which contains 23463 images(800 × 800 pixels).The image resolution is between 0.5 m and 30 m.The dataset covers 20 common categories including 192518 instances.In our experiments, 11725 images are selected as training set, and the remaining 11738 images are used for testing.
DOTA is one of the most commonly used public datasets in remote sensing consisting of 2806 images and the image size is 4000 × 4000 pixels.The 188282 instances in 15 categories are of different orientations, and labeled by an oriented quadrangle.The dataset is divided into three subsets, training set, validation set and test set for 1/2,1/6,1/3 of the whole dataset.All images in training and validation sets are segmented into subimages of 600×600 pixels,overlapping by 150 pixels,and the segmented images are rescaled to 800 × 800 as the training dataset for training.
4.2.Implementation details
We apply Tensorflow52and run all experiments with NVIDIA V100 GPUs.Experiments are initialized by Resnet-5053pretrained on ImageNet.54We use five pyramid layers {P3, P4,P5, P6, P7} to generate anchors.The batch size is set to 1 and the total epoch is 20 for all datasets.The weight decay and momentum of the momentum optimizer are set as 0.0001 and 0.9.and learning rate is 0.0005,and reduced at 8 and 14 epochs.For all datasets, we use the data augmentation for training,including random flipping and rotations.The image iterations per epoch for HRSC2016, UCAS-AOD, DOTA, and DIOR-R are 130000, 10000, 540000 and 282000 respectively.
4.3.Ablation study
We use RetinaNet as the base detector to conduct ablation study.Specifically, the baseline utilizes original FPN and smooth L1 regression loss unless noted specifically.
4.3.1.Ablation test of DCFPN
The results on four different datasets with DCFPN can be found in Table 1.The performance in four datasets, UCAS-AOD, HRSC2016, DIOR-R, and DOTA are increased by 0.46%, 3.15%, 3.34% and 1.30% respectively compared with the baseline (RetinaNet + FPN).The results show that the DCFPN is highly effective in detecting different kinds of objects.With a stronger R3Det detector, the highest performance improvement has also reached 2.36%in DIOR dataset.This also proves that when DCFPN is used to extract feature information, it is more advantageous to obtain the receptive fields of multi-scale objects in RS images.

Table 1 Ablation studies of DCFPN on four different datasets.
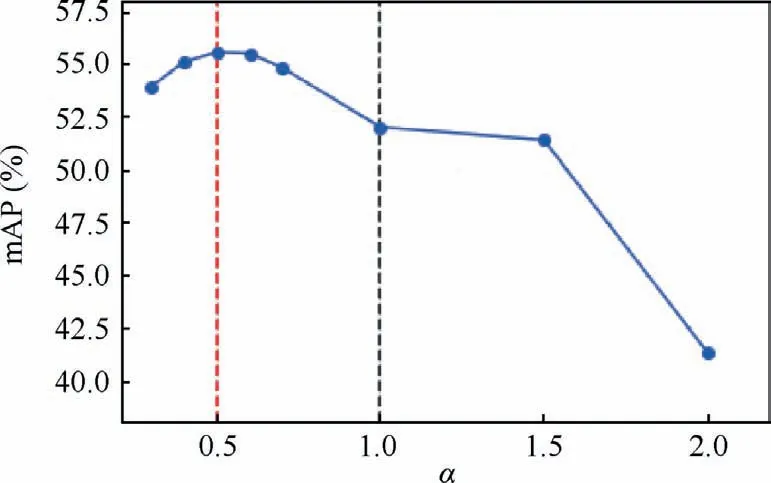
Fig.7 Ablation study of Power parameter α on DIOR-R dataset.Red dashed line denotes Lα-Guassian with α=0.5 while black dashed line denotes the baseline.

Table 2 Ablation study of the hyperparameter on DIOR-R.
4.3.2.Ablation test with different power parameter in α-Gaussian losses
We analyze the availability of α-Gaussian losses, and the performance changes of α-Gaussian losses under different α values are compared on DIOR-R dataset.Here we set

Table 4 Performance evaluation on horizontal detection.
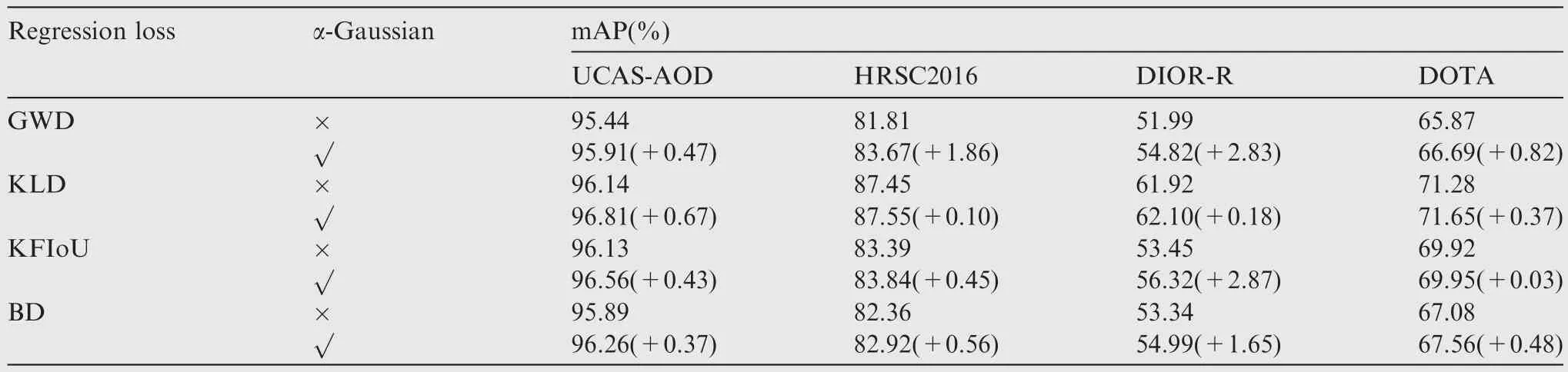
Table 3 Ablation studies of α-Gaussian across different regression losses on various datasets.‘α-Gaussian’ indicates that power transformation is used on regression loss.
where α=0.5, τ=1, f(∙)=sqrt, ε=1×10-3.As shown in Fig.7, it is evident that Lα-Guassianwith α ∊(0.3,1) performs competitively well.When α=1 in baseline, the mAP is only 51.99.The performance reaches the optimal when α=0.5,with an increase of 3.57%.However, in extreme cases α=2,the convergence effect of model training is poor, and the mAP is only 41.30%,which is 10.69%lower than the baseline.Therefore, a proper choice of α is very important for performance.In our experiments, 0<α<1 is a better choice for Lα-Guassian.τ is a hyperparameter in the simple nonlinear transformation.As shown in Table 2,τ=1 performs the best in different cases.ε is regularization term and we set it to 1×10-3to make it effective.The results also prove that the α-Gaussian loss is a good choice for box regression.
4.3.3.Ablation test with different α-Gaussian losses across several datasets
We use four kinds of regression losses GWD, KLD, KFIoU and BD (mentioned in Section 3.3) on four datasets to prove the effectiveness and universality of α-Gaussian losses.α=0.5 is used for all these losses.The experimental results demonstrate that all four α-Gaussian losses outperform the original regression loss.Additionally, ‘α-Gaussian’ resulted in varying degrees of improvement on different kinds of regression losses on various datasets, as shown in Table 3.Lα-Guassian(KLD)shows the best performance among these loss functions.A greater performance improvement is obtained in the DIOR-R dataset of different losses, about 2.83%/0.18%/2.87%/1.65% on GWD/KLD/KFIoU/BD.This is probably because the fact that DIOR-R dataset has more categories and can comprehensively reflect the effect of the proposed loss transformation.
With regard to the horizontal detection task,we have theoretically analyzed that the α-Gaussian losses can be used as the regression loss in the horizontal detection task in Section 3.3.To make the results more convincing,we continue to compare the smooth L1 loss for horizontal detection with our proposed α-Gaussian regression losses on the PASCAL VOC 2007,55a classic horizontal detection benchmark.We train on about 5 k images in VOC07 trainval set and get the results on VOC07 test set.As shown in Table 4, our proposed losses achieve comparable performance to the smooth L1 loss.In particular, Lα-Guassian(GWD) achieves an improvement of 2.96% compared with smooth L1.

Table 6 Detection accuracy on DIOR-R.
4.4.Overall comparison
In the overall comparison, consisting with the state-of-the-art detection methods, we choose one-stage detector R3Det as base rotation detector to consider both speed and accuracy.Using the DCFPN structure proposed above,the loss function Lα-Guassian(KLD) which performs best in ablation study is selected to compare with other advanced rotation detectors with complex model structures.Specifically, data augmentation and multiscale training are used.
4.4.1.Results on HRSC2016
The HRSC2016 consists of large aspect ratio ships in arbitrary direction,posing a big challenge to the accurate localization in detection.As depicted in Table 5,7,10,13,16,18,28,29,32,42,44,56our method achieves relatively good performance, about 89.98%and 96.12% in term of VOC2007 and VOC2012 evaluation metric.Fig.8 shows the visual results of our method on HRSC2016 dataset.
4.4.2.Results on DIOR-R
DIOR-R is a large-scale dataset with massive categories and complex scenes.We compare our method against several advanced detectors on DIOR-R.We select various classes of objects at different scales, and scenes with dense or sparse object arrangements for visualization.The detection results are shown in Fig.9.Table 6 shows the specific performance of each category of objects.For the detection results of individual categories such as DAM,GC,TS and ST,there is quite some room to improve due to the small quantity of training instances per class, which is less than 1500.Likewise, some small object categories such as BR and VE have not achieved the optimal performance because the scale size is less than 80 pixels resulting difficulty in detecting accurately.Overall, our method outperforms most categories, and has achieved superior performance of about 55.56%.
4.4.3.Results on DOTA
We compare the performance of various detectors on the DOTA dataset.Our method can accurately obtain angle and position information through regression, as illustrated in Fig.10.Even in densely distributed scenarios such as large vehicles, this method can accurately detect arbitrary direction of objects without influencing the visual effect.From the experimental results of ground track field and ships,we notice that our method achieves superior detection ability for multiscale objects, and achieves accurate extraction of features at different scales.The detection results of current advanced methods in each category of DOTA are summarized in Table 7.We classify the detectors into one-stage and two-stage, and labeling the top two performances of each category severally.To reduce the impact of different training tricks, we mainly use Resnet-50(Res-50) as the backbone.It can be seen that we achieve the best performance among these detectors.At the same time, the results show a balanced and excellent performance for each category.Note that our proposed singlestage detector also achieves satisfactory results compared to the more complex feature extraction and processing of the two-stage detector.

Table 7 Detection accuracy on DOTA.
5.Conclusions
To solve the problems of ineffective feature extraction and inaccurate rotated bounding box localization in remote sensing, we propose a new feature extraction structure called DCFPN, which utilizes dense multi-path dilation layers to cover all size ranges of objects in different scenarios.This structure can extract multi-scale information accurately and efficiently by generating larger and denser receptive fields,and perform feature transfer and fusion in deep networks.Meanwhile, a new transformation of losses is designed based on existing Gaussian modeling losses for more accurate bounding box regression in object detection.The properties are further analyzed to prove the effectiveness in theory.We conduct extensive ablation studies and experiments on four public datasets such as UCAS-AOD, HRSC2016, DIOR-R,and DOTA.Experimental results demonstrate that the proposed method outperforms the existing detectors on four challenging datasets, and demonstrates the effectiveness of dense context feature extraction and α-Gaussian loss on rotated object detection task.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
 CHINESE JOURNAL OF AERONAUTICS2023年10期
CHINESE JOURNAL OF AERONAUTICS2023年10期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Experimental investigation of typical surface treatment effect on velocity fluctuations in turbulent flow around an airfoil
- Oscillation quenching and physical explanation on freeplay-based aeroelastic airfoil in transonic viscous flow
- Difference analysis in terahertz wave propagation in thermochemical nonequilibrium plasma sheath under different hypersonic vehicle shapes
- Flight control of a flying wing aircraft based on circulation control using synthetic jet actuators
- A parametric design method of nanosatellite close-range formation for on-orbit target inspection
- Bandgap formation and low-frequency structural vibration suppression for stiffened plate-type metastructure with general boundary conditions