
基于改进网络核密度和负二项回归的事故黑点鉴别
2024-02-15 03:04庄焱董春娇米雪玉王菁杨妙言
华南理工大学学报(自然科学版) 2024年1期
庄焱 董春娇† 米雪玉 王菁 杨妙言
(1.北京交通大学 交通运输学院,北京 100044;2.华北理工大学 建筑工程学院,河北 唐山 063210)
2018年公安部道路交通安全研究中心发布的数据显示,占比7.5%的城市道路上发生的交通事故占全国道路交通事故的45.8%,伤亡人数占全国道路交通事故伤亡总数的38.8%。城市道路百公里交通事故率是高速公路的4 倍、普通公路的10 倍[1]。城市道路交通路网结构错综复杂,存在大量交叉口,其复杂的交通组成和交通特征使得交通冲突更为明显,因而成为了现代化城市治理的痛点。2019年中共中央国务院印发的《交通强国建设纲要》中明确提出了“加强交通安全综合治理,切实提高交通安全水平”的目标,要求“大幅提升我国的交通安全水平,全面提高交通安全对策的系统性、科学性、有效性”。面对日益严峻的道路交通安全问题,如何在现有数据条件下精准识别事故黑点并确定优先整治顺序,提出高效经济的治理对策从而有效提升城市路网整体安全水平成为了城市交通安全管理中亟需解决的问题。
目前,黑点鉴别的研究大多采取空间聚类法,如最近邻KNN、K-means聚类等[2]。近年来,以核密度估计为代表的地理信息系统在交通事故黑点中的应用越来越普遍,该技术可以分析既有事故数据以发现道路交通事故的空间分布特征,对后续的交通安全整治提供可视化指导,从而辅助进行针对性的事故预防部署。Achu等[3]利用地理空间工具对印度德里久尔地区的事故黑点进行了核密度分析,并与空间自相关法、热点分析法等方法进行对比,证明了核密度分析法的优越性。已有研究表明在实际的路网空间中,交通事故的发生和分布受路网空间格局的影响体现出非均质性特征,而平面核密度容易检测出过多的空间聚类,产生虚假聚类报错[4]。故学者们开始采用以网络距离为度量的网络核密度估计来识别交通事故热点。Harirforoush 等[5]将网络核密度估计法应用到加拿大舍布鲁克市区事故聚集路段的鉴别上,取得了良好的效果。但已有研究中尚未有考虑交通事故对发生地影响程度的研究。道路交通网络作为一种复杂网络,其拓扑结构、环境位置等条件决定了交通事故的影响程度也有所不同[6],应从地理环境信息和交通流特征等事故致因角度深层次、全面地挖掘交通事故综合影响度的内涵,提高事故黑点鉴别的准确性和科学性。
负二项回归模型是交通安全领域中事故分析时应用最为广泛的方法之一,然而由于事故大多只零散地分布在某些地点上,其他路段并未发生事故,事故数据中往往出现大量零值,若使用传统离散分布分析法会产生较大偏差。因此,考虑选用零膨胀回归模型来处理。自Ridout 等[7]将零膨胀泊松ZIP回归模型推广为零膨胀负二项ZINB回归模型以来,零膨胀回归模型已广泛应用于道路安全、经济学等领域。如果数据中除了存在零膨胀现象,还存在过分散现象即方差大于均值现象,则ZINB 回归模型比其他模型更适用于此类数据分析处理。马壮林等[8]对比了ZINB 和NB 回归模型对高速公路碰撞事故数据的拟合效果,证明了ZINB 回归模型的优越性。Weng 等[9]运用ZINB 模型首次对水上交通事故进行了影响显著性分析。但目前鲜有研究将ZINB模型应用于事故黑点的鉴别。
综上所述,本文系统考虑路网节点的道路环境和网络拓扑特征,在传统网络核密度估计法中嵌入事故严重度和事故综合影响度系数,提出面向交通事故鉴别的改进网络核密度估计方法,直观刻画交通事故黑点的空间分布特征,并采用零膨胀负二项回归模型对网络核密度值进行拟合,实现事故黑点区域边界的定量分级精准鉴别。
1 嵌入节点综合重要度的改进网络核密度估计法
本文提出一种面向事故黑点鉴别的网络核密度估计方法,通过在道路网络上生成平滑的密度表面体现交通点事件的空间聚集特性,研判交通事故的高发区域。核密度估计法根据搜索区域的不同可分为平面核密度估计和网络核密度估计。以城市道路网络为研究对象,平面核密度估计的搜索区域是以核中心为圆心,窗宽为半径的圆形区域,而网络核密度估计的搜索区域则是以核中心为起始点,以窗宽为长度极限所能到达的所有道路的线段范围[10],如图1所示。

图1 平面核密度与网络核密度事故点搜索结果对比Fig.1 Comparison of accident point search results between plane kernel density and network kernel density
有别于主要基于欧氏距离的平面核密度估计法,网络核密度估计法采用网络距离表征通常发生在道路网络内的交通事故点事件,这与现实交通事故密度报告中常用每公里事故数等线性单位指标的情况相吻合。在实际城市路网中,最短网络距离和欧氏距离通常有着显著差异。研究表明,当欧氏距离小于400 m时,二者的差别可超过20%[11]。采用网络核密度估计可有效避免由于使用欧氏距离导致很多不在实际搜索半径内的事件点被计算,从而产生估计结果偏大的情形。故本文选用网络核密度估计法,并在此基础上提出一种面向事故黑点鉴别的改进网络核密度估计方法,以空间子路段为基本分析单元进行交通事故黑点鉴别,主要鉴别流程见图2。

图2 事故黑点鉴别的改进网络核密度估计基本流程Fig.2 Basic flow of improved network kernel density estimation for accident black spot identification
为了使鉴别结果更符合实际道路事故安全状况,同时考虑不同道路路网特征、环境条件下交通事故的影响范围差异,本文考虑在网络时空核密度估计的基本公式中同时引入事故严重程度指数和事故综合影响度指数,改进后的公式为
式中:为网络核密度估计值;n为研究区域内事故点总数;r为窗宽;K(·)为一维高斯核函数;di为第i起事故到该核中心的网络距离;Si为第i起事故的事故严重程度指数,即
式中:D、H、V分别为死亡人数、受伤人数和受损机动车数量;k1、k2分别为死亡人数和受伤人数的权重系数,参考国内外相关资料[12],本文分别设为2和1.25。
研究区域内的城市道路网被抽象为由点(交叉口)线(路段)构成的线性网络系统,路段上的节点信息可借助交叉口节点处的信息表示。故第i起事故在窗宽覆盖范围内的路段上某节点q处的综合重要度影响指数T(i)为
式中,dpq为节点q到邻近交叉口节点p的距离,R为搜索半径(本文用路网平均距离代替),m为搜索半径内节点q周围所有的交叉口节点数。四次项ρ[1-(dpq/R)2]2表示路网交叉口节点p对节点q的影响度影响分配比例,其中ρ为用来保证交叉口节点p对搜索半径内所有节点q的影响总和∑j ρ[1-(dpq/R)2]2=1的常数比例因子。I'p为面向交通事故黑点鉴别同时考虑交叉口节点间相互影响的路网交叉口节点p处的综合影响度,
式中,Ip为交叉口节点p的初始重要度,Lop为节点o和节点p之间的最短路径长度,Ep为影响指标矩阵,Wp为影响指标权重矩阵,考虑到不同指标在事故综合影响度体系中所占权重不同,采用随机森林法标定不同指标的权重以调整其影响程度。由于和交通事故相关的影响指标变量的分类结果具有明显的离散性,本文首先对各影响指标进行离散化处理,得到各指标的分类描述和离散化取值结果,如表1所示。

表1 面向交通事故黑点鉴别的交叉口节点综合影响度指标1)Table 1 Node importance evaluation index for traffic accident black spot identification
通常道路横断面的交通状况会在交叉口附近发生急剧变化,网络核密度值相应也会出现衰减效应,衰减系数α的取值与交叉口处的相交道路条数有关[13],具体可表示为
式中,1/(ns-1)为衰减系数α,ns为交叉口处的相交道路条数。
2 基于零膨胀负二项回归的事故黑点鉴别模型
对于计算得到的网络核密度估计值可以用Arcscene 软件进行可视化展示,即在道路上用色彩的深浅表征核密度值的大小。若直接采用目视判读法通过色彩聚集度对热点道路的边界进行判定存在一定主观臆断性,无法准确勾勒出热点区域的边界。由于经高斯核函数估计得出的网络核密度值存在零膨胀和过分散趋势特征,为了科学合理地鉴别事故黑点,本文先利用零膨胀负二项回归模型拟合网络核密度估计结果,再根据累计频率拟合曲线设置不同的阈值对事故黑点路段进行分级鉴别。
零膨胀负二项回归模型(ZINB)由零分布和负二项分布共同组成,可有效解决网络核密度数据因其跳跃性产生的零值过多和数据方差过大的问题,避免整体拟合结果趋于零,从而遗漏大量事故黑点路段的情形[14]。ZINB回归模型的概率密度函数为
式中:Y为随机变量;yi为变量Y的观测值,即各网络核密度估计值;p为ZI 参数(表示零值数据的占比,p越大,表示数据越有可能出现零膨胀现象);λ为负二项分布的均值;1/τ为散度参数;Γ(·)为伽马函数。在ZI参数部分和负二项参数部分分别引入协变量以讨论自变量和因变量之间的关系:
式中,X、W为协变量,β、γ为回归系数,t为迭代次数。
传统的参数估计一般采用极大似然法(MLE),但当分布函数过于复杂或含有隐变量时,采用期望最大化(EM)算法可以规避极大似然估计法实际无法观测每个数据具体分布的情况,有效简化多维参数问题,并通过迭代优化得到精度较高的参数估计值[15]。假设独立分布的观测数据的联合分布[15]为f(y;θ),θ为参数集合,z为分布已知的隐变量,则第t次迭代的EM算法可表示为以下两个步骤。
步骤1求期望(Expectation)
在已有观测数据Y和第t步估计值的条件下,求关于隐变量z的对数似然函数的期望,即
步骤2求极大(Maximization)
求Q(θ|y,θi)关于θ的极大值,令θ=θi+1,则一次迭代为
重复步骤1 和步骤2 直到得到足够精度的θ为止,即收敛。
3 实证研究
3.1 考虑事故和节点综合影响度的网络核密度估计
本文以深圳市福田区华强北街道为研究对象,共收集到该辖区范围内2016—2020 年城市道路交通事故1 256 起。事故属性包括事故编号、事故日期、事故时间、死伤人数、事故原因等。路网矢量数据从全国地理信息资源目录服务系统发布的1∶100万公众版基础地理信息数据(2019年)的全国矢量路网数据中获取。在ArcGIS 软件中搭建华强北街道辖区范围内的原始路网,对路网进行初步筛选处理,步行街道和交通流量较小的支路忽略不计,距离较小的路段则合并处理,最后得到主要路网总长度23.865 km,交叉口70 个和路段115个,并进一步在Python软件中构建相应的拓扑路网。
交通事故点通常围绕道路网络呈空间聚集分布,但由于受到采集装备精度等的影响,交通事故点经常会和实际道路产生偏移。在网络核密度估计中,空间窗宽一般远大于事故点到路网的最近距离。因此若事故点到路网的距离小于缓冲区范围,则将该事故点投影匹配到该时空子路段中。根据事故点到道路网络最近距离的累计频率分布,设定50 m为缓冲区范围,将所有缓冲区内的事故点投影到道路网络上,最终获得1 060则交通事故点数据匹配路网,如图3(a)所示。为了方便观察事故数据的特征,选定80 m×80 m 的单元网格分别绘制二维和三维事故数据分布渔网图,如图3(b)、图3(c)所示。

图3 交通事故点的路网匹配结果及分布网格图Fig.3 Road network matching results of traffic accident points and distribution grid diagram
从图3可以看出,道路交通事故在华强北商圈的分布具有鲜明的地理分布特征。为此,进一步探究事故分布的空间分布特征及路网特征相关性。
根据近似密度与真实密度的均方误差最小时的窗宽为最优窗宽的原则[16],最优窗宽的计算公式为
式中:hopt为最优窗宽;σ为高斯核函数的标准差,本文用事故点数据的网络距离的标准差替代;N为目标对象总量1 060。计算得到最优空间窗宽为152.300 m,根据最优窗宽的1/10 确定空间步长为15.230 m,按照子路段长度重新划分子路段,其中不足空间步长的部分单独作为子路段,得到23 384条子路段,分别计算每条子路段的核密度估计值,利用ArcScene实现可视化显示,结果如图4所示。

图4 华强北街道交通事故网络核密度估计图Fig.4 Network kernel density estimation of traffic accidents in Huaqiangbei Street
从图4 中的对比可知,考虑节点综合影响度后,部分主要道路上的网络核密度估计值进一步提升,这些网络核密度高值区主要分布在人、车流量较大的地方,如红荔路(华新村小区)、振兴路中段(曼哈数码商场)和深南中路(上步中学)等附近,而部分非主要道路上的网络核密度估计值则显著下降,如华富路北段、振华路西段等,更符合实际情况。
3.2 交通事故黑点路段识别
利用R语言对网络核密度估计值进行零膨胀负二项回归拟合,并绘制拟合前后的概率分布曲线,如图5所示。

图5 事故黑点网络核密度估计值的零膨胀负二项拟合结果及累积概率分布曲线图Fig.5 Zero-inflated negative binomial fitting result and cumulative probability distribution curve of network kernel density estimate of accident black spots
从图5可以看出,零膨胀负二项回归模型将曲线的拟合起始点从48%降至0,且上升阶段的曲线比原始数据的更为光滑,更能够体现出子路段网络核密度估计结果的分布。按照基于零膨胀负二项回归模型得到的累积概率为90%、80%和70%时对应的网络核密度值作为阈值分别划分一级、二级和三级事故黑点路段,得到热点路段等级划分图,如图6所示。

图6 事故热点路段等级划分图Fig.6 Classification diagram of accident hot road sections
从图6可以看出,两种情形下鉴别出的事故黑点路段大体一致,但考虑节点综合影响度后,不少路段的事故黑点等级分布发生了较为显著的变化。例如,位于机动车限行的单行道管理区的钰裕大厦(区域1)、振华大厦(区域2)等地由于所处交叉口节点等级低,核密度值有所下降,而上步管理大厦等由于地处主干道交叉口附近,周围影城、商场遍布,人车流量大,核密度值则显著上升。将事故多发点的可视化结果置于现实场景中,可以看出考虑节点综合影响度后,严重度较高的一级事故黑点路段大多分布在商业广场、办公大厦和学校等人、车流量较大的主要道路上,与实际相吻合。
3.3 结果有效性检验和对比分析
命中率是最常用的鉴别方法有效性的检验指标,即鉴别出来的黑点路段在将来时间段内发生的事故数占总事故数的比例。考虑待研究路段总长度带来的影响,本文采用改进的命中率,即有效搜索率指标S对基于零膨胀负二项回归的事故黑点鉴别法进行有效性检验[17],计算公式如下:
式中,Q为在将来某一时间段内发生的事故数,L为鉴别出的事故黑点路段长度。
基于检验指标的定义,将华强北街道5年的道路交通事故数据分为两组,一组为2016年到2019年的事故数据,一组为2020 年的事故数据,用以比较平面核密度估计法和网络核密度估计法在是否考虑节点综合影响度的鉴别精度,结果见表2。
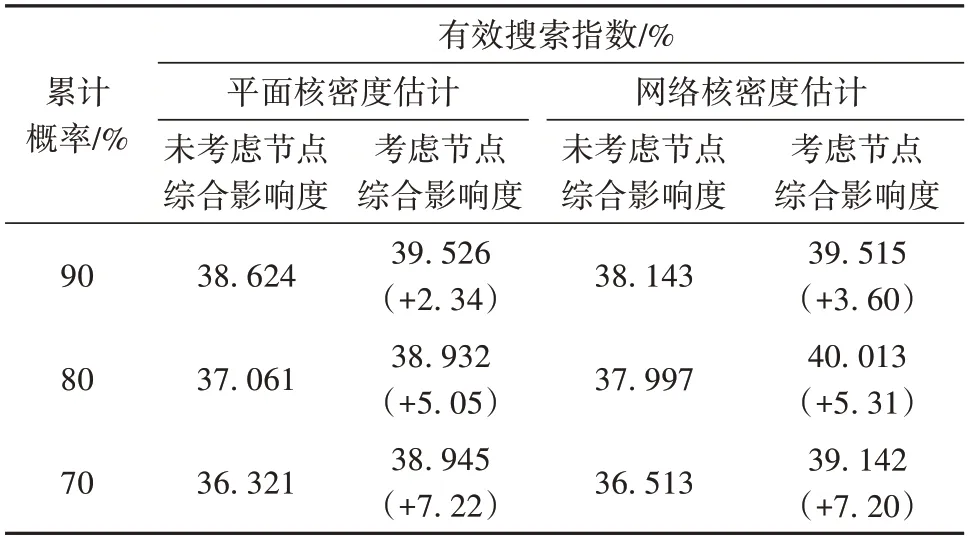
表2 不同鉴别方法在不同阈值下的有效搜索指数对比1)Table 2 Comparison of effective search indexes of different identification methods under different thresholds
从表2中可以看出,网络核密度估计的有效搜索指数总体高于平面核密度估计。考虑节点综合影响度后,在累计概率为90%、80%和70%时,平面核密度估计有效搜索率分别提升了2.34%、5.05%和7.22%,本文提出的改进网络核密度估计也分别提升了3.60%、5.31%和7.20%,两种事故黑点核密度估计鉴别法的有效搜索率分别平均提升了4.87%和5.37%。
将如图4 所示网络核密度法识别结果和如图7所示的平面核密度法识别结果进行对比,可以看出平面核密度法将部分公园(荔枝公园)、居民区(海馨苑)和湖泊等没有道路的区域也识别为事故黑点,与实际不符。这是由于平面核密度法计算了整个路网区域平面的密度分布,以二维欧氏距离度量事件的发生和影响范围,并没有考虑到路网的非均质空间特性。而网络核密度法将密度分布限制于城市道路网络空间内,更加符合交通需求与实际道路网络的对应关系,且密度值在同一道路上分布连续,在不同等级道路分布较均衡,密度分布具有差异性但不存在突变情况,可以如实地反映实际情况中交通事故在路网中的分布特征。

图7 华强北街道交通事故平面核密度估计图Fig.7 Kernel density estimation of traffic accidents in Huaqiangbei Street
4 结语
本文考虑交通事故对不同道路环境和路网拓扑特征的发生位置处的影响,提出面向事故黑点鉴别的节点综合影响度计算方法,并纳入传统网络核密度估计法中。针对计算得出的网络核密度估计值零值多和过分散特点,采用零膨胀负二项回归模型加以解决。实例研究表明:
(1)城市道路的交通事故黑点具有显著的空间分布差异性,办公大厦、商业广场和学校等人、车流量大的干路是一级事故黑点路段的主要分布地,应加强对上述重要度较高的节点附近的交通安全整治和预防;
(2)采用零膨胀的负二项回归模型可以很好地解决事故数据存在的零膨胀和过分散问题,并较平滑地拟合出网络核密度估计值曲线,从而实现在不同阈值水平下定量客观地识别并划分不同等级的事故黑点路段。
(3)受道路网节点综合影响度的影响,路网交通事故黑点也会相应改变,即节点综合影响度的大小改变对交通网络中的事故黑点分布具有一定权重的影响,考虑了节点综合影响度后的平面核密度和网络核密度估计模型的有效搜索率分别平均提升了4.87%和5.37%。
(4)本文仅考虑了部分道路环境指标,后续可进一步考虑其他影响指标,如道路沿线两侧的土地利用情况等等以及不同指标间的耦合作用。此外,道路交通事故在时间维度上也具有集聚性,道路在不同的时间上也有不同的交通流量等特性,因此未来如何综合考虑交通事故的时空分布特性值得进一步研究。
猜你喜欢
廊坊师范学院学报(自然科学版)(2022年3期)2022-10-11
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2022年4期)2022-06-01
今日农业(2021年19期)2022-01-12
科技视界(2021年4期)2021-04-13
学生天地(2020年31期)2020-06-01
中国生殖健康(2019年10期)2019-01-07
环球飞行(2018年7期)2018-06-27
中国公路(2017年11期)2017-07-31
中国公路(2017年7期)2017-07-24
