
基于偏移注意力机制和多特征融合的点云分类
2024-02-15 03:04田晟宋霖赵凯龙
华南理工大学学报(自然科学版) 2024年1期
田晟 宋霖 赵凯龙
(华南理工大学 土木与交通学院,广东 广州 510640)
随着深度学习在各领域的兴起,对点云相关的研究也逐渐深入。由于点云可以获取物体的三维坐标等多种信息,且具有无序性、旋转不变性和稀疏性的特性,在自动驾驶、机器人和测绘方面都得到了广泛的应用,目前对点云分类主流的研究方法主要有基于多视图的方法、基于体素的方法、直接基于点的方法等。
在基于多视图的研究方法中,MVCNN[1]实现了不同角度投影的特征提取,相对于传统的机器学习算法有一定的提升。基于体素的方法是采取已有的方法将点云转换为三维体积形状,利用现在较为成熟的三维卷积网络实现分类,2015 年Voxnet 网络[2]的提出实现了体素在点云分类中的应用。Zhang等[3]将注意力机制和基于体素的方法相结合,分类总体准确率达到了94.0%。对多视图而言,由于视点的位置和角度的变换会导致部分重要信息的丢失,而基于体素的方法对资源消耗比较大。
相对于多视图以及体素的研究方法,直接对点云数据进行特征提取不仅减少了前期人工处理工作,且不易丢失特征信息,充分利用了点云数据的优势,是研究人员较为热衷的方向之一。Qi等[4]于2017 年提出PointNet,直接利用多层感知机(MLP)提取最终全局特征,又于同年提出PointNet++[5]进行最远点采样并分组,通过PointNet 提取点云局部特征,经最大池化进行降采样以减少运算量。PointCNN[6]利用多层感知机实现点特征变换以模仿CNN 进行特征提取。Wu 等[7]提出的PointConv 通过构建逆密度变换实现卷积核的动态更新,分类总体准确率达到了92.5%。陈根等[8]通过整合点与点的关系特征以及中心点的特征,分类总体准确率与PointConv 相同。Xu 等[9]提出的PAConv 通过利用动态生成的分数权重乘以初始权值以实现卷积核的动态更新,嵌入DGCNN 网络准确率较PointConv 提升1.1%。Wang 等[10]提出的DGCNN 采用图卷积的方式,聚合中心点和邻居节点的特征,实现了邻居节点特征的聚合,分类总体准确率达到了92.2%。Zhang 等[11]在DGCNN 的基础上,引入残差结构,实现不同层级动态图的连接,准确率较DGCNN 提高了0.7%。以上网络模型都较少考虑点云多特征的融合,而全局和局部特征还可以进一步的丰富,兰红等[12]利用图卷积提取节点间位置关系,利用三维方向卷积捕捉节点间方向信息,进行信息组合获取更加丰富的局部邻域特征。芦新宇等[13]构造局部-非局部交互卷积模块,实现低层次的几何信息和高层次的语义信息的融合,构建的卷积神经网络分类总体准确率达到了93.4%。戴莫凡等[14]融合了3 个尺度下的K 近邻点云特征导入提出的几何卷积神经网络模块。杜静等[15]同时引入残差优化结构和多特征融合方法实现了S3DIS(Stanford Large-Scale 3D Indoor Spaces Datase)室内和Semantic3D 室外数据集的点云语义分割。从大多数学者的网络改进方式来看,直接对点云实现分类的网络结构,大多是基于PointNet和DGCNN网络进行局部改进。
随着Transformer[16]在自然语言处理等领域效果日渐显著,不少学者利用Transformer的思想,对网络模型进行改进以适应点云的特性。Zhao等[17]设计自注意力机制层应用于3D 点云分类。Chen 等[18]将注意力机制嵌入图神经网络中,采用多头注意力机制,提出点云分类网络GAPNet,通过学习局部的几何表示,得到了在中心点附近不同的注意力权重,实现更加有效地利用局部特征。Guo 等[19]提出的PCT网络对自注意力机制所得的特征矩阵和原始矩阵作差以得到偏移注意力机制,实现了93.2%的总体分类准确率。陈涵娟等[20]提出竞争注意力融合模块嵌入基准网络,实现多层级特征融合,并同存在噪声的数据集测试结果进行了对比实验,最优总体准确率达到93.2%。王利媛等[21]引入PointConv 中的点卷积算子和注意力机制模块,在ISPRS Vaihingen三维语义标记基准数据集和GML_DataSetA室外机载点云数据集上进行分类测试实验,验证了方法的有效性。
同时也有不少计算机图形学中的几何学的知识应用于点云特征提取当中,对整体或者部分区域的几何结构特征进行描述,如CurveNet[22]选取了点云中的曲线以突显局部形状,RepSurf[23]提出的Umbrella Surfaces较好表示局部几何结构,也取得了较好的效果。由于利用几何形状的特征提取计算过程较为复杂,故尝试直接利用Tansformer 的思想和多特征融合方法实现点云分类。
无论是基于体素、基于多视图还是基于点的方法,大多仅单一考虑了全局或局部特征,针对这一问题,本文将点的全局特征信息和局部信息进行融合,并利用残差连接和偏移注意力机制,提升特征提取能力,实现测试集上点云对象的类别判定。
1 网络框架
1.1 模型总体结构
本文受到LDGCNN[11]和PCT[19]网络的启发,提出了一种基于融合注意力机制的多特征融合残差网络,利用Offset-Attention 模块[19]实现初始特征提取,然后实现点云特征和三维坐标特征的融合,引入残差结构以防止浅层特征的丢失。网络总体框架和框架细节如图1和图2所示。
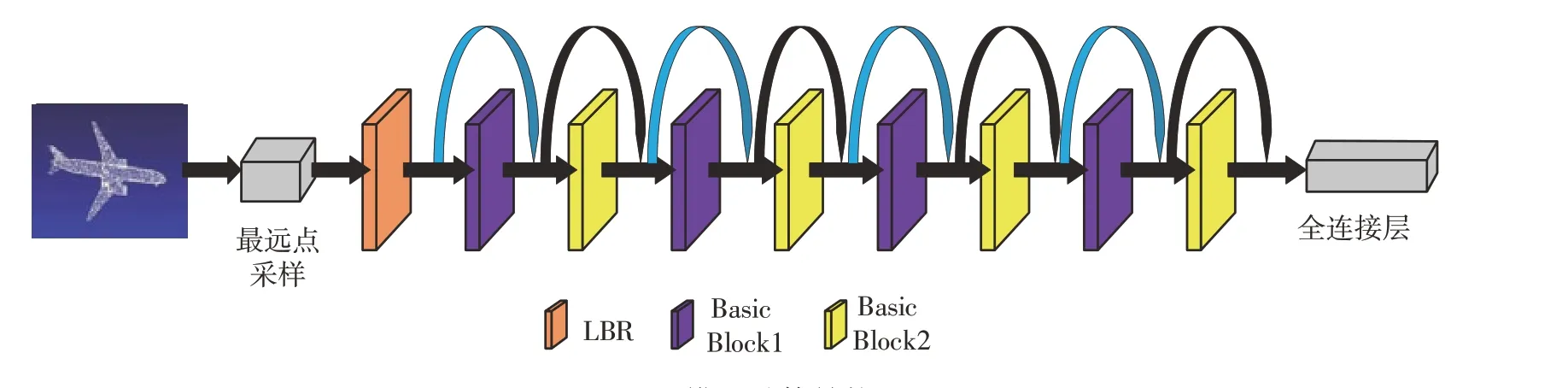
图1 模型总体结构Fig.1 The overall structure of the model

图2 网络结构细节Fig.2 Network structure details
图1中,模型总体采用类似ResNet的结构,以两个基本模块构成一个网络层级,其中第1类基本模块会改变点云特征矩阵的通道数,故采用蓝色箭头进行连接,第2类基本模块用于提取更深层次的网络特征,不改变特征矩阵通道数,故采用黑色箭头进行连接。
多个网络层级进行残差连接以提取深层次的隐式特征,最后通过最大池化和平均池化得到全局拼接的点云特征,导入全连接层实现点云分类任务,网络总结构如图2所示。
图2中的虚线框(Make Layer1)详细描述了单个网络层级中基本模块的构成情况,虚线框Basic Block1描述了第1类基本模块,虚线框Basic Block2描述了第2 类基本模块,两类基本模块中都包括LBR(Linear,BatchNorm and ReLU layers)、OFSA(Offset-Attention)和MFA(Muti-Feature Aggregation)模块。LBR包括卷积层、批量正则化层和Relu激活函数,卷积层用于改变特征矩阵的通道数,批量正则化以防止模型过拟合,加快模型训练速度,Relu激活函数用于增加模型的非线性拟合能力;OFSA模块为偏移注意力机制,用于改变特征权重,介绍见1.2 节;MFA 模块指多特征融合模块,详见1.3 节。网络训练过程中,首先通过LBR 改变采样点矩阵的通道数,使维度从三维坐标特征转换为32 维的隐式特征,同时通过将输入点云输入MFA模块以得到9 维的显式特征,对显式特征使用LBR以和隐式特征的特征通道数一致,实现与隐式特征融合,并将融合得到的特征矩阵输入多层残差模块进一步提取点云的特征信息。
1.2 偏移注意力机制
人类大脑在观察事物时会快速定位并提取关键信息,以作出相应的决策,注意力机制通过对所提取的特征信息分配不同权重以模拟人类大脑快速定位关键信息的能力,从而更加关注较为重要的特征区域,过滤不重要的信息点,提高网络模型在数据噪声下的预测性能,具有较高的鲁棒性。
缩放点积注意力机制(Scaled Dot-Product Attention)的原理是通过某种映射将嵌入的特征矩阵生成不同类型的Q、K、V权重系数矩阵;偏移注意力机制是通过不同的多层感知机(MLP)生成Q、K、V权重系数矩阵,权重矩阵Q和K进行矩阵相乘,并使用Softmax 函数激活相得到Attention 系数矩阵,与V特征矩阵进行哈达玛积得到一个重构特征,并对原始特征与重构特征进行作差,通过LBR 得到最终Offset-Attention层的特征。其中具体的计算公式如下:
式中,m为输出的重构特征矩阵,Fin为输入的特征矩阵,Q为用于查找的系数向量,K为其它用于接受的系数向量,V为自身的向量。
在自然语言处理中,Transformer 网络中Attention机制由于存在较好的效果而得到了广泛的应用,受注意力机制与传统网络模型进行混合的启发,本文采取偏移注意力机制,将改进的注意力机制嵌入特征聚合模块,其中偏移注意力机制的结构如图3所示。

图3 Offset-Attention模块Fig.3 Offset-Attention module
图3中,Conv1d为一维卷积,主要用于改变特征矩阵第2 个维度(Channel)的大小,b为批次数,c为特征矩阵的通道数,n为点的个数,Softmax 为激活函数将数值向量进行归一化为概率分布向量,用于实现多分类问题的输出。
1.3 残差模块
引入残差结构有助于解决梯度消失和梯度爆炸的问题,在训练更深的网络时可以有效防止网络退化的问题。主干结构上采用快捷连接,使用两个卷积层以改变特征矩阵的通道数,使用偏移注意力机制模块(OFSA)和多特征聚合模块(MFA)实现特征重构,另外,对输入层进行恒等映射,并根据输入和输出特征矩阵通道数是否一致,来实现跳跃连接(Identity),具体结构如图4所示。

图4 残差模块Fig.4 Residual module
1.4 多特征融合模块
多特征融合模块如图5所示,为虚线框所选取的MFA 部分。注意力机制每一步计算都不依赖于上一步的计算结果,可实现和CNN 一样的并行处理操作,可替代CNN,能表达任何卷积滤波层[24-26]。图5 中的上半分支,通过最远点采样得到1 024个采样点P={pi|i=1,…,N}∈RN×3,将得到的采样点作为中心点,通过Offset-Attention 注意力机制得到聚合后的中心点特征Fi,与DGCNN 网络对特征矩阵中心点和邻居点拼接不同,本文以广播方式直接对邻居点特征和中心点特征进行求差Fj-Fi,以获取局部邻域特征信息。图5的下半分支是对采样中心点Pi以KNN(K-Nearest Neighbor)算法找到其邻居节点Pj∈Ni,Ni为中心点的k个近邻点坐标集,指中心点和邻居节点构成的一个集合,图中的Pjk均指采样点周围的邻居节点。对采样得到的中心点坐标Pi,中心点k个邻居节点坐标Pjk、中心点与邻居节点的相对坐标Pjk-Pi进行拼接,得到了通道数为9的4维特征矩阵,拼接后利用一维卷积将通道数从9映射为3,实现图5的上半分支和下半分支特征的相加,减少通道堆叠,尽可能降低计算代价。
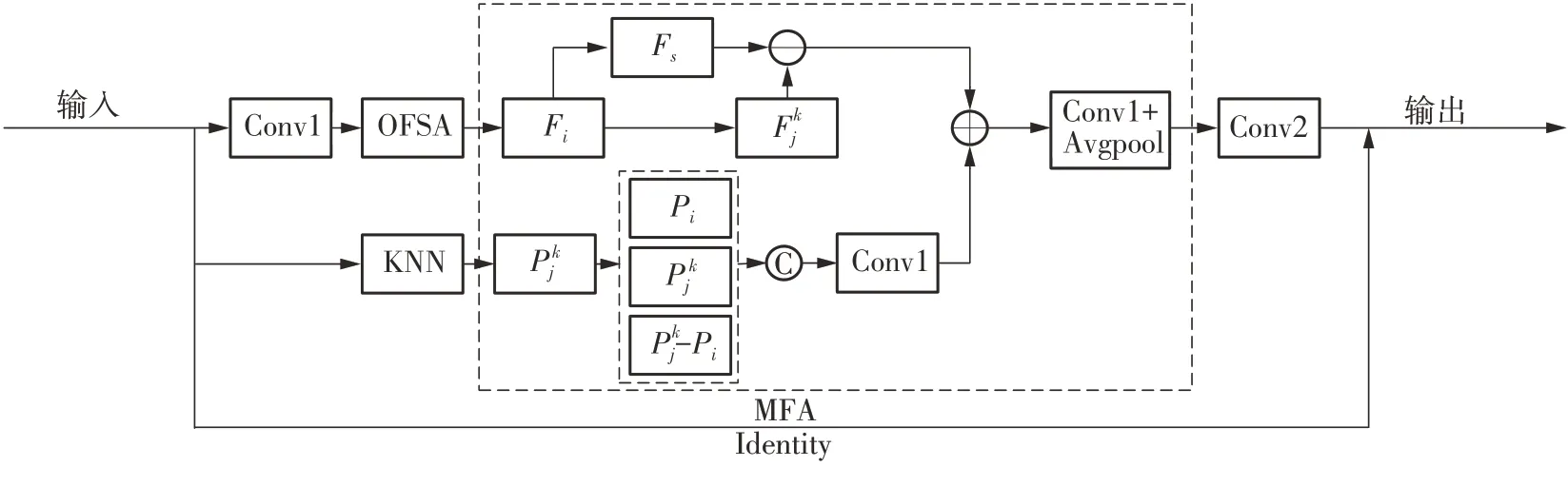
图5 局部特征与点特征融合模块Fig.5 Local feature and point feature fusion module
1.5 评价指标
为了确定模型最终分类的效果,采用分类总体准确率和类别平均准确率作为点云分类评价指标。
(1)分类总体准确率
式中,ηoverall为分类正确的数量与总样本数量的比值,N为总样本数量,T为预测的样本中所有分类正确的点云数量。
(2)类别平均准确率
式中,ηavg为所有类别预测准确率的平均值,i为第i个类,Ti是第i个类别分类预测正确的样本数量,Ni为第i个类别的样本总数。
2 实验结果与分析
2.1 实验数据集
采用ModelNet40[27]和ScanObjectNN[28]数据集用于模型评估。https://modelnet.cs.princeton.edu 和https://hkust-vgd.github.io/scanobjectnn 为数据下载链接。ModelNet40数据集是CAD绘制的3D模型转换成的点云对象,共包含12 311个点云形状个体,共40个类别,其中训练集为9 843个点云模型,测试集为2 468 个点云模型,每个模型都进行了1 024 个点的采样以作为网络的输入,调用Mayavi.mlab库,选取ModelNet40 的前9 个类别如飞机、浴缸、床、板凳、书架、水瓶、碗、汽车和椅子等点云数据进行展示,部分数据见图6所示。

图6 Modelnet40部分数据Fig.6 Partial data from modelnet40
ScanObjectNN是一个从存在背景和遮挡的真实世界中扫描采样的室内数据集,由15 个类别的2 902 个3D 对象组成。由于背景的干扰,部分点云存在缺失和变形的情况,具有较大的挑战性。
为公平地验证模型性能,本文在ScanObjectNN的扰动(PB-T50-RS)变体数据集上进行实验。PB(Perturbation)是指通过平移、旋转和缩放真实边界框等数据增强方法对数据集进行扩展,该变体数据集主要利用了T50和RS数据增强方法,T50是指从边界框中心沿着轴将边界框随机移动至50%的对象大小,RS(Rotation,Scale)表示旋转和缩放。扩充数据集共14 510 个对象,每个对象包含5 个随机变换样本,本文分别以1 024和2 048个采样点作为网络的输入,同时对比了不同采样点下的点云分类准确率,以验证网络模型的性能。部分ScanObjectNN和其中的PB-T50-RS数据如图7和图8所示。

图7 ScanObjectNN部分数据Fig.7 Partial data from ScanObjectNN

图8 PB-T50-RS部分数据Fig.8 Partial data from PB-T50-RS
2.2 实验步骤
2.2.1 点云数据处理
在训练之前,需要对所采集的数据进行前期处理以确保模型有效运行。点云数据处理的流程是首先进行噪声滤除、然后进行数据采样以实现输入模型的数据大小相同,最后在模型搭建过程中对数据分组形成类似卷积的操作。
在数据预处理阶段,需进行数据去噪和数据增强,对于离群噪声点和非离群噪声点,存在中值滤波、均值滤波和高斯滤波等处理方式,ModelNet40数据集采用CAD手工绘制的模型转换得到,存在较少的噪声,可直接用于模型的训练。ScanObjectNN数据集来自真实世界,存在较多噪声,故采用噪声滤除和数据增强过的(PB-T50-RS)变体数据集进行实验。
在模型运行之前,为使输入网络的点云数量一致,需要对点云进行采样,主要有最远点采样(FPS)、随机采样、格点采样和几何采样等采样方式,最远点采样需选择一个初始点作为参考点,在所能承受的最远距离范围内,选取相对参考点的最大欧式距离点用于更新采样点集合,并将最大欧式距离点作为新的参考点以不断迭代,直至采样到所需的N个目标采样点为止。最远点采样方法相对于随机采样等其它采样方式采样点分布较为均匀,避免了部分区域出现采样点密度过大的情况,具有较高的鲁棒性。
在网络搭建过程中,进行算法设计实现点云查询分组,形成类似卷积的操作。点云查询分组的目的主要是为了实现局部区域点云特征的聚合,防止下采样过程中未采样到的点云的特征丢失,实现局部区域的点云特征聚合至该局部区域内的单个中心点。另外查询分组方式有球查询和最近邻(KNN)查询等,大多是在采样点的基础上进行查询分组,以实现局部区域特征的提取,其中球查询是以采样点作为球心,选取特定的半径进行球形区域扫描,在球形区域内的点即为所需分组点,而最近邻查询是以采样点作为中心点,选取离中心点周围最近的k个点作为所需分组点,相对球查询来说所分组中的点个数更加均匀,因此本文采用最近邻采样并通过多层感知机计算出每个局部区域邻居点与中心点的关系系数,通过与DGCNN 中类似的方式完成邻居点信息特征的聚合。
2.2.2 点云特征提取
点云的特征按照空间尺度有单点特征、局部特征和全局特征,按照物理属性有几何域和强度域等,部分网络模型利用点云几何特征作为一部分输入取得了较好的效果,但提取几何特征较为复杂,目前大多模型采用的是点云的空间尺度特征。本文采用最远点采样和最近邻查询实现多个分组,进而在空间特征尺度上实现点云不同层次特征的聚合,之后通过提出的基于偏移注意力机制和多特征融合的点云分类模型,以逼近数据特征所能决定的学习上限。
2.3 点云分类实验环境
本实验使用基于Python语言的Pytorch深度学习框架,硬件环境CPU为Intel(R)Core(TM)i5-9400F@2.90 GHz,GPU 为NVIDIA GeForce GTX 1070显卡,具体软件平台配置如表1所示。

表1 软件平台配置Table 1 Software platform configuration
在实验参数设置方面,K近邻算法k值设置为20,采用SGDM(Stochastic Gradient Descent with Momentum)优化器,设置动量系数缓解SGD优化器可能的梯度下降方向不稳定问题,动量为默认值0.9,初始学习率(lr)设置为0.001。训练的Batchsize设置为32,测试的Batchsize设置为16,共迭代训练200次,采用BN 正则化(Batch Normalization)和RELU(Rectified Linear Unit)激活函数,并在全连接层后添加Dropout层防止网络模型过拟合。
2.4 点云分类实验结果分析
网络模型训练过程中,导入的原始点云数据通过多层感知机增加点云的通道数,进一步通过OFSA 和MFA 将全局的语义特征信息、局部特征信息以及点的相关性信息融合。不断提取特征,增加点云特征矩阵的通道数,在提取的深层次点云特征矩阵上分别使用全局最大池化和全局平均池化,将所有特征点聚集为一个可用于分类的全局特征点,最终根据数据集的特性设计全连接层得到类别向量。选取类别向量中的最大值的索引作为预测类别,若训练ModelNet40,网络最后一层共40 个神经单元;训练ScanObjectNN,网络最后一层共15个神经单元。以训练ModelNet40数据集为例,所提出的网络不同层级通道数变换见表2所示,首先输入最初的特征和采样点,经过第1 个Make_layer层,输出第1层的特征点和采样点,用作下一层的输入,不同层级均存在特征点和采样点的输入输出,每一个Make_layer层基础模块的通道数变换如表2所示。
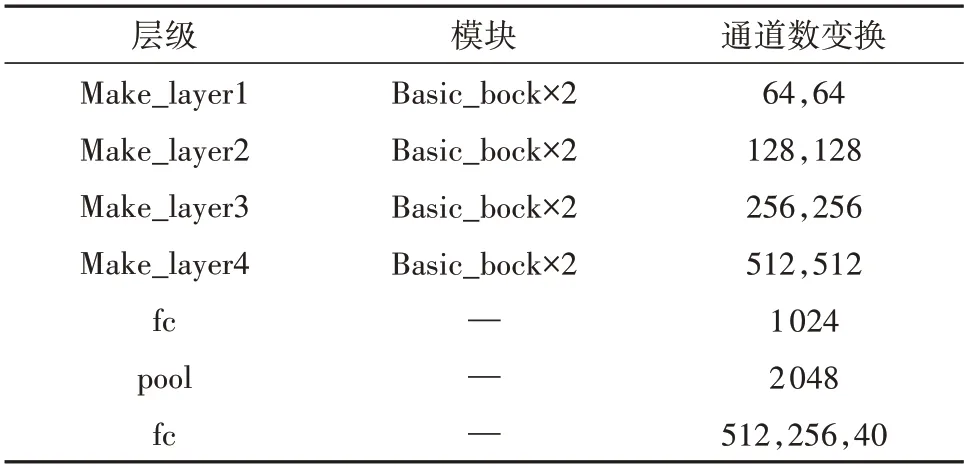
表2 网络的通道数变换Table 2 Channel number conversion of network
应用标签平滑计算交叉熵损失值作为三维点云分类的损失评估指标,用于模型的反向传播过程中的权值等参数的更新。将提出的网络模型在Model-Net40 数据集上与部分基于多视图的方法、基于体素的方法和直接基于点的方法进行对比实验,在分类总体准确率(Ao)和类别平均准确率(Am)上都达到较好的效果,该数据集的不同模型具体分类结果如表3所示。

表3 不同算法在ModelNet40数据集上分类结果比较Table 3 Different algorithms are compared to classify results on the ModelNet40 dataset
表3中的Input列是指输入网络模型的方式,输入方式有体素、多视图和直接基于点云3 个类别,Points指初始输入的点的个数,1k为1 024个点,可以看出,在ModelNet40数据集上,基于体素的方法相对于基于多视图和直接基于点云的方法表现得较差,部分模型由于缺少局部特征信息,较DGCNN等包含局部信息的模型预测分类准确率略微低一些。PCT 和DGCNN 可以较好的弥补缺少局部邻域特征信息这一缺点,另外LDGCNN的残差连接方式使得分类总体准确率相对DGCNN 提高了0.7 个百分点,故考虑构造一个邻域拓扑结构提取局部特征,同时融合点云全局特征,最终搭建一个基于偏移注意力机制并融合图结构信息的残差网络模型。实验结果表明,与其他算法相比,LPCTNet网络消耗的计算资源较少,可以更好地捕获局部信息,在ModelNet40 点云目标分类任务中,Ao指标较Point-Net、LDGCNN、PCT模型分别提高4.4、0.7、0.4个百分点,Am指标较PointNet 和LDGCNN 分别提高4.7、0.4个百分点。
图9表示的是在ScanObjectNN 数据上的混淆矩阵,横坐标表示的是点云的实际类别,纵坐标表示的是预测类别,由于在列方向上进行了归一化处理,故单元格范围在0~1之间,其中混淆矩阵对角线表示的是单个类别的召回率,单个类别的精确率可通过行方向计算推理而出,即可通过该类别召回率的值和该类别行方向上总和的比值计算推理。

图9 ScanObjectNN数据集混淆矩阵Fig.9 ScanObjectNN dataset confusion matrix
表4为不同算法在ScanObjectNN 数据集上分类结果,在ScanObjectNN 数据集上的实验结果表明,与其他算法相比,所提出的算法模型的分类总体准确率较高,Ao指标较PointNet++和DGCNN模型分别提高5.8、5.6 个百分点,Am指标较PointNet++和DGCNN分别提高5.5、7.3个百分点。

表4 不同算法在ScanObjectNN数据集上分类结果比较Table 4 Different algorithms are compared on the ScanObjectNN dataset
2.5 消融实验
不同模块的嵌入对模型的影响不同,为研究不同模块的重要程度,在ModelNet40点云分类数据集上进行模型消融实验,分别将多特征融合模块,残差连接和偏移注意力机制融入网络结构中进行实验,另外为验证不同模块的性能,尝试单独去掉一个模块进行消融实验,共进行6组不同模型结构的对比实验,以发现不同模块对网络总体分类预测准确率的影响程度。
由表5可知,不使用采样点的全局特征和局部邻域结构的融合模型的分类总体准确率仅为89.2%;为捕捉全局的特征信息,在提取采样层级局部区域的特征信息的同时对输入层的点云特征实现特征层面上的拼接,同时和特征层级局部区域特征信息相聚合,实现多特征信息的融合,使得网络的准确率达到92.3%;进一步融入残差结构,网络模型的分类总体准确率提升0.8个百分点;最后在此基础上引入偏移注意力机制,分类总体准确率达到93.6%。另外,从表中可知,当去除多特征融合模块时,分类总体准确率和类别平均准确率分别下降了2.0 和3.8 个百分点,相对偏移注意力机制和残差连接而言下降的更加明显,因此多特征融合模块在提升精度方面的效果最为显著,而偏移注意力机制和残差连接对精度也有一定的提升效果。

表5 模块重要性分析结果Table 5 Module importance analysis results
3 结语
本文提出了一种基于偏移注意力机制和多特征融合的残差点云网络,利用了偏移注意力机制提取点云的全局语义信息,多特征融合模块实现原始层级和特征层级的全局信息和局部信息的融合,在ModelNet40和ScanObjectNN数据集上取得了较好的分类识别效果。
本文提出的模型主要贡献有以下几点:①引入残差结构实现了来自不同层级所聚合的特征的有效连接,避免了梯度消失的问题。②增加了偏移注意力机制,获取点的相关性,提取点云的隐式全局语义特征。③在提取局部特征的基础上,增加点的全局信息特征,提高网络模型对点云的几何形状感知能力。通过在不同数据集上的经典模型对比实验以及自身的消融实验证明了本文所提出的模型具有较高的准确率,且具备较好的鲁棒性。
目前较多的点云分类算法难以兼容准确率和速度,如何进行改进以适应不同的环境需求是未来重点考虑的研究方向之一。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
