
一种基于长短期用户表示和多视角学习的新闻推荐方法
2023-11-02 13:05王京豪
计算机应用与软件 2023年10期
何 丽 王京豪
(北方工业大学信息学院 北京 100144)
News recommendation
0 引 言
随着互联网的发展,各类信息如新闻信息成倍的增长,面对海量数据,如何帮助用户快速得到个性化的、有价值的新闻显得十分重要。基于此,个性化新闻推荐系统应运而生。
个性化推荐的方法主要分为三大类:基于协同过滤的推荐[1-2]、基于内容的推荐[3-4]和混合推荐方法[5-6]。其中,以基于协同过滤的推荐应用最为广泛。针对新闻推荐,学习用户和新闻的表示主要依靠历史行为数据,但是在很多情况下,这些数据是很难获取或者十分稀疏的。比如,一篇新发布的新闻,浏览过的用户很少,采用协同过滤方法就会存在严重的冷启动、数据稀疏等问题,同时新闻中含有的大量文本内容也没有被很好地利用,因此新闻推荐通常采用基于内容的推荐方法。
目前,许多基于内容的深度学习新闻推荐方法被提出[7-8],其核心思路是通过一个用户编码器和新闻编码器来获得用户和新闻的表示来实现推荐。如何学习准确的用户表示对于新闻推荐系统来说是一个关键问题。Wang等[7]利用卷积神经网络学习新闻表示,然后基于候选新闻与浏览新闻的相似性从用户浏览的新闻中学习用户表示,但该方法不能体现用户的短期兴趣;Okura等[8]利用GRU网络从其浏览的新闻中学习用户表示,然而该方法很难捕捉到长期的新闻浏览历史的全部记录;An等[9]提出一种能够较好地结合用户长期爱好和短期兴趣的方法,但仅仅从新闻标题中学习新闻表征,这样的表示学习是不够充分的。
新闻数据通常包含不同类型的信息,比如主题类别、标题和摘要等特征,它们对于学习新闻的表示都是很有帮助的。包含多种信息类别的新闻数据如表1所示。

表1 新闻数据样例
新闻的主题类别对于学习新闻表征来说是具有很大信息量的。如果一个用户浏览过该新闻,那么他极有可能对其他体育类或者篮球NBA类的消息很感兴趣;此外,从标题中可以得到,这是一条关于两支球队竞争的新闻,摘要中则能得到更详细的信息,因此,融合这些不同类别的信息可以改善新闻推荐中的新闻特征表示和用户表示。
因此,本文提出一种使用多视角学习的方法来改进新闻编码器,即利用不同类型的新闻信息来学习新闻的特征表示,并将其融合到结合用户长期和短期兴趣表示的用户编码器中,以此来提升新闻推荐的结果。在新闻编码器中,采用计算机视觉领域常见的多视角学习的方法并结合注意力机制,将主题类别、标题和摘要作为不同的新闻视角来学习统一的新闻表示,由于不同类别的信息可能具有不同的信息量,因此加入注意力机制;用户编码器采用结合用户长期爱好的短期兴趣学习用户表示的方法[9],使用GRU网络从用户最近点击过的新闻的表示中学习用户的短期兴趣,从用户ID的嵌入中学习用户的长期爱好,并利用用户的长期爱好初始化GRU网络的隐藏状态。通过在真实新闻数据集上的大量实验,证明了本文的方法能够有效地提高新闻推荐的准确率等指标。
1 相关工作
个性化新闻推荐是自然语言处理领域的一项重要任务,其有着广泛的应用[10]。对于新闻推荐来说,学习到准确的新闻表示和用户表示是十分重要的。现有的一些传统方法,采用人工特征工程来进行新闻和用户的表示学习。例如,Son等[11]的方法建议从维基百科页面中提取主题和位置特征作为新闻表示。Liu等[12]使用贝叶斯模型生成的话题类别和兴趣特征作为新闻表示。这些方法都依赖于人工工程,需要很大的工作量,并且无法学习到新闻中的上下文和词序,对于学习新闻和用户表示的效果不是很理想。
近年来采用深度学习方法的新闻推荐逐渐增多,如上文引言中提到的[7-8],它们的方法学习用户表示通常为每个用户学习单一的表示向量,无法区分长期爱好和短期兴趣,An等[9]提出的LSTUR模型能够较好地结合用户长期爱好和短期兴趣的方法,但其只从新闻标题中学习新闻表示,这样学习新闻的特征表示是不充分的。由于新闻数据除了标题之外还有主题类别、摘要等信息,为了能够将它们作为统一的学习表示,本文方法参考计算机视觉领域常用的多视角学习方法[13],将不同的类别信息结合起来,学习新闻表示并改进用户表示。在真实新闻数据集上的大量实验表明,本文方法与现有流行的方法相比,能够更好地学习新闻和用户的表示,提高了新闻推荐的准确率。
2 方法设计
本文提出的基于长短期用户表示和多视角学习模型主要分为新闻编码器和用户编码器,其整体框架如图1所示。

图1 模型总体框架
2.1 新闻编码器
新闻编码器用来从不同类别的信息(主题类别、副类别、标题、摘要)中学习新闻的统一表示。同一新闻中不同的词可能具有不同的信息量,比如表1中“championship”就要比“fans”更重要,所以采用注意力机制学习不同单词的重要性。此外,不同类别的信息具有不同的特点,比如主题类别和副类别就是一个单词的标签,标题则短而简洁,摘要较为详细,基于此对不同类别的信息要用不同的方法进行处理。本文利用注意力机制和基于多视角学习的方法将每一种信息作为新闻的一个视角来学习新闻的统一表示,新闻编码器整体模型如图2所示,四种不同的信息对应模型中的四个部分。
2.1.1主题类别编码器
新闻编码器中的第一部分组件是主题类别编码器,用于从新闻的分类中学习到新闻表示。在许多新闻网站上,都会对新闻进行类别标记,比如“体育”“军事”等,这些是可以获得用户兴趣的重要信息。一个经常浏览“军事”类新闻的用户对这方面肯定是感兴趣的,因此从新闻的主题类别中学习信息。主题类别编码器的输入是类别vc的ID,其首先经过一个类别嵌入层,将类别的离散ID转化为低纬度的全连接表示,用bc表示;之后,将其再经过一个全连接层用来学习主题类别的隐性表示,输出ec表示如下:
ec=ReLU(Pc×bc+pc)
(1)
式中:Pc、pc均是全连接层的参数,ReLU是非线性激活函数。
2.1.2副类别编码器
第二部分组件是新闻的副类别编码器,它与主题类别编码器类似,可以从新闻被标记的副类别信息中学习新闻特征,并能够更进一步地缩小用户的兴趣范围。比如喜欢主题类别为“体育”的用户,最经常浏览的新闻副类别是“篮球_NBA”,那么向其推荐足球类的体育新闻可能就不是用户想要的了。由于主题类别和副类别通常都是一个单词来表示,因此采用的编码器方法也类似,输入副类别vsc的ID,经历与主题类别编码器相似的操作得到最终输出esc,其公式表示如下:
esc=ReLU(Psc×bsc+psc)
(2)
式中:Psc、psc均是全连接层的参数。
2.1.3标题编码器
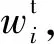
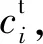
(3)
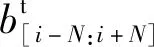
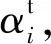
(4)
式中:Pt、pt均是训练参数;qt是注意力向量。
最终,通过三层的标题编码器,得到了新闻标题的最终表示et,公式如下:
(5)
2.1.4摘要编码器
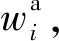
最终,通过三层的摘要编码器,得到新闻摘要的最终表示ea,公式如下:
(6)
2.1.5注意力机制
通过新闻编码器的四个组件,得到从不同信息中学习的新闻表示,将它们简单地相加作为新闻编码器的最终表示不是最理想的结果,因为新闻的不同类别的信息具有的信息量可能是不同的。例如,表1中举例的新闻标题“LA rivalry takes on new meaning for fans as Lakers, Clippers in hunt for NBA championship”描述了NBA球队湖人和快船的争冠竞争,含有的信息是较为丰富的,但例如“The Absolute Best One-piece Bathing Suits of 2019”这样的新闻标题含有的信息就较为模糊了,对于这条新闻来说摘要和主题类别的权重就要占比高一些。基于此,采用注意力机制模拟不同类型的新闻信息的信息量,以便于更好地学习新闻表示。将新闻的主题类别、副类别、标题和摘要的注意力权重分别表示为αc、αsc、αt、αa,以主题类别的计算公式为例,公式如下:
(7)
式中:Ot、ot是训练参数、qe是注意力向量,使用类似的方法,可以求得副类别、标题和摘要的注意力权重αsc、αt、αa。
最终,利用求得的注意力权重,新闻编码器所学习的新闻表示的输出表示为:
e=αcec+αscesc+αtet+αaea
(8)
2.2 用户编码器
用户编码器的作用是从用户浏览过的新闻中学习到用户表示,这对于提高新闻推荐的准确度来说至关重要。由于新闻是具有高度时效性的,用户的兴趣也是随着时间在改变的,无论是只从用户浏览的整段历史还是最近的历史来学习用户表示都是不够充分的,比如一名用户可能从很早开始就浏览“体育”类的新闻,推荐给他体育类新闻效果很好,但他最近浏览“军事”类新闻的次数非常多,这时就不能只专注于推荐用户的长期兴趣体育类新闻,对于新闻推荐来说能够同时学习用户长期爱好和短期兴趣表示的方法取得的效果较好[9]。本文通过融合了基于注意力机制的多视角学习方法改进新闻编码器来更好地学习新闻表示,用户编码器的模型如图3所示。
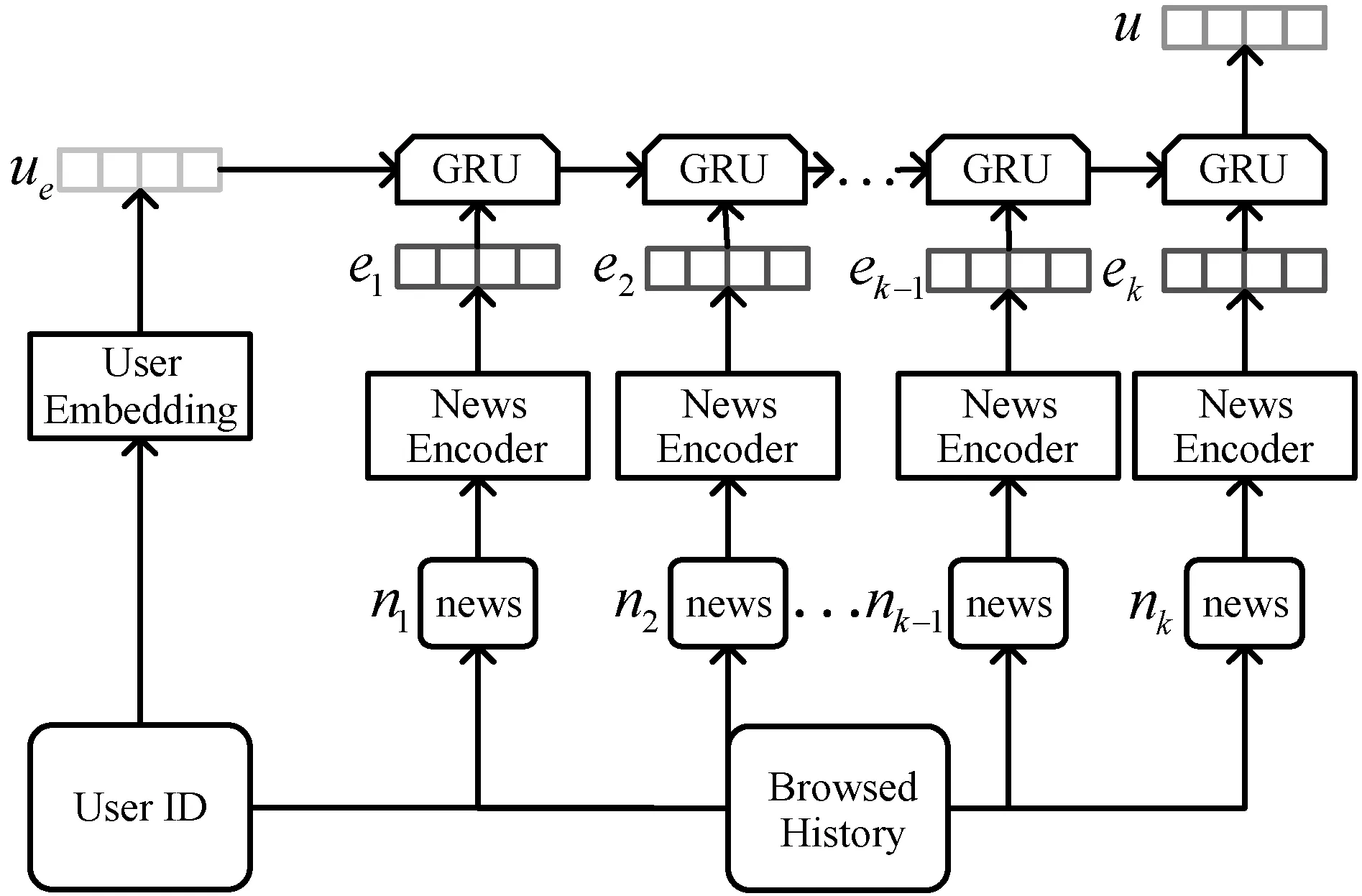
图3 用户编码器模型
用户的表示分为长期和短期的,学习长期用户表示的方法为通过用户ID的嵌入,用u表示用户的id,Wu为用户id的嵌入,长期用户表示就为ue=Wu[u]。之后,从用户最近浏览过的新闻中学习用户的短期表示,应用门控递归网络(GRU)来获取新闻阅读顺序[8],将用户的长期表示作为GRU网络隐藏层的初始状态[9],用户浏览过的新闻按顺序表示为ni,k表示用户浏览过的新闻总量,将这些新闻按顺序通过新闻编码器后得到对应的新闻表示ei,由于改进了新闻编码器,因此得到的新闻表示ei是更为准确的,这能够帮助用户编码器更好地学习用户的短期表示,用户短期表示的计算公式如下:
ri=σ(Wr[hi-1,ei])
zi=σ(Wz[hi-1,ei])
gi=tanh(Wg[ri⊙hi-1,ei])
hi=zi⊙hi+(1-zi)⊙gi])
(9)
式中:σ为sigmoid函数;W为GRU网络的参数;⊙表示同或运算。最终,最后一个GRU网络的隐藏状态就是结合了长短期的用户表示u=hk。
2.3 模型训练
本文使用点生产方法来计算新闻点击概率得分,这种方法被证明不论是时间效率还是性能都很好[8]。将用户表示为u,候选新闻表示为ex,用户点击候选新闻的预测评分s就表示为s(u,nX)=uTeX。采用负采样技术进行模型训练的效果较好[16],本文也使用这种方法进行模型训练。用户浏览过的新闻视为正样本y+,对于每一个正样本都随机抽取同一印象中未被该用户点击的k条新闻作为负样本y-,使模型联合预测正样本和负样本的点击概率得分s,这样新闻预测问题就转化为分类问题,使用softmax函数标准化这些点击概率来计算正样本的点击概率,公式如下:
(10)
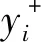
由于不是所有用户都有长期表示,比如没有长期浏览历史的新用户,所以在训练时以一定的概率p随机屏蔽用户的长期表示可以更好地提高模型性能[9],并且达到更接近于真实环境的目的,因此用户的长期表示可以改为:
ue=M×Wu[u],M~B(1,1-p)
(11)
式中:M为服从B(1,1-p)的伯努利分布。
3 实验与结果分析
为了验证改进后的方法是否能够提高新闻推荐的效果,本文设计了一系列对比实验。首先对实验设置进行说明,然后探究改进后的模型与其他方法的效果对比,最后验证融合了多视角学习方法改进新闻编码器的有效性。
3.1 实验设置
3.1.1数据集
为了验证新闻推荐的效果提升,本实验使用真实世界的新闻数据集MIND数据集[17],这是微软公司从微软新闻网站的匿名行为日志中收集的用于研究新闻推荐的大型数据集。为了提升验证效率,本文使用小规模的MIND数据集,数据集的详细信息如表2和表3所示。
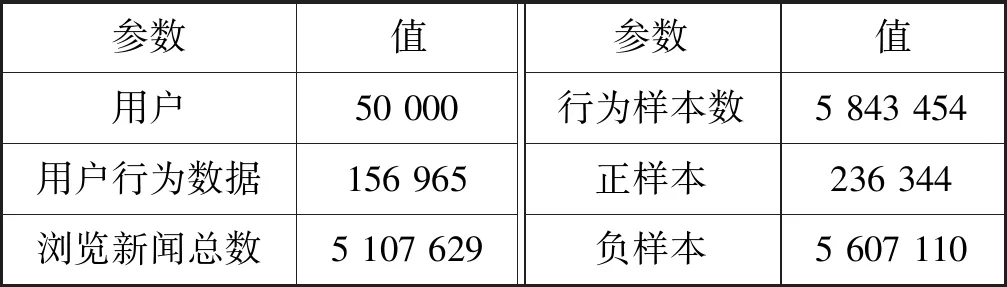
表2 用户行为数据集

表3 新闻数据集
其中,用户行为数据集的每条数据包括用户行为ID、用户ID、行为的时间、用户的浏览历史和用户对新闻的行为,用户对新闻的行为指的是用户在此次用户行为时间时展示给他的新闻他是否点击过,点击过的标记为1,否则为0。新闻数据集的每条新闻包括新闻ID、主题分类、副分类、标题、摘要、正文链接、标题的实体信息和摘要的实体信息,这些实体信息是标题和摘要中的一些单词实体的类别、维基百科ID和置信度等等,便于进行词嵌入等操作。
3.1.2评价指标与参数设置
本文使用预训练的Glove嵌入法初始化词嵌入[18],参数设置如下:用于标题和摘要的词嵌入维度设置为300,主题类别和副类别嵌入维度设置为100,CNN网络过滤器设置为425,窗口大小设置为3,dropout设置为0.2,设置Adam优化模型[19],学习率设置为0.01,batchsize设置为64,每个正样本的负样本数设置为4,GRU单元设置为400,Attention queries设置为200。
本文采用的实验评价指标是与主流方法相同的AUC(计算ROC曲线下的面积)、MRR(平均倒数秩)和nDCG(归一化折损累计增益)。算法给用户推荐一个新闻列表,用户实际点击的新闻越靠前,则表明推荐准确度越高,推荐效果越好,上述指标的数值也会越大。
3.2 与其他方法对比实验及结果分析
本文将提出的方法与其他几种作为基线的主流方法进行对比,以此来验证改进后的方法能够提升推荐效果。
(1) LibFM[20]:将矩阵分解法应用于推荐系统中,从浏览的新闻标题中提取的TF-IDF特征和主题类别、副类别归一化计数获取用户特征,之后再与新闻特征连接作为推荐总输入。
(2) DeepFM[21]:结合了因子分解机(FM)和深层神经网络,与LibFM特性相同。
(3) CNN[22]:利用卷积神经网络和最大化池相结合,从最显著的特征中获取新闻表示。
(4) DKN[7]:结合了知识图谱中的信息,包含了卷积神经网络和用户浏览新闻历史注意力机制的深度学习网络。
(5) NPA[23]:使用个性化注意力机制,用卷积神经网络从新闻标题中学习新闻表示,根据用户点击历史学习用户表示并使用单词级和新闻级的个性化注意力机制捕捉不同用户的信息。
(6) NRMS[24]:提出了一种多头部自我注意力机制的方法从新闻和用户浏览历史中学习新闻表示和用户表示。
(7) LSTUR[9]:一种结合了用户长期和短期表示的新闻推荐方法,利用卷积神经网络从新闻的标题中学习新闻表示,从用户信息中学习长期表示,利用GRU网络从最近浏览的新闻中学习短期表示。
虽然以上提到的方法论文中所使用的数据集与本文不同,但其所用的新闻数据中的新闻标题、分类和用户行为数据中的用户点击新闻历史等,MIND数据集都包括。故通过对以上这些论文中提到的方法进行复现,使用本文方法相同的数据集和同样的评价指标得到的推荐结果展示在表4中。
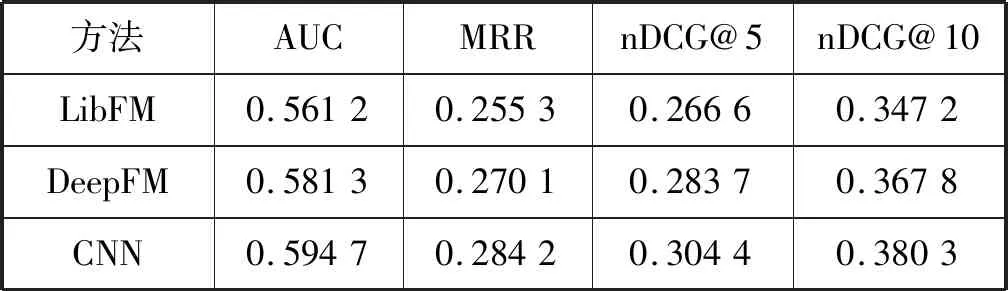
表4 不同方法的新闻推荐结果
推荐结果表明,首先CNN、DKN等使用了神经网络的推荐方法比LibFM、DeepFM这样的采用传统矩阵分解方法的推荐效果要好,体现出采用神经网络能够比传统的矩阵分解更好地从数据中学习到新闻表示和用户表示;其次,采用结合用户长期和短期表示的LSTUR方法的推荐效果比其他只学习一种用户表示的方法的推荐效果要更好,这说明融合多视角学习的方法能够更好地获得用户表示,并应用于新闻推荐中。
最后,从表4中可以看出本文改进的方法比其他的基线方法的效果更好,说明如果只从新闻标题中学习新闻表示是不够充分的,并不能提供最好的推荐效果。本文的方法从新闻的主题类别、副类别、标题和摘要中联合学习,应用注意力机制选出最重要的信息,以此获得更具信息量的新闻表示,并将之应用到基于长短期用户表示的方法中进一步改善推荐的效果。
3.3 验证改进新闻表示有效性的实验
首先,采用消融实验的方法进行了几个对比实验验证加入不同类型的信息对提高学习新闻表示效果的有效性,对比实验的结果如图4所示。
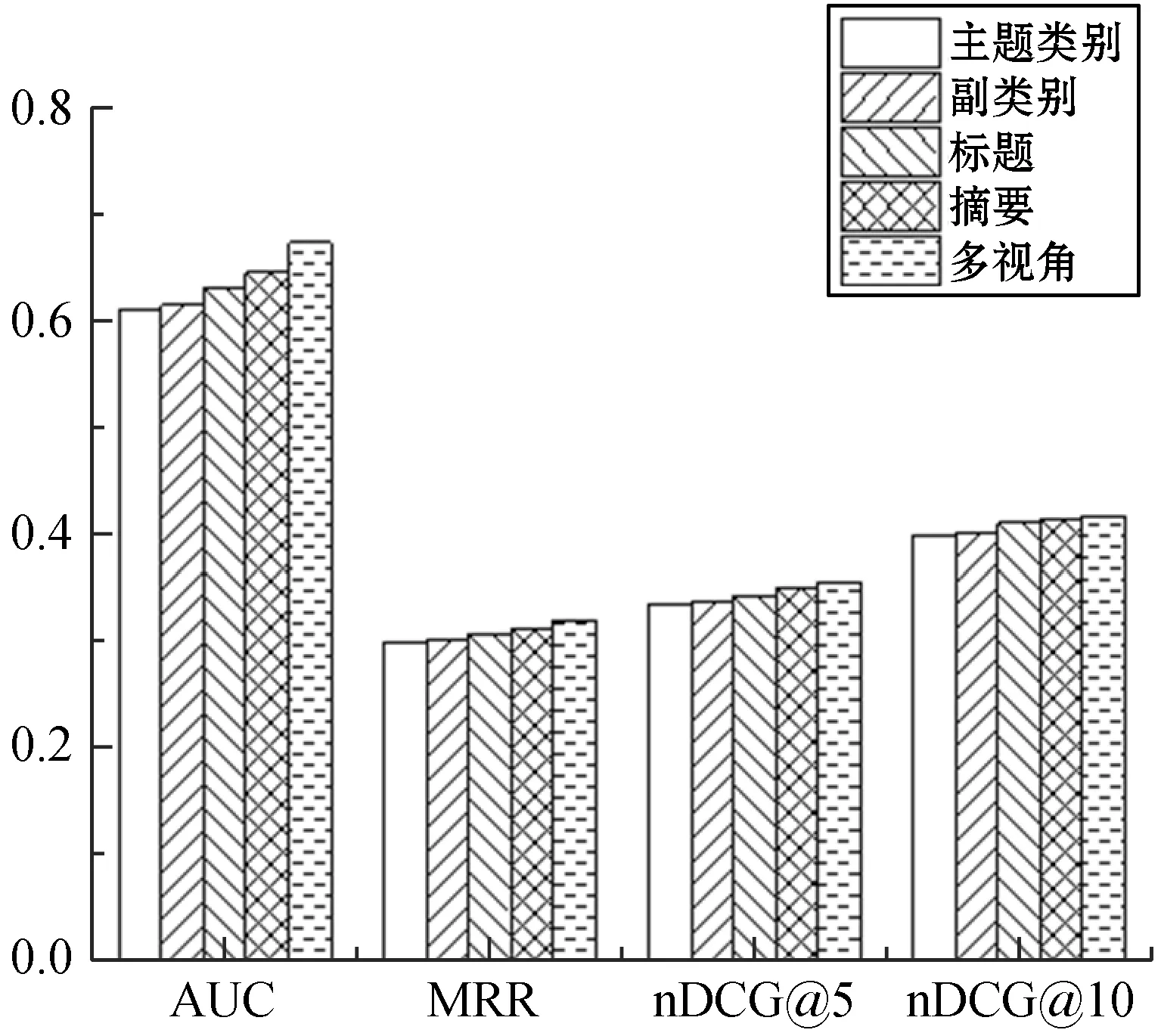
图4 使用不同类型信息的对比实验图
可以看出,使用单一类型的学习新闻表示方法,摘要和标题的效果要比主题类别和副类别要好,因为摘要和标题中含有的信息量较为丰富,能够更为细致准确地反映出用户的阅读兴趣;而摘要的信息量又比标题更丰富,因此在只使用单一类型信息中用摘要学习新闻表示的效果是最好的。但不论是哪一类信息,都能够提供一定的信息量来学习新闻表示,因此把四种类型的信息结合起来才可以取得最好的实验结果。
之后,继续采用消融实验的方法验证新闻编码器中两个注意力机制网络的有效性,实验的结果如图5所示。
本文在新闻编码器中使用了两种注意力机制,一种是从新闻标题和摘要信息中获取新闻表示时,使用词级注意力网络来获取标题和摘要中的重要词汇,另一种是将主题类别、副类别、标题和摘要四类信息进行联合学习时用到的注意力机制。从图5中可以看出,应用联合学习的注意力机制比应用词级注意力网络的效果要好,其原因为不同新闻的四类不同信息的丰富程度不一样,比如有的新闻标题很模糊,而有的新闻标题就已经把新闻概括的很好。这两种注意力机制都对更好地学习新闻表示有所帮助,因此将它们共同使用可以达到更好的效果。
最后,验证学习不同类型的用户表示对推荐结果的影响,实验的结果如图6所示。
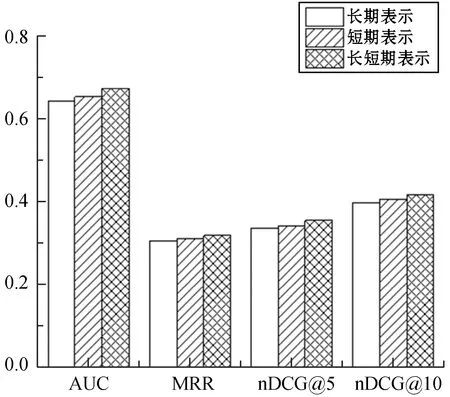
图6 不同类型用户表示的对比实验
可以看出,不论是用户的长期表示还是短期表示都可以提高推荐结果,与此同时,只使用短期用户表示比只使用长期用户表示的结果更好,其原因为用户的浏览历史较少导致长期用户表示所包含的信息不够丰富,最终实验结果也验证了结合长短期用户兴趣来学习用户表示的方法达到的推荐效果是较为理想的。
综上所述,在MIND数据集上,使用基于用户长短期兴趣的方法学习用户表示,使用基于多视角学习的方法从不同类别的信息汇总学习新闻表示,相比于基线方法可以提升新闻推荐的AUC、MRR和nDCG指标。
4 结 语
本文提出了一种融合多视角学习和长短期用户表示的新闻推荐方法,在结合用户长期表示和短期表示的同时从新闻的主题类别、副类别、标题和摘要中联合学习新闻表示。在新闻编码器中使用基于注意力机制的多视角学习方法,将主题类别、副类别、标题和摘要这四类新闻信息看作不同的视角,并应用注意力机制获取其中重要的信息类型和词汇。用户编码器则使用的是基于长短期用户表示的方法,通过改进的新闻编码器学习到的新闻表示来提升获取的短期用户表示,并进一步提升用户编码器效果。在真实数据集上的大量实验表明,相比于其他基线方法,该方法可以有效提高新闻推荐的结果。
猜你喜欢
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
喜剧世界(2016年9期)2016-08-24
新校长(2016年8期)2016-01-10
电子器件(2015年5期)2015-12-29
新闻传播(2015年22期)2015-07-18
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年13期)2014-04-04
