
初级卫生保健领域量表的设计与开发:实用步骤与统计方法
2024-03-08 01:10王飞汤靖琪孙小楠孙昕霙黎俊孟星星吴一波
中国全科医学 2024年13期
王飞,汤靖琪,孙小楠,孙昕霙,黎俊,孟星星,吴一波*
1.100875 北京市,北京师范大学认知神经科学与学习国家重点实验室
2.200062 上海市,华东师范大学心理与认知科学学院
3.150081 黑龙江省哈尔滨市,哈尔滨医科大学公共卫生学院
4.100191 北京市,北京大学公共卫生学院
5.100191 北京市,北京大学第三医院全科医学科
6.230039 安徽省合肥市,安徽大学哲学学院
WHO 在1977 年第30 届世界卫生大会上提出“人人享有健康”的宏伟目标,并指出初级卫生保健是实现这一目标的关键和基本途径[1]。全科医生作为初级卫生保健服务的主要提供者,常需要面临临床和科研的双重压力。在实际的临床工作中,全科医生通常很少使用量表来帮助诊断,但在科研工作中,由于量表具有便捷等优势,量表研究已经成为全科医生青睐的研究范式之一。然而,量表的设计与开发涉及多个复杂且耗时的步骤,这些程序可能会令人望而却步,且其中的部分程序通常会被忽略[2]。这就导致目前量表设计领域研究存在一定的问题,如:一项系统评价研究显示,在纳入的多项使用问卷评估运动员和教练营养态度、营养知识的研究中,约70%的研究使用了效度和可靠性未知的工具,67%的研究使用了未经过验证的工具[3];陈文雄编制的孤独症筛查量表中个别项目的信效度较差,但仍保留在正式量表中[4]。这些未经信效度验证或信效度较差的量表会严重限制结论的准确性,甚至会起到负面作用。因此,制定出能够指导初级卫生保健领域开展量表设计研究的标准化流程十分必要。除此之外,当前大部分初级卫生保健领域的量表设计研究是在经典测量理论的框架下进行的,这一技术对量表心理测量学特性的验证至关重要,但由于经典测量理论的固有缺陷——误差的模糊性和不可知性,常不能保证测量的客观性,Rasch 模型是解决这一问题的良好方法。Rasch 模型以自然科学领域内的客观测量为标杆,为社会科学领域的测量建立起一套客观标准,可以确保测量所提供的信息更为客观和可靠[5]。基于此,本研究将从经典测量理论和Rasch模型两个角度来总结目前国内外初级卫生保健领域常用的问卷编制和量表设计方法,通过对具体步骤和统计学方法的阐述来帮助该领域研究者更好地开展研究。
1 实用步骤与统计方法
1.1 定义测量的构念
在初级卫生保健领域进行量表开发,最重要的一步就是对所需要测量的构念进行准确、概括的定义。定义中既需要解释所要测量构念的内涵和外延,也需要解释这一构念的结构是什么。这种定义通常由经典教材/指南、该领域权威专家、经验丰富的全科医生给出,也可以基于大量文献和调查总结而来。前者在临床上较为常用,为进一步扩展相关方法学应用,本文以基于大量调查和专家访谈确立定义为例。
WANG 等[6]的研究中使了Weiss-Laxer 等基于大量调查和专家访谈确立的定义:(1)研究者首先联系知名家庭健康领域研究者组成专家小组,由研究执行者组成领导小组,以明确专家访谈的最终目标。(2)通过第1 轮专家咨询,专家组提出并共同修改“家庭健康”的概念,由领导小组将概念划分为6 个不同的领域。(3)专家进一步确认各领域的内容及包含的概念,并按照重要性和可行性程度进行划分。最终得出家庭健康的定义为:其是家庭单位层面的资源,从每个家庭成员的健康、互动和能力,以及家庭的身体、社会、情感、经济和医疗资源的交叉点发展而来。在量表编制过程中选用重要的4 个因素:家庭/社会/情感健康过程、家庭健康生活方式、家庭健康资源、家庭外部社会支持。有学者在研究开始前界定了构念的内涵,包含了想要去测量的家庭健康的确切主题,也涵盖了家庭健康的相关维度,为研究的顺利推进奠定了基础,其方法值得研究者学习。研究者也可以根据定义来确定问卷的初始维度和预期目的,以使初始测试尽可能多样化。
1.2 生成条目池
在完成测量构念的定义后,研究者即开始制作初始维度的条目池。代表同一维度的条目池要尽可能冗余,以确保最后能够符合预期条目,也避免在后期数据处理过程中删减条目造成条目数不足等问题。一般来说,研究者所编制量表的条目至少要达到最终保留版本的2 倍。
条目池的生成通常以经典教材、指南、文献和理论为指导,结合针对临床问题的既往研究或已有问卷,通过对已有资料的评估,编制出能够测量各维度特征的问题。因此,在编制量表条目池前一定要明确各维度的定义,根据各维度的定义来编制符合其含义的问题。如高志强等[7]编制成功恐惧问卷时,通过对已有研究进行整理与分析,总结出了成功恐惧的结构维度包括生活品质、家庭幸福、身体健康、心理健康、人际关系和恋爱择偶,然后围绕该6 个维度编制了最初的条目池,并针对施测人群进行了初始化的结构化访谈和半开放式的问卷调查。
在量表设计的语言方面也要遵循一定的原则,在编制量表条目时使用的语言应尽可能简单明了,避免使用专业性词汇和双重否定,因为这会让受访者感到困惑;各条目的语言应尽量避免涉及社会禁忌和个人隐私,防止受访者出现抵触情绪,干扰研究;语言的使用一定要符合受测者所处地区的文化规范,必要时需进行调整。在成功恐惧问卷的编制中,完成对量表内容的制定后还邀请了中文系专家对量表语言进行评估,以排除语意重复和存在歧义的条目[7]。
1.3 选择响应格式和评分系统
1.3.1 响应格式:响应格式选择通常与条目池的生成同步进行,研究者需要根据实际情况和调查的具体目的来选择适合该研究的评分系统和响应格式。
首先,研究者需要确定所编制条目池中每个问题的响应格式,是采用开放式提问的方式还是封闭式提问?开放式提问要求施测对象提供每个问题的答案,这对于受访者和研究者来说难度较大,同时给出的答案具有多样性,不利于进行编码计分。开放式提问的好处是可以为研究者提供更多的思路,一般更适合在初始调查中使用,而在一个成型的量表中使用得并不多。因此,在初级卫生保健领域研究中,使用较多的仍然是封闭式提问。封闭式提问会给出具体的选项,对施测对象来说更容易回答,但这也会造成其他问题,如答案是设置单选还是多选?给出的可选择答案不同是否会影响测量结果?这在量表设计类研究中都是不可忽略的。
在绝大多数量表设计类研究中使用较多的是单选题,但是多项选择仍然是有价值的,因为很多时候一个问题并不会只有一个答案,而多项选择能够提供关于该问题更多的信息。孙昕霙等[8]利用项目反应理论开发出了糖尿病功能性健康素养量表,该量表共30 道题目,其中3 道是多选题,这提供了与糖尿病功能性健康素养有关的更多的信息。在评分方面,该量表将多选题按选项数量每答对1 个选项计1 分,但这种计分方式较为复杂,同时也会受到选项设置的干扰。一般来说,“选择所有正确的选项”的问题可能难以“编码”和评分,应尽可能避免[2]。此外,在封闭式提问设置选项时,仍然需要加以注意。如在量表选项设置中是否应该加入“不确定”这一选项,ALSAFFAR[9]在翻译营养知识问卷时就使用了“不确定”这一选项,但FOLASIRE 等[10]对此提出了质疑,质疑原因为“不确定”选项容易导致那些对选项有很好了解的人在信心低下时避免回答或因为懒惰而选择逃避。除此之外,研究者还应避免将“其他”类别作为选项,当然只有在仔细确定了绝大部分可能存在的潜在类别之后,才能做出不提供“其他”选项的决定。
1.3.2 评分系统:在一份量表中,评分系统的设置需要结合具体条目。一般来说,当问题回答有正误之分时,只需将正确的选项计为1 分,将错误的选项计为0 分。但在大多数时候,受测对象很难做到绝对的二分,因此在实际研究中,常用的评分系统是Likert 评分系统,如Likert 5 级计分、7 级计分、9 级计分等。胡海利等[11]在编制中学生心理复原力量表时即采用了Likert 5 级计分法,以“从不”“偶尔”“有时”“经常”“总是”5个等级进行程度评定,分别计为1、2、3、4、5 分。而在涉及态度的研究中,研究者更倾向于使用“非常不同意”“有些不同意”“中立”“有些同意”“非常同意”5个等级,计分仍然是1~5 分。这两者均属于Likert 5 级计分,而7 级计分和9 级计分则是在5 级计分的基础上进一步将选项细分。那么在研究中该如何选择Likert 量尺点数呢?PODSAKOFF 等[12]认为,当调查对象具有较多的知识和较高的兴趣时,量表需要更多的态度量尺点数,此时使用7 级或9 级计分比5 级计分更合适,因为态度量尺的点数越少,偏态程度越大。
此外,在研究过程中,哪怕是收集了数据后,不同量尺点数的Likert 计分之间仍然可以转换。这种转换是通过Rasch 分析实现的,Rasch 分析可以系统地分析每个选项的测量特性,通过绘制选项概率曲线(category probability curve,CPC)判断是否存在选项等级的滥用和缺失[13]。以2021 年中国居民心理与行为调查(PBICR)中的法式烟草依赖评估量表(FTND)为例作图[14],FTND 的条目1 为“您早晨醒后多长时间吸第1 支烟?>60 min(类别0),31~60 min(类别1),6~30 min(类别2),≤5 min(类别3)”。图1 为条目1 的CPC图,图中每条曲线对应一个选项,横轴代表被试烟草依赖程度(从左往右递增),纵轴代表被试选择的概率。以某位烟草依赖程度为-4 的被试为例,其选择类别0的概率约为95%,选择类别1 的概率约为5%,选择其他选项的概率接近于0。因此,该被试选择类别0 的可能性最大。以此类推,在类别0 与类别2 交点左侧,选择类别0 的概率最大;在类别0 与类别2 交点和类别2与类别3 交点之间,选择类别2 的概率最大;在类别2与类别3 交点右侧,选择类别3 的概率最大。研究团队在测量过程中发现,类别1 选项的使用率偏低,出现了Likert 等级滥用的情况。根据LINACRE[15]的建议,当出现Likert 等级滥用时,应考虑将相应选项与相邻选项合并。因此,这里可以考虑将类别1 与类别2 合并为6~60 min,但合并选项后的量表仍需要再进行检验。需要注意的是,由于FTND 条目1 为多分类选项设置,因此在模型拟合时使用了分步计分模型(Partial Credit Model,PCM)。
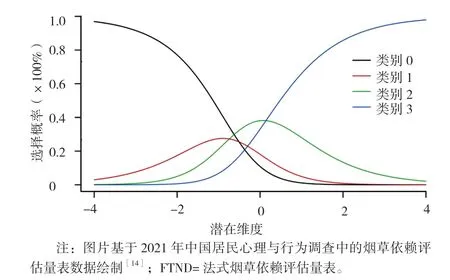
图1 FTND 条目1 的选项概率曲线图Figure 1 Probability curve of item 1 options in the FTND
1.4 预测试
定性预测试是任何问卷或心理测量工具开发、翻译或修订的关键阶段。选取小样本受访人群进行小范围预测试,目的是验证目标受众是否理解条目问题与选项,从受访者角度评价条目表述是否存在歧义,若出现语义理解困难、框架不清晰等问题,需修改条目后进行新一轮预测试,直至确保所有受访者理解条目含义且内容可接受[16]。预测试主要采用便利抽样法抽取样本,尽可能选择30 份或以上样本,以确保数据分析的稳定性与可靠性[16],并需对目标人群进行问卷填写感受与理解度调查。如程彦如等[17]在编制失能老年人照顾者居家照护行为量表时,采用便利抽样法选取了3 个社区的102 名失能老年人照顾者为预测试对象。
预测试环节需进行量表的表面效度测评,即从受访者角度看测评工具内容是否与测评目的一致,表面效度并不是真正的效度指标。在实际应用中,如果直接阅读问卷条目能够明显觉察问卷的测量意图,则该问卷表面效度较高。如测量护理人员洗手状况的问卷涉及洗手次数、时长及方法等,故此问卷具备表面效度[18]。在初级卫生保健领域,研究者想要考察患者的行为情况或针对某一病情进行详细询问,必然应当提高量表的表面效度,确保“所答即所问”;然而在涉及个人隐私方面或影响社会形象的问题上,表面效度过高可能会导致欺骗和隐瞒行为的出现,因此表面效度的设置需要依据具体研究目的设定。
1.5 通过项目分析剔除条目
在初级卫生保健领域的量表编制过程中,应当在完成预测试后对量表进行项目分析,该步骤可为进一步修订量表提供依据,也是后续正确评价量表的前提。项目分析的实质是探究每个题项的差异,检验其质量,并依据一定的标准对其进行修订或剔除,保障项目之间的同质性与量表的可靠性。研究者主要可以从项目的难度、项目区分度和项目功能的差异3 个方面来考察。
1.5.1 项目难度:项目难度是指完成测验项目的困难程度,是对测试者作答情况进行评估的指标,作答正确率越高,难度越低。设置测验难度水平的目的在于通过研究者开发的量表将不同的受测者尽可能区分开来,以最大限度体现受测者的差异,体现量表的鉴别力。正如步骤3 所述,不同的量表类型适宜设置不同的计分系统,对于非二分法计分项目的难度可以采用所有受测者某一项目的平均得分与该题目满分之比来计算难度。如在一项关于大学生健康素养的研究中,研究者将多项选择题的反应进行重新编码,换算成另一种比例,对于正确值<0.2 或>0.8 的项目都进行了重评,并考虑是否删除[19]。过高或过低的难度值都会给得分的分布和分数的离散程度带来影响,在实际操作过程中研究者应当考虑量表的性质和目的,科学设置合理的难度临界值。
Rasch 模型与经典测量理论运用的方法不同,Rasch模型主要强调测量的客观性和可比性。因此对于测量难度这一指标,Rasch 模型认为题目难度必须独立于样本被试分布,即抽样的人群在选择选项时不受题目难度的影响,同时个体的能力也应当独立于测量题目的难度分布。即题目的难度不随被试样本的变化而变化,不受被试能力水平高低的影响。因此Rasch 测量能够提供关于个体能力和题目难度的等距分数,将个体能力水平和题目难度水平置于同一个Logit 量尺中进行对比,刻画被试能力水平和项目难度水平的人-项目图(Person-Item Map)。图2 是生活满意度量表的人-项目图,由该图可知,图中的黑点主要位于0~2,提示在生活满意度量表项目中,中等及偏高水平生活满意度的被试者提供的信息量最大,但不适用于用来评定生活满意度水平较低的被试。不同的被试和项目分布在一张图表中,可为研究者提供更多的信息。如果研究者计算出来的难度阈值和均值围绕在0 附近,这就表明试题的难度适中。如惠建荣等[20]关于卒中患者生活质量量表的质量分析中,所有条目的难度阈值为-0.32~0.67(M=0.00,SD=0.34),这意味着所有条目的认可度处于中等水平,认可度良好。如果在量表开发过程中,项目难度水平过高或过低,则说明该题目所代表的行为或维度出现频率并不高,或对于被试来说过难,而这样的量表只有在针对特定人群(过高或过低水平的被试)时准确度才高。
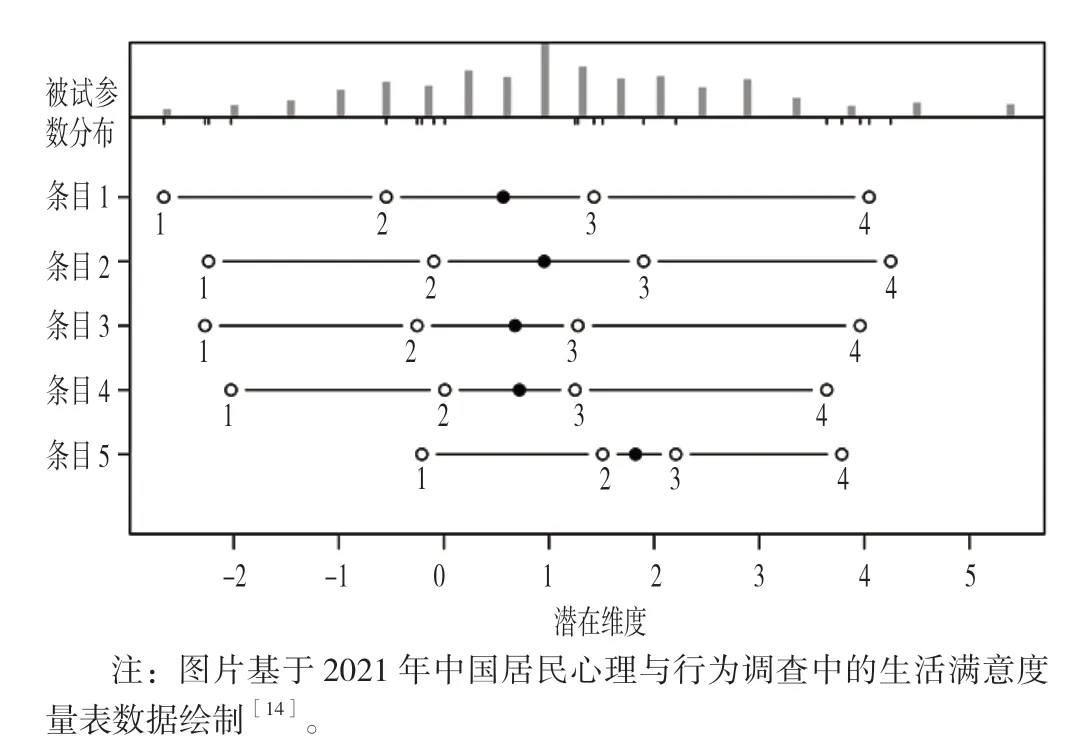
图2 生活满意度量表的人-项目图Figure 2 Person-item map of the Life Satisfaction Scale
1.5.2 项目区分度:考察项目区分度的目的在于检验设计的量表是否能将两类不同的人真正区分开来,达到研究者预先的设想,主要包括鉴别指数法、相关法和矫正项总计相关性(corrected item-total correlation,CITC)法。
(1)鉴别指数的计算方法并不复杂,在统计好所有受测者的总分后按分数高低依次排序,测量学上一般以前后27%的比例划分出高分组和低分组,对两组人群的各题项得分进行独立样本t 检验,最终对于未表现出统计学意义的题项单独考虑,必要情况下可以剔除,以保障量表的准确性。(2)可采用计算项目得分和测验总分的相关系数(PT-mesure)作为区分度指标,相关系数越大区分度越高,最终综合考量是否剔除相关度不佳的项目。(3)CITC 也可以用来考察量表维度中项目之间的相关性,如果≥0.5 则说明该题项与其他项之间有着较高的相关性,如果<0.5 则可以考虑删除该项目后观察Cronbach'sα系数的变化,或考虑修改该项目。花静等[21]编制的儿童运动发育家庭环境量表运用鉴别指数的方法测量项目区分度,结果显示,各个项目之间,高分组和低分组在71 个条目的得分上均存在统计学意义,因此在该阶段保留了所有条目。杨振等[22]在对老年健康促进量表进行信效度检验时,测得条目与量表总分的相关系数为0.406~0.752,呈中等程度相关(临界值为0.300),随后结合信度系数对每个条目进行了进一步的检验。
在项目反应理论当中,难度与区分度是密不可分的,在中等难度下,项目的区分度常最高。因此,项目的难度也可以通过人-项目图看出。图2 中最下侧为Logit标尺,从左到右测量值逐渐升高,对于每个被试而言,所处位置越靠近右端,其生活满意度越高。图中条形高度表示位于这一位置被试的数量,被试分布越集中说明该量表的区分度越小,分布越分散说明量表的区分度越大。在图中的5 个项目上,被试的掌握水平基本呈偏态分布,并集中分布在0 Logit 到2 Logit 之间。这说明在5 个项目中,该量表的区分度较差,在区分生活满意度较差的被试时较为困难。赵福菓等[13]在编制奥尔维斯欺负量表时,使用Rasch 模型发现难度分布非常集中,导致量表对不同霸凌/被霸凌程度被试的区分效果较差,尤其难以区分高霸凌/被霸凌群体。值得注意的是,一般意义上的Rasch 模型仅考虑了难度这一个参数,如果需要将区分度纳入模型,需要使用双参数模型。
1.5.3 项目功能差异(differential item functioning,DIF):DIF 是指两组被试在某个项目上的表现差异,代表了项目对不同被试有不同的统计特性,如果在同一项目上正确作答的概率不同,达到某一临界值,那么该项目则存在偏差,需要进一步的探究差异的来源[23]。Rasch 模型倾向于运用统计检验的方法计算DIF,随着该理论模型影响力的进一步扩大,不同的学者提出了不同的计算方法。通过运用Mantel-Haenszel(M-H 方法)检验法检验被试者个人特征变量带来的DIF,当差异>0.5 且P<0.05 时认为题目存在项目功能差异[24]。如杜海燕等[25]应用M-H 方法进行DIF 检验时发现第9、39、58 题呈现出中等或较为严重的DIF 现象。也可以通过Lord χ2卡方检验法、运用R 语言软件进行DIF 检验,分析结果中χ213为项目功能差异指标,某一项中χ213>0.05 说明存在DIF[26]。如高爽等[27]应用Rasch模型分析Rosenberg 自尊量表时便是使用Lord χ2检验法,结果发现项目1 和项目5 存在DIF,即在这两个项目上,性别差异导致自尊水平不同。对于多级计分题也可以使用方差分析法进行检验,如在WHO 残疾评估计划的开展过程中,发现不同性别群体间的项目难度不同,研究者采用方差分析,通过性别和其他有可能产生DIF的项目进行对比,从而找出不合适的项目进行修改[28]。值得注意的是,项目分析的三大方面并非要求在编制量表时全部使用,而是根据量表的特征加以选择——量表是单项选择还是多项选择?是二分法还是多级计分?开发的量表是什么性质的?在项目分析过程中发现的问题项是否剔除也不能一概而论,简单的删除难度过大、区分度不良或拟合度不高的项目都并非值得提倡的做法,因为过于完美的模型难以真实存在,其只是一种理想性的假设与指导,应当结合多项指标的综合情况进行考虑。
1.6 量表的初次评价
1.6.1 基于经典测量理论的初次评价:经典测量理论也被称作真分数理论,20 世纪50 年代趋于完善。该理论认为测验得到的分数X 是由真分数T 和随机误差E 所组成,即X=T+E,误差E 的平均数为零,T 和E 之间的相关为零。并在此基础之上建立了测验项目的测量学指标,如信度、效度、难度和区分度等,并以此筛选测验项目、建立题库和构制测验[29]。前文中已经对如何利用难度和区分度筛选测验项目做了详细说明,此处旨在介绍如何运用经典测量理论来完成测验的初次评价,即进行探索性因素分析(exploratory factor analysis,EFA)和信效度分析。
(1)EFA 作为一种经典测量理论技术,已经被广泛运用于初级卫生保健领域的量表设计与开发之中。EFA 主要是通过数学的方法探索量表中的变量或因素,以此来确定量表的具体维度和每个项目归属于哪个维度。EFA 应包括确定变量及样本、确定是否可以进行EFA、确定因子个数、因子旋转4 个关键步骤。
①确定变量及样本。这是进行数据分析前的准备工作,对于整个研究来说至关重要。该阶段要求研究者根据以往研究和理论尽可能编制或收集与自己研究主题相关的条目,有时甚至需要包含一些与主题无关的条目。因为在经过EFA 的筛选之后,剩下的条目常会比原始条目少很多,如何决定条目的去留也是研究者需要关注的问题,常见的标准有因子载荷量、项目共同度、跨因子载荷等。通常认为成分矩阵中项目的因子载荷量>0.71 为优秀,>0.63 为非常好,>0.55 为好,>0.45 为一般,>0.32 为差[30];项目共同度不能过低,一般认为项目共同度不得低于0.30[31];同一个项目不能在两个因子上都有着较高的载荷,如陈贵等[32]剔除了在不同因子上有相近载荷且难以解释的项目。在做因素分析之前,还需要注意样本量,因素分析的样本量不可太低,否则结果没有太大说服力。Corsuch 建议的样本数和变量数比为5 ∶1,同时样本量不能低于100;Nunnally 则推荐样本数和变量数比为10 ∶1[33]。
②确定是否可以进行EFA。EFA 的目的是简化数据或者找出量表的基本数据结构,目前研究者普遍采用主成分分析法来进行EFA,因此在进行EFA 之前需要确保因素分析的理论假设和统计假设得以满足。因素分析的理论假设认为这组变量中确实存在潜在结构,而统计假设要求观测变量之间存在较强的相关性。因此,在进行EFA 前需要确保以下几个条件被满足:项目间相关性>0.3、Bartlett 球形检验显著(P<0.05)、抽样充分性(MSA)的KMO 度量至少为0.6[2]。项目间相关性>0.3 要求研究者计算所有题目的相关性,如果所有或大部分相关性≤0.3 则不适合做EFA。球形检验和MSA 也是同样的道理。如郭静等[34]在修订中文版心理脆弱性问卷时进行了KMO 度量和Bartlett 球形检验,结果显示KMO=0.89,Bartlett 球形检验的χ2/df=25.31,P<0.001。需要注意的是,这些参数合格仅代表可以进行因素分析,而不是说明因素分析结果较好。
③确定因子个数。确定所选变量的因子结构和因子个数是EFA 中非常关键的一步,因子抽取过少或过多都会造成一定的问题,但实证研究中更倾向于保留较多的因子,因为抽取过度相比于抽取不足的因子载荷估计更加准确。因此,研究者提出了多种检验方法来帮助决策,主要包括3 种。其一,特征值>1,也叫K1 原则,是研究者最常采用的标准之一。其二,解释方差总量。方差解释量也是基于主成分分析法的思想发展而来,关于因子解释多少总体方差合适并没有统一的标准,有研究者认为因子解释的方差总量应不低于50%[35]。表1 显示了8 条目一般自我效能感量表的因子分析结果[14],其中仅有一个主成分的特征值大于1,研究者据此认为一般自我效能感量表是个单维度的量表,仅包含1 个因子;不仅如此,表中还显示了该因子的方差解释量(71.91%),意味着该因子能够解释一般自我效能感71.91%的变异,能较好地反映一般自我效能感。其三,碎石图。碎石图提供了因子数和特征值大小的图形表示,研究者只需要根据EFA 给出的碎石图选择出现拐点时对应的因子数即可,这种方法简单方便,也更加直观。图3 为一般自我效能感量表的碎石图,由图可知,在从第1 个成分开始,特征值产生了巨大转折,因此可将第1 个成分视为拐点,认为该量表仅包含一个因子。
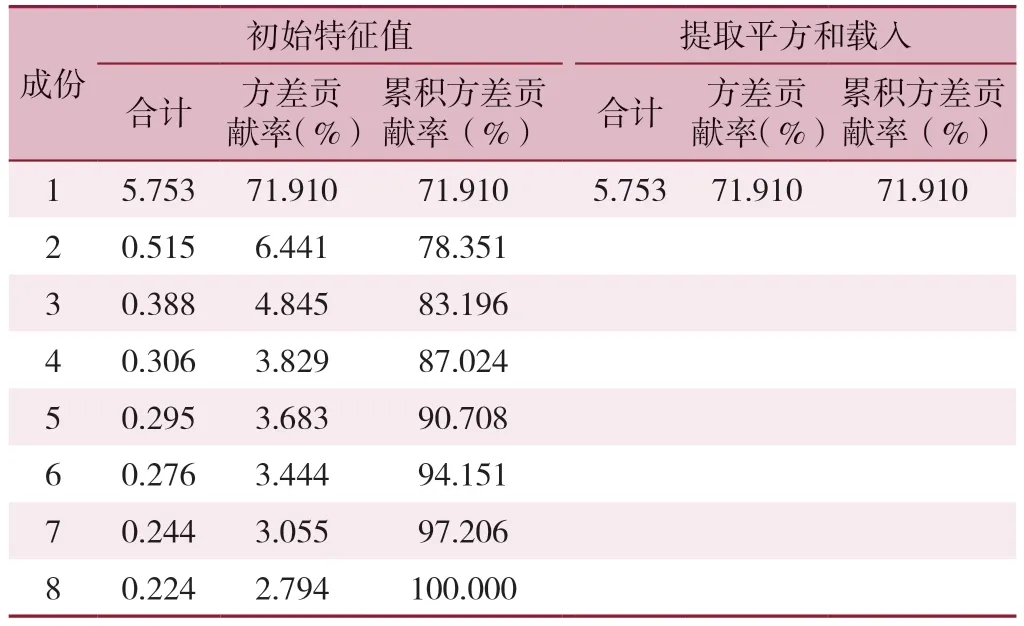
表1 基于主成分分析法的一般自我效能感量表因子分析结果Table 1 Factor analysis results of the General Self-efficacy Scale using principal component analysis
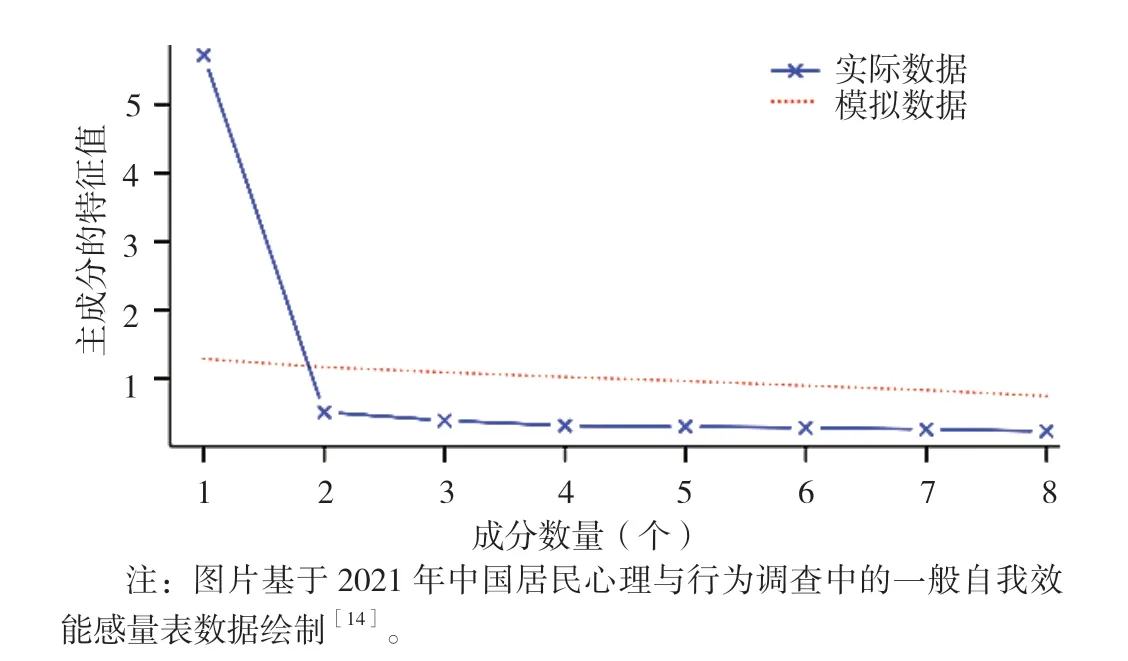
图3 一般自我效能感量表的碎石图Figure 3 Scree plot of the general self-efficacy scale
④因子旋转。在确定了因子个数后,下一步就需要确定因子旋转的方法。因子旋转的方法可分为两大类:斜交旋转(oblique rotation)和正交旋转(orthogonal Rotation)。与斜交旋转不同的是,正交旋转需要假设因子之间无相关。就初级卫生保健领域的实证研究而言,因子之间常存在着或大或小的相关性,因此采用斜交旋转更加客观,然而目前已发表的绝大多数研究使用的多是正交旋转,其结果更有利于研究者对因子结构做出解读,但这也容易对研究结论造成误导。因此,研究者在未来的研究中先选用斜交旋转,如果发现因子间相关性较小或没有相关性再考虑采用正交旋转。
(2)信度分析:经历了EFA 的剔除条目后,正式量表已经成型,此时还需要利用该数据检验正式量表的信度。信度是指测量结果的稳定性。如果一个人的同一种特质能够用同一种测量工具反复测量,那么各种测量相互间的吻合程度就称为信度,有时也称为测量的可靠性。在经典测量理论中,衡量信度的方法通常包括复本信度、重测信度、同质性信度、分半信度、评分者信度。在临床研究中,由于复本信度较难获得,故很少使用这一指标,研究者更倾向于使用重测信度、分半信度和同质性信度。
①重测信度:在量表设计类研究中,量表的跨时间一致性是一个衡量测量工具可靠性的重要指标。因此,在初级卫生保健领域进行量表的开发和设计时,需要报告该量表两次对同一组被试施测所得结果的一致性程度,其大小可用前后两次相同测验的皮尔逊积差相关系数来表示。如刘蕾等[36]在编制中文版老年人锻炼心理需求满足量表时报告了该量表的重测信度为0.883,3 个维度的重测信度系数为0.829~0.876。对于测验中的重测信度,一般公认的评价标准是:0.65~0.70 为最小可接受值,>0.70~0.80为相当好,>0.80~0.90为非常好[37]。因此,刘蕾等[36]编制量表的重测信度较好,但刘蕾等[36]并未报告两次施测的间隔,这也是影响重测信度的重要因素,在今后的研究中应加以注意,因为随着第2 次测量的时间不同,量表可以有不同的重测信度。
②复本信度:通过设计两个平行测验来测量同一批被试,所得结果的一致性程度称为复本信度,其大小可使用两个复本测验上同一批人测试的皮尔逊积差相关系数来表示。复本信度也是衡量量表可靠性的一个指标,但是由于设计复本测验费时费力,同时又很难保证两个测验在内容和结果上一致,故其在测量领域并未得到广泛使用。刘爱梅等[38]在编制适用于突发性耳聋患者的健康知信行问卷时就使用了这一信度,复本测验采用内容、应答形式相似的问卷进行调查,结果发现健康相关知识部分的复本信度为0.88,而复本信度的评价标准与重测信度基本保持一致[37],故该量表的复本信度较好。
③分半信度,也叫内部一致性系数,研究者需要将一个完整的测试分成对等的两半,比较参与测验的被试在新得到的两组上测验分数的一致性。分半信度是目前研究中使用较多的信度指标之一,研究者只需要在统计软件内进行简单操作即可得出量表的分半信度。
④同质性信度:研究者可通过测量测验内部所有题项间的一致性程度得到同质性信度,即内部一致性系数。研究者一般采用Cronbach'sα系数来衡量一个测验的内部一致性。Cronbach'sα系数是目前研究中使用最多的信度,与分半信度类似,研究者只需要在统计软件内简单操作即可算出该量表的Cronbach'sα系数。量表的Cronbach'sα系数最好在0.80 以上,0.70~0.80 是可以接受的范围;分量表的Cronbach'sα系数最好在0.70以上,0.60~0.70 是可以接受的范围[37]。
⑤评分者信度:由多个评分者给同一批人的答卷进行打分,通过计算得分的一致性,可以得到量表的评分者信度。其大小等于一个评分者的一组评分与另一个评分者的一组评分的肯德尔和谐系数。肯德尔和谐系数是表示多列等级数据相关程度的一种量数,常用于评价多个主评者的评分一致性。
(3)效度分析:在进行初级卫生保健领域量表设计研究时,还应检验所编制量表的效度。效度是一个测试量表能够测量其试图测量特征的程度。效度的理论定义是:在与测量目的相关的一系列测量中,真实变化(被测量变化引起的有效变化)与总变化(真实变化)的比值。测试效度可分为内容效度、结构效度和经验效度。
①内容效度:是由相关专家对测评工具的条目与内容范围的吻合度进行详尽、系统判断。其中,参评专家的资质、专业范围是内容效度评估质量的基本保障。如崔楚云等[39]选择6 名护理领域专家(来自学校和医院的护理学教授、护理部主任及临床护理专家)对量表内容效度进行评价,因为选择研究领域的教授或临床专家是开展内容效度评价是最常见的选择。另外,内容效度在条目筛选中的定量评估包括多种指标计算,其中内容效度指数(content validity index,CVI)由于计算简单、易于理解和交流、可对随机一致性进行校正等优点得到了广泛应用。项目水平的内容效度指数(I-CVI)可以评估各项目的内容效度,量表层面的内容效度指数(S-CVI)可用于衡量整个量表的内容效度。如在完成冠心病患者二级预防服药依从性问卷的初步编制后,研究者依照Likert 4 级评分法编制专家评定表,选项设定为“不相关”“修改否则不相关”“很相关但仍需修改”“十分相关”4 级,依次计为1~4 分,发放给专家作答,回收后计算得出I-CVI 和S-CVI 均为1.00,表明问卷的内容效度良好[40]。
②结构效度:测验在实际上所测到想要测量的理论和特质的程度即为量表的结构效度,其表示了一份量表在多大程度上能够说明测验理论的某种结构或特质。在实证研究中,研究者一般可以通过项目分析、EFA 及验证性因子分析(confirmatory factor analysis,CFA)来衡量一个量表的结构效度。项目分析是通过计算量表各条目与所在维度的相关矩阵及各维度之间的相关矩阵来检验量表各维度之间的关联性与独立性。如杨丽等[41]在认知风格问卷中使用了项目分析来衡量量表的结构效度,结果显示项目与所在维度的相关系数均在0.55 以上,基本分布在0.56~0.75,问卷的项目区分度良好,认知风格问卷4 个维度之间存在中等相关,说明4 个维度相互关联,同时相对独立。EFA 与上节所述基本一致,只不过这次不需要删减条目,一般来说,经历过EFA形成的问卷在检验其结构效度时应重新收取新的数据,对新的数据采用EFA 或CFA 来衡量。如WU 等[42]在检验中文版杜克抗凝满意度量表(DASS)的信效度时使用AMOS 软件进行CFA 来检验模型拟合,结果发现各项指标均显示4 因素的DASS 模型拟合良好[CMIN/DF=1.825(<5.000),适配度指数(GFI)=0.854(>0.850),相对拟合指数(CFI)=0.938(>0.900),渐进残差均方和平方根(RMSEA)=0.066(<0.080),标准拟合指数(NFI)=0.875(<0.900),Tucker-Lewis 指数(TLI)=0.921(>0.900)],量表具备良好的结构效度。
③实证效度:如果一个量表能够对处于具体情境中的被试的行为进行有效估计,则称该量表具有良好的实证效度或校标关联效度。效标效度主要可以通过相关法、区分法、命中率法来衡量,而目前初级卫生保健领域的量表设计研究多采用相关法。相关法是测试成绩与效度变量之间的相关程度。计算出的相关系数为效度系数,效度系数的平方为效度。如游永恒等[43]就选取总体幸福感量表(GWB)作为效标来验证Beck 抑郁(BDI)量表的同时效度,再发放抑郁量表时同时要求作答校标量表,结果发现总体幸福感各维度及总分与抑郁总分均有明显相关性(P<0.001),这表明BDI 量表具有较好的效标效度。
1.6.2 基于Rasch 模型的初次评价:Rasch 模型是一种基本特征模型,其通过个体在某项上的表现来衡量基本特征。Rasch 模型的基本原理是:一个人在具体题目上的具体表现是由这个人的能力和题目的难度来衡量的,因此个体反应的好坏完全取决于个体能力和项目难度。Rasch 模型是一种理想化的数学模型,因此Rasch 模型对客观测量提出了两个要求:第一是对任何题目,能力高的个体应该比能力低的个体有更大可能做出正确回答;第二是任何个体在容易题目上表现得更好,在困难题目上表现得更差[44]。尽管Rasch 模型已经发展了数十年,但其仍未引起足够重视,尤其是在初级卫生保健领域。在中国知网以“Rasch”为主题进行检索,发现1915—2022 年仅发表了160 篇核心期刊论文,其中2017—2021 年的研究占比高达46.25%,这意味着近年来Rasch 模型已逐渐得到研究者的注意,然而这些研究仍然主要集中于心理学、教育学领域,涉及初级卫生保健的文章仅有几篇。因此,在初级卫生保健领域开展Rasch 模型研究非常必要。
(1)单维性检验。项目反应理论(item response theory,IRT)是一种关于个体回答问题的概率与潜在特质之间关系的数学表述,是区别于CTT 的又一测量领域的经典理论。常见的IRT 模型包括单参数模型、双参数模型和三参数模型[44]。部分研究者将Rasch 模型作为IRT 单参数模型的一个特例,其使用有一个前提,那就是量表具有单维性。单维性是指测量过程中有且仅有一种潜在特质影响被试作答。在这里需要注意的是,一种潜在特质并不意味着该量表只能有一个维度,只要量表中的各个维度都指向同一种特质即可。如陈圆圆等[45]在汉化营养素养评价工具时发现该工具包含6 个分量表,但分量表中包含的条目都指向营养素养这一特质,于是针对分量表和全量表均做了Rasch 分析。一般采用Rasch 模型残差主成分分析法(PCA)检验量表单维性,根据Raiche 的建议,首因子残差标准化特征值在1.4~2.1即可认为该数据满足单维性的要求,适合Rasch 模型[45]。如陈圆圆等[45]在汉化营养素养评价工具过程中进行单维性检验,发现分量表1~6 的首成分残差特征值为1.6~1.8,总量表的首成分残差特征值为3.1,即认为该量表适合进行Rasch 分析。
(2)模型拟合度。从怀特图中可得知,Rasch 模型能够估计项目的难度和被试的能力水平,通过将实际的观测分数与每个被试在每个项目上答对的理论概率进行比较,即可评估Rasch 模型的拟合情况。Rasch 模型通常需要计算两个拟合指标:加权均方拟合统计量(infit mean square,infit MNSQ)和非加权均方拟合统计量(outfit mean square,outfit MNSQ),两者接近于1 表示模型拟合效果好。一般认为,当数据拟合良好时,非加权均方拟合统计量和加权均方拟合统计量为0.5~1.5 为好[46]。以生活满意度量表为例[14],研究者收集了569 份数据,使用R 软件进行模型拟合度检验,结果见表2。由表2可知,所有项目的参数基本在可接受范围内,说明数据与模型达到了很好的拟合。题目5(如果我能重新活过,差不多没有东西我想改变。1=不同意,2=有些不同意,3=中立,4=有些同意,5=同意)的非加权均方拟合统计量和加权均方拟合统计量参数值分别为1.52 和1.40(均>1.000)。这意味着有较高生活满意度的人选择了低分,即不同意/有些不同意;而有着较低生活满意度的人选择了高分,即同意/有些同意。因此,题目5 在区分被试生活满意度时误差较大,需要进一步考虑是否需要保留该条目。
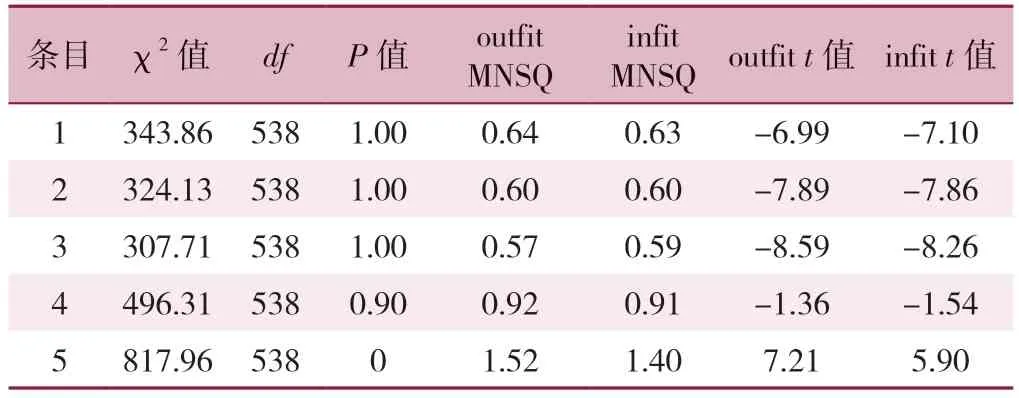
表2 生活满意度量表的模型拟合参数Table 2 Model fitting parameters of the Life Satisfaction Scale
此外,一个较好的项目或量表应该能够为测试提供较多的信息,降低对被试特质水平估计方面的误差。项目反应理论认为,用与被试特质水平相当的量表进行测试时,量表才能提供最精准的测量结果。在研究中,一般采用测试信息曲线进行测量,其可以反映当不同特征水平的被试完成完整量表的所有项目时,量表整体能提供准确评价的程度。其中,项目的难度可参见横坐标,代表了被试的特质水平,每个刻度代表1 个Logit 单位,纵坐标代表信息量,即Fisher 信息函数[13]。图4 是生活满意度量表的测验信息曲线图[14],其中上半图是各条目的测验信息曲线,下半图是总量表的测验信息曲线。总体而言,该量表在生活满意度估计值为0~2 时准确率最高,能为中、高生活满意度的被试提供最大的信息。如高爽等[27]在计算Fisher 信息函数后发现,自尊的估计值为-2~0,可以提供最高的测量精度,为中、低自尊被试提供最多的信息。
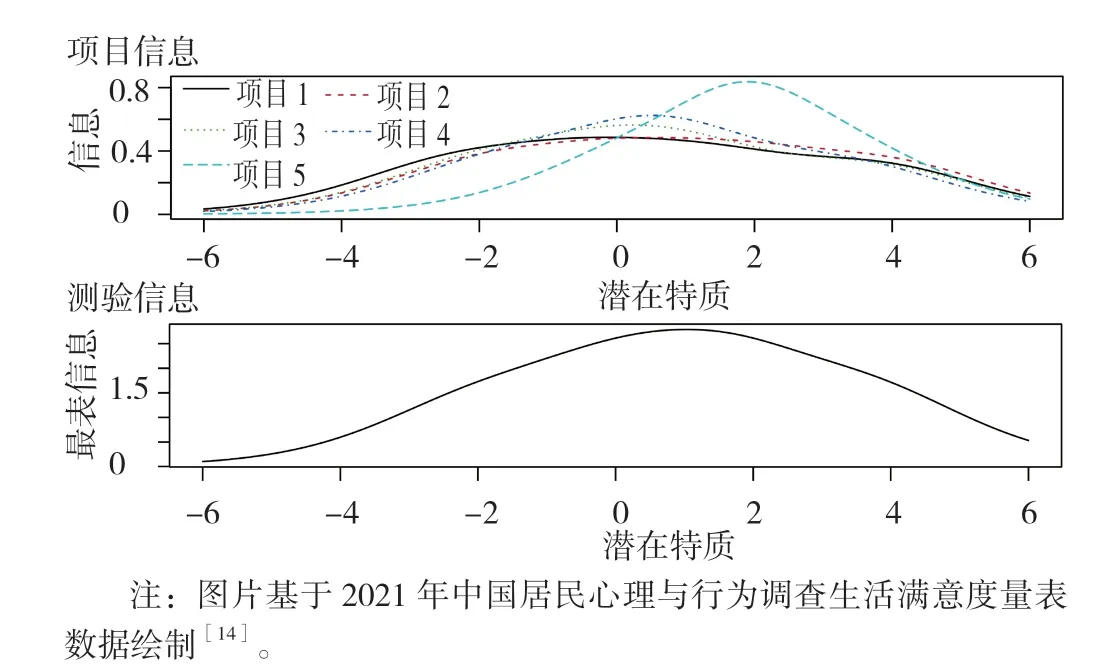
图4 生活满意度的测验信息曲线Figure 4 Information curve of life satisfaction test
(3) 信度。Rasch 模型以分隔信度(person separation reliability,PSR)衡量量表信度,分隔信度可以通过计算个体所产生“真实”变异与总变异的比例得出,通常用于考察受试者在项目评定上的可靠程度[13]。Rasch 模型测量的总体信度是通过计算个体水平上的解释率得到的,其值从0 到1。一般情况下,可靠性指标在0.7 以上为可接受,0.8 以上为良好[5]。
1.7 量表的再次评价
从第1 步到第6 步,一个量表基本已经成型。但由于量表条目筛选和信效度检验均是采用同一份样本进行,该量表是否具有跨样本和跨时间的一致性仍然是未知的。因此,研究者应该使用正式量表重新收集一个新的样本,检验该量表在新样本上的信度与效度。当然,需要注意的是,如果研究者需要检验该量表的重测信度,那么第2 批量表的被试中就应该包含一部分第1 批施测的对象。由于信效度分析的相关内容已经在前面阐述,研究者只需要使用相同方法再次检验即可,故不再赘述。此处仅对经典测量理论中使用CFA 检验量表结构效度的方法进行阐述。
CFA 是指在明确观测指标和潜在因子之间隶属关系的前提下进行的假设检验,是理论驱动型分析。在经历了EFA 以后,已经明确了正式量表的因子结构,故可以利用新数据构建CFA 模型来检验量表的结构效度。再根据输出结果的拟合状况考虑是否需要进行模型修正,主要选用的拟合指标包含卡方自由度比值(χ2/df)、GFI、调整拟合优度指数(AGFI)、RMSEA、NFI、增量拟合指数(IFI)、相对拟合指数(RFI)、CFI、TLI 等。这些参数的适配标准为:χ2/df<2 时(也有研究者认为χ2/df<3),表示假设模型的适配度较佳[47];RMSEA<0.08 意味着模型尚可接受[6];AGFI 与GFI 应>0.90,表示模型与数据有着良好的匹配度[48];NFI、RFI、IFI、TLI、CFI 应>0.90[48]。如果这些拟合指数未达到较好的适配标准,研究者应考虑对模型进行修正,具体做法是利用AMOS 报表呈现的MI 值,释放两个测验误差变量彼此之间的关系,即在其之间建立共变关系[46],从而达到对优化模型的目的。
2 讨论
量表设计类方法在初级卫生保健领域得到了充分的运用,这主要体现在量表设计研究的使用广度上。大部分研究会涉及量表的使用,故一个量表的设计与开发是否合理便决定了该研究是否可靠。而目前关于量表设计的研究仍存在诸多不规范的地方,如信效度较差、缺乏关键步骤、统计错误等。总体而言,在初级卫生保健领域开展量表设计类研究需要严格按照上述标准化流程进行,这在一定程度上能够解决研究过程中步骤和统计方法使用不规范的问题。当然,为了更好地掌握这种方法,有些必需技能也是需要注意的。
量表设计类研究所需要的必要技能主要包括理论指导和统计检验。理论指导是自上而下的加工,是理论驱动的过程。理论指导要求研究者在开发量表前期和中期一定要阅读大量相关文献,了解所需要测量特质的结构及现有理论和量表,只有在了解这些成熟的前人经验的基础上才能尽可能地确保所编制量表的有效性。而统计检验是自下而上的加工,是数据驱动的过程。统计检验可以帮助研究者更好地发现项目编制过程中存在的问题,同时也是研究者筛选不佳条目的重要参照。研究者通过统计学来检验量表的信度和效度,以此来保证这一量具的客观与有效。综上,理论指导和统计检验是量表设计类研究中两项必需的技能,只有将这两者很好地结合起来,将自下而上的自上而下的角度一起考虑,才能最大限度地保证所设计测量工具的可靠性。
此外,从统计的视角来看,传统的因素分析和Rasch分析(项目反应理论)是两种不同的数据分析方法。因素分析倾向于将被试的反应(即0~4 点评分的选择)理解为是连续变量,而项目反应理论则将其视为5 个不同的类别[49]。因此,在量表开发或汉化过程中,可以使用两种方法一起检验量表的信效度,但切忌混用,例如使用经典测量理论删减条目之后再使用项目反应理论去构建统计模型。
本研究较为系统地阐述了如何在初级卫生保健领域开展量表设计研究,但由于篇幅和专业限制,部分临床医生可能很难理解文中出现的术语。另外,可能对于大多数全科医生而言,如何选取一个合适的量表比设计一个量表更为直接、有效。为此,在附件中提供了文中出现的一些专业词汇的解释及全科医生选取量表的相关建议(请扫描文章二维码获取)。此外,本研究还为研究者提供了继续深入学习量表设计类方法的参考文献,如《潜变量建模与Mplus 应用-基础篇》[33]、《健康调查问卷设计原理与实践》[49]、《R 语言:量表编制,统计分析与试题反应理论》[50]、《心理与行为定量研究手册》[51]。总的来说,研究者在开展量表设计时需要严格遵守标准化流程,具体步骤可参照清单中的相关资料操作,以确保设计量表的客观性和有效性。
致谢:感谢安徽大学哲学学院的高志强副教授在心理测量领域给予的指导,正是因为高志强副教授的心理测量课程才让本文作者很早就了解到了这一领域。还要感谢参与2021 年中国居民心理与行为调查的全体调查员,正是因为有了大家的参与,才能有如此多的数据来支持文中的相关图表。
作者贡献:王飞提出选题方向,负责数据处理,撰写论文初稿;汤靖琪参与论文初稿撰写,并进行数据管理;孙小楠负责论文修订;孙昕霙对文章提出了批判性建议;黎俊从全科医生的视角对文章进行了修改和完善;孟星星、吴一波全程指导论文写作,负责文章的质量控制及审校,对文章整体负责;所有作者确认了论文终稿。
本文无利益冲突。
猜你喜欢
世界科学技术-中医药现代化(2021年7期)2021-11-04
河池学院学报(2021年1期)2021-07-10
中国非营利评论(2019年1期)2019-06-18
英语文摘(2019年2期)2019-03-30
中华手工(2018年6期)2018-07-17
管理现代化(2016年6期)2016-01-23
听力学及言语疾病杂志(2015年5期)2015-12-24
心理学探新(2015年4期)2015-12-10
中国卫生(2015年7期)2015-11-08
外语教学理论与实践(2015年1期)2015-06-11
