
基于改进SSA算法优化极限学习机模型的土壤供肥量预测*
2023-11-11 04:02李井竹刘秋菊王仲英
中国农机化学报 2023年10期
李井竹,刘秋菊,王仲英
(1.河南牧业经济学院信息工程学院,郑州市,450032; 2.郑州工程技术学院信息工程学院,郑州市,450032; 3.河南经贸职业学院工程经济学院,郑州市,450018;4.河南省智慧农业远程环境监测控制工程技术研究中心应用技术研究院,郑州市,450018)
0 引言
作为农业大国,农业现代化和精准化一直是我国农业领域的前沿发展方向。在农业节水领域,鉴于淡水资源的稀有性,随着理论研究的不断深入和技术的提高,为了满足现代农业对节水灌溉的快捷和准确性需求,农业节水已经逐步走向精准化、智能化和信息化。土壤供肥量预测是农业水肥气一体化领域的关键技术环节,高效精准的土壤供肥量预测能够按照农作物生长不同阶段对养分的需求和气候条件进行精准补肥,提高农肥利用率,确保土壤供氧,实现农作物增产提质,并最大程度降低农药化肥对农田生态环境的不利影响[1]。
目前,研究人员对农作物土壤供肥量预测模型主要划分为物理模型和数据驱动模型。数据驱动模型能够根据历史实测数据构建土壤供肥量的数学模型,拥有比物理模型更好的操作性。而影响农作物土壤供肥量的因素较多,作物生长机理复杂,因此,数据驱动模型通常具备比物理模型更高的预测精度。随着机器学习的不断发展,各研究领域越来越多地引入智能决策模型,这其中应用广泛的包括人工神经网络(Artificial Neural Network,ANN)[2]、支持向量机(Support Vector Machine,SVM)、回归模型(Regression Model,RM)以及极限学习机模型(Extreme Learning Machine,ELM)[3]等。这些数据驱动模型对于复杂条件的非线性复杂系统行为能够更好地预测,是目前的预测热点。人工神经网络ANN具有易于得到局部最优的不足,而支持向量机模型SVM则易受到训练样本的影响,极限学习机ELM因为具备预测精度高、泛化能力强和学习速度快的优点,已被应用于诸多智能决策领域。但标准极限学习机的权重和偏差具有很大的随机性,对训练精度和泛化能力产生了很大的不确定性,为此,很多学者借助于启发式搜索机制对其进行优化,试图降低随机取值对模型预测能力的影响。如:Sheoran等[4]为提高软件构件质量预测的准确度和灵敏度,提出利用蚁群算法优化极限学习机,最后证明预测模型具有较好性能。Liu等[5]结合HW方法和极限学习机对住宅用电进行预测,证明预测模型误差更小。Hazir等[6]结合极限学习机和支持向量机对木材涂层粘接度进行预测,在考虑不同工艺因素的情况下,提高了预测效率和精度。Suchithra等[7]利用极限学习机对农业土壤特征参数进行分类,在泛化能力上提高了评估的准确度。由于针对极限学习机的主要参数是随机选择的,以上文献方法的最终结果容易出现稳定性差、数据过拟合的不足。而在农业领域,Bz等[8]结合混合粒子群优化极限学习机,对西北干旱区气候条件的参考蒸发蒸腾量进行了预测和评估。Ska等[9]为优化能量利用率,提出结合粒子群和极限学习机的环境温度预测模型。Vidhya等[10]为实现电能质量的特征分类,设计增强型粒子群的极限学习机模型。李明军等[11]则针对混凝土大坝的变形预测模型,结合智能优化算法对极限学习机进行优化,以此应对大坝安全隐患。Zkf等[12]则在水电站及水库规律领域结合粒子群和极限学习机对其进行预测,有效提升了预测准确度。以上研究成果都不同程度对预测模型的效率和准确度进行了优化,但依然存在针对复杂高维问题计算效率低、易产生局部收敛以及收敛精度不高等不足。
土壤供肥量预测模型是目前农业灌溉理论领域的重要突破点,为提高土壤预测模型的准确度,本文提出一种融合改进麻雀搜索算法优化极限学习机的农业土壤供肥量预测算法。旨在利用混合多策略改进的麻雀优化算法MHISSA对极限学习机ELM的连接权重和偏差进行寻优,避免随机取值对模型拟合能力的影响,进而建立泛化能力更优和准确性更好的极限学习机下的土壤供肥量预测模型。然后结合农作物生长期中的天气、土壤以及作物本身的实时信息作为优化后的极限学习机的网络输入,为农作物土壤肥料用量及灌溉提供更精准的决策。
1 麻雀搜索算法
麻雀搜索算法(Sparrow Search Algorithm,SSA)是受自然界中麻雀觅食社会行为启发,在2020年提出的群智能优化算法[13]。SSA算法模型简单、可调参数少、寻优性能极佳,已被广泛应用在机器学习超参调优[14]、图像分割[15]、频谱分配[16]、航迹规划[17]等。麻雀觅食过程分工明确,一部分负责搜索食物源,称为发现者。发现者负责寻找食物,并为整个种群提供搜索方向和觅食区域;一部分则利用发现者捕食猎物,称为追随者;还有一部分麻雀作为警戒者,当发现危险时,会及时向其他个体发出警报信号,以便种群立即作出反捕食行为。通常,发现者和追随者麻雀比例一般分别占种群规模的10%~20%,且角色可以相互转换,但比例维持不变。具有较优适应度的发现者搜索能力强,获取食物更快。追随者则根据发现者的行为提高自身适应度。
SSA算法迭代过程中,发现者的位置更新方式如式(1)所示。
(1)
式中:t——算法当前的迭代次数;
Tmax——最大迭代次数;
xi,j(t)——第i个麻雀个体在第j维的位置信息,j=1,2,…,d;
α——随机量,α∈(0,1];
R2——预警值,R2∈[0,1];
ST——安全值,ST∈[0.5,1];
Q——服从正态分布的随机量;
L——1×d的矩阵,元素均为1。
若R2 追随者的位置更新方式如式(2)所示。 (2) 式中:xP,j(t)——当前发现者占据的最佳位置; xworst,j(t)——当前全局最差位置; A——1×d的矩阵,每个元素随机赋值1或-1,且A+=AT(AAT)-1,表示伪逆矩阵。 若i>n/2,表明适应度较差的追随者个体i没有得到食物,已发生饥饿,需飞到其他区域觅食。 警戒者位置更新方式如式(3)所示。 (3) 式中:xbest,j(t)——当前全局最优位置; β——步长控制因子,为服从均值为0、方差为1的正态分布随机量; K——随机量,K∈[-1,1],表示麻雀飞行方向,也是移动步长控制因子; fi——麻雀个体i的适应度; fg——当前全局最优适应度; fworst——当前全局最差适应度; ξ——极小常量,避免分母为0。 若fi>fg,表明此时麻雀正处于群体边界位置,未受到警戒保护,很容易被捕食者攻击;若fi=fg,则表明处于种群中间位置的麻雀已意识到危险,需要相互靠拢以降低被捕食风险。xbest,j(t)为种群的中心位置,也是安全区域。 对于SSA算法,麻雀通过信息共享与交互方式搜索食物源。寻优过程中,虽然发现者具有指引功能,但整个种群的跟随者还是具有较大盲目性,表现为:个体之间交互频率低,可能聚集在局部最优解的方向上,得到局部极值。针对这种盲目飞行现象,改进算法将充分利用当前麻雀和最优麻雀的寻优方向,计算两者的适应度,以此确定个体的飞行模式。具体地,若当前个体适应度小于最优解时,种群受当前个体引领较多;若当前个体适应度大于最优解时,种群受最优解引领较多。该飞行引领方式定义如式(4)和式(5)所示。 (4) (5) 式中:xi(t)——第i个麻雀个体的位置信息; xbest——当前最优解的信息; f[xi(t)]——个体i对应的适应度值; f(xbest)——最优解对应的适应度值; b1——引领因子,且b1∈[-2,1],用于约束种群的引领方向; θ——矫正因子,为随机量,且θ∈[0,1]。 根据式(1)可知,若预警值R2小于安全值ST,则表明发现者麻雀种群个体可以在安全值区域内进行广泛搜索。但在算法迭代过程中,发现者的每个搜索维度都在变小,搜索空间逐渐收窄,逐步失去种群多样性,从而增加了算法陷入局部最优的可能。针对这一不足,为了提升发现者的全局搜索能力,对发现者位置更新方式进行改进。MHISSA算法引入一种基于分段权重的正余弦优化方法对发现者位置进行更新,利用正余弦函数表现出的震荡寻优特性和分段权重的结合,确保发现者麻雀在种群空间内进行广泛搜索,维持个体多样性。 正余弦算法SCA是一种新型启发式搜索算法[18],它可以根据正弦函数和余弦函数的数学特征和变化实现个体更新和目标寻优,其全局寻优能力较强,其粒子位置的更新方式如式(6)、式(7)所示。 (6) 式中:r1——振幅调节系数; r2、r3、r4——均匀分布随机量,r2∈[0,2π]、r3∈[-2,2]、r4∈[0,1]。 (7) 式中:a——常量,一般取值1。 对于SSA算法而言,在搜索前半段,麻雀种群个体需要更强的全局搜索能力,以保持空间的搜索广泛性。此时,个体应该被赋予较大且稳定的权重,确保广泛的全局寻优。改进算法将引入一种对数与指数结合的权重方式以保证权重值的稳定变化,并以自适应调整的方式增强算法跳离局部极值的能力。因此,前半段权重公式设计如式(8)、式(9)所示。 w1(t)=2+γ+logat+lnt (8) γ=e(t/Tmax)-10 (9) 式中:w(t)——分段权重,a=1/2; γ——调节因子,且γ∈(0,1]。 在搜索后半段,麻雀种群个体需要更强的局部开发能力,才能确保种群在局部范围内的集中开采。此时,个体应该被赋予较小且稳定的权重,确保种群进行深度挖掘。改进算法将引入一种指数型权重方式,以自适应方式调小权重值,实现稳定地深度挖掘。因此,后半段权重公式设计如式(10)所示。 (10) 搜索前半段,w1(t)∈(0,1),搜索后半段,w2(t)∈[-1,1)。 结合分段权重的定义,MHISSA算法进行发现者位置更新的方式如式(11)所示。 (11) 在警戒者位置更新公式(3)中,两个控制因子β和K决定了个体的飞行步长,即均衡算法在全局搜索和局部开发间的过渡。但由于标准SSA算法中的β和K是随机取值,无法满足算法对解空间的搜索灵活需求,进而导致局部最优。由于较大的步长因子有利于全局搜索,较小的步长因子有利于局部开发,改进算法MHISSA将使用非线性方式对控制因子β和K进行更新,公式如式(12)、式(13)所示。 (12) K=Kmax-(Kmax-Kmin)· (13) 式中:βmax——β的最大值; βmin——β的最小值; Kmax——K的最大值; Kmin——K的最小值。 步长因子β、K分别以指数函数和正切函数形式实现非线性转换,使步长因子在迭代早期递增较快,迭代晚期快速降低,使得早期可以在更广阔的空间进行全局搜索,保持较好的种群多样性;后期以更快的局部开发,加速算法收敛,从而平衡算法在全局搜索与局部开发间的过渡,提高算法的寻优精度。 对于标准SSA算法而言,麻雀个体的位置更新取决于算法迭代后的位置更新,并通过个体适应度的优劣变化,以择优方式选择下一代的个体。但这个过程中并没有对个体进行变异干扰,导致迭代晚期种群多样性匮乏,容易得到局部极值。改进算法将结合遗传算法中变异的思想,在MHISSA算法中引入对立学习策略对麻雀位置进行变异,提升多样性。 对立学习OBL是一种通过评估问题的可行解及其对立解,并择优保留至下一代种群的优化方法。令x=(x1,x2,…,xn)为问题的一个可行解(即位置坐标),且xi∈[ai,bi],则解x的对立点坐标求解方式为xi′=ai+bi-xi,i=1,2,…,n。MHISSA算法将对立学习机制与变异概率结合起来,具体公式如式(14)所示。 (14) 式中:r——随机量,且r∈(0,1); [lbi,ubi]——个体的搜索空间边界; pr——变异概率; b2——随机量,b2∈(0,1); xnew_i——个体i通过对立学习变异后的新位置。 式(14)表明,若b2≤pr,表明个体i可以通过随机式对立学习扩大搜索范围;否则,则通过一般对立学习扩大搜索范围。 为确保经过对立学习后的变异操作算法具备跳离局部最优的能力,改进算法将通过贪婪择优保存策略保留适应度较优的个体到下一代种群中。其数学模型为 (15) MHISSA算法的执行流程如图1所示。 图1 MHISSA算法流程图 MHISSA算法一共采用四种改进手段对标准SSA算法进行改进,包括在算法第一阶段以飞行引领更新个体位置,降低个体飞行搜索的盲目性;在算法第二阶段以分段权重正余弦优化和非线性步长因子分别对发现者和警戒者个体进行位置更新的改进,提升搜索个体的寻优能力;在算法的第三阶段以对立学习变异对搜索位置进行扰动,降低得到局部最优解的概率。流程图中以虚线框对改进策略的实施位置进行了特别标注。 极限学习机ELM是一种基于单隐层前馈神经网络构建的机器学习算法[19-20]。该算法通过人工设定或随机选择输入层权重和隐含层偏差,根据Moore-Penrose广义逆矩阵理论计算输出层权重。ELM相比支持向量机SVM、反向传播BP单层感知器等神经网络模型,训练参数少、学习速率快,泛化能力也更有优势。令ELM模型有s个输入层神经元节点,I个隐含层神经元节点和M个输出层神经元节点。令模型输入样本为(xi,yi),1≤i≤Q,样本数量为K。xi=(xi1,xi2,…,xis)T∈Rs,表示输入层第i个输入样本,维度为s,yi=(yi1,yi2,…,yiM)T∈RM表示输出层第i个输出样本,维度为M。ELM模型的输出 (16) 式中:wi∈Rs——输入层至隐含层神经元i的输入权重,wi=(wi1,wi2,…,wis)T; g(x)——ELM隐含层的激励函数; βi——隐含层神经元i与输出层的输出权重; bi——隐含层神经元i的偏差。 ELM网络的训练目标是将输出误差最小化,即存在wi、βi和bi,如式(17)所示。 (17) 等同于 (18) 式(18)可简化的矩阵表达式如式(19)所示。 Hβ=Y (19) 式中:H——隐含层输出矩阵。 (20) 网络训练过程中,若g(x)为无限可微,在随机给定输入权重和偏差的情况下,隐含层输出矩阵H不变,则ELM网络的训练过程可以利用最小二乘法求解式Hβ=Y来决定输出权重β,如式(21)所示。 β′=H+Y (21) 式中:H+——H的Moore-Penrose广义逆矩阵; β′——输出权重矩阵。 由于在传统ELM模型中,输入层权重与隐含层偏差的设置具有很大的随机性,导致ELM的训练精度和泛化能力出现下降,模型具有初值敏感的不足。针对这一问题,本文将采用改进麻雀搜索算法MHISSA优化ELM的初始权重和偏差,提升模型的泛化能力。 结合改进麻雀搜索算法MHISSA优化极限学习机的主要思想是:将ELM的输入层权重和隐含层偏差值映射为MHISSA算法中麻雀的个体位置,根据定义的适应度函数,将MHISSA-ELM模型优化问题转化为求解适应度最优时MHISSA算法得到的最优解,即最优麻雀个体的位置。利用MHISSA算法对ELM的输入层权重和隐含层偏差寻优,构建最优ELM预测模型,并对土壤供肥量进行预测。具体过程如下。 step1:确定影响土壤供肥量变化的相关因素,并以此确定极限学习机的网络输入量。 step2:初始化MHISSA算法的相关参数,包括:种群规模n、最大迭代次数Tmax、控制因子β和K的最小值和最大值、变异概率pr。构建极限学习机模型,设置激活函数、隐含层神经元数以及输入层权重和隐含层偏差的搜索范围。 step3:将样本数据划分为训练样本和测试样本,并利用max-min方法对数据进行标准化处理。 step4:根据ELM模型的结构对麻雀个体位置进行编码。以均方误差函数MSE定义评估个体位置优劣的适应度函数如式(22)所示。 (22) 式中:S——数据总量; yi′——ELM模型的土壤供肥量预测值; yi——土壤供肥量实际值。 step5:初始化麻雀种群xi,i=1,2,…,n,将麻雀个体位置编码为(w,b)。 step6:根据式(22)计算种群个体适应度,确定适应度最优个体和最差个体。 step7:通过式(4)的飞行引领策略更新种群个体位置。 step8:确定发现者个体,利用式(8)、式(10)、式(11)的分段权重正余弦优化机制更新发现者位置。 step9:确定追随者个体,通过式(2)更新追随者位置。 step10:利用式(12)、式(13)非线性更新警戒者步长因子;再根据式(3)更新警戒者位置。 step11:通过式(14)、式(15)的对立学习变异机制实施位置扰动。 step12:判断个体位置是否超过(w,b)的边界,若越界,则以相应位置上下限修正个体位置。 step13:若t step14:以x*=(w*,b*)对ELM模型初始化,并利用训练样本和测试样本检测预测精度,得到土壤供肥量的预测值。 基于MHISSA-ELM的农作物土壤供肥量预测模型如图2所示。 图2 基于MHISSA-ELM的土壤供肥量预测模型 根据MHISSA-ELM模型进行土壤供肥量预测,首先需要确定MHISSA-ELM网络的输入样本。由于影响农作物的土壤供肥量的客观因素比较多,而很多因素并不能实现在线精确测量,因此,本文将选择影响权重最大且易于测量的6个影响因素输入网络进行训练,包括:土壤湿度、蒸发量、土壤肥量、平均气温、光照时间和农作物生育期[21-22]。同时需要对输入样本数据进行归一化预处理,即在算法正式训练之前,利用max-min映射函数将所有样本数据映射到区间[-1,1]内,同时为了提高模型的寻优速度,使网络训练中避免出现神经元的饱和,将具体归一化方式定义如式(23)所示。 (23) 式中:x′——预测因子的归一化标准值; x——预测因子原始数值; xavg——原始样本数据预测因子的均值; xmin——原始样本数据中预测因子序列中不同时间的最小值; xmax——相应预测因子的最大值。 该部分利用两个经典基准函数测试MHISSA算法求解函数值的有效性。基准函数种类较多,相同试验也可以扩展到其他基准函数上进行测试。算法参数设置为:种群规模n=30、最大迭代次数Tmax=500。试验环境为Intel(R) Core i5 CPU 2.4G,内存8 GB,64位微软操作系统WIN7,实验平台为Matlab。实验过程为:设置算法的初始参数,并随机生成初始种群分布,根据定义的基准函数计算所有个体的适应度值,确定其中的最优解和最差解。利用式(4)的飞行引领方式更新个体位置,利用式(11)计算发现者个体的位置更新,利用式(2)计算追随者个体的位置更新。利用式(12)和式(13)更新步长因子,并利用式(3)计算警戒者个体的位置更新。最后利用式(14)和式(15)对个体位置进行变异。算法迭代运行500次之后,输出种群中的最优解。 基准函数F1(x)表达式如式(24)所示。 (24) 该函数名称为Schwefel1.2,为单峰函数,维度为30,搜索范围为[-100,100],理论极值点fmin=0。 基准函数F2(x)表达式如式(25)所示。 (25) 该函数名称为Ackley,为多峰函数,维度为30,搜索范围为[-32,32],理论极值点fmin=0。该函数各变量间无明显关联,拐点较多,是一种具有明显局部波峰特征的多模态函数。 单峰函数F1(x)可以测试算法的寻优精度和收敛能力,而多峰值函数F2(x)更加侧重于测试算法是否具备跳离局部最优点的能力。由于对于连续多峰值函数,随着函数维度递增,其局部极值点会呈现指数级增长。选择文献综述部分提及的增强型粒子群优化算法HPSO[10]、改进灰狼优化算法IGWO[11]以及标准麻雀搜索算法SSA[13]进行性能对比。 四种算法在目标函数最大值、最小值、均值、标准方差值、寻优成功率以及寻优时间上的试验结果如表1所示,算法在不同基准函数上的寻优收敛曲线如图3和图4所示。观察试验结果可知,在两个基准函数F1(x)和F2(x)上,本文的MHISSA算法都求解到了最优解,其求解精度是最高的。而最小的标准方差值也说明算法寻优具有更好的稳定性,可以稳定地求解到最优解。对比标准SSA算法,MHISSA算法在原基础上提高了二十个数量级以上的寻优精度,证明改进策略的有效性。而对比另外两种智能算法的改进策略也均有不同程度的性能提升。在算法收敛曲线方面,MHISSA算法明显下坠趋势更加明显,能够更快地接近最优解。SSA算法曲线平缓,说明寻优精度较差,寻优能力有待改进。HPSO和IGWO算法也在经过若干次迭代之后无法进一步提高寻优精度,陷入了局部最优解。将寻优成功率SR定义ξ=10-10,若寻优结果小于ξ值,则视为算法寻优成功;否则,算法寻优失败。可以看到,MHISSA算法在两个不同类型的基准函数上都可以得到100%的寻优成功率,表明在20次独立试验过程中均可以求解到预定义的精度。SSA算法和HPSO算法的寻优成功率为0,表明算法寻优能力还有待提升。从寻优时间上看,MHISSA算法可以以更少的时间求得最优解,表明算法不仅寻优精度更高,而且寻优效率也可以得到保证。 表1 算法的寻优结果 图3 基准函数F1(x) 图4 基准函数F2(x) Wilcoxon秩和检验是一种非参数统计检验方法,可以用于判断改进算法MHISSA与对比算法之间是否具有显著性差别。MHISSA算法的Wilcoxon秩和检验结果如表2所示。p值为Wilcoxon秩和检验值结果,S表示是否具备显著性判定结果。若满足条件p<0.05而S为“+”,则表明MHISSA算法优于对比算法具有强显著性结果;若满足条件p>0.05而S为“-”,则表明MHISSA算法优于对比算法具有弱显著性结果;若p=NaN,则表明MHISSA算法与对比算法之间的显著性结果无法判断。将四种算法独立运行20次取其均值做Wilcoxon秩和检验。根据表2的结果可知,MHISSA算法在两个基准函数测试上都具有显著性结果,无论是单峰函数还是多峰函数,MHISSA算法的Wilcoxon秩和检验p值均小于0.05,且S为“+”,表明MHISSA算法对比SSA、HPSO和IGWO算法在寻优性能上具有显著性优势。 表2 Wilcoxon秩和检验 令麻雀种群规模为n,算法的最大迭代次数为Tmax,个体空间搜索维度为d。根据MHISSA算法的实施步骤,种群初始化阶段的时间复杂度为O(n×d),飞行引领阶段对个体位置进行更新的时间复杂度为O(n×d),发现者、追随者和警戒者的位置仅在更新方式上进行了改变,并未增加更新流程,所以该阶段的时间复杂度为O(n×d),对立学习变异阶段由于是按概率对个体位置进行变异,所以其最差时间复杂度也仅为O(n×d)。此外,MHISSA算法需要迭代Tmax次才能结束,所以除了种群初始化阶段之外,其他过程均需要进行Tmax次。所以,MHISSA算法的最差整体时间复杂度为O(n×d×Tmax),这个与标准SSA算法的时间复杂度是一致的,表明改进算法在试图优化算法寻优性能的同时并未额外增加计算代价。 以一种春季瓜类蔬菜“甬甜5号”在2020年3—8月的观测数据作为训练样本数据,2021年3—8月的观测数据作为测试样本数据。对于这种瓜类蔬菜的主要施肥及生长期是:移苗施基肥于3月19日,移栽定植于3月20日,伸蔓期追肥于4月19日,膨瓜初期追肥于5月10日,成熟期为6月5日。该品种甜瓜在其整个生育期的磷氮钾(分别对应过磷酸钙、尿素和硫酸钾)三种肥料的用量比例为2∶4∶4。施基肥后,磷肥用量为70%,氮肥用量为40%,钾肥用量为40%。剩余肥料用量则通过滴灌系统自动播撒,同时保持作物土壤持水七层为灌水底限。 预测实验的过程为:设置MHISSA算法初始参数,构建极限学习机模型,输入模型网络输入量。划分训练样本和测试样本,并对样本作标准化处理。设置极限学习机模型训练的适应度函数,并计算种群个体适应度,确定种群最优解和最差解。按MHISSA算法迭代搜索最优解,输出极限学习机最优权重值和偏差值,并构建最优预测模型。最后输入测试样本至最优预测模型,对土壤供肥量进行预测。选取四种预测模型与本文的MHISSA-ELM模型进行对比,包括:混合增强粒子群优化ELM的预测模型HPSO-ELM、标准麻雀搜索算法优化ELM的预测模型SSA-ELM、改进灰狼算法优化ELM的预测模型IGWO-ELM以及未进行连接权重与偏差参数优化的标准ELM预测模型。为了提高预测模型的可靠性,四种模型均针对作物从苗期施基肥到成熟期采摘一共80天内的土壤供肥量进行预测。 为了评估模型的预测质量,选择平均绝对误差MAE、平均相对误差RMSE以及拟合度因子R2三个指标对预测结构进行全面评估。MAE可以反映预测值误差的实际情况,其值越小,精度越高;RMSE可以反映预测可信度,其值越小,精度更高;R2值越接近1,表明预测值与实际值具有更高的拟合度。指标相关定义如式(26)~式(28)所示。 (26) (27) (28) 式中:n——选择的样本数量; yi——样本实际值; yi′——土壤供肥量预测值; yavg——实际值均值; yi,avg′——预测值均值。 MAE、RMSE和R2三个评价指标对比如表3所示。在MAE和RMSE两个指标上,本文的MHISSA-ELM模型不同程度地小于另外四种对比模型。在R2指标上,ELM模型拟合度是最小的,即R2值最小,其他四种基于智能群体算法对ELM改进后的预测模型都不同程度地提高了R2值,说明对极限学习机的连接权重和偏差的优化是能够提升ELM模型预测精度的。同时,本文的MHISSA-ELM模型的R2与1最为接近,预测精度最高,这些结论均有效证明本文所采用的改进策略的有效性,能够通过改进麻雀搜索算法对极限学习机ELM在预测精度和模型泛化能力方面实现有效改进。 利用2020年3—8月的观测数据作为预测模型的训练样本集,下一年2021年3—8月的同时段观测数据作为模型的测试样本集。此外,将土壤湿度、蒸发量、土壤肥量、平均气温、光照时间和作物生育期六个因素考虑为影响土壤供肥量预测模型的网络输入量,通过预测模型计算该甜瓜在生育期的土壤供肥量预测值,五种模型的预测值与实际土壤供肥量值的对比图如图5所示。从预测值与实际值对比结果来看,五种预测模型得到的预测值与实际值间的变化趋势是基本一致的,可见结合极限学习机ELM模型的预测机制在农业土壤供肥量上具有一定的预测能力。但从预测值与实际值曲线是的拟合程度来说,不同模型的差别还是比较明显。ELM模型、SSA-ELM模型、HPSO-ELM模型和IGWO-ELM模型的预测值与实际值都存在不同程度的偏差,ELM模型的偏差最多,说明标准极限学习机模型在预测稳定性和泛化能力上还有较大提升空间。SSA-ELM模型优于ELM模型,但依然不稳定,说明标准麻雀搜索算法在寻优精精度上还存在不足。HPSO-ELM和IGWO-ELM模型在部分日期上的土壤供肥量预测值与实际值较为贴近,稳定性和拟合程度要优于SSA-ELM和ELM模型。而本文的MHISSA-ELM模型则得到了所有模型中最好的稳定性和最高的数据拟合程度,部分日期甚至准确率达到100%,说明改进后的麻雀搜索算法通过提升的寻优精度和收敛速度能够增强极限学习机的预测精度和泛化能力。 图5 五种模型的预测值与实际值对比 引入平均绝对百分比误差MAPE进一步分析预测模型的预测精度和稳定性,定义如式(29)所示。 (29) 式中:|yi-yi′|——预测误差。 引入MAPE后的预测误差如图6所示。 图6 引入MAPE后的预测误差 从表4及图6可知,ELM模型的预测误差在[-100,100]kg/hm2之间,最大相对误差为15.9%,MAPE达7.3%,说明标准极限学习机在常量化的连接权重和偏差下预测模型的泛化能力较弱。另外四种基于智能群体优化算法下改进的ELM模型的预测精度都有不同程度提升。SSA-ELM模型的预测误差在[-90,95]kg/hm2之间,最大相对误差为14.3%,MAPE为6.9%,比ELM预测能力更强,弱于HPSO-ELM和IGWO-ELM模型。本文的MHISSA-ELM模型的预测误差基本可以控制在[-10,15]kg/hm2之间,最大相对误差为4.8%,MAPE为1.7%,说明算法出现的误差波动范围最小,对于土壤供肥量的预测精度得到了大幅提高。 表4 引入MAPE后的相对误差值 综合以上模型得到的预测值与样本提供的土壤供肥量实际值之间的拟合程度,并对比模型的相关预测误差结果可知,本文的MHISSA-ELM模型具有更强的学习能力,模型不仅拥有更高的收敛速度,而且在预测精度和性能稳定性方面均优于四种对比模型,在农业智能灌溉领域具有一定应用可行性。 1) 农业灌溉系统的土壤供肥量受多个因素的综合影响,为提高农作物土壤供肥量的预测精度,提出一种基于改进麻雀搜索算法优化极限学习机的农业土壤供肥量预测模型MHISSA-ELM。首先,分别利用飞行引领、分段权重正余弦优化、警戒者步长因子非线性更新和变异对立学习机制对传统SSA算法的全局搜索能力进行改进;然后,利用改进麻雀搜索算法对极限学习机的网络连接权重和隐含层偏差迭代寻优,建立预测精度更高和泛化能力更优的改进预测模型MHISSA-ELM。利用MHISSA-ELM模型研究农业土壤供肥量预测问题。 2) MHISSA-ELM模型的预测误差基本可以控制在[-10,15]kg/hm2之间,最大相对误差为4.8%,MAPE为1.7%。MHISSA-ELM模型得到了所有模型中最好的稳定性和最高的数据拟合程度,部分日期甚至准确率达到100%,说明通过提升寻优精度和收敛速度,改进后的麻雀搜索算法能够增强极限学习机的预测精度和泛化能力。该模型能够结合作物生育期的影响因素对土壤供肥量作出精准预测,在农业智能灌溉领域具有应用前景。2 一种多策略混合改进麻雀搜索算法MHISSA
2.1 飞行引领策略
2.2 分段权重正余弦优化发现者更新机制
2.3 警戒者步长因子非线性更新
2.4 变异对立学习
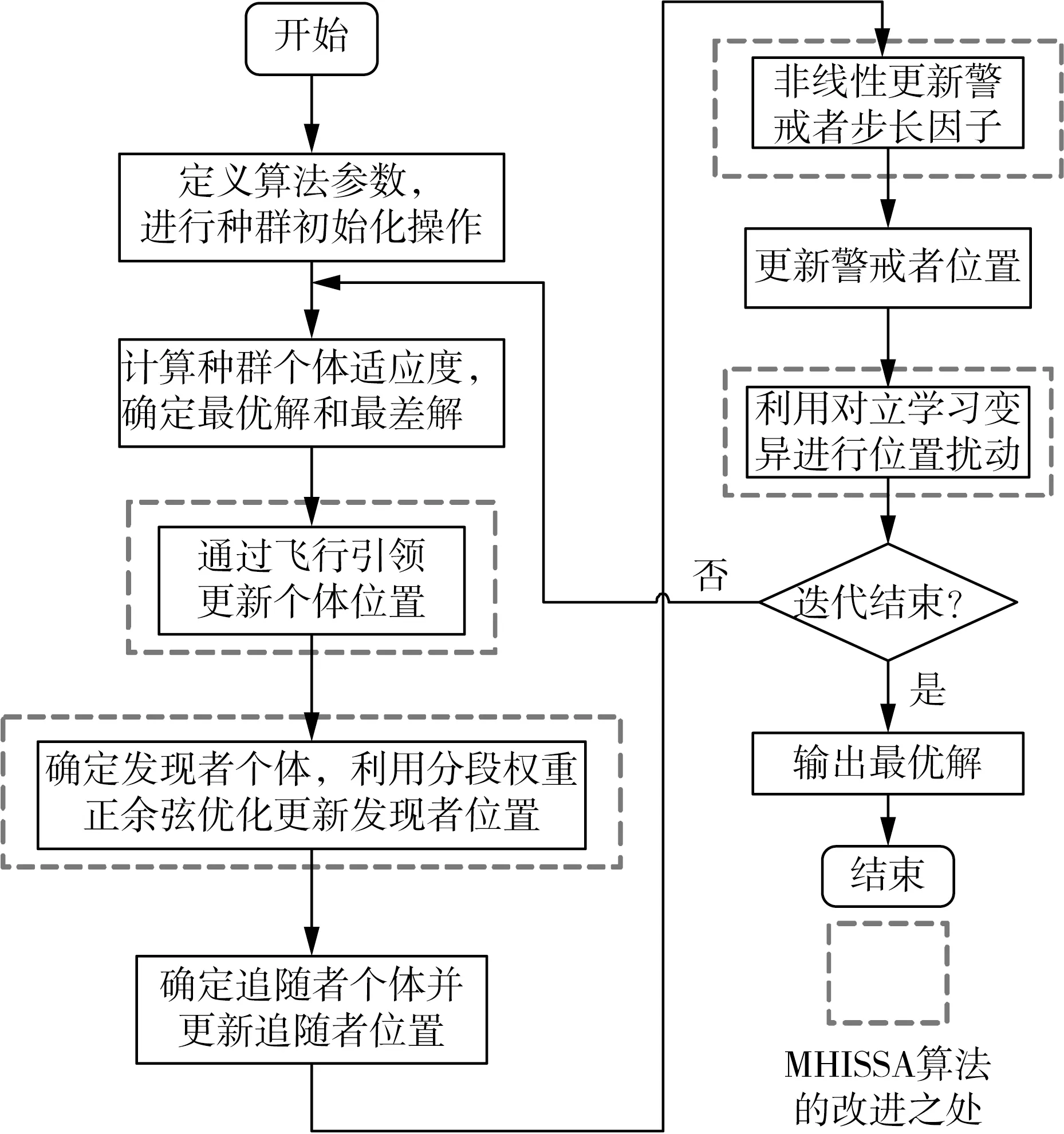
3 基于MHISSA算法优化极限学习机ELM模型
3.1 极限学习机模型
3.2 MHISSA-ELM模型设计
3.3 基于MHISSA-ELM模型的土壤供肥量预测

4 试验分析
4.1 MHISSA算法的基准函数测试及分析

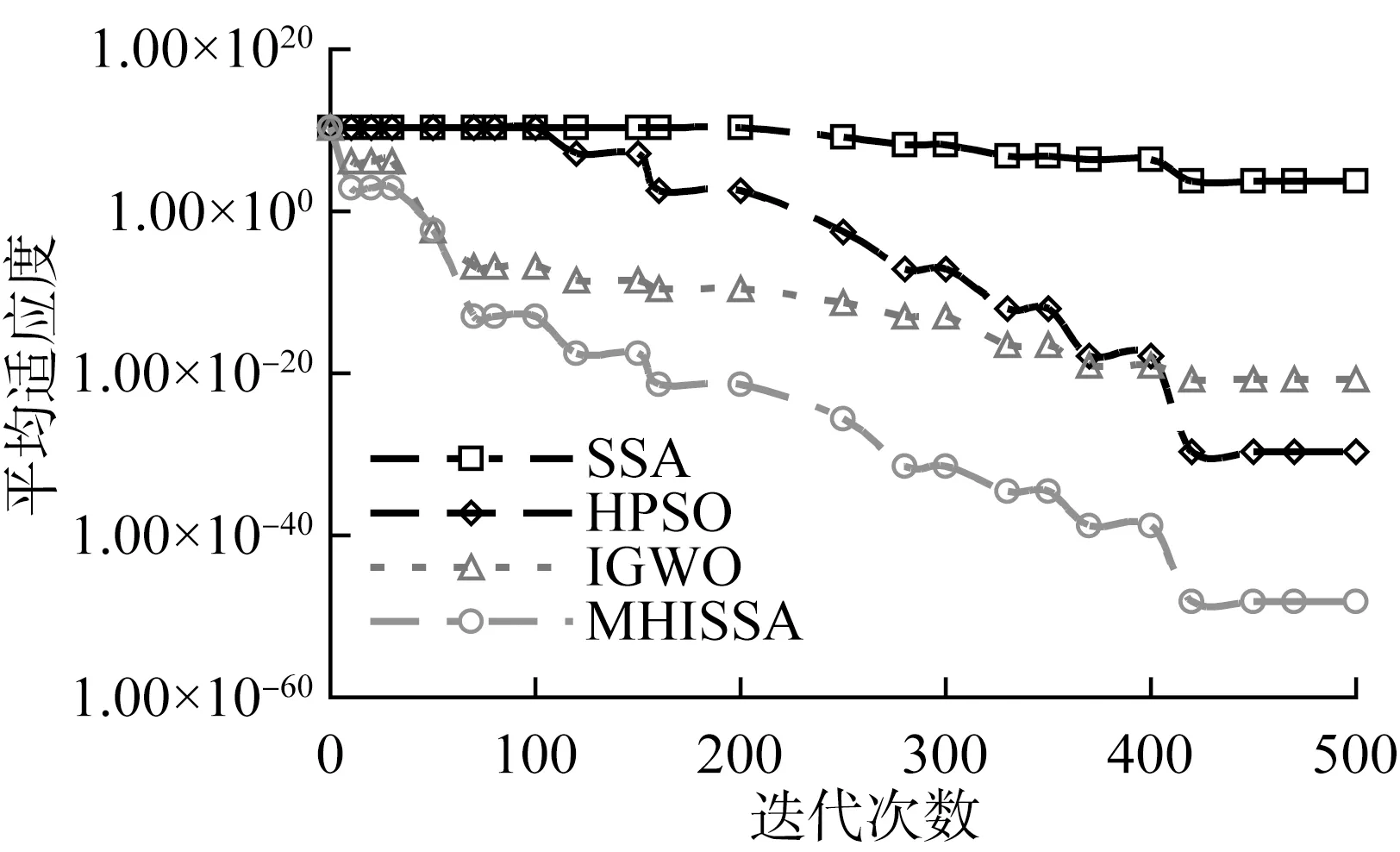


4.2 农作物土壤供肥量预测试验

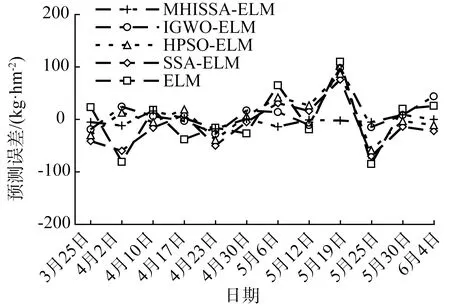
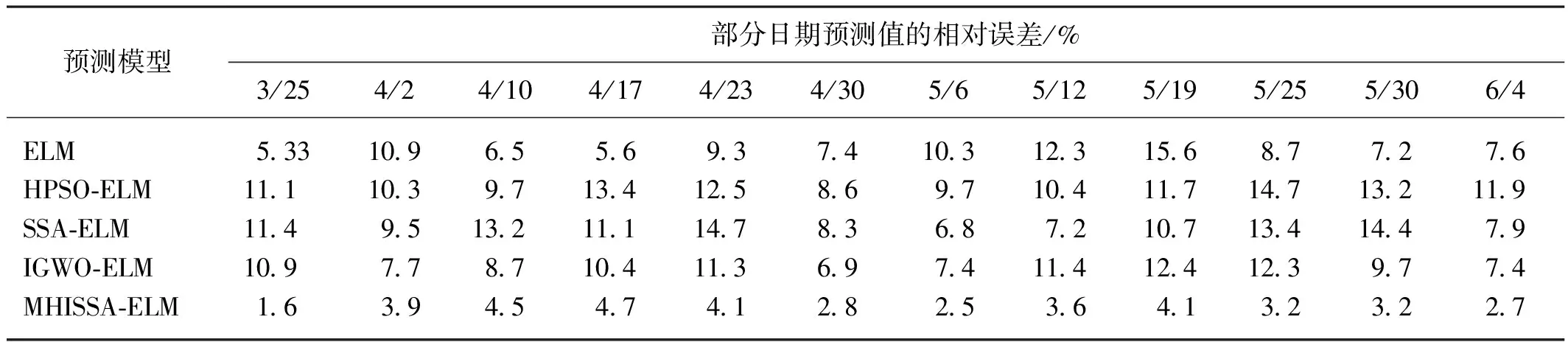
5 结论
猜你喜欢
今日农业(2022年15期)2022-09-20作文小学中年级(2019年10期)2019-11-04新世纪智能(高一语文)(2018年11期)2018-12-29测控技术(2018年10期)2018-11-25红土地(2018年7期)2018-09-26趣味(语文)(2018年2期)2018-05-26自动化学报(2018年2期)2018-04-12制造技术与机床(2017年4期)2017-06-22山东青年(2016年1期)2016-02-28郑州大学学报(理学版)(2014年2期)2014-03-01
