
基于深度主动学习的示功图诊断方法及应用
2023-12-20 04:53李汉周段志刚朱苏青叶红张晓娟
石油化工自动化 2023年6期
李汉周,段志刚,朱苏青,叶红,张晓娟
(1. 中国石油化工股份有限公司江苏油田分公司 石油工程技术研究院,江苏 扬州225009;2. 中国石油化工股份有限公司江苏油田分公司 工程技术管理部,江苏 扬州 225009;3. 中国石油化工股份有限公司江苏油田分公司 采油一厂,江苏 扬州225265)
有杆抽油机是油田开发的主要设备之一,其作业工况极大程度地决定了采油效率[1]。然而,抽油机在采油作业过程中易受一些干扰导致作业异常,需要工程人员能及时作出诊断并处理作业异常。常见的作业异常包括: 不平衡,供液不足,凡尔失灵,上/下行遇阻和气体影响等20多种,表现形式多样,成因也错综复杂,因而实现作业故障的快速诊断是一个巨大的挑战[2]。
目前,国内对于抽油机的故障诊断主要依据采油工程师对悬点示功图的分析和油井管理经验来确定[3]。悬点示功图,也称地面示功图或光杆示功图,是抽油井采油现场采集的第一手资料。示功图不同的几何形状代表作业的不同工况,无异常的示功图为平行四边形,如果抽油机发生供液不足,则会导致作业增载正常但是卸载会变慢,此时示功图会在右下角有缺失,形象表现为手枪状,如图1所示。

图1 正常示功图与供液不足示功图比较示意
早期的示功图自动诊断方法是通过对示功图的图形特征进行归纳总结形成专家系统[4-5],构筑耗时且难以解决复杂问题[6];基于SVM等传统分类器的判别式方法可以获得不错的效果[7],但同样受限于合理的特征选择。因此,本文尝试基于深度学习将示功图的故障诊断问题转化为图像分类问题,在无相关专家知识和领域信息的前提下,通过神经网络自动抽取特征来实现相对传统方法的有效提升。
然而,深度学习这类有监督学习方法需要大量有标签数据作为训练支撑,训练集的数量决定了模型的精度,训练的质量则影响模型的鲁棒性。在工业场景中,示功图数据库往往可达千万级别的规模,从如此海量的样本集中采样并标注出20多个类别的数据集,其难度和成本均是巨大的挑战,尤其是一些较为罕见的工况如杆断等,从千万样本中找出寥寥数个无异于大海捞针。因此,本文基于迁移学习的理念,从预训练卷积神经网络在示功图数据集上微调,降低初始化模型对于样本数量的依赖。此外,本文也提出了一种基于主动学习的示功图数据挖掘方案,一方面基于传统的图形变换方式,对每个样本增强多个平行样本;另一方面,通过模型从数据库中自动筛选出新的样本做增量学习。实验表明,通过迁移学习与主动学习的结合,模型诊断精度获得明显提升,尤其对长尾类别图形提升更为显著。本文的主要贡献如下: 基于预训练深度卷积网络通过迁移学习构建示功图诊断模型,实现了对油杆抽油机作业工况的实时诊断;基于主动学习以自动化样本挖掘的数据增强方式,不断扩展训练集,极大程度地减少了人工标注的难度与成本,带来了稳定的性能提升。
1 示功图诊断算法研究
作者研究项目采用“图形+数据”复合诊断,“图形”对应示功图,“数据”指电参数、套压等生产参数,将示功图的故障诊断问题转化为基于深度学习的图像分类问题。
1.1 基于示功图的作业诊断方法
示功图作为油田作业诊断的第一手资料,一直受到国内外学者的广泛关注[7-8]。早期学者将专家系统用于抽油机工况诊断,利用领域知识与经验建立了典型示功图的规则集合的知识库,可以对示功图使用推理机解析规则进行识别,实现识别诊断[9]。周宁宁等[10]通过模糊理论实现示功图诊断,解决示功图表示不明确的问题,将特征缺失面积与缺失行程定义为隶属变量,设计隶属函数求解出最佳隶属度作为样本类别。杨洋等[11]基于灰色理论,将经过归一化后消除量纲、尺度的示功图利用网格法得到灰度矩阵,再求解其灰度关联特征得到6个元素的特征向量,最终与基准库的11种典型示功图特征作灰度关联分析,从而实现诊断。Sun等[12]通过不变矩理论提取示功图的几何特征作为输入,分别使用BP神经网络[13]和SVM作为分类器识别示功图类型,其中SVM表现更好,83%的正确率高出BP神经网络5个百分点。而随着深度学习的发展,仲志丹等[14]通过稀疏自编码器自动提取示功图图像特征,并通过softmax分类器做分类,在其测试集上获得了98%的准确率[15]。
1.2 基于卷积神经网络的图像分类
近年来,随着数据规模与计算能力的同步增长,深度学习在以机器视觉和自然语言处理为代表的人工智能领域接连获得了重大突破。相较于传统机器学习方法,深度学习无需手动设计特征,通过监督信号对网络参数优化即可获得较好的样本表示。卷积神经网络是一种有效的网络结构,通过卷积核对输入图像进行特征抽取,池化层进行采样,使得模型既对图片的平移、放缩等变化具有一定程度的抗干扰能力,也可以有效降低网络的复杂性,减少参数量,是处理图像问题的主要手段之一。Alex等[16]提出的AlexNet首次将深度卷积网络应用于大规模图像分类ImageNet上就大幅度超越了传统算法。谷歌团队在ILSVRC2014上发布的GoogleNet[17]基于Network in network思想进一步提出Inception模块以稠密组实现了有效降维,减少了模型参数的同时也减轻了过拟合问题。深度残差网络ResNet的出现[18],通过残差结构使得模型不会因为网络过深而产生模型退化等问题,将网络深度成功地加深到152层,逐步产生了规模越来越大的超大模型[19]。
随着网络深度的增加,研究者开始关注网络中不同层的作用,并发现大多数图像模型的底层网络通常都包含着关于图像的基本特征,如颜色、形状、纹理等。因此,研究者提出了迁移学习这一范式[20],通过在现有的大规模数据集上预训练,学习数据的基本特征,再迁移到目标数据集上进行微调训练。相较于随机初始化参数,微调模型收敛速度更快,准确率更高,且仅在少量有标签数据的情况下就可以获得不错的效果。
1.3 主动学习
数据增强是提高数据数量与质量的重要方法,是用有监督学习处理问题的标准范式之一。在图像处理领域,最经典的增强方式是一系列图形变换方法,如平移、翻折、旋转、放缩等方式,由于图形经过变换后,依然保留着原本的语义信息,因此可以作为一个新的训练样本对模型进行训练,使模型学习到目标类别的本质特征;缺点是所增强样本多样性较差,对模型提升有限。除了从输入图像的角度数据增强之外,还可以基于图像编码之后的结果进行增强,具有代表性的工作就是混合方法,该方法将属于同类别的样本特征按照不同比例混合形成新的样本。而随着图像生成领域的发展,部分学者另辟蹊径通过图像生成的方法,基于对抗神经网络随机生成不同类别图像,但是由于生成质量不一,随机性较高,往往难以产生令人惊艳的效果。
主动学习同样是一种高效的数据增强方法,不同点在于,上述三种方法只能相对固定机械地按照预先设定好的逻辑做增强,属于“被动”学习。而主动学习基于模型已学习到的知识能够对于训练过程做自适应优化,模型主动从训练数据集中筛选出更加具有价值的数据样本,经专家标注后再学习,能更好地适应更大规模的数据,既减少标注量和对应的人工成本,也能补足初始训练集的部分缺陷,提高模型精度。传统的主动学习算法包括: 委员会查询、基于数据池的主动学习方法以及基于数据流的主动学习方法。委员会查询算法类似集成学习,通过不同数据分布的数据集训练出多个不同参数的模型,基于投票的方式决定对哪些数据做标注;数据池方法与数据流方法的不同点在于,前者从维护的一定量数据池中选择最有价值的一部分数据再标注,而后者则针对输入的每一个数据样本做判别。本文针对示功图分类问题提出了一种新的基于数据流的主动学习方法,先通过深度学习模型从海量数据中初步筛选出一部分目标样本,再基于数据流主动学习,从而以最小的代价挖掘更多有效数据。
2 功图故障智能诊断模型
2.1 模型结构
示功图诊断是将示功图分类至正常、不平衡、气体影响、供液不足、凡尔失灵等26个类别中,属于图片多分类问题。常规示功图数据在数据库中以二进制编码的形式保存,经由Python程序解码后在画布上作图而形成图片,保留横纵坐标轴为模型识别提供尺度信息,并以224×224的分辨率保存在本地,模型结构如图2所示。
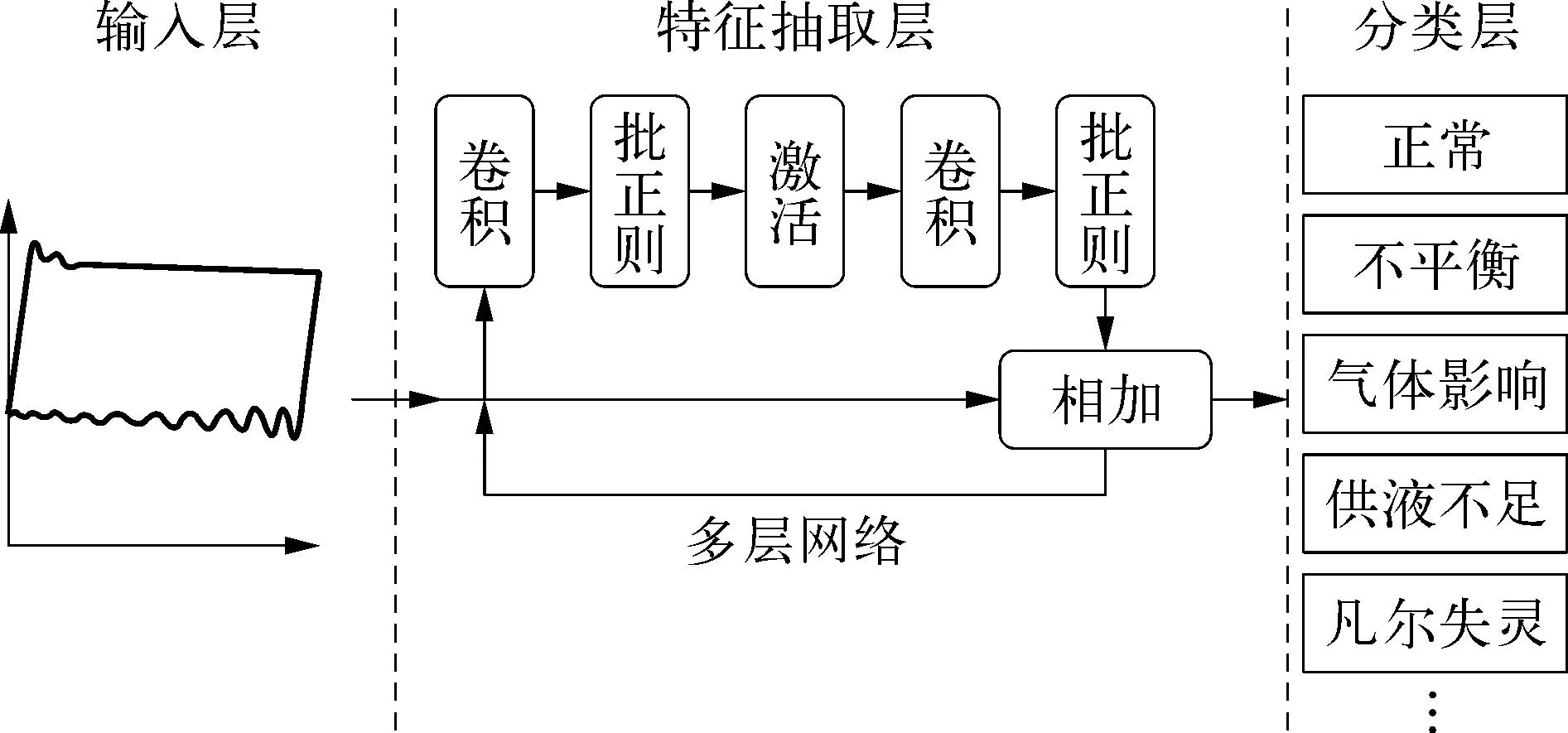
图2 功图故障智能诊断模型结构示意
整个模型的输出通过中间的预训练模型进行特征提取[21],预训练模型内部包括多个残差块,再通过全连接层将特征向量变成目标分类的概率分布实现模型预测,最后通过以softmax激活函数将概率分布归一化,获得最终的分类结果。
2.2 训练集扩充
数据增强是避免模型过拟合的有效方式,针对图片的常见增强方式,包括基础的图形变换,如平移、翻折、旋转、放缩等方式,由于图形经过变换后,依然保留着原本的语义信息,因此可以作为一个新的训练样本对模型进行训练,使模型学习到目标类别的本质特征。除了从输入图像的角度数据增强之外,还可以基于图像编码之后的结果进行增强,具有代表性的工作就是mixup方法,该方法将属于同类别的样本特征按照不同比例混合形成新的样本。此外,部分学者另辟蹊径通过图像生成的方法,基于对抗神经网络随机生成不同类别图像,但是由于生成质量不一,随机性较高,往往难以产生令人惊艳的效果。训练集扩充示意如图3所示。

图3 训练集扩充示意
2.3 特征抽取器
该项目探究了不同残差网络作为特征抽取器的效果,包括ResNet,DenseNet与MobileNet等。ResNet率先将残差结构引入深度神经网络中,将网络深度首次突破100层,并在2015 年的ILSVRC(imageNet large scale visual recognition challenge)中取得了冠军,是目前最经典的图像处理网络之一。DenceNet[22]是对ResNet的一次拓展,相较于ResNet每个残差块是前后直连,DenceNet提出来一个密集连接机制,即网络中的所有层都互相连接,具体而言,每一层网络都会接受其前面所有层的输出作为其输入。在同等参数量时,具有比ResNet更好的性能。MobileNet[23]是一种轻量级的神经网络,采用深度可分离卷积代替普通卷积操作,以降低模型的计算量和参数量。MobileNet在尽可能保证图像分类精度的同时,极大地缩短了网络推理速度,是追求实时性应用的不二之选。
三个模型对于不均衡的样本,ResNet具有最强的鲁棒性,DenceNet最差,可见DenceNet各个层的充分连接带来的强大拟合能力在此处反而使得模型忽略了少数样本的特征。MobileNet更加简洁,因此效果更好,但是相较于ResNet更为强大的迁移学习能力,在少样本上自然稍逊一筹。
分类层通过多层感知机,将网络提取出的图像特征映射到N维向量,每个维度代表着该图片属于对应类别的概率。通过Softmax对概率分布进行归一化,并以交叉熵作为损失函数进行最小化优化,如式(1),式(2)所示:
(1)
(2)
式中,zi——模型预测该图片属于第i类故障的初始概率值;pi——预测概率;qi——真实概率;Loss——对应待优化的交叉熵损失函数,对于每一类故障的概率值,计算预测概率pi与真实概率qi的交叉熵。
3 实 验
3.1 实验设置
首先,作为特征抽取的预训练模块取自ResNet-152,该部分网络参数随着整个模型一同训练,基于微调的原理,学习率设为1.0×10-4,使得模型主要更新任务相关部分而不至丢失预训练信息。优化器为adam,该优化器可以自适应学习率,具有较好的收敛效果。训练样本的批大小为64,模型在该批大小下收敛较为稳定,且能充分运用显存提高推理效率。由于是故障诊断模型,以准确率作为任务的评价指标较为合适,各类别的综合评价指标为宏平均与微平均,其中宏平均是先对每一个类统计指标值后求算术平均值,微平均是根据样本数量采用加权的方式再取平均,可以更好地衡量模型对不平衡样本的性能。详细试验参数设置见表1所列。

表1 试验参数设置
3.2 数据准备
实验数据取自某油田作业数据库,人工定义了22个示功图类别,取其中7种典型示功图的实验结果进行分析,包括正常、气体影响、抽喷、供液不足、不平衡、气锁和杆断。整个数据集以3∶1的比例划分为训练集和测试集,每个样本通过图形变换的方式进行数据增强,每张图片的变换方式包括旋转、放缩、裁剪,因此可以使原数据集扩大3倍。但变化不包括翻折,因为经过翻折的示功图有可能发生语义变化,如供液不足是右下角缺失,翻折之后则变成了左下角缺失,容易对模型产生误导。具体的数据分布见表2所列。

表2 实验数据分布 个
从表2可见,正常、供液不足等类别的样本初始数目就较多,且在数据库中的存量也较多,所以经过新样本挖掘之后,样本数量有着千倍的涨幅。而不平衡、气锁、杆断等类别,在初始化时只有20多个,甚至到个位数,处于完全不可训练状态,而在经过挖掘之后,配合数据增强也达到了可以正常训练的程度。
3.3 实验结果与分析
具体的实验结果见表3所列。

表3 不同模型的实验对比 %
表3展示了3组不同的实验,前2组实验均采用项目最初的少量人工标注训练集。第1组实验“从头初始化”代表着不使用预训练模型,第2组实验“微调”代表着通过预训练模型进行迁移学习。当模型参数从头初始化时,模型的平均精度只有70%左右,且集中在气体影响和不平衡两个类别上,这是由于这两种示功图特点鲜明,使得模型记忆住了该特征而不是学习到该类别,对于数目较少的气锁甚至完全无法识别。而通过迁移学习构建的分类模型即便在训练数据很少的情况下已经可以取得不错的效果。正常、供液不足、气体影响等样本较为充足的类别,其平均准确率已经超过80%,但是少样本的类别气锁受限于样本数量的严重不足,准确率只有60%,依然处于严重不可用状态,可见即便是迁移学习也不能完全替代有标注数据的作用。
而随着新样本挖掘与增量学习的迭代,第3组实验“增量微调”模型在各个类别识别效果均有不同程度的提升,达到了97%的平均准确率,尤其是气锁,从60%到94%提升了34%,达到了工业场景可用的程度。
4 应用效果
基于功图故障诊断的工况类型共分26类,在该油田的油田A一厂和二厂阶段共出现21类故障,经人工审核统计见表4所列。表4中的工况井数包含误报井数,不含漏报井数;正确率=(工况井数-误报井数)/(工况井数+漏报井数)×100%;正常工况里误报的18口井数主要属于油管漏或洗井这一类;工况类型共有28类包括基于功图的26类加停机和待核实的。从表4中可以看出,绝大多数工况诊断的正确率很高,误报井数、漏报井数都比较少。固定阀漏失、碰泵生产、油管漏或洗井、上行遇阻的诊断正确率较低的原因是这些工况的井数较少。

表4 基于功图故障诊断的统计结果
5 结束语
本文提出了一种基于深度学习的示功图诊断方法,针对示功图数据标注的成本与难度,一方面通过迁移学习的方式降低了模型训练对于大量有标注样本的依赖;另外一方面提出了一种少样本数据挖掘范式,以增量学习的方式,不断迭代模型,提高模型的上限。实验表明,该方法可以在满足模型性能的同时,有效地控制数据标注的成本,在工业场景下具有较强的借鉴意义。
猜你喜欢
煤气与热力(2022年4期)2022-05-23
舰船科学技术(2021年12期)2021-03-29
铁道通信信号(2020年1期)2020-09-21
新校长(2016年8期)2016-01-10
石油化工自动化(2015年6期)2015-02-26
水电站机电技术(2014年5期)2014-09-26
商事法论集(2014年1期)2014-06-27
压缩机技术(2014年4期)2014-03-20
中国中医药现代远程教育(2014年16期)2014-03-01
河南科技(2014年11期)2014-02-27
