
基于高频已实现协方差预测的约束的投资组合研究
2023-12-29 04:16刘广应施科文徐鸣一张亦驰
吉林工商学院学报 2023年6期
刘广应,施科文,徐鸣一,张亦驰
(南京审计大学1.统计与数据科学学院2.数学学院,江苏 南京 211815)
一、引言
投资组合研究是金融计量学者的研究热点,金融从业人员也十分关注投资组合的实际投资效果。近年来,最小方差投资组合受到大量学者关注。DeMiguel 等(2009)[1]指出最小方差投资组合的夏普比率表现经常会优于经典的均值方差投资组合。Bollerslev 等(2018)[2]采用最小方差投资组合对构造的协方差矩阵动态预测模型进行经济学评价。相对于经典的均值方差投资组合,最小方差投资组合模型没有引入预期收益率,只考虑了协方差矩阵的预测结果,避免了对未来收益率的预测难题。
投资组合的建立主要涉及到多只金融资产收益率的协方差矩阵和预期收益率,其投资表现也主要依赖于协方差和收益率的预测精度。金融高频数据含有丰富的市场信息,近年来人们可以很便利地获得金融高频数据。关于金融高频数据的研究,特别是协方差矩阵的度量和预测等,都是金融计量领域的研究热点。Andersen和Bollerslev(1998)[3]提出了已实现波动率,用来度量每日金融资产收益率的波动,该度量无需利用历史数据,只需利用当日的高频数据即可得到当日该资产价格的波动率,具有很好的时效性。Andersen 等(2003)[4]发现已实现波动率时间序列具有极强的长期记忆特性,可以利用分整移动自回归(ARFIMA)模型给予预测。Corsi(2009)[5]提出了异质自回归(HAR)模型预测未来已实现波动率,该模型预测效果较好,且模型简单。Barndorff-Nielsen和Shephard(2004)[6]提出了已实现协方差矩阵,用来度量多只金融资产价格收益率的协方差矩阵。已经产生了一些初步预测模型,利用高频波动率序列的长期记忆性等特性预测未来协方差矩阵。以上实证结果表明,相对于基于低频日收益率序列建立的协方差模型,基于高频数据建立的已实现协方差预测模型,其预测效果较优。
由于协方差的估计和预测都面临高维问题,有较大的误差,基于带有误差的最小方差投资组合通常表现较差。实际数据分析时,最小方差投资组合的风险(方差)较小,但通常存在平均收益也相对较小的问题。为了提高最小方差投资组合实际投资表现,目前主要有两种方法。一是给投资组合的权重添加适当约束条件,提升投资效果。Fan等(2012)[7]通过限制投资组合允许做空比例改善投资组合绩效,提出了L1范数约束的最小方差投资组合。Ding 等(2021)[8]基于因子模型考虑了L1约束下的最小方差投资组合表现。这些文献协方差矩阵模型未考虑动态建模,只利用历史协方差矩阵的估计值,分析其投资组合效果,也没有充分考虑波动率的长期记忆性。二是构建更为准确的协方差矩阵预测模型。Callot 等(2017)[9]首先利用金融高频数据得到已实现协方差矩阵,然后对其进行对数变换,再进行向量化,利用向量自回归(VAR)模型进行预测建模,利用LASSO 方法对VAR 模型的回归系数进行降维估计,得到了LASSO-VAR 预测模型。Oh 和Patton(2016)[10]借鉴动态相关系数模型,将已实现协方差分解为DRD,其中D是由单个资产的已实现波动率构成的对角矩阵,R对应于已实现相关系数矩阵,对D每个元素分别通过单变量HAR模型预测,对R进行向量化后建立向量HAR 模型进行预测,构造了HAR-DRD 波动率矩阵预测模型。Bollerslev 等(2018)[2]对HAR-DRD模型进行拓展,利用HARQ模型预测D的每个元素,构造HARQ-DRD模型预测协方差矩阵。这些文献在考虑协方差矩阵预测模型的投资组合分析时,都没有考虑L1约束条件下的投资组合表现。
高频波动率的长期记忆特性,有助于预测已实现协方差矩阵预测,提升预测效果;具有L1约束的最小方差投资组合实际效果较好。本文将这两者给予结合,构建高频已实现协方差矩阵预测视角下L1约束的投资组合。首先,通过日内高频数据估计得到已实现协方差矩阵,并建立HAR-DRD和HARQ-DRD模型对已实现协方差矩阵序列进行预测,这类模型充分利用了波动率的长期记忆性,可以得到更精确的协方差矩阵预测值;并将预测得到的协方差矩阵应用到投资组合建立中,构建L1约束的最小方差投资组合模型。实证分析表明,与其他模型进行对比,本文提出的基于高频协方差预测视角的L1约束的投资组合具有优越的绩效表现和应用价值。
本文主要贡献在于:一是将L1约束的投资组合研究应用到高频数据场景,并与具有长期记忆特性的已实现协方差矩阵预测模型相结合,分析其投资效果。二是针对中国金融市场的高频数据进行L1约束的投资组合分析,给出实证结果与相关结论。
二、L1 约束的投资组合
均值方差投资组合受到了学术界和业界的极大关注。为了在实践中实施这一投资策略,需要对预期收益和收益协方差结构进行准确估计和预测。Merton(1980)[11]指出,预期收益的估计比协方差的估计更困难,预期收益的估计误差对投资组合绩效的影响大于协方差估计误差对投资组合绩效的影响,这些困难对经典的均值方差模型实施提出了严峻的挑战。
近年来,最小方差投资组合(MVP)受到了大量的关注。最小方差投资组合与均方差组合有所不同,最小方差组合避免了估计预期收益的困难,但其本身依然为有效投资组合。实证研究表明,最小方差组合与均值方差投资组合相比,通常具有更低的风险和更高的收益率。此外,它也为评估不同的协方差矩阵估计量或预测模型提供了一种方法。
理论上,最小方差投资组合就是在给定p个风险资产的条件下,寻求最小风险投资组合,也即求解如下问题:
上述(1)式的ωt=(ω1,t,ω2,t,…,ωp,t)'为第t天p个资产对应的投资组合权重,Σt为第t天资产收益率的协方差矩阵,表示元素全部为1的一个p维列向量。那么权重向量最优解和最小风险满足如下表达式:
根据(1)式,如果得到收益率向量的协方差矩阵Σt的估计式,即可计算出最小方差投资组合的最优权重。在高频数据情况下,时间间隔较小,预期收益率通常很小,当假设预期收益率为0时,经典的均值方差投资组合问题就转化为了最小方差投资组合问题。因此,在高频数据情形下,采用最小方差投资组合也更为恰当。在高频数据下分析投资组合具有如下优点:一方面,大量的观察值有助于更好地理解收益协方差结构;另一方面,高频数据允许短时重新平衡,因此投资组合可以快速调整以适应波动率的时间变化。
最小方差投资组合的模型主要由(1)式给出,其最优投资权重和最小风险(方差)主要由(2)式给出。在实践中,由于(1)式协方差矩阵未知,因此建立最小方差组合前,必须建立协方差矩阵的估计和预测模型。然而由于对实际协方差矩阵估计误差的存在,其实际表现较差。学者发现最小方差投资组合对投资权重向量没有约束,允许卖空。在实际进行投资时,会产生卖空比例较大的问题;更新投资组合时,容易出现投资转换成本较高等问题。为了克服以上问题,需要对投资组合向量进行约束,Fan等(2012)[7]、Ding等(2021)[8]指出可以利用对投资权重向量进行L1范数约束,提出了L1约束的投资组合模型:
式(3)中M为一调节参数,用于控制投资组合权重允许卖空数量。这里施加L1范数约束(又称总风险敞口约束)可以控制投资组合的卖空头寸,即控制投资组合的允许做空比例。常数M与允许做空比例具有如下关系:做空比例等于。当M=1时,此时投资组合不允许卖空。
通过L1范数对投资组合进行约束具有如下优点:1.控制投资成本。实际投资中卖空将承担较大的卖空成本,L1约束将限制卖空比例,进而可以较好地控制卖空成本。2.降低投资组合的转换成本。现实中,一个投资组合通常需要经常更新,经过L1约束后的投资组合,更新变化相对较小,因此,投资组合的转化成本也相对较低。3.采用L1约束的投资组合,每只股票的投资比例都相对平衡,即使遇到个别股票出现较大变化时,整个投资组合收益影响也较小,因此投资组合的风险也较小。
在实际操作中,我们通常希望这个投资组合在未来表现最优,因此,最小方差投资组合模型(1)式、L1约束的最小方差投资组合模型(3)式的Σt,应当是对未来的协方差矩阵的预测值。
三、高频已实现协方差预测模型
(一)高频已实现协方差
Barndorff-Nielsen和Shephard(2004)[6]提出了已实现协方差矩阵,用于估计多只股票收益率的协方差矩阵,其定义为:
其中ri,kδn,t表示第i只金融资产在第t天第kδn时刻的对数收益率,RCovij,t表示第i只和第j只金融资产第t天的已实现协方差,p表示资产总个数,K表示一天内高频数据采样的数据量。中国股票市场每日交易时间为4小时,当采样间隔定义为5分钟时,K=48。因此可以通过当天的高频收益率数据计算得到当天的已实现协方差矩阵,并且当采样间隔δn趋于0时,得到的已实现协方差矩阵RCovt是积分协方差矩阵的一致渐近无偏估计,可以利用日内高频数据估计出每日的协方差矩阵,此时波动率矩阵就变成了可观测值,进而可以得到已实现协方差矩阵序列。
(二)DRD分解
DRD分解是金融领域中用于处理已实现协方差矩阵的一种重要方法。该方法的主要目标是将已实现协方差矩阵分解为两部分:已实现波动率矩阵D和已实现相关系数矩阵R,以实现数据降维,以及更准确地捕捉资产波动性和关联性的变化特征。针对p×p维已实现协方差矩阵RCovt的DRD分解为:
其中:
这里Dt为已实现波动率组成的对角矩阵,Rt为已实现相关系数矩阵,反映了资产之间的关联程度。实际数据分析表明,Dt和Rt具有不同的动态特征,分别对它们进行预测将有助于更准确地捕捉市场变化的趋势,降低预测误差。此外DRD分解还可以保证协方差矩阵的正定性,因而成为金融领域中用于波动率建模和风险管理的重要工具,对投资组合管理和风险控制具有重要意义。
(三)HAR-DRD模型和HARQ-DRD模型
为了刻画高频数据波动率的长期记忆性,Corsi(2009)[5]提出了异质自回归(HAR)模型,这一模型比较简单,在实证研究中取得了很好的预测效果。Chiriac和Voev(2011)[12]借鉴HAR模型的思想,针对已实现协方差矩阵进行建模,将异质自回归HAR模型扩展为向量HAR模型。注意到已实现协方差矩阵RCovt为对称正定矩阵,将RCovt下三角部分拉直成向量,得到对应向量St=vecℎ(RCovt),其维数是,对St(t=1,2,…T)建立向量HAR模型:
Oh 和Patton(2016)[10]借鉴Engle(2002)[13]的动态条件相关系数模型(DCC)思想,构建了HAR-DRD 模型。该模型构建步骤如下:(1)将高频已实现协方差矩阵RCovt按照DRD分解得到Dt和Rt;(2)将Dt进行对数变换得到lnDt,对lnDt的每个分量建立单变量HAR模型进行预测;(3)由于Rt是对称矩阵,因此只需取Rt下半部分得到vecℎ(Rt)后建立向量HAR模型进行预测,最后将预测值与按照(5)式相乘即可得到协方差矩阵的预测值。
HAR 模型在建模时没有考虑已实现方差的估计误差,Bollerslev 等(2016)[14]将估计误差引入到已实现方差的预测模型,建立变系数HAR 模型,即HARQ 模型。利用已实现方差估计积分波动率的估计误差方差,可以利用已实现四次变差来估计。第i个资产已实现四次变差定义为,故单变量HARQ模型定义为:
其中RVi,t=RCovi,i,t,分别表示第i个资产已实现方差和h天的平均值。
Bollerslev等(2018)[2]提出了HARQ-DRD模型,该模型的构造与HAR-DRD模型类似,区别在于HARQDRD模型的第二步,对lnDt分量用了单变量HARQ模型(8)式进行预测,其余步骤一致。
四、实证分析
(一)实际数据
本文选取了上证50成分股中的10只股票的收益率数据进行预测分析,选取其中股票代码排在前10的股票,数据起止时间为2004年1月2日至2019年12月31日,高频数据采样间隔为5分钟,数据来源于锐思数据库。在剔除异常值数据后一共有3 834个交易日数据,对于数据缺失值进行填补后得到了完整的5min高频收益率数据集。本文将整个数据集划分为两部分:样本内数据和样本外数据。样本内数据用于训练模型参数,样本外数据用于评价模型泛化效果。选取2004年1月2日至2015年5月6日共2 704个交易日作为样本内数据,2015年5月7日至2019年12月31日共1 130个交易日作为样本外数据。
图1给出了10只股票已实现波动率RDt和已实现相关系数Rt的均值时间序列图。从图1可以发现已实现相关系数相较于已实现波动率其变化程度更大,波动更加明显,已实现相关系数的时序图轨迹更加粗糙,而已实现波动率时序图有明显的波峰,变化小且相对更加稳定。由此我们可以发现已实现波动率RDt和已实现相关系数Rt两个部分分别有不同的动态特征,因此将已实现协方差矩阵通过DRD分解成Dt和Rt后,再对两部分分别进行建模,这样能利用到更多有效信息,更加科学合理。
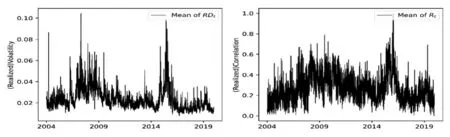
图1 已实现波动率RDt 均值和已实现相关系数Rt 均值的时间序列图
(二)评价标准
在对协方差矩阵进行预测时,需要对其预测效果进行评价。本文通过模型预测得到的协方差矩阵与样本外数据计算得出的真实协方差矩阵进行对比,分别计算出各个模型的MSE、RMSE和MAE,通过这三个指标来衡量模型预测的准确度,公式如下:

在实际金融市场中,建立投资组合时需要考虑到投资组合的交易成本、资产集中度和卖空成本等因素。因此本文计算了投资组合第t天到第t+1天的周转率TOt、集中度COt和卖空资产权重SPt来度量投资组合的优劣,具体计算公式如下:
在考虑了交易成本和卖空成本后,投资组合ωt在第t天的实际收益率计算方式如下:
其中c1代表交易成本率,c2表示卖空时贷款利率。本文取c1=0.1%、c2=6%/360,分别表示交易成本为成交金额的0.1%、卖空时的贷款年利率为6%。
(三)实证结果
本文除了给出HAR-DRD和HARQ-DRD协方差预测模型的实证结果,还给出了向量自回归VAR模型、向量异质自回归HAR模型以及基于Cholesky分解的HAR-CHOL 模型等对比模型的实证结果。向量自回归VAR 模型为直接对已实现协方差矩阵的下三角进行拉直向量化,利用一阶向量自回归建模预测得到未来已实现协方差矩阵;向量HAR 模型即为模型(7)式。HAR-CHOL 模型为首先对已实现协方差矩阵进行Cholesky 分解,对分解后的下三角矩阵进行向量化,然后利用向量HAR 进行建模预测未来已实现协方差矩阵。
表1给出5种已实现协方差矩阵预测模型在样本外数据集(2015年5月7日至2019年12月31日)已实现协方差矩阵的预测实证结果。由表1 可以得出以下结论:1.将估计误差信息考虑在内HARQ 模型相较于HAR模型预测效果略优。2.相较于简单地将已实现协方差矩阵拉直成向量后直接进行预测的VAR模型和HAR 模型,先将已实现协方差矩阵进行分解处理再进行预测的HAR-CHOL、HAR-DRD、HARQ-DRD 模型预测效果更优。3.采用DRD分解的HAR-DRD模型和HARQ-DRD模型相较于直接建模的HAR模型、VAR模型和基于Cholesky分解的HAR-CHOL模型预测精度更高,说明DRD分解能够捕捉波动率矩阵的动态特征,对具有不同动态特征的Dt和Rt分别进行建模有助于提升模型预测精度。

表1 已实现协方差矩阵模型预测结果(括号内为排名)
表2和表3给出了L1约束的最小方差投资组合和无约束的最小方差投资组合实证结果,表2为考虑交易成本和卖空成本情形,表3为考虑了交易成本和卖空成本情形。为了分析基于高频数据的协方差矩阵估计量和基于低频数据的协方差矩阵估计量在投资组合中的差异,还考虑了基于Fan 等(2013)[15]提出的POET协方差矩阵估计量的投资组合结果,POET协方差矩阵估计量只利用低频日收益率数据,未利用高频数据。
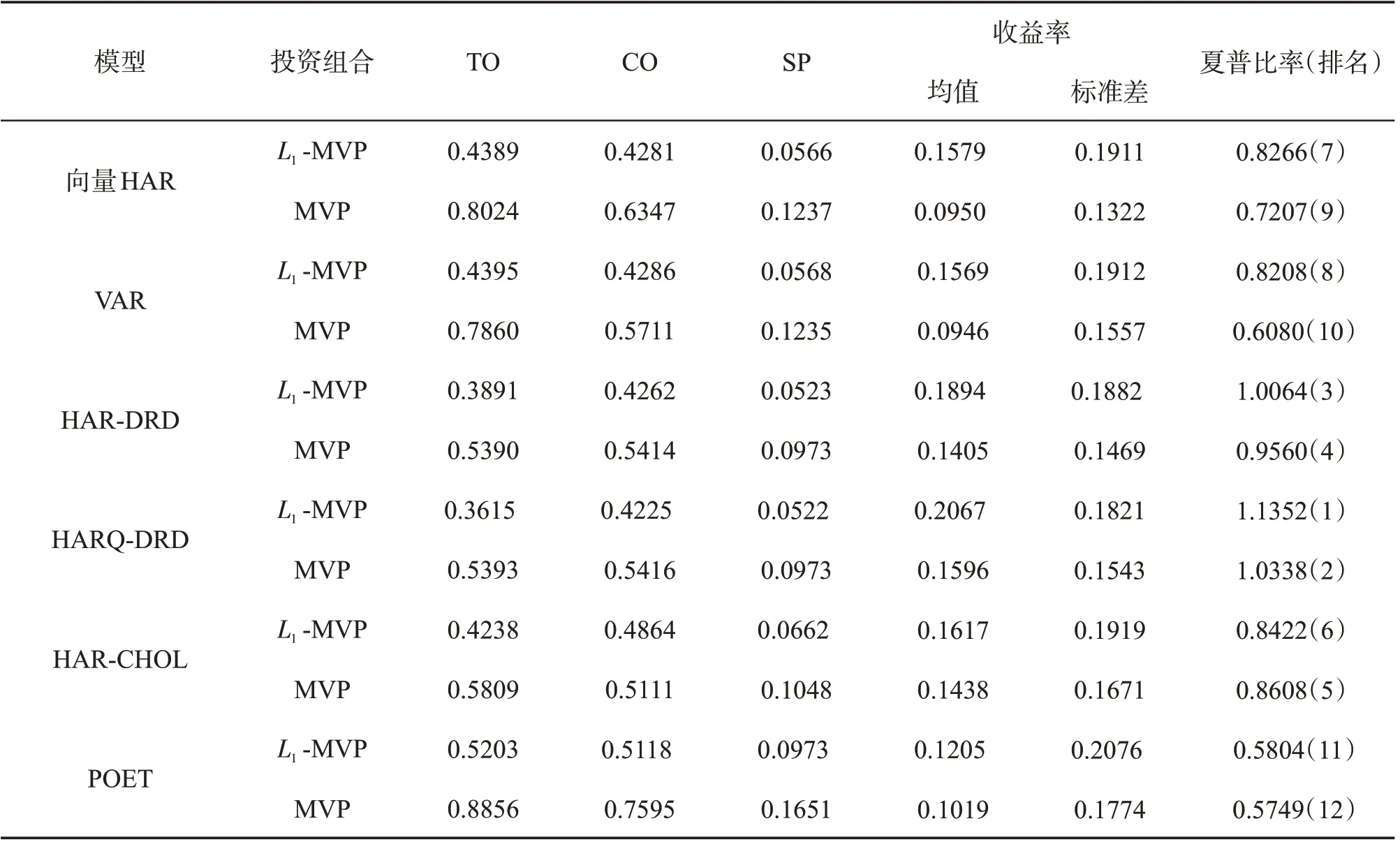
表2 L1 约束的投资组合与最小方差投资组合实证结果(未考虑交易成本和卖空成本)

表3 L1 约束的投资组合与最小方差投资组合实证结果(考虑交易成本和卖空成本)
根据表2和表3我们可以得出以下结论:1.相同协方差矩阵预测模型得出的L1约束最小方差组合,相对于最小方差投资组合,其周转率TO、集中度CO、和卖空头寸SP 都相对更低,投资组合更加均匀稳定,风险较低,收益相对较高,夏普比率也更高,可见在对投资组合的卖空头寸进行限制后能够显著改善投资组合表现。2.基于高频数据的已实现协方差矩阵预测模型得出的投资组合相较于基于低频数据的POET协方差矩阵估计量得出的投资组合表现更好,说明使用日内高频数据估计协方差矩阵相较于低频数据能够获取更多有效信息,改善投资组合绩效表现。3.结合表1结果,已实现协方差矩阵预测越准确的模型,对应的投资组合效果也越佳,采用L1约束的HARQ-DRD投资组合模型综合表现最佳。
五、结语
本文结合高频已实现协方差矩阵预测模型,研究了L1约束下最小方差投资组合。通过已实现协方差矩阵预测模型,构建了基于高频数据的L1约束最小方差投资组合。实证分析表明:1.与无约束最小方差投资组合相比,具有L1约束的最小方差投资组合风险较低、成本较小、夏普比率较高。2.采用高频数据已实现协方差预测模型的投资组合,其投资效果也优于基于低频数据协方差预测模型的投资组合。3.采用了DRD分解的模型相较于没有采用DRD分解的模型,无论是协方差矩阵预测精度还是投资组合绩效表现都存在一定优势,分解后针对相关系数矩阵R和已实现波动率矩阵D的单独建模,有助于捕捉各自规律,具有较低的预测误差,表现出更好的投资效果。
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-05-25
商业会计(2021年13期)2021-07-27
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
初中生世界·九年级(2017年10期)2017-11-08
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
考试周刊(2016年54期)2016-07-18
自动化学报(2016年8期)2016-04-16
湖南师范大学自然科学学报(2013年5期)2013-03-11
